链接核验:2026-06-11 · Wine & Chord
AI Agent 阅读路线:从上下文到 Harness 的六条机制路径
这不是一份按公司名堆链接的清单。AI Agent 的公开资料已经多到足够让人迷路: OpenAI 讲 Codex、Agents SDK、沙箱和 harness;Anthropic 讲 effective agents、 context engineering、skills、sandboxing 和 managed agents;Cursor 讲 cloud agents、 CursorBench 和产品 harness。真正要读懂的是它们背后的工程边界。
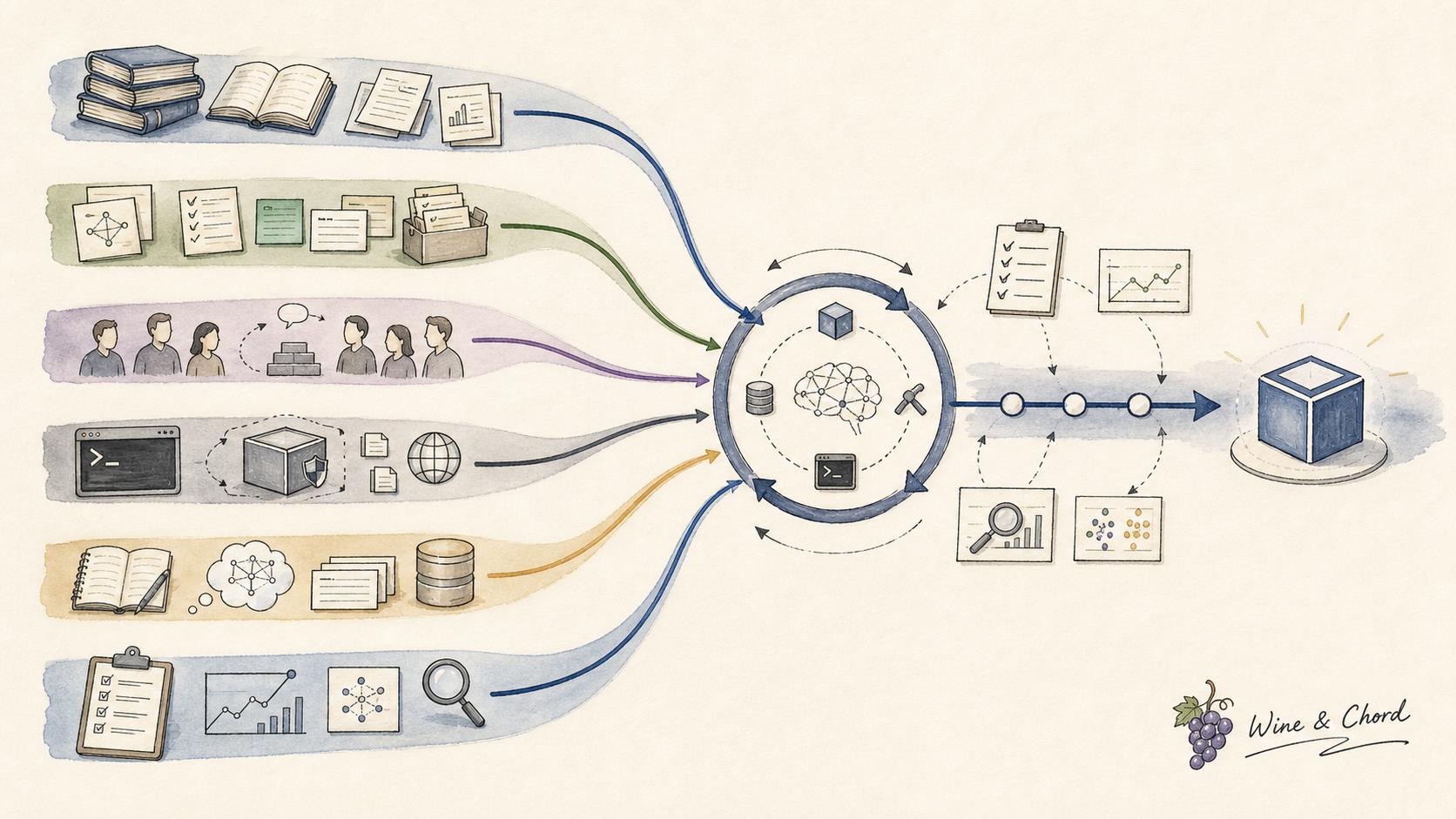
本页回答一个问题:想系统学习 AI Agent,应该先建立哪些工程坐标?读完后,你应该能把一篇资料放进 context、team、runtime、learning、measurement、harness 六条线, 并能说明它证明了哪个 contract、暴露了哪个边界、留下了什么可复核证据。
一、实践压力:为什么不能只收藏链接
1.1 真实问题:Agent 失败常常不是“模型不会”
做 coding agent 或业务 agent 时,失败经常发生在模型之外:上下文塞进了过期信息,工具输出没有过滤,沙箱权限过宽,长任务没有 checkpoint, eval 只看最终答案,没有记录轨迹。Anthropic 在 Demystifying evals for AI agents 里强调 agent eval 要覆盖带工具、会修改环境的多轮过程;Cursor 在 harness 迭代复盘 里把提示、工具、UI、反馈和训练数据放进同一条产品闭环。它们讨论的不是“再换一个模型”,而是如何让模型处在一个可控系统里。
1.2 六个明确问题
- 本轮模型真正看见了什么,哪些状态留在外部 artifact 或 memory 里?
- 什么时候该拆 subagent,拆出去的上下文、工具和输出如何回收?
- 代码执行、浏览器、文件、网络、凭证和人工确认的边界在哪里?
- 一次失败后的经验怎样变成 rule、skill、memory 或训练信号,而不是新的噪声?
- agent eval 衡量的是一次 answer,还是包含环境、预算、随机性和 的 trajectory 分布?
- harness 怎样把 prompt、tools、state machine、checkpoint、review 和 deploy 接成可交付路径?
1.3 主论点:先读边界,再读能力
本文的主论点是:Agent 资料的阅读顺序应该是 public contract first。先看公开 API、文档和产品承诺允许什么,再看实现或论文如何组织机制,最后才比较模型能力。 这也是 Building effective agents 的基本气质:优先使用可解释、可组合的 workflow 和 agent 模式,只在任务需要时增加复杂性。
二、心智模型:Agent 是运行系统
2.1 系统清单:模型只是其中一个部件
如果把 agent 只理解成“会调用工具的大模型”,后面的资料会全部糊在一起。更稳的入口是把它写成系统清单:
这个式子不是数学定理,而是阅读检查表。OpenAI 的 Agents SDK 文档 强调 instructions、tools、handoffs、guardrails 和 tracing;Codex 文档把 AGENTS.md、 sandbox、subagents、skills 放进开发工作流;这些都说明 agent 是模型与运行时的组合。
2.2 ReAct 的边界:经典循环,不是现代产品全图
ReAct 给了一个重要范式:reasoning、action、observation 可以交替推进。但现代产品 agent 还需要沙箱、权限、状态持久化、恢复、评测、人工门禁和交付路径。 所以 ReAct 应该作为行动循环的经典论文来读,而不是把所有 tool-using agent 的来源都简化成 ReAct。
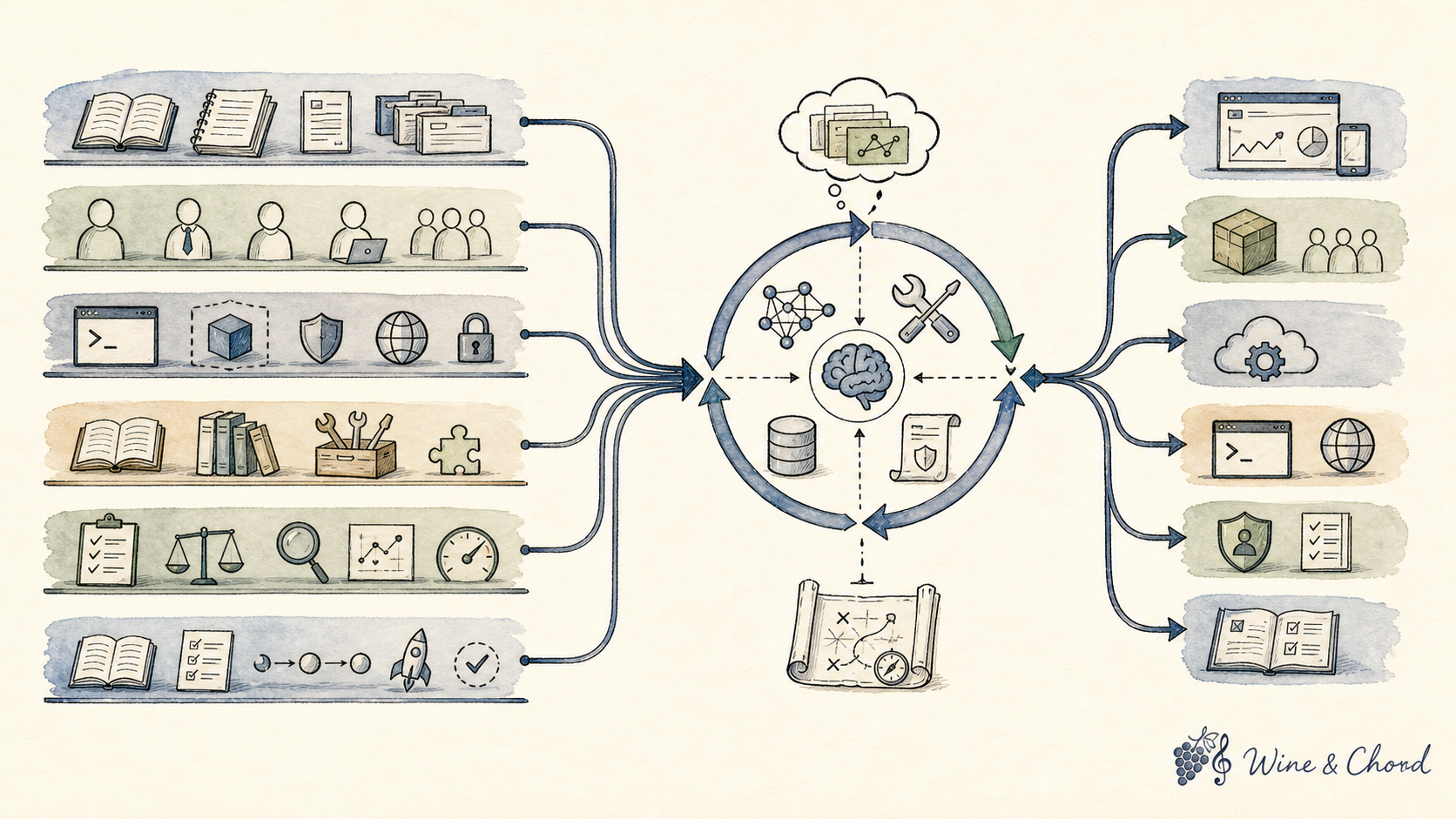
2.3 阅读地图:从问题线走到机制线
三、Provider 与公司契约
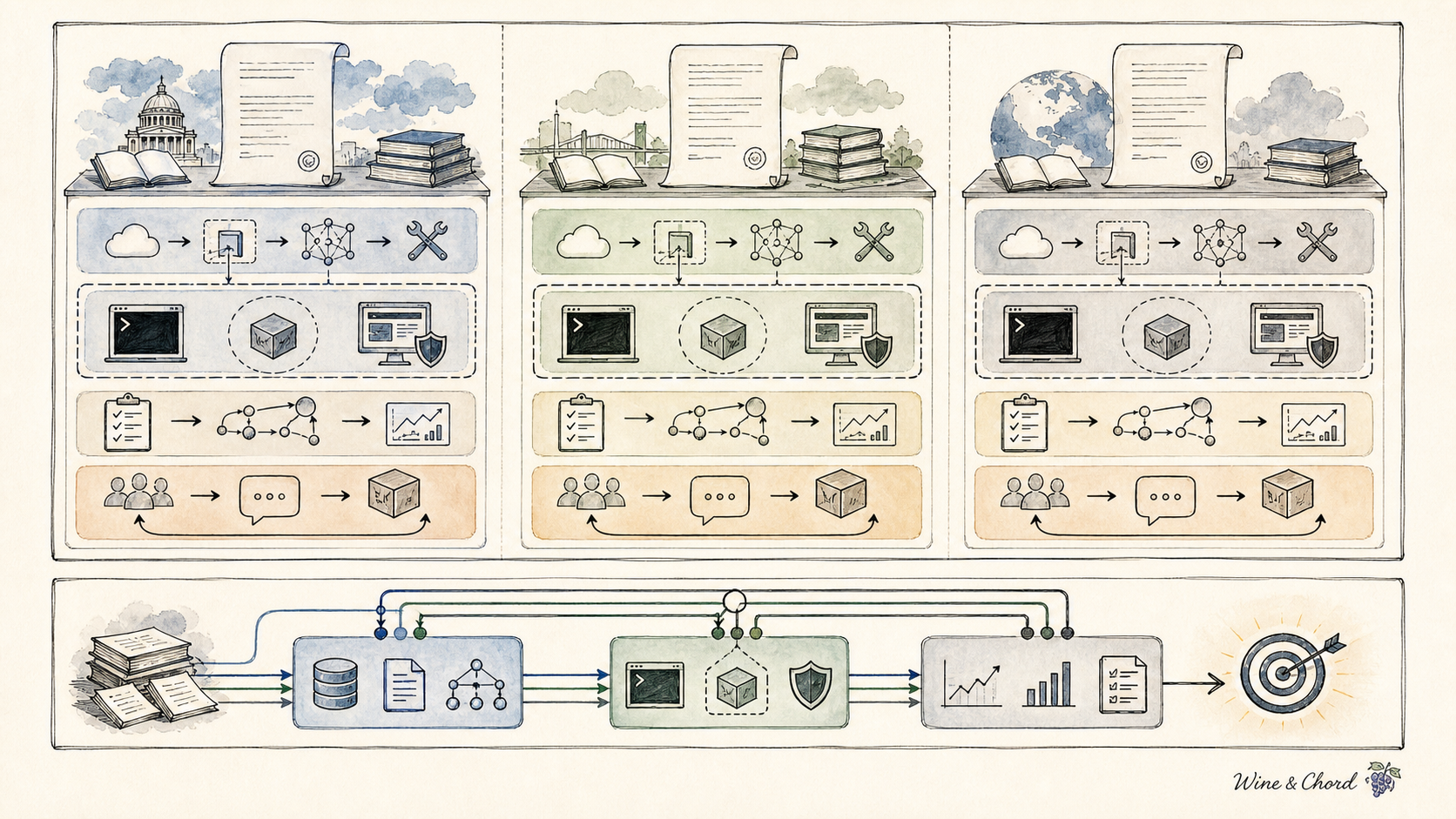
3.1 OpenAI:Codex、Agents SDK、AGENTS.md 与 sandbox
OpenAI 这条线适合从 Practical guide to building agents 入门,然后接 Agents SDK、 Sandbox Agents 和 Codex changelog。 Coding agent 方向重点看 Codex agent loop、 Codex harness 和 Symphony。 它们共同回答:agent loop 怎样被产品化,工具、沙箱、任务编排和验证如何接入工程交付。
3.2 Anthropic:简单模式、context、sandbox、skills 与 managed agents
Anthropic 的工程博客更像一套 runtime 课程。 Building effective agents 先区分 workflow 与 agent; Effective context engineering 讨论 notes、retrieval、tool-result filtering、compaction 和 context reset; Claude Code sandboxing 与 Agent Skills 则把执行边界和可复用经验放到前台。
3.3 Cursor:环境、harness 与真实使用信号
Cursor 的资料更偏产品系统。Cloud agent lessons 把 agent 能力和开发环境、持久执行、会话状态联系起来; Continually improving our agent harness 解释真实反馈如何推动提示、工具和训练数据;CursorBench 则提醒读者,模型质量在产品环境里要看真实编辑轨迹,而不只是离线题分。
四、六条机制路径
4.1 Context:有限工作集怎样装箱
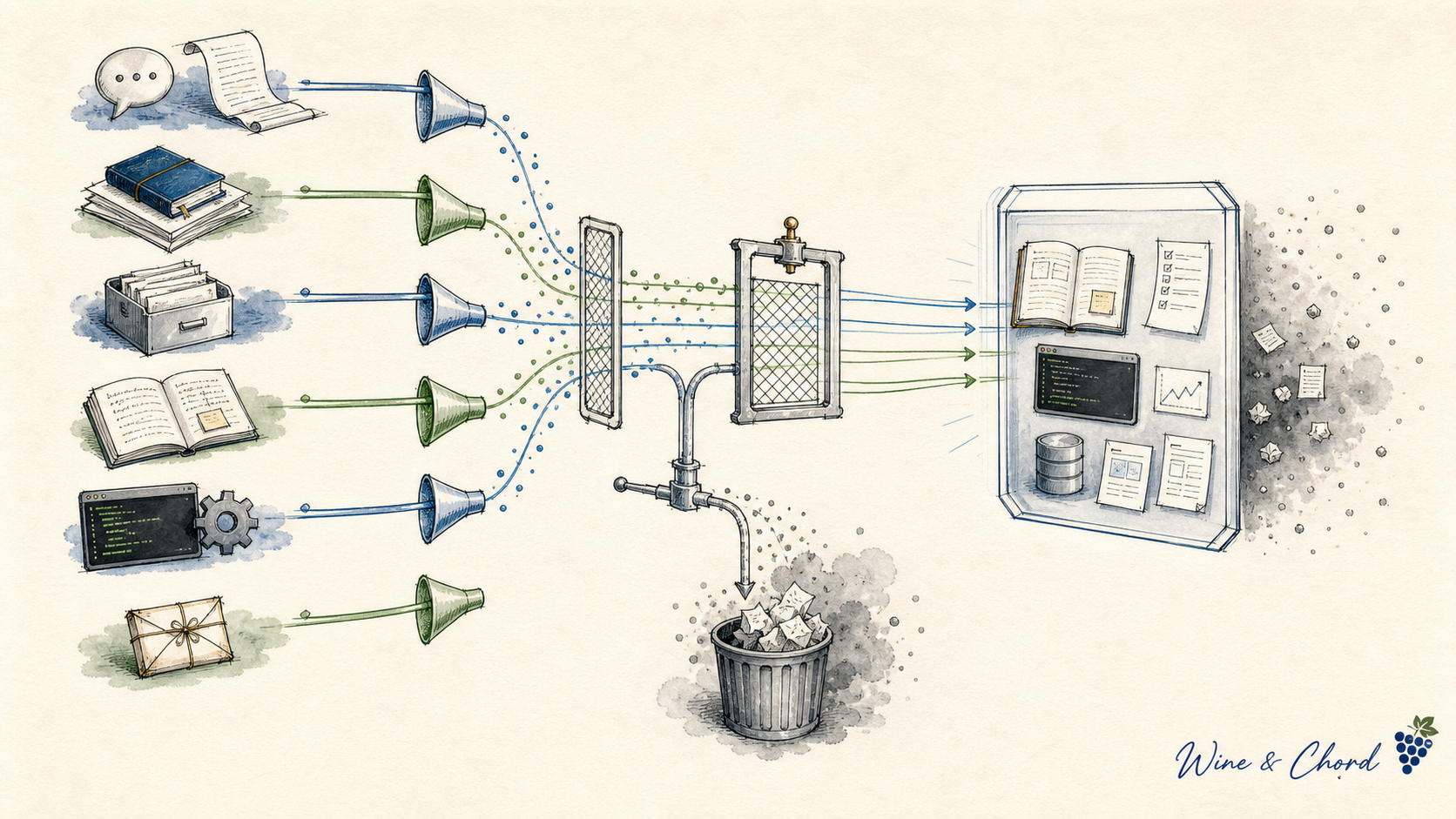
读 context 时要分清五类东西:对话历史、任务状态、项目规则、外部知识、工具结果。Anthropic 的 context engineering 文章把它们拆成 notes、retrieval、filtering、compaction、reset; OpenAI Codex 的 AGENTS.md 文档 和 Cursor 的 Rules 都说明,长期规则应该可审计、可版本化,而不是每轮临时拼接。
读什么
先读 Anthropic context engineering,再读 MemGPT 的 working memory / archival memory 类比;如果关注 coding agent,再接 Codex loop、AGENTS.md、prompt caching 与 conversation state。
不要误读
不要把 memory、RAG、summary、rules、skills 都叫“上下文越多越好”。它们的风险不同:摘要会偏移,检索会漏召回,规则会污染前缀,工具输出会带来注入。
4.2 Team:什么时候拆 subagent
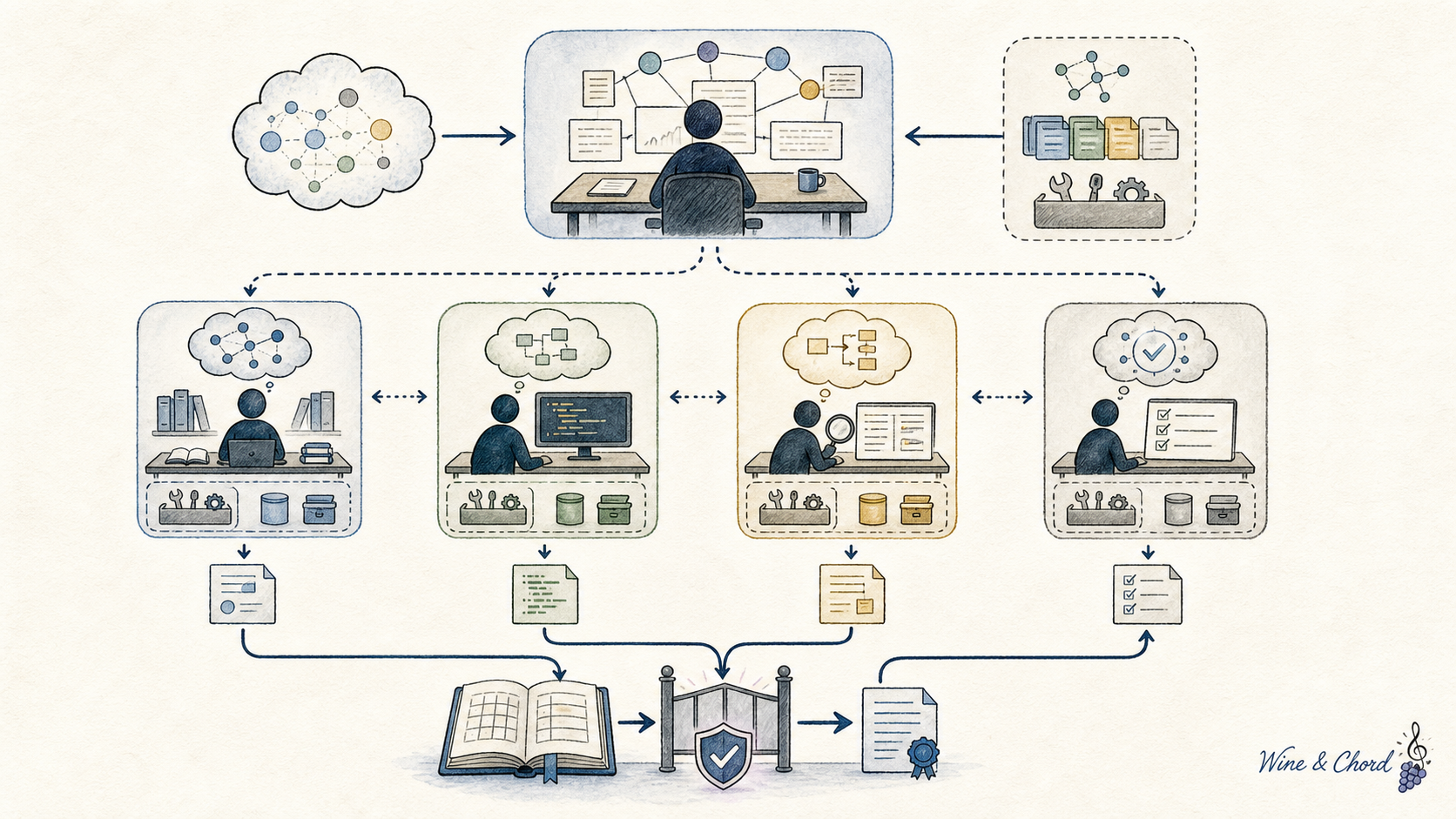
多智能体适合搜索空间宽、资料源分散、角色能力差异明显或需要独立评审的任务。Anthropic 的 multi-agent research system 和 OpenAI Codex 的 subagents 文档 都把关键点放在任务边界、上下文隔离和输出回收上,而不是简单增加“代理数量”。
读什么
先读 Anthropic 的 orchestrator-workers / evaluator-optimizer 模式,再读 Codex subagents、Symphony 和 AutoGen、CAMEL、MetaGPT 等早期论文。
不要误读
拆 subagent 不是并行化仪式。没有共享仓库、锁、任务板、测试、日志和合并协议,多 agent 会把通信成本和一致性风险放大。
4.3 Runtime:代码执行与沙箱边界
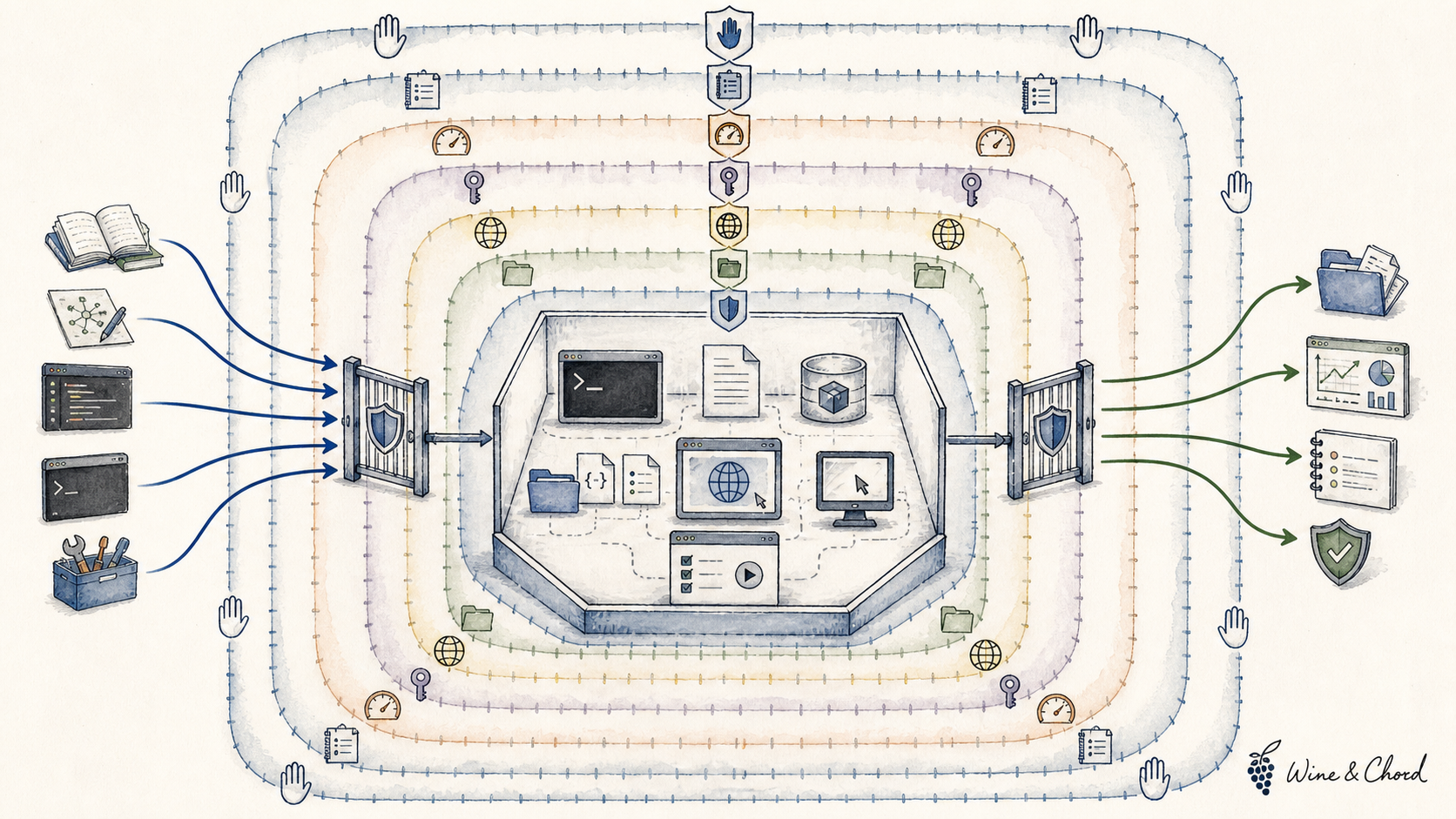
代码执行是 agent 能力的一部分。OpenAI 的 Codex sandboxing 和 Sandbox Agents 讲 provider-managed execution;Anthropic 的 Code execution with MCP 和 Claude Code sandboxing 讲工具、MCP 与本地边界。共同点是:filesystem、network、credentials、resource limits、audit 和 human confirmation 必须显式。
读什么
先读 Codex sandbox 与 Anthropic Claude Code sandboxing,再读 CodeAct 和 OpenHands 这类代码行动论文。
不要误读
沙箱不是容器品牌。容器、VM、OS sandbox、远端 workspace、provider-managed sandbox 都只是实现;真正要审的是可见边界和失败吸收能力。
4.4 Learning:经验怎样沉淀
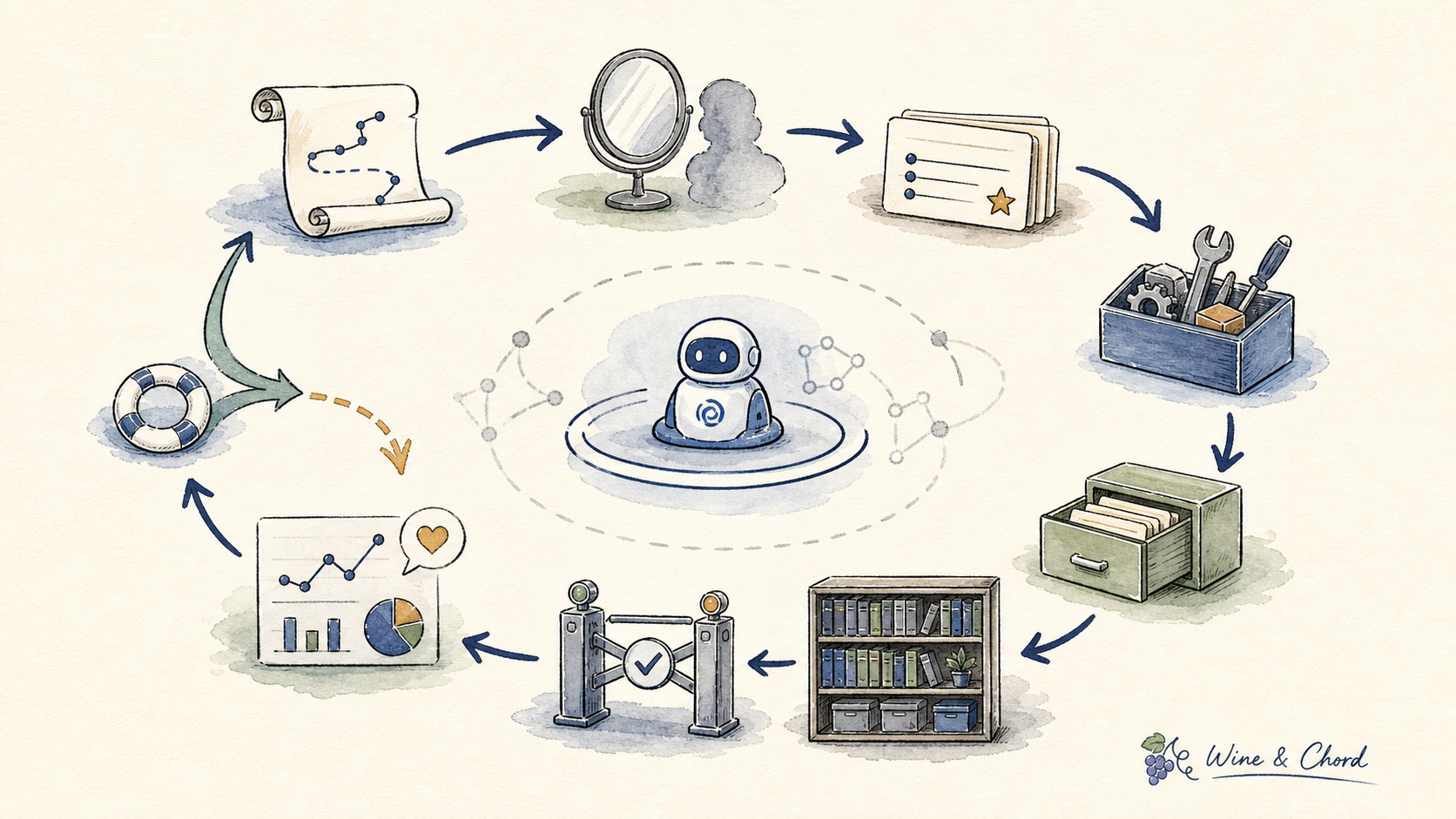
自进化至少有四层:单次任务里的自我修正,跨任务的记忆与规则,可复用技能库,以及训练数据或模型权重的长期闭环。 Anthropic 的 Agent Skills 和 OpenAI Codex 的 skills 文档 都说明,经验要变成有触发条件、依赖、测试和版本边界的资产。
读什么
论文从 Reflexion、Self-Refine、Voyager 读起,再看 Cursor 的 harness 反馈闭环。
不要误读
不要把“写一段反思”当成 self-evolution。没有检索、验证、淘汰、回滚和负反馈处理的反思,会变成新的上下文污染。
4.5 Measurement:评的是轨迹,不是答案
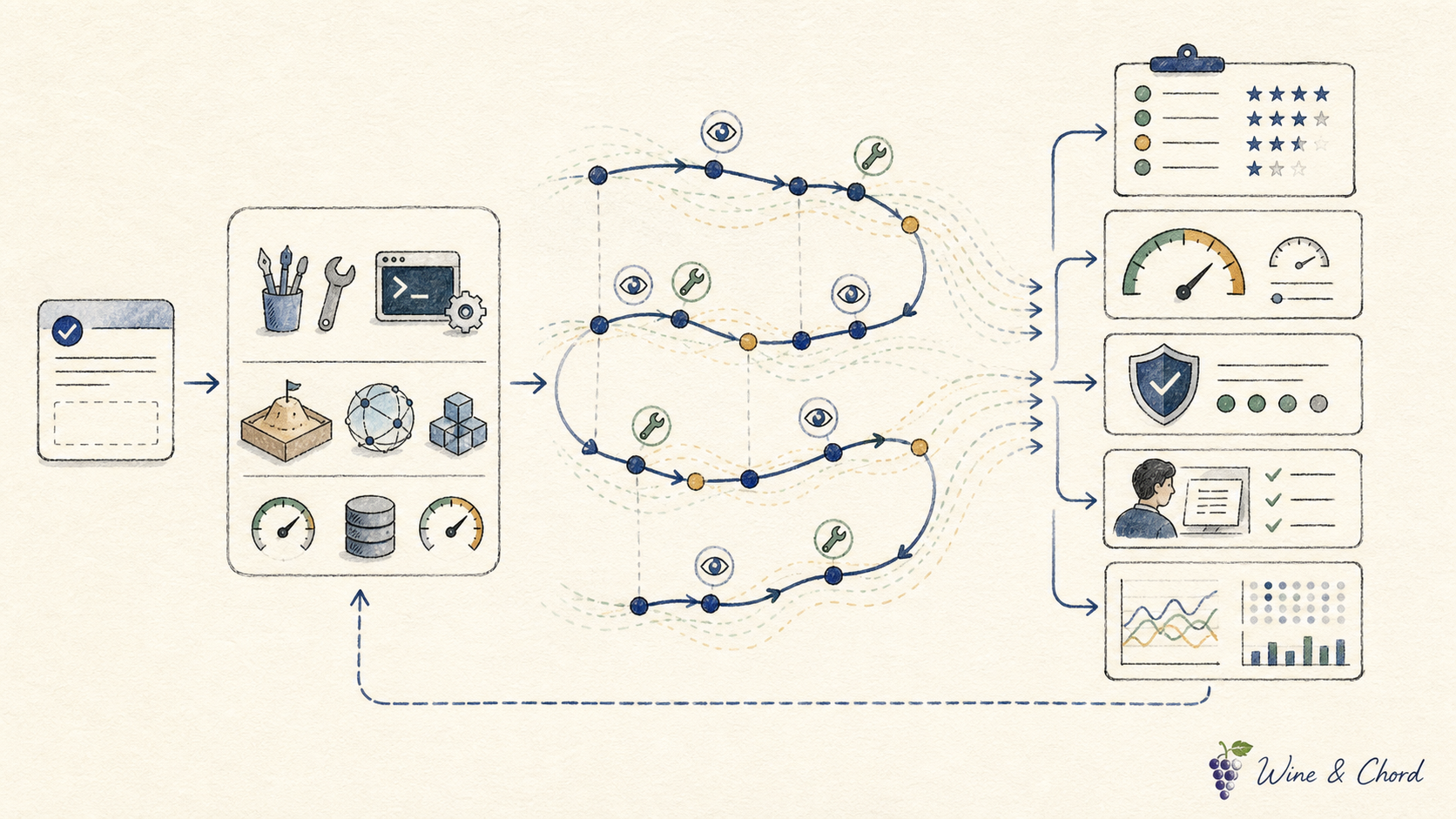
Anthropic 的 eval 文章和 infrastructure noise 文章都提醒:同一个模型在不同机器、依赖缓存、网络条件和时间限制下不是同一场考试。 SWE-bench、Terminal-Bench、tau-bench、AgentDojo 这些 benchmark 要和环境、预算、污染、重试策略一起读。报告指标时,不要只写最高分;要写样本数、预算、重试、、成本、延迟和安全回归。
读什么
先读 Demystifying evals、infrastructure noise 和 CursorBench,再读 SWE-bench、Terminal-Bench、tau-bench、AgentDojo。
不要误读
Leaderboard 是观测入口,不是上线结论。生产 eval 还要覆盖恢复能力、越权、安全、用户体验、成本和人工复核样本。
4.6 Harness:把能力接成交付路径
Harness 是把模型变成可交付系统的运行时层。OpenAI 的 Harness engineering 讨论 AGENTS.md、架构可读性、review loop、merge 和垃圾回收;Cursor 的 harness 文章展示产品如何围绕真实反馈持续改进。 12-Factor Agents 的规则也指向同一件事:应用应该拥有 context、prompts、control flow、state、tools 和 failure gates。
读什么
先读 OpenAI Codex harness、Harness engineering 和 Cursor harness,再用 12-Factor Agents 检查自己的应用是否把控制流外包给黑箱。
不要误读
不要把 harness 当胶水代码。它决定输入怎样组装、工具怎样暴露、状态怎样持久化、失败怎样恢复、结果怎样验证。
五、对照表:把资料放回工程坐标
5.1 四层对照
| 阅读层 | 先问什么 | 代表来源 | 常见误判 |
|---|---|---|---|
| Provider / API contract | 公开接口允许什么,哪些只是服务端内部? | OpenAI Agents SDK、Codex docs;Anthropic Claude Code docs;Cursor Rules | 把发布新闻里的产品能力当成稳定 API。 |
| Runtime / harness | 谁持有状态,谁执行命令,谁审批越界? | Codex loop、Sandbox Agents、Managed Agents、Cursor cloud agents | 只比较模型,不比较工具和运行时。 |
| Mechanism / source pattern | context、tools、subagents、skills、evals 在链路中怎样流动? | Context engineering、Agent Skills、Cursor harness、12-Factor Agents | 把所有机制都叫 memory 或 prompt。 |
| Measurement / operation | 成功率、成本、延迟、安全、恢复和人工复核怎样一起报告? | SWE-bench、Terminal-Bench、tau-bench、AgentDojo、CursorBench | 用一次 leaderboard 分数替代上线判断。 |
5.2 选择规则
一篇资料值得放进这份书单,至少要回答一个可验证问题:状态在哪里、边界在哪里、恢复在哪里、测量在哪里。 只展示“多个 agent 互相聊天”的 demo,如果没有环境、协议、验证和回滚,只能算灵感材料,不能算工程资料。
六、常见误读
6.1 六个陷阱
- 把 agent 等同于 autonomous。 Anthropic 的分类更稳:workflow 与 agent 都是 agentic system,差别在控制流由代码预设还是由 LLM 动态决定。
- 把 ReAct 当作完整架构。 ReAct 是行动循环的经典论文,不包含现代产品所需的沙箱、权限、状态、恢复、评测和发布路径。
- 把长上下文当作免维护。 长窗口仍有 attention budget、context rot、缓存、成本和噪声问题。
- 把 subagent 当作并行聊天。 subagent 的核心是隔离上下文、工具和输出 artifact。
- 把 sandbox 当成容器品牌。 沙箱是执行边界,具体可以是 OS sandbox、container、VM、remote workspace 或 provider-managed sandbox。
- 把 self-evolution 当成写总结。 没有验证、版本、回滚和淘汰机制的反思,会变成新的上下文污染。
七、可迁移规则
7.1 八条规则
- 先确定 agent 的状态边界,再讨论 prompt。
- 把动态事实放在可替换层,把长期规则放在可审计文件或配置里。
- 任何 subagent 都必须有输入契约、工具契约、输出 artifact 和合并规则。
- 沙箱默认收紧文件、网络、凭证和资源;例外通过 approval 或 rule 表达。
- 把工具输出当成不可信输入处理,保留 receipt 和可复核 trace。
- 把经验沉淀成 rule、skill 或 eval 前,先写触发条件和反例。
- 评测报告必须同时写任务分布、环境、预算、重试、成本、延迟和安全边界。
- Harness 要允许模型升级,但不要让模型升级改写状态机、权限模型和发布门禁。
八、References
8.1 公司与文档
- OpenAI: A practical guide to building agents、Agents SDK、Sandbox Agents、Codex changelog。
- OpenAI Codex: Unrolling the Codex agent loop、Unlocking the Codex harness、Harness engineering、Symphony。
- OpenAI Codex docs: AGENTS.md、Sandbox、Subagents、Agent Skills。
- Anthropic: Building effective agents、Effective context engineering for AI agents、Demystifying evals for AI agents。
- Anthropic Claude Code and harness: Claude Code sandboxing、Code execution with MCP、Agent Skills、Managed Agents。
- Cursor: What we’ve learned building cloud agents、Continually improving our agent harness、CursorBench、Rules。