Preview edition · Verified on 2026-05-24
DeepSeek V4 模型技术大全
这是一页面向初学者的技术书稿:先从「为什么 token 上下文很难」讲起,再逐层拆开 DeepSeek V4 的混合注意力、MoE、mHC、Muon、训练稳定性、推理缓存、后训练与评测。

Zero Chapter
先从第一性原理看懂 DeepSeek V
初学者最容易被模型名、参数量、benchmark 和一堆缩写吓住。先把它们放下,大语言模型最朴素的任务只有一句话: 已经看到一串 token ,预测下一个 token 的概率分布 。如果模型能在无数文本、代码、公式、工具轨迹中反复做好这件事,它就学到了语言、知识、推理和行动模式。
DeepSeek V 的复杂之处,不是它换了一个完全陌生的目标,而是它把这个目标推到 token 上下文、超大 MoE、真实 agent 工具链和多阶段后训练里。换句话说,本章要先回答: 一个 token 怎样变成向量,向量怎样互相“看见”,历史怎样缓存,专家怎样被选择,分数怎样变成概率,训练怎样把错误压低,最后这些基础件为什么会导向 CSA/HCA/SWA、mHC、MoE、OPD 这条 V 技术路线。
是词表, 是词表大小; 是 hidden size。token 本身只是编号,embedding 矩阵 像一本查表词典:给定编号 ,取出一条连续向量 。从这一刻开始,模型处理的就不是文字,而是矩阵 。
离散符号变连续向量
文本先被 tokenizer 切成 个 token,再查表成 的向量矩阵。这个步骤决定了模型能读哪些基本符号,但还没有发生理解。
注意力让位置互相读取
每个位置都生成 query、key、value:query 问“我需要什么”,key 贴“我是什么索引”,value 存“我能贡献什么内容”。长上下文难,首先难在这里。
FFN/MoE 加工每个位置
注意力负责“取信息”,FFN 负责“加工信息”。MoE 把加工器拆成很多专家,每个 token 只调用少量专家,让容量大但计算稀疏。
logits 变概率,再用 loss 纠错
最后一层给词表里每个 token 一个分数。softmax 把分数变成概率;loss 衡量“真实下一个 token 的概率够不够高”。
Attention:为什么上下文一长,普通 Transformer 会变贵
一层 attention 的核心公式如下。令输入矩阵为 , 单个 head 的维度为 :
是 causal mask,保证第 个位置不能偷看未来。矩阵 表示每个位置和每个历史位置的相关性,所以 prefill 的主要注意力成本近似是 。当 时,问题不只是“能不能塞进去”,而是“每一步读它要花多少钱”。
推理时还有第二个瓶颈: cache。 生成第 个 token 时,旧 token 的 不会变,所以系统会缓存它们,避免重复算历史投影。 但新 query 仍要读取历史的 ,单步注意力约为 ,cache 规模近似为:
这里的 来自 和 两份缓存, 是层数, 是 KV heads, 是每个数的存储字节。DeepSeek V 的 CSA/HCA/SWA 正是在改写这个式子:减少需要精确保存和精确读取的历史数量。
FFN 与 MoE:为什么“参数多”不等于“每步都算完”
普通 Transformer block 里,attention 之后通常接一个 FFN。可以把 FFN 理解成“对每个位置单独做的非线性加工”:
MoE 把一个大 FFN 拆成 个 routed experts 和 shared expert。 router 给每个 token 的每个 expert 打分 ,只选 个 routed experts。V 的核心直觉是:总容量可以很大,但每个 token 的激活计算只走小子集。代价是路由必须稳定,否则会出现 hot experts、跨设备通信拥塞和 loss spike。
Logits、softmax、loss:模型到底怎样“学会”
每一层都在更新 hidden states,最后模型把当前位置的向量 投影到整个词表,得到 logits :
如果真实下一个 token 是 ,训练就提高 ,压低不合适 token 的概率。 预训练得到 Base 模型;后训练再用 SFT、RL 和 distillation 把“会续写”变成“会遵循指令、会用工具、会在预算内推理”。
Post-training:为什么 V 不只靠一个统一 RL
预训练的目标很宽:它学习世界上各种 token 序列的统计规律。后训练的目标更具体:让模型在聊天、数学、代码、agent、工具调用等场景中行为可靠。 最朴素的 SFT 是“看正确答案并模仿”:
SFT 像带答案的练习;RL 像按 reward 调整行为;OPD 则像让一个学生模型在自己的 rollout 上吸收多个 teacher 的完整词表分布。这里的 是分布差异,不只是“下一个字对不对”。这就是为什么 V 的后训练路线要和长上下文、工具轨迹、reasoning effort 一起理解。
| 第一性原理问题 | 数学对象 | 普通做法的瓶颈 | DeepSeek V 路线 |
|---|---|---|---|
| 文字怎样进入模型? | token 只是离散编号,必须变成可微分的向量才能训练。 | 保留标准 embedding,把后续难点集中到长上下文注意力、MoE 和训练稳定性。 | |
| 当前位置怎样读取历史? | prefill 成本约 ,decode 仍需按历史长度读取。 | CSA 用 压缩后稀疏选择,HCA 用 重压缩保留全局视图,SWA 处理最近窗口 。 | |
| 历史为什么会占显存? | cache 随 线性增长,长 agent trace 会持续堆积。 | 混合 存储、压缩块、局部窗口和 prefix cache 共同降低长历史服务成本。 | |
| 每层怎样加工信息? | Dense FFN 容量越大,每个 token 的计算也越大;MoE 又会引入路由不均。 | DeepSeekMoE 用少量激活 experts 扩容量,再用 auxiliary-loss-free balancing、sequence-wise balance、Hash routing 等机制稳住路由。 | |
| 为什么深层训练容易不稳? | 很深的残差传播可能放大噪声或让某些路径主导。 | mHC 用受约束的多 residual stream 混合,把表达能力和稳定传播一起考虑。 | |
| 模型怎样输出答案? | Base 只学 next-token distribution,不自动等于好助手或好 agent。 | 后训练把 SFT、RL、domain specialists 和 OPD 串起来,让统一模型吸收多种能力分布。 |
业界/全网讨论视角:只作为解读,不当官方事实
下面几条是评论文章的阅读角度,不是 DeepSeek 官方技术报告本身。它们适合帮助初学者理解“大家为什么关注 V”,但不能替代官方论文、模型卡和实际评测。
观点一:长上下文要为 agent workloads 服务
Hugging Face blog 的解读重点是: context 真正有价值的场景不是把窗口数字写大,而是让长时间运行的 agent 在工具调用、代码仓库、终端输出和多轮轨迹里仍能负担注意力与 cache 成本。
观点二: context 不是 magic
Syntax Dispatch review 强调: 能放入 token 不等于模型拥有长期记忆、判断力或真实性。长窗口是容量, 不是自动检索、自动验证、自动不幻觉。
观点三:关键是 efficient long-horizon computation
Medium review 的解读是: million-token context 的核心不是更大的窗口本身,而是长期轨迹上可承受的计算、缓存、路由和后训练合成;这和 V 把 CSA/HCA/SWA、MoE/mHC、Muon、OPD 放在同一系统里是一致的阅读线索。
Spec
读者契约:这不是新闻摘要,而是一张技术地图
新闻摘要通常回答“今天发布了什么”;技术地图要回答“这个系统由哪些部件组成、每个部件解决什么瓶颈、哪些结论来自官方、哪些只是工程背景或评论解读”。 本页按第二种方式写:把 DeepSeek V 的公开材料拆成模型族、架构、mHC、attention、MoE/MTP、training、systems、inference、post-training、evaluation、interview、limits、glossary、citations 这些路标。 读者不需要先懂所有术语;你只需要沿着路标看清一条主线:当上下文被推到 token,普通 Transformer 的注意力成本、缓存成本、路由成本和训练/后训练组织方式都会一起改变。
这个式子是本章的契约:本文的结论集合 只能落在公开来源的并集里;后续 个章节负责把这些来源拆开解释。所谓“全”,是覆盖公开材料里的全部核心技术点,不是凭空补齐未公开的 kernel、数据清洗规则、线上调度策略或私有评测细节。
本文承诺
每个关键名词都给出“为什么有它、它输入输出什么、它如何降低成本或稳定训练”。例如 、 、、 不只是一组参数数字,而是理解 MoE “总参数大、每 token 激活少”的入口。
本文不承诺
不把评论文章当作官方事实;不把 DeepSeek/Tile-AI/FlashMLA//TileLink 的相关工程背景误写成 V 论文命名模块; 不把 context 解释成 magic memory。长窗口只是容量,能否用好还取决于 decode 读历史成本、 cache、检索行为和任务验证。
事实分层
章内会显式区分 官方明确、相关实现、系统背景、本文推断。 如果一个结论只能从 、、 这类机制推出,它就会被写成解释或推断,而不是官方公告。
数学记号
所有数学符号、模型参数、token 数、上下文长度、数值区间、矩阵/向量、概率分布、复杂度、算子、损失函数、量化精度和评测指标/分数都用 LaTeX/KaTeX 表达; 例如 、、 、、 、、 和 。
读分方式
评测分数只在同一设置下比较: 不能和 混比, reasoning budget 会改变表现,、CorpusQA 和 LongBench-V 也不是同一种长上下文任务。
后文串联
家族表回答“有哪些模型”;架构章回答“骨架怎么变”;mHC、attention、MoE/MTP 回答“每个 block 怎么工作”; training、systems、inference、post-training 回答“怎么训、怎么跑、怎么合成能力”;evaluation、interview、limits、glossary、citations 回答“怎么判断和复述”。
覆盖矩阵:每一章在地图里的位置
| 公开材料范围 | 后续章节 | 核心问题 | 证据层级与边界 |
|---|---|---|---|
| Introduction、model downloads、model cards、config | 模型族、总览 | V 有哪些模型,Pro/Flash、Base/Post-trained 如何区分? | 官方明确 参数、上下文、量化和 checkpoint 名称可当事实;不要从页面下载量推导模型质量。 |
| Architecture | 总架构、mHC、attention、MoE/MTP | 为什么 token 不只是扩大位置编码,而要同时改 、mHC、MoE 和 MTP? | 官方明确 结构图、压缩率、层型和公式是事实;本文推断 负责把瓶颈从 讲到可服务化成本。 |
| Pre-Training | 预训练、训练稳定性 | 这么大的 MoE 如何用 数据稳定训练,并在 阶段切换注意力策略? | 官方明确 Muon、Hash routing、、 bias update 和 sequence-wise loss;不猜未公开数据配方。 |
| General Infrastructures | 系统工程、推理与缓存 | 训练框架、推理框架、DSec、 cache 和 prefix cache 如何支撑长上下文服务? | 官方明确 报告里的系统设计可当事实;系统背景 、TileLang、FlashMLA、TileLink 只帮助理解工程约束。 |
| Post-Training | 后训练 | SFT、RL、domain specialists、OPD、GRM、Quick Instruction 如何把多个能力分布合成一个可用模型? | 官方明确 OPD 和训练流程可讲公式;本文推断 解释 为什么是系统问题。 |
| Evaluation / Real-World Tasks | 评测 | 哪些能力强,哪些场景仍有缺口,怎样读 、、? | 官方明确 报告表格/图可以引用;业界博客里的“强/弱”判断只能当测试假设,不能替代复现评测。 |
| Limitations、Future Directions、术语和引用 | 面试考点、限制与方向、术语表、参考资料 | 怎样把复杂系统讲成可复述的答案,同时知道哪些边界不能越过? | 官方明确 作者列出的限制优先;本文推断 只把前文机制整理成面试路径和术语索引。 |
资料层级:什么能当事实,什么只能当线索
| 层级 | 可以作为事实的范围 | 不能误用的边界 |
|---|---|---|
| 官方技术报告 | 模型目标、架构模块、训练阶段、推理系统、后训练流程、评测设置、限制与未来方向。 | 不能据此补写未公开实现细节,例如完整数据清洗规则、私有线上调度策略或没有披露的 kernel 参数。 |
| HF model cards/config/encoding | checkpoint 名称、参数规模、context 长度、量化形态、config 字段、tokenizer/encoding 与 special tokens。 | 不能把 config 字段存在直接解释成某个训练效果;也不能把托管页面的展示大小等同于完整理论参数量。 |
| Transformers implementation notes | 开源 Transformers 里 DeepseekV4Config、layer type、cache API、forward 输入输出等公共实现接口。 | 不能把通用库实现当作 DeepSeek 生产推理栈;库里的 接口只说明兼容形式,不等于线上缓存布局。 |
| DeepSeek/Tile-AI/FlashMLA//TileLink 背景 | 相关 kernel、存储、tile 编程、计算通信重叠、文件系统和 sandbox 约束如何影响长上下文系统设计。 | 除非报告点名,否则不能把这些仓库或论文直接写成 V 架构组件;它们是边界说明和工程直觉。 |
| 业界评论/博客 | 帮助观察社区在讨论什么: context 是否实用、efficient attention、agent workloads、成本和可用性。 | 不能当官方事实或独立评测结论;评论只能产生问题清单,事实仍要回到 核对。 |
阅读路径: 类读者各自怎么读
初学者
路径是基础概念 模型族 总架构 attention 术语表。 目标不是背名词,而是先理解 next-token probability 、注意力矩阵 和 cache 为什么会随 变贵。
工程读者
路径是 attention systems inference post-training。 重点看 如何改变 cache 形状, 和 prefix cache 为什么服务长前缀,OPD 的 full-vocabulary 为什么会变成吞吐问题。
研究读者
路径是 architecture mHC MoE/MTP training evaluation。 重点看 mHC 的 doubly stochastic 约束、Muon、Hash routing、、MTP 和 OPD 是否真的组成一个可扩展的训练路线。
面试读者
路径是 spec 总架构 面试考点 limits glossary。 答题时先给瓶颈 或 ,再讲模块,最后讲边界:官方明确、相关实现、本文推断不要混成一句话。
评论与全网讨论:只作为解读层
Hugging Face blog
Hugging Face blog 把关注点放在 agent workloads:长时间工具调用、代码仓库、终端输出和多轮轨迹会不断拉长 ,所以问题不是“能不能放下 token”,而是每一步还能否负担 attention 与 cache。
Syntax Dispatch review
Syntax Dispatch review 的有用提醒是:context length 不是 memory、judgment 或 truth。它可以容纳更多证据,但不能自动保证检索到关键段落、自动验证事实或自动避免 hallucination。
Medium review
Medium review 常见的解读角度是: token context 的重点是 efficient long-horizon computation,也就是 CSA/HCA/SWA、MoE/mHC、Muon、OPD 和系统缓存共同决定可用性。
如何使用这些评论
评论适合生成阅读问题,例如 是否实用、agent 成本是否下降、Flash/Pro 如何取舍; 但最终判断必须回到官方报告、HF config、Transformers notes 和可复现评测。换句话说,评论是 ,不是 。
Family
模型族、规格、选型与配置边界
读 DeepSeek V 先不要从“哪个最强”开始,而要先分清两个正交维度: 规模维度是 Flash 与 Pro,训练阶段维度是 Base 与 post-trained。Flash / Pro 决定大体容量、激活参数和架构宽深; Base / post-trained 决定它是不是已经过对话、推理、工具和偏好对齐训练。官方 HF model card、 DeepSeek-V report 和 Transformers DeepSeek-V docs 可以作为 checkpoint、下载入口与配置字段的事实来源;“什么时候该用哪个”是本文把这些事实放到工程场景里的归纳,不是官方对成本、延迟或效果的绝对承诺。
MoE 模型像一座很大的专家库。 是仓库里所有专家和公共路径的总容量; 是一个 token 实际走过的参数量。Flash 的 / 和 Pro 的 / 不能横向只看前者或只看后者;总参数影响模型可储存的知识与技能边界,激活参数更接近单 token 的主干计算量,但真实延迟还受 batch、 、硬件、kernel、缓存命中和服务编排影响。
模型族矩阵:四个 checkpoint 不是四个孤立模型
| 模型 | 总参数 | 每 token 激活 | 上下文 | 公开精度 | 下载入口 | 该关注它的场景 |
|---|---|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | token | mixed | HF / ModelScope | 研究预训练底座、架构消融、Base benchmark;不要把它当默认聊天模型。 | ||
| DeepSeek-V4-Flash | token | mixed | HF / ModelScope | 优先评估成本、吞吐、低延迟和长上下文可用性的应用;能力边界仍要用自己的任务集测。 | ||
| DeepSeek-V4-Pro-Base | token | mixed | HF / ModelScope | 研究最大 Base 的知识、语言建模与长上下文底座能力;适合做后训练前的基线。 | ||
| DeepSeek-V4-Pro | token | mixed | HF / ModelScope | 优先评估高难推理、复杂 agent、代码修复和知识密集任务;部署成本与延迟需要实测。 |
表中的下载、参数、context 与 precision 来自 HF model card 的 Model Downloads 表。一个容易误读的点是: DeepSeek-V-Pro-Max / Flash-Max 是 post-trained 模型在评测和推理中的 reasoning effort 模式, 不是这张下载表里额外的独立 checkpoint。另一个容易误读的点是:Hub 文件大小、分片数和侧边栏统计会受量化格式、元数据与存储方式影响, 不应替代官方列出的 与 。
Base 与 post-trained:差别不只是名字后缀
| 维度 | Base | post-trained | 读者应如何使用 |
|---|---|---|---|
| 训练阶段 | 主要是预训练后的 next-token checkpoint。 | 在预训练后继续经过 SFT、RL / GRPO、on-policy distillation 等后训练流程。 | 比较架构和底座能力时看 Base;做聊天、coding agent、工具调用和推理任务时先看 post-trained。 |
| 评测口径 | HF model card 的 Base 表按固定 benchmark 与 shots 报告,例如 : Flash-Base 为 ,Pro-Base 为 。 | post-trained 表按 Non-think / High / Max 推理模式报告,例如 和 。 | 不要把 Base 分数和 Instruct / Max 分数当同一条件比较;prompt、thinking budget 和工具条件都改变了任务。 |
| 精度边界 |
Model Downloads 表列为 mixed;
Base 的 expert_dtype 是 。
|
Model Downloads 表列为 mixed;
post-trained 的 expert_dtype 是 。
|
不要只看 quantization_config.quant_method 的 ;
expert 权重精度要同时读 expert_dtype。
|
| 对话模板 | 不应默认具备完整聊天、工具调用和 reasoning effort 行为。 | encoding README
说明了 OpenAI-compatible messages、<think>、tool calling 与 parsing 约定。
| 如果你在复现聊天或工具调用,重点看 encoding README,而不是只看权重文件。 |
Flash vs Pro:不是简单“快 / 慢”
| 配置项 | Flash | Pro | 怎么理解 |
|---|---|---|---|
num_hidden_layers | Pro 更深;同样输入要经过更多 block,容量通常更大,延迟也可能更高。 | ||
hidden_size | Pro 每个 token 的主隐藏向量更宽;这影响表示容量和矩阵乘规模。 | ||
num_attention_heads / num_key_value_heads | 这是 Transformers 实现读取 attention 形状的字段;不要把它直接等同于论文里所有混合注意力分支的工程缓存布局。 | ||
n_routed_experts / n_shared_experts | Pro 的专家池更大;每个 token 仍只选部分专家,而不是把所有 experts 都算一遍。 | ||
num_experts_per_tok | 两者每个 token 选择的 routed experts 数相同,所以差别不只是“Pro 多选专家”。 | ||
moe_intermediate_size | Pro 的单 expert FFN 中间维度更大,专家内部计算也更重。 | ||
index_topk / index_n_heads | 长上下文检索式索引相关字段;Pro 的候选规模更大,但它不等于“能无损理解所有历史”。 | ||
routed_scaling_factor | 路由权重缩放不同;这属于 checkpoint 配置事实,不应直接推导成固定质量差距。 |
因此,“Flash 更便宜、Pro 更强”只能作为初始假设。业界讨论常把 Flash vs Pro 放在成本、延迟、能力三角里:Flash 的 activated params 更适合先做吞吐和预算验证;Pro 的 activated params 和更大专家池更适合高难任务候选。 但这仍是解读层:真实选择要看你的 、输出长度、工具调用次数、batch、硬件、服务实现和失败成本。
读 config.json:哪些字段是事实,哪些不是结论
| 字段 | 公开值 | 第一性原理读法 | 常见误读 |
|---|---|---|---|
model_type / architectures | deepseek_v4 / DeepseekV4ForCausalLM | 告诉 Transformers 用哪个模型类装载 causal LM。 | 它只说明实现入口,不等于完整训练 recipe。 |
max_position_embeddings | 这是 checkpoint 配置里的最大位置上限;model card 简称为 context。 | context length 不等于有效长程推理能力;能放下历史,不代表能稳定检索、归因和推理所有历史。 | |
vocab_size | 这是 config 的精确词表大小;encoding README 说明消息如何被拼成 prompt,再交给 tokenizer。 | 不要用报告或文章里的简称反推精确 vocab size,也不要从 special tokens 列表反推出完整词表。 | |
rope_scaling | 说明位置编码扩展的实现参数;它和混合注意力共同服务长上下文。 | 不要把 RoPE scaling 单独当成 token 可用性的全部原因。 | |
compress_ratios / sliding_window | pattern, window | 这些字段对应不同层的压缩 / 滑窗注意力配置,和报告里的 CSA / HCA / SWA 路线相关。 | 不是 context length; 也不是“这一层失效”,要结合实现读。 |
quantization_config | 说明大部分权重的 量化格式和 block scale 形状。 | post-trained 模型仍要看 expert_dtype,因为 experts 是 。 | |
expert_dtype | Base: ;post-trained: | 这正好对应 model card 的 Base mixed 与 post-trained mixed。 | 不要把“config 里有 ”简化成“整个模型都是 ”。 |
num_nextn_predict_layers | 和 MTP / next-token prediction 扩展有关;后文会解释为什么训练时预测多个未来 token 能改善表征。 | 不要把它读成推理时一定一次输出多个 token 的 API 承诺。 |
第一行是 HF model card、HF config.json 和报告可以直接支撑的事实;第二行是工程结果。很多争论,例如
token context 是否“实用”、Flash 是否足够、Pro 是否值得,实际都落在第二行。
这也是为什么同一个 checkpoint 在不同服务栈里会呈现不同延迟、吞吐和失败模式。
怎么选:把任务先归类,再选 checkpoint
| 你的目标 | 优先关注 | 理由 | 边界 |
|---|---|---|---|
| 读论文、做架构分析、复现 Base benchmark | Flash-Base / Pro-Base | Base 更接近预训练底座,可以减少后训练对行为的干扰。 | Base 不是默认 assistant;不要用聊天体验评价 Base 的完整能力。 |
| 做普通对话、工具调用、coding agent、复杂推理 | Flash / Pro | post-trained 模型才匹配 encoding README 里的对话、thinking 与 tool calling 格式。 | 不同 reasoning effort 改变输出成本和分数;例如 、 不能脱离预算看。 |
| 预算敏感、请求量大、先验证产品闭环 | Flash | activated params 和较小结构通常更容易做吞吐优化。 | “更便宜 / 更快”是工程倾向,不是跨硬件、跨上下文、跨任务的绝对结论。 |
| 知识密集、高难数学代码、长链 agent、多工具任务 | Pro | total params、 activated params、更深更宽的配置给了它更高上限。 | 上限不等于每个业务 prompt 都赢;需要用你自己的 、失败率、延迟和成本指标验收。 |
| 尝试 token 长上下文 | Flash 与 Pro 都要测 | 两者 config 都给出 ;报告强调混合注意力降低长上下文 FLOPs 与 cache。 | 长 context 是容量上限,不是检索质量、证据引用和长程推理正确性的保证。 |
资料来源怎么分层
DeepSeek-V report 用来确认架构、训练、系统与 benchmark 口径; Pro / Flash HF model cards 用来确认模型族表、下载入口、precision 与评测表; Pro config / Flash config / Base config 用来确认装载字段和 checkpoint 形状。
社区讨论怎么放进来
Flash vs Pro 的成本 / 延迟 / 能力折中、 context 是否实用、Base 与 Instruct benchmark 是否可比, 都是业界常讨论的问题。本页会把这些当成解读问题,而不是把社区结论写成官方事实。
Transformers docs 的边界
Transformers 文档说明 DeepseekV4Config、模型类和缓存接口如何在通用库中表达;它适合帮助你读字段,
但不能替代 DeepSeek 线上服务栈,也不能证明某个部署一定达到报告中的吞吐或 cache 比例。
最容易记错的三句话
总参数不等于 activated params; context 不等于 token 都能被完美推理;Flash / Pro 的差别不是一个“快慢开关”,而是一组规模、专家、索引和后训练预算的共同结果。
Architecture
总架构:一个 Transformer 骨架,五个瓶颈一起改
DeepSeek V 不是“普通 Transformer 加一个更大的 RoPE”。 更准确的说法是:它保留 decoder-only Transformer 的主干 , 但在每个 block 内把长期瓶颈拆成 residual mixing、 hybrid attention、 、 training signal 和服务侧 cache 组织来共同处理。 这条主线来自 DeepSeek-V 技术报告 的 Figure 与 Architecture 章节;HF Transformers 文档 和 config 用来确认公开字段的形状。
是总容量, 是单 token 激活参数。MoE 让二者分离,但 context 又把 attention 与 cache 成本推到前台。因此架构章必须同时看 、、 、、 和服务系统,而不能只看一个字段。

总览图:token 在 V 里怎样流动
输入与 residual streams
token 先查表为 ,再扩成 条 residual streams。mHC 不是另一个 attention,而是包住 attention/MoE site 的残差控制层。
远程、全局、局部三路 attention
负责 query-specific 远程稀疏选择, 负责强压缩全局摘要, 保留最近 个 token 的细节。
MoE 扩容量但控制通信
每个 token 调用 个 shared expert 和 个 routed experts;Hash routing 与 让容量、负载和 成本一起可控。
LM loss 与 MTP loss
prediction head 做 预测;MTP 让训练信号看向更远的 。它提升训练监督密度,但不是对外承诺“一次 API 调用吐多个 token”。
旧 Transformer vs V 架构改造
| 维度 | 普通 decoder-only Transformer | DeepSeek V 改造 | 为什么不是单点优化 |
|---|---|---|---|
| 主干 | 层 self-attention + FFN + residual。 | 仍是 Transformer block stack:Flash ,Pro 。 | 保留可扩展训练范式,让创新集中到长上下文、残差、MoE 和服务瓶颈。 |
| attention 成本 | ,prefill 约 。 | 用 压缩再 ; 用 重压缩; 补局部细节。 | context 的难点既有远程检索,也有全局摘要和近邻 token 依赖,单一稀疏或单一滑窗都不够。 |
| cache | 随 线性增长,decode 每步读长历史。 | Shared MQA、压缩 、SWA state cache、混合 存储共同降低 cache。 | 如果只扩 RoPE,位置能编码,但 cache 仍然大;如果只压 cache,最近细节和服务命中策略又会出问题。 |
| 残差传播 | 一条 residual stream。 | , 被 Sinkhorn 投影到 doubly stochastic manifold。 | 更深、更宽、MoE 更稀疏时,信号传播不稳会放大路由和 attention 噪声;mHC 是稳定主干的一部分。 |
| FFN 容量 | Dense FFN:容量上去,单 token 计算也一起上去。 | DeepSeekMoE:Flash ,Pro ,每 token 激活 routed experts + shared expert。 | MoE 带来容量,但也带来专家热点、跨设备通信和路由稳定性问题,必须和训练/系统一起设计。 |
| 训练信号 | 主要是 next-token loss:。 | 继续使用 MTP:,额外预测未来 token,增强 block stack 的监督密度。 | 长链推理和 agent 轨迹很长,只靠近邻 next-token 监督容易信号稀薄;MTP 是训练目标,不是推理 API。 |
Flash / Pro 架构参数速查
| 配置项 | Flash | Pro | 读法 |
|---|---|---|---|
| Transformer layers | Pro 更深;mHC 要在更长 block stack 里控制残差传播。 | ||
| hidden size | Pro 更宽;attention projection、MoE expert 和输出混合都更重。 | ||
| attention heads / heads | 多 query head 共享 个 compressed head,配合 shared MQA 降低 cache。 | ||
| head dim / RoPE dim | partial RoPE 比例为 ,位置编码只占 head 的一部分。 | ||
| CSA / indexer heads | CSA 不直接看所有远程压缩块,而是由 Lightning Indexer 选出 query 相关的块。 | ||
| output groups / output rank | grouped output projection 把 个 head 分组低秩混合,控制输出投影规模。 | ||
| routed / shared experts | 每层都有 个 shared expert;routed expert 池越大,路由平衡越重要。 | ||
| activated routed experts / token | 单 token 不会计算所有 experts;总参数不能当成单 token compute。 | ||
| expert intermediate size | Pro 的单 expert FFN 更宽,容量和计算都更大。 | ||
| mHC expansion / Sinkhorn iterations | 多 residual stream + doubly stochastic 投影是每个 block 的结构约束。 | ||
| MTP depth | 末尾额外预测模块提供训练信号;Transformers 文档也标注 upstream checkpoint 有该层但通用实现不一定实例化。 |
、layer types 与模块位置
初学者最容易把配置数组读乱。可以把
看成“每个 attention site 用哪种历史读取方式”的 schedule:
代表 pure ,
代表 ,
代表 。
HF config.json 里它有 个条目:前
个对应 Transformer layers,最后一个
对应末尾 MTP module。Transformers 文档暴露的
layer_types / compress_rates 视图方便实现装载,但它不是完整训练框架或线上推理系统。
| 模型 | 公开 schedule | 前 个条目怎样读 | 最后 个条目 |
|---|---|---|---|
| Flash | 前 层 pure ;随后 与 交错;第 层为 。 | MTP module 使用 ,不要误读成第 个 Transformer block。 | |
| Pro | 前 层为 ;随后 与 交错;第 层为 。 | MTP module 使用 ,说明额外预测模块有自己的轻量路径,不代表 Pro 少一层。 |
Hybrid Attention:三类历史读取方式为什么要一起存在
适合“远处很多,但当前 query 只需要一小部分”的场景; 适合“全局背景要有,但不能保留全部细节”的场景; 适合“最近 token 不能被压坏”的场景。 三者拼起来,才有机会让 的读历史成本从“全量扫描”转成“压缩、检索、局部保真”的组合。
| attention 内部件 | 数学位置 | 解决的具体问题 | 本章只需要记住 |
|---|---|---|---|
| Shared MQA | 多个 query heads 共享一个 compressed 入口,减少 cache 和内存带宽。 | 这是 attention 表示和 cache 设计的一部分,不是 MoE router。 | |
| query / RMSNorm | 稳定 attention logits,降低极长上下文下的数值爆炸风险。 | 这是 CSA/HCA 的 query 与 compressed entry 归一化,不是普通 layer norm 的简单重复。 | |
| partial RoPE | 只让一部分 head dimension 承担位置旋转,减少位置编码对 shared 表示的干扰。 | 扩位置范围;partial RoPE 决定每个 head 里哪些维度带位置。 | |
| Attention Sink | 允许某个 head 不把全部注意力质量强行分给历史 token 或压缩块。 | 它是每个 head 的可学习 sink logit,能降低无关历史带来的噪声依赖。 | |
| Grouped output projection | attention heads 很多时,把输出侧混合拆成 组低秩路径,控制投影参数和计算。 | Flash ,Pro ;它是 output projection,不是 expert group。 |
mHC:为什么 residual 也要进总架构图
普通 residual connection 把层输入加回层输出,目的是让深层网络不丢信号。V 的问题更难: attention 在压缩/稀疏,MoE 在分专家,模型又很深;如果 residual path 自身不稳定,后面的 router、attention logits 和 loss 都会被噪声放大。 mHC 的角色是把单条 residual stream 扩成 条,并在每个 attention site 与 MoE site 前后做受约束的 stream mixing。
决定子层前怎样从多条 stream 取输入, 决定子层输出怎样写回, 决定旧 residual streams 怎样互相传播。 Sinkhorn-Knopp 让 行列归一, 是公开配置中的迭代次数。细节留给 mHC 章;本章只要记住它包住的是 attention/MoE site,不是替代它们。
DeepSeekMoE、Hash routing 与 noaux balance 的位置
attention 负责“从历史取信息”,MoE 负责“加工当前位置信息”。V 延续 DeepSeekMoE 的总思路:大 expert 池提供容量,每个 token 只激活小子集。 但 很大时,router 不能只追求概率最高;它还必须让各专家负载、跨设备通信和训练 loss 都可控。
前 个 MoE layers 使用 Hash routing,近似把 token id 映射到专家候选,降低早期路由冷启动风险。 后续 learned router 用 :校正偏置 影响 选择,但 gate 权重仍按原始 score 归一化。所谓 auxiliary-loss-free 不是“没有负载均衡”,而是主要不用传统 router auxiliary loss 直接压模型目标;仍有 bias update 和很小的 sequence-wise balance loss。
MTP:它在总架构尾部,不在推理 API 表面
V 继承 Multi-Token Prediction 思路,也继承了 DeepSeek-V 里把 MTP 用作训练增强的路线。 Figure 里 MTP modules 接在 prediction head 之后,产生额外 MTP loss。 这说明它提供未来 token 的训练信号,而不是把标准 causal generation 改成“每步向用户返回 个 token”的产品 API。
对初学者来说,MTP 的直觉是“同一个上下文里多问几个未来位置的问题”。这会让中间表示更早暴露长期依赖和规划信号,尤其适合很长 reasoning trace;
但部署时是否利用这些头、如何 speculative decoding,是实现问题,不应从 num_nextn_predict_layers 自动推出。
为什么这些模块必须协同设计
| 根问题 | 单独做会怎样 | V 的协同答案 |
|---|---|---|
| context 的 attention / cache 问题 | 只扩 RoPE 得到更长位置索引,但 prefill、 decode 和 cache 仍然压垮服务。 | 改历史读取形状;shared MQA、partial RoPE、混合精度 cache 和 on-disk prefix cache 改服务形状。 |
| MoE 的容量 / 通信 / 路由问题 | 只堆专家会让 增大,但 hot experts 与 通信成为瓶颈。 | DeepSeekMoE 让 大、 小;Hash routing、、bias update 与系统 EP overlap 一起稳住。 |
| mHC 的深层稳定性问题 | 只改 attention/MoE,深层 residual path 仍可能放大噪声,训练不稳定会反馈到 router 和 long-context logits。 | mHC 在 attention 和 MoE 两个 site 前后都做受约束 mixing,让多路径表达与数值稳定一起进入 block 设计。 |
| MTP 的训练信号问题 | 只用 next-token loss,长链规划和 agent trajectory 的远期依赖信号很稀。 | MTP 在 block stack 之后添加未来 token 监督;它和 context 的长轨迹目标相配,但不改变用户侧逐 token 自回归语义。 |
| systems 的可服务化问题 | 论文结构能跑小 batch,不代表线上能承载 prefix reuse、tail states、不同 layer cache policy 和长请求调度。 | V 的系统章节把 heterogeneous cache、state cache、on-disk storage、batch-invariant kernels 与模型结构配套描述。 |
官方明确报告事实
技术报告明确给出 V 保留 Transformer / DeepSeekMoE / MTP,并新增 、hybrid 、Muon 与长上下文系统设计。表格中的 来自报告和公开 config。
相关实现Transformers 边界
Transformers 文档里的 DeepseekV4Config、layer_types、compress_rates、cache API 是通用库表达。
它们帮助读公开 checkpoint,但不能替代 DeepSeek 自己的训练框架、推理框架或 kernel 选择。
业界解读长上下文不是只扩窗口
社区常把 V 解读为: context 的关键不是“RoPE 变长”一个动作,而是注意力、缓存、MoE、训练信号和系统共同设计。 这是本文的解读层,不应写成官方原话或独立评测结论。
面试最容易说错的边界
| 错误说法 | 为什么错 | 更准确的答法 |
|---|---|---|
| “V 就是普通 Transformer + long RoPE。” | 忽略了 、mHC、DeepSeekMoE、MTP 和 heterogeneous cache。 | 先说 Transformer skeleton,再说长上下文瓶颈由 attention/cache/MoE/training/systems 一起改。 |
| “FlashMLA / TileLink 是 V 架构组件。” | 它们是相关 kernel / compute-communication overlap 背景或生态线索,不是 Figure 的模型模块。 | 可以作为系统工程背景讨论,但架构组件应说 mHC、hybrid attention、DeepSeekMoE、MTP。 |
| “ 参数就是每个 token 都算 。” | MoE 的总参数 与激活参数 不同。 | Pro 是 、;Flash 是 。 |
| “MTP 是推理 API,一次返回多个 token。” | MTP 在官方总图里接在 prediction head 后作为训练目标;公开 config 的 num_nextn_predict_layers 不能推出产品 API 语义。 | MTP 是额外未来 token 监督,可支持更强表征或 speculative 路线,但不能直接当 API 承诺。 |
| “config 里的 layer types 就是全部工程实现。” | config 只描述 checkpoint 可装载形状;服务还涉及 cache layout、state cache、prefix cache、kernel、调度和精度。 | 用 读层级 schedule,用系统章节读线上可服务化。 |
章内来源与背景链接
官方事实优先看 DeepSeek-V PDF、 Pro config、 Flash config 和 Transformers docs。 背景论文可按模块回溯: DeepSeek-V 提供 DeepSeekMoE/MTP 继承脉络, DeepSeekMoE 解释专家专门化, MTP 解释多 token 训练信号, Hyper-Connections 和 mHC 解释多 residual stream 与 manifold constraint。工程评论可以帮助提出问题,但本章不把评论当官方事实。
mHC
mHC:从 residual connection 到受约束的多 residual stream
DeepSeek V 的 mHC 全称是 Manifold-Constrained Hyper-Connections。官方报告把它列为三项核心架构升级之一: CSA/HCA 改的是长上下文 attention,DeepSeekMoE 改的是每个 token 走哪些专家,mHC 改的是更底层的问题:深层网络里信息和梯度怎样沿着 residual path 稳定传播。 本章的核心资料来自 DeepSeek V PDF、 Hyper-Connections、 mHC 论文 和 Transformers DeepSeek-V docs。
先给一句直觉:普通 residual connection 是一条不收费的直达路, Hyper-Connections 把它扩成 条可交互的车道, mHC 再要求“换道矩阵”必须落在一个安全集合里。这样既能让多条 residual stream 交换信息,又不让某条路径在很多层之后把信号任意放大或吞掉。
第一性原理:为什么 residual connection 这么重要
一个深层模型不是一次性把输入变成答案,而是反复做“保留旧信息 + 加一点新变化”。最朴素的 pre-norm residual block 可以写成:
是关键。即使当前层的 一开始学得很差,旧信号仍能沿着 原样通过; 反向传播时,梯度也有一条不必穿过复杂非线性函数的通道。没有这条通道,层数 很大时,连续相乘的 Jacobian 很容易让 爆炸或消失。
但单条 residual stream 也有局限。每一层 attention 读到的远程信息、MoE 专家加工出的新特征、位置编码带来的偏置,最终都被写回同一条 。这很稳定,却也很“窄”:模型只能用一条主干同时保存原始信息、局部句法、远程证据、专家变换和下一层要用的工作记忆。 当 、、MoE 容量和上下文长度一起增大时,问题不只是“能不能表示”,还包括“多层以后哪些信号还活着、哪些路径主导了梯度”。
从 Residual 到 HC:把一条 stream 扩成多条 stream
Hyper-Connections 的出发点是:不要只有一条 ,而是维护 条 residual stream。对一个 token 来说,可以把状态看成矩阵:
是 pre-block mixing:从多条 stream 读出一条输入给子层 ; 是 residual mixing:让旧的多条 stream 互相传播; 是 post-block mixing:把子层新算出的 写回多条 stream。面试里最容易错的就是只记得 ,却说不清 分别在子层前、残差传播、子层后。
读出子层输入
attention 或 MoE
写回多 stream
旧 stream 混合
传给下一站点
对整个序列来说,真实张量形状更接近 : 是 batch, 是序列长度, 是 hidden size。mHC 的混合主要发生在 这个很小的 stream 维度上,不是在 token 维度上做 attention,也不是在 expert 维度上做路由。
为什么 HC 还不够:无约束的 会破坏恒等路径
如果 是任意可学习矩阵,单层看起来没问题,多层相乘就会出事。忽略每层的新写入项,只看旧 residual stream 如何传播:
可理解为“某个输出 stream 最多从所有输入 stream 累积多少量”,更贴近 forward signal; 可理解为“某个输入 stream 的梯度最多被多少输出 stream 汇回来”,更贴近 backward gradient。 无约束 HC 的风险是 或 在深层复合后远离 ,于是多 stream 带来的表达能力变成信号放大器或信号消音器。
mHC 的核心:把 投影到 Birkhoff polytope
mHC 不否定 HC 的多 stream 思路;它只给最危险的 residual mixing 矩阵加几何约束。约束集合是 doubly stochastic matrices,也叫 Birkhoff polytope:
行和为 表示每条输出 stream 是输入 streams 的 convex combination,不会凭空扩大总量; 列和为 表示每条输入 stream 不会被所有输出 stream 反复复制。Birkhoff-von Neumann 视角下, 又可以理解为若干 permutation matrices 的凸组合:它允许“换道”和“重排”,但不允许负权抵消或无界放大。
这个矩阵图要抓住两点:第一,doubly stochastic 不是“每行归一化”而已,列也必须归一化;第二,约束的是 这张 stream-to-stream 混合图,不是 attention 的 ,也不是 MoE router 的 expert scores。
Sinkhorn-Knopp:不是训练后处理,而是 forward 里的可微投影
神经网络实际预测的是无约束 logits 。mHC 先用指数把它变成正矩阵,再反复做行归一化和列归一化:
是数值下界,避免除以 。DeepSeek V 的配置字段里对应 、 。 这一步发生在每次 forward 的 mHC 计算中,梯度会穿过这些归一化步骤回到 ;它不是“模型训练完以后再把矩阵修一修”的离线后处理。
完整参数化: 都是动态控制量
mHC 的控制矩阵不是所有 token 共用一张死板表。它会从当前多 stream 状态生成动态映射,再叠加静态 bias 和 learnable gates:
和 采用非负、有界的 sigmoid 约束,减少正负系数互相抵消; 采用 Sinkhorn 投影,负责深层 residual 传播的稳定性。 DeepSeek V 训练中还把这类小而敏感的 scalar gates 与 biases 留在 AdamW 更新路径里;Muon 主要用于大权重矩阵的优化。
DeepSeek V 具体怎么用 mHC
官方 PDF 的总架构图把 Residual Mixing / Pre-Block Mixing / Post-Block Mixing 放在 CSA/HCA 和 DeepSeekMoE 两个子层站点周围。
Transformers 文档也把实现说成两个 DeepseekV4HyperConnection:attn_hc 包住 attention sublayer,ffn_hc 包住 MLP/MoE sublayer。
因此一个 Transformer block 的概念流程可以写成:
这里必须分清角色: 仍然负责 token 之间的信息读取, 仍然负责每个 token 的专家加工; mHC 只是包住这些站点,决定多条 residual stream 怎样读入子层、怎样接收子层输出、怎样把旧 stream 稳定传下去。它不是一种新的 attention,也不是一种新的 expert router。
| 公开字段 / 结构 | DeepSeek V 值 | 本章解读 |
|---|---|---|
| 每个 token 维护 条 residual stream。表达力来自多 stream 的可控读写,不是把 attention heads 变成 个。 | ||
| 每次生成 时做 次 Sinkhorn-Knopp 归一化,得到近似 doubly stochastic 的 residual mixing。 | ||
attn_hc | 每个 attention 站点一套 mHC 包裹 | CSA/HCA 算出的 attention 更新先通过 写回多 stream;旧 stream 同时通过 传播。 |
ffn_hc | 每个 MLP/MoE 站点一套 mHC 包裹 | DeepSeekMoE 的 expert computation 仍由 router 和 experts 决定;mHC 只控制 MoE 输出怎样注入 residual streams。 |
DeepseekV4HyperHead | 最终 collapse 条 stream | 进入 final norm 与 LM head 前,多 stream 需要合回普通序列 hidden states;这解释了为什么 mHC 是主干内部结构,不改变最终 next-token 目标。 |
普通 residual / HC / mHC 对比
| 机制 | 状态形状 | 核心公式 | 优点 | 主要风险或代价 |
|---|---|---|---|---|
| 普通 residual | 恒等路径清晰,梯度传播稳定,工程实现简单。 | 只有单条 stream,复杂特征都挤在同一条主干里。 | ||
| Hyper-Connections | 多条 stream 增加拓扑表达力,子层可以从不同 residual 组合读写。 | 若无约束,深层复合 可能放大或衰减信号。 | ||
| mHC | 保留多 stream 表达力,同时用 doubly stochastic 约束恢复近似恒等传播的稳定性。 | 引入额外 stream 存储、小矩阵乘、Sinkhorn 迭代和 recomputation 调度复杂度。 |
和 attention、MoE、训练稳定性的关系
不是 attention
attention 的核心对象是 token-to-token 权重,例如 ; mHC 的核心对象是 stream-to-stream 权重 。 两者维度、语义和成本瓶颈都不同。
不是 MoE router
MoE router 选择 experts: 。 mHC 不选择 expert,也不改变 个 routed experts 的事实;它只决定 MoE 输出怎样写回 residual streams。
服务训练稳定性
mHC 约束 、 和 , 目标是让深层 forward signal 与 backward gradient 更不容易失控。它与 Muon、RMSNorm、Hash routing、expert balancing 一起构成训练稳定性拼图。
工程意义:小维度矩阵不等于没有成本
因为 ,mHC 的额外 FLOPs 通常不会像 attention 或 MoE 那样成为主计算量;但它扩大了 residual state,增加了内存访问和训练时需要保存的中间量:
这里的关键不是“大矩阵乘很贵”,而是现代训练常被 memory bandwidth 和 activation memory 限制。DeepSeek V 的报告因此专门提到 mHC 的 recomputation、fused kernels、tensor-level activation checkpointing 和 DualPipe 边界调度。
checkpointing 的边界也要讲清楚:mHC 的 recomputation 可以减少训练时保留 、 Sinkhorn 中间值和多 stream 激活的显存;但它不是 KV cache 压缩技术,也不会替代 CSA/HCA。 推理长上下文时, cache 的主要收益来自 attention 结构和缓存策略; mHC 的主要收益仍是主干深层信号传播和训练稳定性。
这两项依赖不同:训练 activation memory 受 影响,推理 cache 主要受 和注意力压缩策略影响。把二者混为一谈,是 mHC 面试里常见误区。
业界/全网讨论视角:这是解读,不是官方事实
社区讨论 DeepSeek V 时,注意力机制、MoE 参数量和 context 更容易吸引眼球;mHC 有时会被一句“换了 residual”带过。 但从研究和工程角度看,mHC 解决的是另一个不那么显眼、却很基础的问题: 当模型很深、MoE 很大、attention 站点和 MoE 站点都在不断写入 hidden state 时,主干 residual topology 是否还能提供稳定、可训练、可扩展的信号路径。 这段是本文对公开讨论的阅读方式,不应当当成 DeepSeek 官方对社区关注点的描述。
面试易错点速查
| 常见错误 | 正确说法 | 可以用来解释的公式 |
|---|---|---|
| 把 mHC 当成多头注意力 | multi-head attention 的 head 维度是 attention 内部视角;mHC 的 是 residual stream 维度。 | |
| 把 Sinkhorn 当训练后处理 | Sinkhorn-Knopp 是 forward 里的可微归一化,V 使用 次迭代。 | |
| 只背 doubly stochastic,不解释行列和 | 行和为 控制每条输出 stream 的总输入;列和为 控制每条输入 stream 被分配出去的总量。 | |
| 说不清 | 读入子层, 混合旧 residual streams, 写回子层输出。 | |
| 把 mHC 和 MoE router 混在一起 | MoE router 选 experts;mHC 控制 residual streams。V 只是用 ffn_hc 包住 MoE 站点。 | |
| 以为 mHC 自动降低推理 KV cache | mHC 主要影响 residual topology 和训练稳定性;KV cache 降低主要来自 CSA/HCA、shared 、压缩与存储策略。 | |
| 把 checkpointing 说成 mHC 理论的一部分 | checkpointing/recomputation 是工程实现,用来降低训练显存;理论核心仍是 的 manifold constraint。 |
Attention
CSA / HCA:V4 最核心的长上下文技术
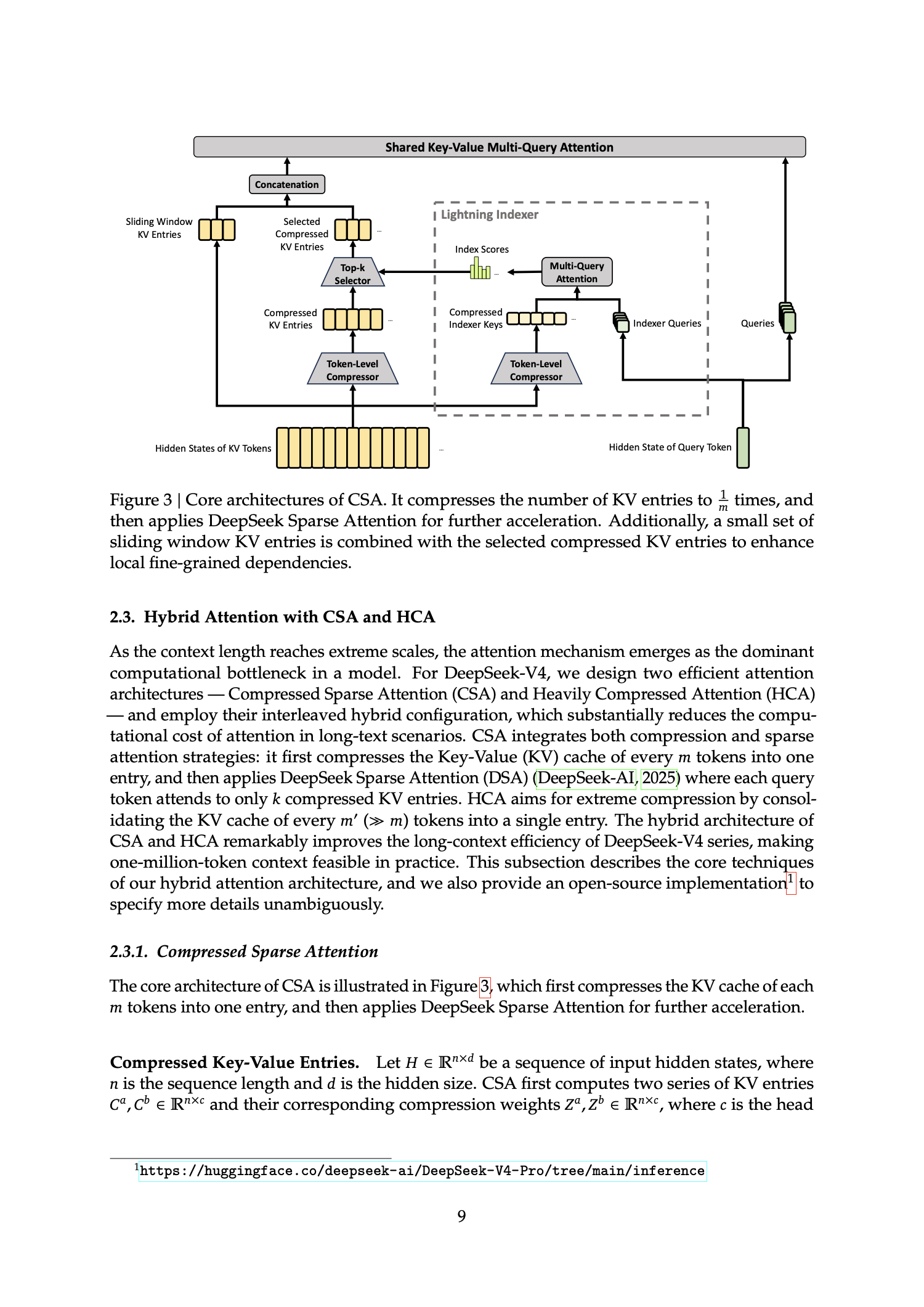
token 的上下文如果还用普通全注意力, cache 会变成推理服务的主要成本。DeepSeek V4 的答案是三种注意力层混排: 近处保留细节,远处压缩,关键远处再挑出来看。
第一性原理:普通 attention 为什么会在长上下文上失控
先忘掉所有缩写,只看一层普通 dense attention。输入是 ,每个 head 的维度是 。模型把同一份 hidden states 投影成 、、 : 表示“当前位置想找什么”, 表示“历史位置能被怎样索引”, 表示“历史位置真正贡献什么内容”。
为什么是 ? 因为 个 query 都要和 个 key 做点积,每个点积约用 维;再乘上 个 heads,就是 。这不是“实现不够优化”,而是 dense attention 的信息图本身就是 。
推理时常说有 cache,好像历史已经“解决了”。它只解决了“不要重复计算历史投影”,没有解决“新 token 仍要读历史”。 生成第 个 token 时,新的 仍要和历史 做点积,并用注意力权重读取 。
这里的 是普通结构里 与 两份历史; 是层数, 是 key/value heads, 是每个数的字节数。长上下文服务真正痛的不是只存下 ,还包括每生成一个 token 都要从显存读越来越长的 。
普通 dense attention
读取全部 。 prefill 是 ,decode 单步仍随 线性增长。
先按 压缩远程历史,再由 Lightning Indexer 对压缩块打分,取 。它解决“远处很多,但当前 query 只需要少数证据”的问题。
用 保留全局摘要; 用 保留最近局部精度。一个管全局轮廓,一个管局部细节。
因此 DeepSeek V 的核心不是“把窗口数字写成 ”这么简单,而是把历史读取拆成四个问题: 压缩减少可读条目数,稀疏选择避免每个 query 都读全部远程历史,重压缩给模型一个廉价全局摘要,滑窗保证近处不被压坏。
Sliding Window Attention 只看最近 个 token。它像短期记忆,成本稳定,负责局部细节。
CSA
Compressed Sparse Attention 先把每 个 token 压成一个 entry,再用 Lightning Indexer 选 远程块。
HCA
Heavily Compressed Attention 用更大的 把长历史重压缩,不做 选择,适合保留全局轮廓。

一张表分清每个部件到底解决什么
| 部件 | 第一性原理位置 | 系统 / cache 含义 | 面试边界 |
|---|---|---|---|
| 普通 dense attention | ,decode 仍读 历史。 | 有 cache 不等于 decode 变成常数成本。 | |
| 远程历史先变成约 个 compressed entries,再按 query gather 少数块。 | 它不是把全部历史平均压缩后 dense 读取;关键是 Lightning Indexer 的 query-specific 稀疏选择。 | ||
| 条目少到可以 dense 读所有已闭合 compressed blocks,形成廉价全局摘要。 | 不要说 是“更强 ”;它更粗,负责全局轮廓,不负责细粒度召回。 | ||
| state cache 固定保存最近窗口和未闭合 tail states。 | 不是上下文长度; 依赖压缩远程分支。 | ||
| Shared | 多个 query heads 共享一份 key/value 表示,降低 与内存带宽。 | 共享的是 和 ,不是所有 heads 只有一个 。 | |
| for query / compressed entries | 约束极长上下文下 logits 的尺度,配合 Muon 后不再需要 这类额外裁剪。 | 这是 attention 内部数值稳定措施,不是把所有层归一化都重新发明一遍。 | |
| 只有一部分 head channels 带旋转位置;压缩分支有独立 。 | 负责扩位置范围; 负责哪些维度携带相对位置。 | ||
| 给每个 head 一个可学习 sink logit,允许注意力质量不必全分给噪声历史。 | 它不是一个特殊 token;更像 softmax denominator 里的可学习“空接收器”。 | ||
| 把很宽的 attention output 先分组低秩压缩,再合并回 hidden state;Flash ,Pro 。 | 它是 attention output 的投影优化,不是 MoE expert group。 | ||
| classical cache 存已闭合 compressed entries;state cache 存 和未闭合 tail。 | prefix cache 只能复用完整压缩块;尾部不足 或 的部分要重算。 |
CSA 的完整路径
CSA 的关键是「先压缩,再选择」。V4 默认压缩率 ,也就是大约每 个历史 token 形成一个压缩 。Lightning Indexer 为每个 query 计算它和压缩块的相关性,只保留分数最高的若干块。 Flash 的 CSA 为 ,Pro 为 。 这样模型不必扫描所有远程历史,但仍能按 query 动态找回重要片段。
这条式子比普通 更接近报告描述: CSA 先生成 两条 流和 压缩权重, 再用 位置偏置与 形成重叠 token compressor;Lightning Indexer 的 head 权重 是 query-level 的; 来自与 相同的压缩操作。这里同样采用从 开始的 token index,并且只给 的已闭合 preceding compressed blocks 打分。 注意:相对位置信息主要进入压缩分支的表示,indexer 打分式本身不额外加入论文未定义的相对位置偏置项。
注意力实现细节
- Flash 的前 层使用 pure ;Pro 的前 层使用 ,后续层再交错使用 。
- query 与压缩 entries 都做 ,降低 attention logits 爆炸风险;因此 Muon 部分不再需要 。
- 只施加在最后 维;core attention 输出再做 reverse rotation,减少位置编码对共享 的干扰。
- 都带一条 分支:压缩分支负责远程历史,窗口分支保留最近 个 token 的精细依赖。
- 因果约束仍然存在:压缩条目只有在源窗口闭合后才对 query 可见;当前块和最近未压缩细节由 分支兜住。
- 混合 存储把 RoPE 维保留为 ,其余维用 ;Lightning Indexer attention compute 使用 。这与 压缩共同降低 上下文的 cache 成本。
- 输出投影采用 ;Flash 的组数为 ,Pro 的组数为 ,低秩瓶颈为 。
:只读 attention schedule,不要读成全部架构
公开 里最容易看错的是 。它是按 attention site 排列的历史读取策略: 表示 pure , 表示 , 表示 。最后一个 对应 MTP module 的 sliding-window-only 路径,不要把它当成额外 Transformer block。
这只描述第 个 attention site 读历史的方式。 、MoE、MTP、Muon、推理调度和 cache eviction 不会完整编码在这个数组里。
可以理解为:普通 output projection 直接把所有 个 attention head 的输出一次性混回 hidden state;V4 先把 head 按 组拆开,每组经过 rank 的低秩中间表示,再合并输出。这样在 或 的宽 attention 下,输出侧混合更容易控制计算和参数规模。
HCA 的完整路径
HCA 采用更激进的压缩率 ,把长历史变成极短的全局摘要。它不需要 indexer,因为条目已经很少,所有已经闭合的历史压缩块都可在因果约束下进入核心注意力。 为了避免远程摘要丢掉局部细节,CSA 和 HCA 都附加一条 sliding window 分支,把最近 个未压缩 拼进去。
这里采用从 开始的 token index。对 query 时刻 ,HCA 只暴露 的已闭合压缩块;也就是只有当某个压缩块在当前位置已经完整落在因果前缀内时才可见。 总序列尾部不足 的部分不会作为 block 提前泄漏,而是由 state cache 的 tail 状态处理。
| 机制 | 解决什么问题 | 保留什么信息 | 代价控制 |
|---|---|---|---|
| 局部语法、刚说过的内容不能被压坏。 | 最近窗口的原始 。 | 窗口固定,随总上下文长度增长很慢。 | |
| CSA | 远处内容太多,但每个 query 只需要其中一部分。 | 压缩 + query-specific 远程块。 | 压缩, 稀疏选择,indexer 。 |
| HCA | 全局背景要保留,但不能维护庞大 。 | 的重压缩全局摘要。 | 条目极少,因此无需 。 |
| Attention Sink | 有些 query 不应该把注意力强行分满到历史 token 上。 | 每个 head 一个可学习 sink logit。 | 允许总注意力质量接近 ,降低噪声依赖。 |
Shared MQA 是什么?
MQA 的意思是多个 query head 共享较少的 key/value head。V4 更进一步使用 shared :同一个压缩条目同时作为 key 和 value。 这会进一步削减 cache 和内存带宽,是长上下文推理里非常实际的工程收益。
cache / 系统含义:为什么 V 需要 hybrid layout
从模型公式看,、、 只是不同的历史读取方式;从推理系统看,它们会产生不同生命周期、不同尺寸、不同复用规则的 cache。 普通 PagedAttention 假设每层每个 token 的 条目形状差不多,而 V 同时存在已闭合 compressed entries、最近窗口 entries、Lightning Indexer entries 和尚未达到压缩边界的 tail states。
官方系统设计把 cache 分成两大类:state cache 保存 最近窗口和未闭合 tail;classical cache 保存已经能复用的 compressed entries。 因为 与 的共同边界是 个原始 token,一个 cache block 覆盖 个原始 token 时,会自然产生 个 entries 和 个 entry。
| cache 类型 | 存什么 | 什么时候可复用 | 错用后果 |
|---|---|---|---|
| compressed | 每 个 token 闭合后的 main compressed entry,以及 indexer compressed entry。 | prefix 命中时,最多读到最后一个完整 边界。 | 如果把不足 的尾部当成 compressed entry,就会引入未来信息或错误位置状态。 |
| compressed | 每 个 token 闭合后的全局摘要 entry。 | prefix 命中时,最多读到最后一个完整 边界。 | 误复用未闭合 HCA tail 会把摘要和真实因果前缀错位。 |
| state cache | 最近 个 uncompressed entries。 | 可按完整缓存、周期 checkpoint 或零缓存三种策略,在存储和重算之间取舍。 | 只存 compressed entries 不足以恢复最近局部注意力,tail 需要额外状态或重算。 |
| on-disk prefix cache | 共享前缀的 compressed entries,以及按策略保存的 状态。 | 请求共享长前缀时避免重复 prefill;compressed branch 只复用完整块。 | 把未闭合 tail 写成可复用 prefix,会让下一条请求从错误 hidden state 继续。 |
这也是为什么社区常说 context 不是 magic。 大窗口只说明位置范围允许这么长;真正让它可服务化的是 、读取带宽、cache hit、tail recomputation、kernel block alignment 和 eviction policy 一起成立。
架构超参数对照
| 配置项 | Flash | Pro | 为什么重要 |
|---|---|---|---|
| attention heads | query 并行视角数量,Pro 更宽。 | ||
| head dim | 单头表示宽度,配合 。 | ||
| heads | Shared MQA 的缓存压缩基础。 | ||
| query LoRA rank | query projection 的低秩中间维度。 | ||
| CSA compression | 细粒度远程检索的压缩率。 | ||
| HCA compression | 全局摘要的重压缩率。 | ||
| CSA | 每个 query 可取回的压缩远程块数。 | ||
| indexer heads / dim | / | / | Lightning Indexer 的检索打分容量。 |
| window | 未压缩局部细节的保真窗口。 | ||
| output groups / rank | / | / | 的低秩瓶颈。 |
| mHC streams / Sinkhorn iters | / | / | 多 residual stream 数量与投影强度。 |
官方 config.json 补充项
| 配置项 | Flash | Pro | 解释 |
|---|---|---|---|
| vocab size | 官方配置的 tokenizer 词表规模。 | ||
| max position embeddings | 等于 ,对应 token 上下文。 | ||
| RoPE base / compressed RoPE base | / | / | 普通位置旋转与压缩分支位置旋转的基底。 |
| YaRN scaling | 从原始上下文扩展到 上下文的 RoPE scaling 配置。 | ||
| RoPE head dim | 只有最后 维施加 RoPE。 | ||
| 官方 attention schedule:、、;前 个条目映射 Transformer layers,最后 个 映射 MTP module 的 sliding-window-only 路径。 | |||
| routed scaling factor | 路由专家输出的缩放系数,Pro 更大。 | ||
| MoE router method / | / | / | MoE 专家选择路径,区别于 CSA attention 的 远程块检索。 |
| SwiGLU limit | 激活裁剪上限,配合稳定性训练。 | ||
| eps / mHC eps | / | / | 归一化和 mHC 数值稳定常数。 |
| expert dtype | Base ;post-training | Base ;post-training | Base 配置使用 expert weights,后训练/部署模型使用 routed experts。 |
业界 / 全网讨论视角:这是解读,不是官方事实
官方明确 效率目标
官方 PDF 把 和 放在长上下文效率核心位置,并在系统章节讨论 heterogeneous cache 与 on-disk prefix cache。这里可以当事实引用。
相关实现 HF / Transformers
Transformers docs 把 layer types、、cache layer 和 config 字段暴露出来,适合核对 、、 和 。 但通用库实现不等于 DeepSeek 线上推理栈。
社区解读 context 不是 magic
Hugging Face blog 与 MarkTechPost 这类文章常把重点放在 agent 长轨迹、 与 long-horizon computation 上。这个角度有助于理解为什么大家关心 V, 但评论文章不能替代 PDF、config 和可复现实测。
面试深度:最容易答错的 个点
| 错误说法 | 为什么错 | 更准确的答法 |
|---|---|---|
| “ 是更强的 。” | 的 压缩更粗,信息密度更低,只是条目少到可以 dense 读。 | 负责细粒度远程召回; 负责廉价全局摘要。 |
| “ window 就是 context length。” | 只是不压缩局部窗口;它不是 。 | 长程来自 compressed branches;近程来自 。 |
| “ 是一个特殊 token。” | 它是每个 head 的可学习 sink logit,进入 softmax denominator,不是输入序列里的 token。 | 用 解释。 |
| “shared 意味着只有一个 query head。” | heads 仍有 或 个;共享的是 与 。 | 答成 ,多个 query views 读一份 shared key/value memory。 |
| “prefix cache 可以直接复用任意长度前缀。” | 和 只存完整压缩块;未闭合 tail 没有可复用 compressed entry。 | 复用到 对齐边界最自然;尾部不足块要重算或从 state cache 恢复。 |
| “ 是 V attention 架构组件。” | 是相关 kernel / 生态背景;V 架构报告的 attention 关键词是 。 | 可以谈 kernel co-design,但不要把它写进 V 的核心 attention module 名单。 |
| “ 越大就一定越好。” | 增大提高召回,但也增加 gather、attention compute 和 cache bandwidth。 | Flash 使用 ,Pro 使用 ,这是容量/成本折中。 |
| “、、 都是小 trick,可以不讲。” | 长上下文下 logits 尺度、相对位置和无关历史噪声会直接影响 sparse selection 与 core attention 稳定性。 | 研究面试要能把它们接回 的数值稳定和 cache 表示。 |
MoE / MTP
DeepSeekMoE + MTP:大容量、低激活和更密的训练信号
这一章只讲一个问题:为什么 DeepSeek V 可以把模型容量做得很大,却让每个 token 实际只激活一小部分参数。 答案不是“参数多就自动便宜”,而是把 FFN 改成 DeepSeekMoE:每层保留一个所有 token 都会走的 shared expert,再放入 个 routed experts,并让 router 对每个 token 只选 个 routed experts。MTP 则是另一条线:它不降低 MoE 计算,而是在训练时给 hidden state 增加更远未来 token 的监督。
是 total parameters,表示权重文件里总共有多少参数; 是每个 token 前向计算实际触碰到的 activated parameters。 MoE 面试里第一条边界就是:。 DeepSeek V 的 Pro 比 Flash 总容量更大、激活也更大,但两者每个 token 都只选 个 routed experts,再加上 个 shared expert。
第一性原理:dense FFN 为什么容量和计算绑死
Transformer block 里最贵的局部计算之一是 FFN。对一个 token hidden state ,普通 dense FFN 可以抽象成:
如果想让 FFN 更会记知识、更会组合特征,最直接的方法是增大 。但 dense FFN 的问题是:参数量增加多少,每个 token 的乘法也几乎跟着增加多少。 这就是容量和计算耦合。模型越大,训练更贵;推理每生成一个 token,也必须把整块 FFN 都算一遍。
MoE 的想法很朴素:不要让每个 token 都跑完整的大 FFN,而是准备很多小 FFN,让 router 判断当前 token 应该交给哪些 experts。 于是“总共能存多少能力”和“这一个 token 需要算多少能力”被拆开:
当 变大而 固定时,模型总容量可以增长,但单 token 激活计算近似不随 线性增长。代价是 router 变成系统核心:如果 router 不稳定,就会出现 hot experts、负载不均、跨设备 拥塞和 spike。
DeepSeekMoE 的一层到底怎么走
DeepSeek V 继承 DeepSeekMoE:FFN 站点包含 shared expert 和 routed experts。 shared expert 不是“所有 experts 都共享权重”,而是额外的一条通用 MLP 路径;routed experts 仍然是专家池里的独立参数。
hidden state
router logits
affinity score
select experts
gate weights
combine
| 流程 | 公式 | 初学者要抓住什么 |
|---|---|---|
| 打分 | V 把 V 的 affinity 改成 。 | |
| 选择 | 普通 MoE 层用校正偏置影响选择; 不是 gate 概率本身。 | |
| 加权 | gate 权重仍用原始 score 归一化,再乘 routed scaling factor 。 | |
| 合并 | shared expert 每个 token 都走;routed experts 只走 个。 |
V 配置:Flash 与 Pro 的专家规模
| 设置 | Flash | Pro | 含义 |
|---|---|---|---|
| Total / activated params | 面试不能只报 total params;服务成本更接近 activated params、attention 成本和 cache 成本的组合。 | ||
| Transformer layers | Pro 更深更宽;MoE 只是 FFN 站点的稀疏化,不代表层数相同。 | ||
| Hidden dimension | hidden size 影响 attention、mHC、MoE 输入输出和 LM head 成本。 | ||
| Routed experts / layer | 专家池越大,总容量越大,路由负载和专家并行通信越重要。 | ||
| Shared experts / layer | 这是一条额外通用路径,不是把所有 experts 变成同一份共享权重。 | ||
| Activated routed experts / token | 两者每个 token 选择同样数量的 routed experts;Pro 不是通过增大 来变强。 | ||
| Expert intermediate dimension | 每个 expert 自身也是一套 SwiGLU MLP;宽度决定单 expert 表达力和 GEMM 形状。 | ||
| Routed scaling factor | 归一化后的 routed expert 输出再乘 ,用于调节 routed path 的量级。 | ||
| Hash MoE layers | 前几层用冻结的 lookup 固定选择 experts,降低早期路由冷启动风险。 | ||
| MTP layers | 对应 num_nextn_predict_layers 为 ;这是训练辅助模块,不是用户 API 一次吐多个 token。 |
Hash routing:前几层先用 token id 分专家
学习型 router 一开始也很弱。如果刚训练时 router 乱选专家,部分 experts 得不到足够 token,另一些 experts 被打爆,模型会同时遇到表示学习和负载均衡两个难题。 V 因此把初始若干 MoE 层设为 Hash routing:专家集合由冻结 lookup 表按 token id 给出。
Hash routing 不是哈希注意力,也不是把 token 内容哈希后去查 KV cache。它只发生在 MoE expert 选择上: 给出 routed experts 的集合。 HF Transformers 文档还说明,hash MoE 层里 learned gate 仍产生 per-expert scores 来加权这些被选 experts;静态的是 which experts,不是 expert 输出的加权幅度。
:没有传统 aux loss,不等于没有平衡
普通 MoE 最大的工程风险是 hot experts。设一个 batch 或一个序列里,第 个 expert 收到的 token 数为:
如果很多 token 都选同一个 expert,这个 expert 对应设备上的队列会变长,其他设备空等;如果系统设置了容量上限,还可能丢弃或延迟 token。 训练上,某些 experts 反复接收高梯度 token,会形成 outliers,进而触发 spike。
传统 MoE 常把负载均衡写成一个可微 auxiliary loss,加到主语言模型 loss 里。V 沿用 auxiliary-loss-free load balancing: 选择 experts 时用 correction bias,真正 gate 权重仍用原始 score。
这四行很适合回答面试追问: 影响 的选择,但不进入 的归一化权重;overloaded expert 会被降低选择倾向,underloaded expert 会被提高选择倾向。 所谓 auxiliary-loss-free 是“不把主要均衡压力做成传统 router auxiliary loss”,不是“不做负载均衡”。V 仍保留很小的 sequence-wise balance loss,用 防止单条序列内部极端偏斜。
路由和通信:MoE 便宜在哪里,又贵在哪里
MoE 降低的是单 token 激活计算,不是把所有工程成本都消掉。专家通常被分到不同设备上,token 先被 dispatch 到目标 expert,算完再 combine 回原位置。 这会产生专家并行里的核心通信:
是 batch size, 是序列长度, 是 hidden size, 是每个激活数的字节数。 前面的 表示 dispatch 和 combine 两次跨设备传输。 所以社区说 MoE “便宜”时,严谨说法应该是:在负载均衡、通信重叠、expert GEMM kernel 和 batch 调度都做好的前提下,MoE 可以用较低 activated params 获得较大 total params。
训练稳定性边界:Anticipatory Routing 与 SwiGLU Clamping
本章只做定位,训练章会展开。MoE 的路由会把 token 分流到不同 experts,因而 outlier token、hot experts 和某些专家权重的异常激活会集中放大。 V 报告提到两类稳定性手段:Anticipatory Routing 在出现 spike 时短暂解耦“当前参数算特征”和“提前缓存的路由索引”;SwiGLU Clamping 则直接限制 routed expert 内部激活幅度。
这两项不是 MoE 的基本定义,而是大规模训练里的安全阀。它们和 、Hash routing、deterministic kernels 一起服务稳定训练;不要把它们误说成推理时的用户可见功能。
MTP:普通 next-token loss 之外,再预测更远 token
MTP 全称 Multi-Token Prediction。DeepSeek V 明确继承 DeepSeek-V 的 MTP 模块和目标;
公开配置里 num_nextn_predict_layers 是
,可写成
。
它的作用是训练时多给一个未来 token 的监督,不是对外推理 API。
普通语言模型只问:“看到 ,下一个 是什么?” MTP 再问一个更远的问题。以 为例,额外模块预测 。这会让主干 hidden state 更早承受未来信息、长链规划和代码结构的训练压力。
| 对比项 | Ordinary next-token loss | MTP extra prediction |
|---|---|---|
| 预测目标 | ,V 里 。 | |
| 损失形式 | ||
| 训练信号 | 只对最近未来 token 给监督。 | 让表示同时解释更远 token,增加 sequence-wise 的未来约束。 |
| 推理语义 | 自回归逐 token 生成: | MTP 模块本身不是公开 API;不能据此声称模型一次返回多个 token。 |
| 和 speculative decoding 的关系 | 普通 LM loss 不等于 speculative decoding。 | MTP 可以给 speculative 路线提供启发或训练基础,但“MTP 等于 speculative decoding”是错误说法。 |
业界/全网讨论视角:以下是解读,不是官方事实
MoE 是否真的便宜
社区常把 和 放在一起讨论成本。本文解读是:MoE 便宜的是激活计算,不自动免除 、KV cache、调度和 kernel 成本。
专家是否真的专门化
DeepSeekMoE paper 的研究目标是 expert specialization;但从线上模型外部很难直接证明某个 expert 只负责某类知识。 更稳妥的说法是:router 给模型提供稀疏子网络选择能力,是否专门化要看内部路由统计和消融。
MTP 是否等于 speculative decoding
MTP paper 和 DeepSeek-V 路线说明它是训练信号和辅助预测模块。 speculative decoding 是推理算法;两者可相关,但不能把社区评论当官方 API 事实。
面试易错点速查
| 常见错误 | 正确说法 | 可用公式 |
|---|---|---|
| 把 total params 当 active params | total params 是权重容量;active params 是单 token 前向触碰的参数量。 | |
| 说 auxiliary-loss-free 等于没有平衡 | 仍有 correction bias、bias update 和很小的 sequence-wise balance loss。 | |
| 把 MoE 和 CSA 混在一起 | MoE 选 experts;CSA 选 compressed KV entries。 | |
| 把 Hash routing 说成 hash attention | Hash routing 是 token id 到 expert id 的 lookup;attention 仍由 CSA/HCA/SWA 处理。 | |
| 说 MTP 一次吐多个 token | MTP 是训练目标和辅助预测模块;对外生成语义仍应按自回归逐 token 理解。 | |
| 说 shared expert 表示所有 experts 共享 | shared expert 是每个 token 都走的一条通用 MLP;routed experts 仍是独立专家池。 |
章内来源
官方事实优先看 DeepSeek V PDF、 Pro config、 Flash config 和 Transformers DeepSeek V docs。 背景脉络看 DeepSeekMoE paper、 DeepSeek-V report 和 MTP paper。
Pre-Training
预训练:从 next-token 到 context
预训练的第一性原理很朴素:把文本、代码、论文、工具轨迹都切成 token 序列 ,让模型在第 个位置只看过去 ,预测下一个 token 。如果真实 token 的概率越高,loss 越低;如果模型把概率分给了错误 token,梯度就会把参数往相反方向推。
这里的 是训练语料集合, 是样本 的 token 长度。DeepSeek V 的难点不是换掉这个目标,而是让这个目标在 级数据、 长度课程、 MoE 路由、CSA/HCA 稀疏注意力和 Muon 优化器上同时稳定成立。
这一章只讲预训练边界:官方报告明确的是预训练数据、tokenizer 继承与少量特殊 token、FIM、sample-level mask、agentic mid-training data、 Muon + AdamW、长度 schedule、dense-to-sparse transition、Anticipatory Routing 和 SwiGLU Clamping。 SFT、RL、OPD、sandbox rollout 和 batch-invariant decoding 的主体属于后训练或系统章节;这里会说明它们和预训练的接口,避免把边界混在一起。
从短序列和 dense attention 起步,先学稳定局部语言、代码和 MoE 路由基础。
逐步增加有效上下文,让模型开始学习跨段落、跨文件和长文档依赖。
引入 sparse attention;先 warm up CSA Lightning Indexer,再打开稀疏检索。
最终扩展到 million-token context,靠 CSA/HCA/SWA 和系统并行支撑。
数据:质量、长度和边界比“堆 token”更重要
官方说 V 在 DeepSeek-V 数据基础上构造更多样、更高质量、有效上下文更长的语料;Flash 训练 tokens,Pro 训练 tokens。初学者容易把 理解成“全部人工高质量样本”,这是错的:它是经过过滤、去模板化、长文档构造和多类来源混合后的预训练 token 总量。
| 数据/机制 | 公开说法 | 第一性原理解释 | 面试易错点 |
|---|---|---|---|
| 总 token 数 | Flash: ;Pro: 。 | 更多 token 降低估计误差,但只有数据分布覆盖真实任务,loss 下降才会转成能力。 | 不要说 都是人工精标高质量数据。 |
| 网页过滤 | 过滤批量自动生成和模板化内容,以降低 model collapse 风险。 | 模板数据让模型学会重复格式而不是世界知识;低熵样本过多会污染 next-token 目标。 | 不要把“数据多”当成“数据质量自然高”。 |
| 数学/代码 | 数学和编程语料仍是核心部分。 | 推理并不是凭空出现;证明、程序、测试、错误修复都提供可验证的中间结构。 | 不要把 reasoning 全部归因于后训练 RL。 |
| 长文档 | 强调 scientific papers、technical reports 等长文档数据。 | 长上下文能力需要模型反复看到跨段落、跨章节和跨文件依赖,而不是只靠位置编码外推。 | 不要说 context 只是把 RoPE 参数调大。 |
| agentic mid-training data | 报告说 mid-training 阶段加入 agentic data 来增强 coding/agentic 场景。 | 工具轨迹、代码仓库状态和执行反馈给 base model 提供“行动模式”的 next-token 信号。 | 不要说 base model 因此自动变成完整 agent;工具使用、奖励优化和 rollout 仍属于后训练/系统边界。 |
Tokenization、FIM 与 sample-level mask
Tokenizer 是“文字到整数”的接口。报告用 级词表简称;HF config 的精确值是 。这两个数字不矛盾:前者是报告级简称,后者是实现配置里的词表大小。 V 在 DeepSeek-V tokenizer 上新增少量 context construction special tokens,并继承 token splitting 与 Fill-in-Middle。
token splitting 让模型不要过度依赖某些合并 token 的边界;FIM 让模型学会“给定前缀和后缀,补中间”,这对代码补全和编辑尤其重要。 sample-level attention masking 的直觉是:为了提高吞吐,训练会把不同来源文档 pack 到同一条序列里,但 attention mask 要阻止样本之间互相偷看,否则 loss 会被跨样本泄漏污染。
Length schedule:为什么不能一开始就用
长上下文训练有三个成本一起上升:attention 计算、激活显存、并行通信。普通 dense attention 的 prefill 复杂度近似 ,KV/激活存储至少随 线性增长;当 时,早期随机表示会让模型把大量算力花在噪声依赖上。 所以 schedule 的意义不是“保守”,而是先让局部语言、路由、压缩表示和优化器状态站稳,再扩展到更长序列。
上面是帮助理解的复杂度近似:SWA 只看最近窗口,CSA 用 indexer 选压缩后的少量 entries,HCA 用 的重压缩摘要提供全局视图。真实系统还要叠加 MoE dispatch、Contextual Parallelism、activation checkpointing 和 kernel 实现。
| 训练项 | Flash | Pro | 解释 |
|---|---|---|---|
| 训练 token | Pro 多一个大模型的长训练版本,不表示两者数据配方完全公开。 | ||
| 最大 batch tokens | batch scheduling 从小 batch token 数增长到最大值,再在大部分训练中保持。 | ||
| LR warmup | steps | steps | 早期梯度方向不稳定,线性 warmup 避免学习率一开始过大。 |
| Peak LR | Pro 更大,峰值学习率更低。 | ||
| End LR | 末期 cosine decay,把大步探索变成小步收敛。 | ||
| MTP loss weight | 主体训练用更强未来 token 监督,LR decay 后减弱。 |
Dense-to-sparse transition:先学会“看”,再学会“选”
稀疏注意力不能一开始就打开。CSA 的 indexer 本质上在回答: “当前 query 应该从哪些 compressed entries 取信息?”早期模型 hidden state 还没形成可靠语义,indexer 的 选择也会噪声很大;如果一开始就 sparse,模型可能在错误远程块上反复更新。 V 的公开流程是:Flash 先用 dense attention warmup tokens;到 sequence length 时引入 sparse attention;先短阶段 warm up CSA Lightning Indexer,再用 sparse attention 进行后续大部分训练。 Pro 的 dense 阶段更长,但 sparse 引入策略与 Flash 一致。
HCA 和 CSA 不一样:HCA 用 做更强压缩,但不做 indexer;它把已经闭合的 compressed entries 作为 dense compressed global view。 面试里把 dense-to-sparse transition 说成“从第 步就 sparse”是典型错误。
优化器:Muon 不是 AdamW 的完全替代
Muon 的直觉是:许多神经网络权重是矩阵,矩阵更新不只有“每个元素加多少”,还有“整体方向是否扭曲”。Muon 对大多数矩阵参数做 momentum 后,用 Newton-Schulz 近似正交化更新方向; 但 embedding、prediction head、RMSNorm 权重、mHC static biases 和 gates 仍走 AdamW。社区常讨论“Muon 是否替代 AdamW”,更准确的说法是: V 采用分工,不是单一优化器统治所有参数。
是 hybrid Newton-Schulz。若 , 正交化想近似得到 ,但每步做 SVD 太贵,所以用多次矩阵乘迭代近似。
前 次用快速收敛系数把奇异值推近 ,后 次用稳定系数把奇异值压稳。V 由于在 query 和 KV entries 上使用 RMSNorm,报告明确不再使用 QK-Clip。
| 参数分工 | AdamW | Muon | 为什么这样分 |
|---|---|---|---|
| 使用范围 | embedding、prediction head、RMSNorm、mHC static biases/gates。 | 其它大多数矩阵权重,包括 attention、MoE 和 dense matrix parameters。 | 小向量、归一化权重和 gate/bias 不适合强行做矩阵正交化;大矩阵更能利用 Muon 的结构假设。 |
| 更新形式 | AdamW 是 element-wise adaptive update;Muon 是 matrix-structured orthogonalized update。 | ||
| 核心超参 | Muon 的 用来复用 AdamW 风格学习率尺度。 | ||
| 系统边界 | ZeRO 原本更适配 AdamW 这类 element-wise optimizer。 | Muon 需要完整梯度矩阵,V 用 hybrid ZeRO bucket assignment、knapsack balancing、 Newton-Schulz matmul 和 MoE 梯度通信优化支撑。 | 不要只讲优化器公式;大规模训练里通信和显存决定它能不能落地。 |
负载均衡、bias update 和 MTP loss
MoE 稳定性还取决于专家负载。V 继承 auxiliary-loss-free load balancing: correction bias 影响 选择,但 gate 权重仍来自原始 score。 另外保留很小的 sequence-wise balance loss,避免单条序列内部过度偏向少数 experts。
在大部分训练为 ,进入 LR decay 后为 。MTP 是预训练额外未来 token 监督,不等于推理 API 一次吐多个 token。
稳定性机制:路由、异常值和系统可复现
报告把 loss spike 与 MoE outliers 和 routing 机制联系起来。处理思路分两类:一类打断“路由导致异常值、异常值又影响路由”的循环;另一类直接压住 SwiGLU 里的异常激活。
| 机制 | 公式/边界 | 解决什么问题 | 不要误解成什么 |
|---|---|---|---|
| Anticipatory Routing | 当前参数算特征,历史参数提前算并缓存路由索引;loss spike 时短暂启用,稳定后回到标准训练。 | 不是普通推理功能,也不是永久使用旧模型训练。 | |
| SwiGLU Clamping | 直接限制 routed expert 内部异常激活,减少 outlier 扩散。 | 不是 decoding trick;不要把 clamping 说成用户侧推理开关。 | |
| Deterministic training kernels | 固定 backward 规约顺序,便于定位数值问题和复现 spike。 | 这是 systems 里的训练可复现边界,不是替代优化器或数据质量。 | |
| Batch-invariant decoding | 推理时同一请求不应因同批其它请求变化而改变输出;请求级 也要隔离。 | 这是推理系统一致性,不是预训练稳定性的核心机制。 |
业界/全网讨论视角:标清为解读
Muon 是否替代 AdamW
解读 社区常把 Muon 讲成“AdamW killer”。V 的公开事实是分工: 大矩阵用 Muon,embedding/head/RMSNorm/mHC 小参数仍用 AdamW。
长上下文是否只是堆数据
解读 数据重要,但 context 还依赖 length schedule、CSA/HCA/SWA、indexer warmup、CP 和 KV cache 系统。
agentic data 是否让 base 自动变 agent
解读 agentic mid-training data 提供轨迹模式和 coding 信号,但完整 agent 能力还要看 SFT/RL/OPD、工具环境和 sandbox rollout;评论不能替代官方事实。
本章可定位来源
事实优先来自 DeepSeek V technical report; Muon 背景可读 Muon is Scalable for LLM Training; tokenizer/FIM 继承边界可回看 DeepSeek-V technical report; config 里的 、、 等可对照 Transformers DeepSeek-V docs。 HF blog 这类文章适合理解社区关注点,但本文只把它们当解读入口。
面试快错清单
- 把 Muon 说成 AdamW 的完全替代:错,V 明确保留 AdamW 参数组。
- 把 说成全部人工高质量数据:错,它是混合预训练语料总 token 数。
- 把 agentic mid-training 和后训练 RL 混淆:错,前者是预训练/中训练数据边界,后者是行为优化 pipeline。
- 把 dense-to-sparse transition 说成一开始 sparse:错,Flash 先 dense warmup tokens,Pro dense 阶段更长。
- 把 clamping 当推理功能:错,它是训练稳定性机制,区间为 和 gate upper 。
- 把 batch-invariant decoding 说成训练稳定性核心:错,它主要属于推理/系统一致性;训练 spike 定位更接近 deterministic backward kernels。
Systems
系统工程大全:V4 的难点不只在模型公式
V4 的技术报告花了大量篇幅讲训练/推理系统,因为 MoE、Muon、mHC 和 上下文会把普通训练框架的假设都打破。 这些系统点看似工程细节,实际上决定论文里的模型能不能真的跑起来。
第一性原理是:模型公式只定义函数 ,系统工程要证明这个函数能在有限显存、有限带宽、有限时间和可复现约束下执行。 写出 不难,真正难的是让 、MoE 路由、Muon 更新、后训练 rollout 和线上 cache 同时满足:
上面三行分别对应延迟、内存和可复现。初学者可以把系统工程理解成“给模型公式补上物理世界账本”:每个 FLOP、每次 、每个 cache block、每次 reduce 的顺序都要付钱。
训练 / 推理 / 后训练系统总览图
Muon + ZeRO + CP
EP overlap + DeepGEMM
batch-invariant decoding
KV + on-disk prefix
OPD + DSec sandbox
这张流程图故意把“模型层”和“系统层”放在同一条线上:V 的 context 不是只靠位置编码或参数量解决,而是训练时的 、推理时的 hybrid cache、后训练时的 DSec sandbox 和存储层共同支撑。
系统组件对照表:瓶颈、方案和边界
| 压力来源 | 第一性原理瓶颈 | V4 机制 | 边界和易错点 |
|---|---|---|---|
| MoE routed experts | 每层 token 要跨设备发给 experts,再把结果收回,通信量近似 。 | fine-grained overlap、MegaMoE wave pipeline、DeepGEMM component。 | 不能只说“MoE 省计算”;省的是每 token 激活 FLOPs,新增的是 和负载均衡问题。 |
| Muon full gradient | Muon 的 需要完整矩阵方向;普通 ZeRO shard 会把 切碎。 | ZeRO bucket assignment、knapsack balancing、局部冗余计算、 Newton-Schulz matmul。 | Muon 不是“换个 optimizer 名字”;系统必须重排 bucket,保证矩阵更新可算、显存可控。 |
| mHC activation graph | mHC 引入多 stream 和约束投影,激活不再是普通顺序 block, 会快速膨胀。 | tensor-level activation checkpointing、TorchFX 最小重算图、extended automatic differentiation。 | checkpointing 不是“少存一点”这么简单;它要在 和 之间做图级权衡。 |
| Long context KV cache | cache 规模随上下文线性增长: 。 | hybrid cache、CSA/HCA compressed blocks、SWA state cache、on-disk prefix cache。 | on-disk prefix cache 只复用已闭合压缩块,不能直接复用未闭合 tail。 |
| Post-training sandbox | agent rollout 要同时保存环境镜像、文件系统状态、工具输出和 trajectory: 。 | DSec、、EROFS、overlaybd、cross-instance sharing、deterministic replay。 | DSec 是后训练/评测基础设施,不是模型 architecture block。 |
资料边界:官方事实、实现背景和社区解读
本章的官方机制以 DeepSeek V4 PDF 为主;工程背景会引用 DeepGEMM、 TileLang paper / GitHub、 3FS、 FlashMLA、 TileLink 和 Transformers DeepSeek-V4 docs。 这些链接的地位不同:官方报告里的 V4 系统设计可以作为事实;GitHub/paper 里的 kernel、文件系统和库接口是相关实现或背景;社区评论只能作为“大家在误解什么”的解读入口。
Batch-invariant decoding
同一 token 的 输出不应因 位置或同批请求变化而改变;端到端采样一致还需要请求级 设计。V4 在 attention 中避免 ,在主矩阵乘中尽量避免会改变规约顺序的 naive ,并用 DeepGEMM 提供固定顺序的高吞吐路径。
Deterministic training
为了定位 spike 和数值问题,attention backward、MoE backward、mHC 小矩阵乘都做了确定性累加/规约设计; 极小 的 mHC matmul 可使用 ,但规约顺序必须固定。
Muon with ZeRO
Muon 需要完整梯度矩阵,和 ZeRO 分片天然冲突。V4 用 assignment、knapsack balancing、局部冗余计算来换显存。
communication
Muon 的 Newton-Schulz 迭代可用 matmul;MoE 梯度通信随机舍入到 ,再用 + local sum 保持数值稳健。
mHC checkpointing
开发者只标注要重算的 tensor,TorchFX 找最小重算图,释放原 tensor 存储并复用重算结果指针。
DSec sandbox
后训练和评测需要真实工具环境。DSec 用 Rust API gateway、Edge、Watcher 和 支撑海量 sandbox; 重点不是“能开容器”,而是让 量级环境可快速启动、可恢复、可审计。
Fine-grained overlap
MoE 的 会产生跨节点 。V4 用 expert wave 调度把 token dispatch、linear 、SwiGLU、linear 、combine 分块重叠; 当每个 wave 的通信压力满足类似 的条件时,通信更容易被计算隐藏。 这里 是峰值算力, 是互联带宽, / 是每个 wave 的计算量/通信量。
MegaMoE in DeepGEMM
routed experts 的矩阵乘形状碎、批量动态,普通 GEMM 不一定高效。V4 使用作为 DeepGEMM 组件的 CUDA mega-kernel MegaMoE, 把 dispatch、linear 、SwiGLU、linear 、combine 融合成更少的 wave pipeline kernel,减少 launch、读写和中间 buffer。
TileLang
V4 很多 kernel 形状特殊,例如 mHC 小矩阵乘、 indexer、OPD full-vocabulary 。TileLang 让工程师用 tile 级描述生成高性能 kernel,其中 OPD 的精确 使用专门 TileLang kernel 来减少中间张量。
FlashMLA boundary
相关实现 FlashMLA 是 DeepSeek 开源的 attention kernel 库,官方仓库说明它服务 DeepSeek-V、 DeepSeek-V-Exp 和 DSA。V 论文没有把 FlashMLA 命名为架构组件;这里把它作为“长上下文 attention 必须落到专用 kernel”的背景。
TileLink boundary
系统背景 TileLink 论文研究用 tile-centric primitives 自动生成计算通信重叠 kernel。它不是 V 报告里的官方组件,但能帮助理解为什么 V 的 fine-grained overlap 要围绕 tile、wave、通信阶段来设计。
Host Codegen + Z3
Host Codegen 生成调度代码;Z3 被集成到 TileLang 的 compile-time integer expression analysis 中,用 SMT 求解检查 index、shape、tile 边界等整数关系,而不只是服务长上下文切块。
Contextual Parallelism
context 下单卡不能独自持有全部序列状态。 把上下文维度切给多个 :相邻 / 先传递边界未压缩 ,再 压缩 ,并把 融合成固定长度输入。
Extended AD checkpointing
扩展 automatic differentiation,让框架按 tensor 而不是粗粒度 module 做 checkpoint;这对 mHC 和 hybrid attention 这类非标准图尤其重要。
训练系统深拆:MoE、Muon、mHC 为什么会逼出专门系统
训练系统最核心的矛盾是:模型越稀疏、越结构化,单个公式越漂亮,但执行图越不规则。MoE 让每个 token 只算 个 expert,却要求 token 在设备间搬来搬去;Muon 用矩阵结构改善更新方向,却要求完整梯度矩阵;mHC 让信息在多个 stream 间流动,却让激活保存与重算图不再像普通 Transformer block 那样简单。
第一行说明 MoE 的慢点通常不是平均 expert,而是最热的 ;第二行是 fine-grained overlap 的直觉:把 dispatch、expert GEMM、SwiGLU、combine 切成 wave,让通信尽量藏在计算后面。
| 训练机制 | 系统动作 | 公式直觉 | 初学者要记住的边界 |
|---|---|---|---|
| deterministic training kernels | 固定 attention backward、MoE backward、mHC small matmul 的规约顺序。 | 浮点加法通常 ,所以要固定 。 | 这不是“固定随机种子”本身;随机种子控制采样,deterministic reduce 控制并行数值顺序。 |
| Muon + ZeRO bucket | 按矩阵完整性与设备负载重新分 bucket,并用 knapsack balancing 降低 rank 间不均衡。 | 对 bucket , ; 目标是控制 。 | ZeRO 的目标是分片省显存;Muon 的目标需要完整矩阵方向,两者必须靠 bucket assignment 调和。 |
| communication | Muon Newton-Schulz matmul 和 MoE gradient communication 使用 路径,局部求和保留更稳的累加。 | 通信量从 近似降到 ,带宽瓶颈下降约 。 | 低精度通信不是无脑截断;随机舍入和本地累加策略决定数值误差是否可控。 |
| mHC activation checkpointing | 开发者标注 tensor,TorchFX 找最小重算图,释放原 tensor storage,并让重算结果复用指针。 | 选择 checkpoint 集合 后, , 。 | 它是 activation checkpointing,不是 checkpoint 文件保存;解决的是反向传播激活显存。 |
推理系统深拆:batch-invariant decoding 不等于训练确定性
训练确定性问的是“同一训练输入能不能复现同一梯度”;batch-invariant decoding 问的是“同一个线上请求,和谁拼成一个 batch 后结果会不会变”。 二者都关心数值顺序,但边界完全不同。推理服务会动态拼 batch、拆 batch、抢占、恢复,如果一个请求 因为同批请求集合改变而得到不同 logits,用户会看到不可解释的输出漂移。
第一行是 batch-invariant logits,第二行是请求级随机数隔离。即使 logits 固定,如果所有请求共享一个 stream,batch 顺序改变也会改变采样结果。
| 对象 | V4 机制 | 为什么和普通实现不同 | 面试常见误解 |
|---|---|---|---|
| batch-invariant DeepGEMM | 为主 GEMM 提供固定 tile/规约顺序的高吞吐路径,减少 batch 形状变化带来的数值顺序变化。 | 普通 GEMM 只追求快;这里还要让 不因同批其它 改变而走不同规约路径。 | DeepGEMM 不是“普通 GEMM 换名字”,而是服务低精度、动态 batch、determinism / batch-invariance 的 kernel 体系。 |
| avoid naive | 避免让不同 batch shape 触发不同 k 维切分和归约树。 | 若 随 batch 改变,则 。 | split-k 不是永远不能用;训练中极小 batch 的 mHC matmul 可用,但必须固定规约顺序。 |
| avoid | attention decode 避免按动态 batch 形状改变 KV 分片。 | 对长上下文,单步 decode 常被 限制;改变分片会改变读取与累加顺序。 | batch-invariant decoding 不是训练 deterministic kernels,也不是简单把 temperature 设为 。 |
DeepGEMM / MegaMoE / TileLang / Z3 / Host Codegen
V 的系统故事里,kernel 不是末端优化,而是模型能否服务化的一部分。MoE expert 的 token 数 每步都变,OPD 的 full-vocabulary 会产生巨大 logits 张量,mHC 和 CP 还引入特殊 shape。靠通用算子拼接会出现 launch 多、显存读写多、batch 不变性差的问题。
| 组件 | 解决的工程问题 | 公式/约束 | 边界 |
|---|---|---|---|
| MegaMoE as DeepGEMM component | 把 MoE dispatch、linear 、SwiGLU、linear 、combine 融入 wave pipeline。 | , 但 动态变化。 | 它是 DeepGEMM 语境下的 MoE kernel 工程,不是新的 MoE 路由算法。 |
| TileLang | 用 tile 级 DSL 描述特殊 kernel,减少手写 CUDA 的开发成本。 | tile 映射可写成 , 编译器据此生成 memory layout 和 loop。 | TileLang 是 kernel 生成工具,不是模型结构名。 |
| Host Codegen | 生成 host 侧 launch、shape 绑定和调度代码,避免手写大量易错 glue code。 | 同一 kernel 需要在 不同取值下保持布局和边界一致。 | 它服务编译和运行时调度,不表示模型多了一个 neural module。 |
| Z3 / SMT integer analysis | 在 compile time 检查 index、tile、shape、alignment 的整数关系。 | 例如验证 、 是否满足边界。 | Z3 不只是“帮长上下文切块”;它是一般的整数约束分析工具。 |
Contextual Parallelism 和 hybrid cache:长上下文的两个账本
处理训练/推理计算图里“上下文太长,单 rank 放不下”的问题;hybrid cache 处理服务阶段“历史状态太多,不能都按普通 cache 保存”的问题。它们都沿序列维度动刀,但一个是并行执行,一个是状态存储,不能混成 data parallel。
第一行是 CP 对单 rank 激活显存的缓解;第二行表示 rank 间要传边界状态和压缩 ;第三行说明 on-disk prefix cache 为什么按 token 对齐:CSA 的 和 HCA 的 必须都闭合,才能安全复用。
业界 / 全网讨论视角:以下是解读,不是官方事实
社区常低估 system co-design
常见讨论会把 context 当成“参数更大”或“位置编码更长”。更准确的解读是:长上下文让 、、 同时变大,必须模型、kernel、并行、cache、存储共同设计。
不要把 kernel / FS / TileLink 混成架构模块
FlashMLA、DeepGEMM、TileLang、TileLink、 都有助于理解工程背景,但它们的身份不同。 其中 FlashMLA/TileLink 不是官方 V architecture module; 是 DSec/storage 语境里的基础设施。
context 不是 magic memory
能放入 token 只是容量,能不能稳定使用还取决于 检索质量、tail 重算、prefix 命中率、SWA 窗口和任务验证。 评论文章可以启发问题,但不能替代官方报告和可复现实验。
3FS、FlashMLA、TileLink 的来源边界
这三项很容易混在一起。正确读法是: 是 V DSec/系统基础设施会用到的存储底座; FlashMLA 是 DeepSeek 公开的相关 attention kernel 实现,主要服务 V/V 与 DSA,不应被写成 V 的 CSA/HCA 官方组件; TileLink 是计算通信重叠的系统论文背景,不是 V 技术报告命名模块。
| 对象 | 一句话直觉 | 工程公式 | 面试易错点 |
|---|---|---|---|
| 官方明确 把 SSD + RDMA 组成共享存储层,让训练数据、checkpoint、 cache 和 sandbox 镜像层不再绑死在某台机器本地。 | 冷启动从下载全镜像近似 变成按需读取 。 | 不要只说“分布式文件系统”。要讲清它为何能降低 DSec sandbox 冷启动、镜像重复存储和跨实例共享成本。 | |
| FlashMLA | 相关实现 attention 的数学省下来以后,还要用 kernel 把稀疏/低精度 访问真正跑快。 | decoding 延迟常近似为 ; sparse kernel 通过 和 FP cache 降低内存压力。 | 不要把 MLA kernel 等同于 V 的 Hybrid Attention。V 是 CSA/HCA/SWA 组合,FlashMLA 是相关 kernel 生态背景。 |
| TileLink | 系统背景 把一次大算子拆成 tile,让第 个 tile 计算时,第 个 tile 可以通信。 | 不重叠时 ; 理想重叠时 。 | 不要只背“通信计算重叠”。要能解释 tile 粒度太大隐藏不住通信,太小又会增加同步和调度开销。 |
在 DSec 里的角色
对 container,base image 和 filesystem commits 可作为 -backed readonly EROFS layers 挂到 overlay ; 对 microVM,readonly base layer 放在 上共享,写入走本地 layer。
FlashMLA 和 V 的关系
V 的 attention 章节应从 CSA/HCA/SWA、partial RoPE、attention sink 和 grouped output projection 解释; FlashMLA 只作为 kernel 背景帮助理解:长上下文模型的瓶颈最终会落到 带宽、低精度 cache 和稀疏访问调度。
TileLink 给 EP overlap 的启发
V 的 MegaMoE wave pipeline 与 TileLink 都在追求 被 覆盖。区别是前者是 V/DeepGEMM 语境下的 MoE 工程实现,后者是更一般的 kernel generation 论文。
三类系统问题
| 系统层 | 主要瓶颈 | V4 的处理方式 | 面试考点 |
|---|---|---|---|
| 训练系统 | Muon 需要完整矩阵、MoE 通信重、mHC 图复杂。 | ZeRO 、fine-grained overlap、 communication、tensor-level checkpointing。 | 为什么优化器、并行策略和模型结构必须一起设计? |
| 推理系统 | 长上下文的 cache、 相关非确定性、 复用。 | hybrid cache layout、on-disk 、 kernels、低精度 storage。 | 为什么 V4 不能直接套普通 PagedAttention? |
| 后训练系统 | 多 teacher full-vocabulary 、 token rollout、真实工具 sandbox。 | teacher scheduling、TileLang kernel、token-granular WAL、DSec。 | 为什么 OPD 的瓶颈更像系统问题,而不只是算法问题? |
Hybrid cache 与 复用
| 缓存对象 | 怎么存 | 为什么这样做 |
|---|---|---|
| classical cache | 存放 CSA/HCA 已闭合的 compressed blocks;每个落盘单元覆盖 个原始 token。 | 已闭合块可以跨请求安全复用,不会泄漏当前未闭合块的信息。 |
| state cache | 维护 SWA 最近窗口、CSA/HCA 未闭合 tail hidden states 和运行时 attention 状态。 | V4 的 attention 状态是异构的:闭合压缩块适合落盘复用,tail 与窗口更适合留在 state cache。 |
| block 对齐 | 按 对齐落盘边界。 | 让 CSA 的 与 HCA 的 都只复用已闭合块。 |
| on-disk | 只把已闭合的 CSA/HCA compressed 写入磁盘;tail tokens 命中后重算。 | 共享前缀常很长,落盘能跨请求复用;tail 不完整,直接复用会破坏因果边界。 |
| SWA 策略 | / / caching。 | 在精确局部窗口、内存成本和 命中收益之间做分层折中。 |
DSec 还做了什么
DSec 不只是“四种底座”的枚举。报告还强调 layered/on-demand image loading、海量并发密度优化、trajectory logging 与 deterministic replay: 前者减少 sandbox 冷启动和存储压力,后两者让 agent rollout 可以复现、审计和从失败点恢复。
DSec / storage:为什么 sandbox 也是系统瓶颈
后训练里的 agent 不是只在 GPU 上吐 token。它会打开仓库、运行测试、写文件、访问工具、保存环境轨迹。若每个 sandbox 都复制完整镜像,存储量和冷启动时间会随实例数线性爆炸。 DSec 的 storage 语境里,、EROFS、overlaybd 和 cross-instance sharing 的作用是把“大部分相同”的只读层共享,把“每个实例不同”的写入层隔离。
第一行是不共享时的线性复制;第二行是共享基础层后的存储账;第三行说明 on-demand loading 为什么能降低冷启动:大镜像不必一次性全部拉完,只读取本次工具真正触碰到的块。
DSec 的四种执行底座
| 底座 | 适用场景 | 为什么需要它 |
|---|---|---|
| Function Call | 轻量、无状态调用 | 预热容器池减少冷启动。 |
| Container | 常规 Linux 工具和软件工程任务 | Docker 兼容,配合 EROFS 按需加载镜像层。 |
| microVM | 高密度但更强调隔离 | 基于 Firecracker,安全边界比容器更强。 |
| fullVM | 任意 guest OS | 基于 QEMU,覆盖更复杂环境。 |
本章面试易错点:一句话纠偏
| 错误说法 | 正确说法 | 为什么 |
|---|---|---|
| batch-invariant decoding 就是 deterministic training。 | 前者是线上请求不受 batch 组合影响;后者是训练 backward / reduce 可复现。 | 和 约束的对象不同。 |
| deterministic training 等于固定随机种子。 | 固定 seed 只控制随机流;确定性 kernel 还要固定并行规约顺序和数值路径。 | 浮点加法不满足严格结合律, 与 可能不同。 |
| DeepGEMM 就是普通 GEMM。 | DeepGEMM 在 V4 语境里还承担低精度、动态 batch、batch-invariant 和 MoE expert GEMM 的系统职责。 | 普通 GEMM 只看单算子吞吐;V4 还要看 、wave pipeline 和通信重叠。 |
| CP 就是 data parallel。 | CP 切的是上下文序列维度;data parallel 复制模型、切 batch 样本。 | CP 的核心账本是 和边界状态通信,不是多份 batch 平均梯度。 |
| 是模型结构。 | 是系统基础设施,主要在 DSec storage、checkpoint、cache、共享镜像层等语境里出现。 | 它改变文件与状态的存储/共享方式,不改变 Transformer block 的计算公式。 |
| on-disk prefix cache 可以直接复用 tail。 | 只能复用已闭合的 CSA/HCA compressed blocks;未闭合 tail hidden states 命中后要重算。 | 落盘块需满足 ,tail 不满足完整块边界。 |
| FlashMLA / TileLink 是官方 V4 module。 | FlashMLA 是相关 attention kernel 背景;TileLink 是计算通信重叠论文背景,不是 V4 报告命名模块。 | 它们能帮助理解 kernel 和 overlap,但不能替代 V4 的 CSA/HCA/SWA、MegaMoE、DSec 等官方系统叙述。 |
Inference
推理与服务:从 cache 到 token 在线系统
这一章只讲“模型已经训练好之后,线上怎样把它跑起来”。先给结论: DeepSeek V 的推理难点不是单个 token 的矩阵乘法,而是 token 历史带来的状态账本。普通 dense attention 会让 计算、decode 读带宽和 cache 显存同时随上下文增长;V 通过 CSA/HCA/SWA 混合注意力,把“必须逐 token 精确保留的历史”改成“局部窗口 + 压缩远程索引 + 全局摘要”。
本章的事实边界如下: 官方明确 DeepSeek_V4.pdf、 Pro / Flash model card 和 config.json 可作为架构、上下文、精度和参数规模事实; 相关实现 Transformers DeepSeek-V4 文档、 vLLM DeepSeek V4 serving 文章 和 NVIDIA Megatron Bridge 文档 说明通用推理框架怎样落地这些 cache; 工程推断 本章会把这些公开信息翻译成延迟、吞吐、batching 和面试问题,但不会伪造 DeepSeek 未公开的线上实现细节。

第一性原理:一次生成为什么分成 prefill 和 decode
用户发来 prompt 后,模型并不是“一口气吐完答案”。推理服务通常先做 prefill:把输入 token 全部过一遍模型,建立最后一个位置的 logits 和每层历史状态; 然后做 decode:每次只喂新生成的一个 token ,读取前面已经缓存的历史,生成下一个 token。
是 time to first token,用户最先感到的等待; 是输出长度。低 TTFT 偏向短队列、小 prefill chunk、强 prefix cache; 高吞吐偏向把更多请求合并成 batch。两者天然拉扯:batch 越大 GPU 越满,但单个请求可能等更久。
排队与组 batch
scheduler 把不同请求拼成 batch。它要同时看 prompt 长度、是否命中 prefix cache、GPU 剩余 空间和延迟目标。
Prefill 建历史
prompt 内部所有 token 互相可见,dense attention 的朴素成本近似 ;长 prompt 时 TTFT 很容易被 prefill 主导。
Decode 读历史
每生成一个 token,query 都要读取历史状态。此时算力不一定最紧,HBM 带宽和 cache 容量常常先到瓶颈。
dense attention 的 cache 字节账
prefill 账
一次处理 个输入 token。 若所有位置都看所有历史,注意力分数矩阵有 个元素。
decode 账
每步只有一个新 query,但它要读 个历史 key/value。长上下文下,读历史比算一个小矩阵更要命。
并发账
同一张卡上活跃请求越多,历史 token 总数越多。即使每个请求只 decode 一个 token,总 cache 仍会线性膨胀。
第一行是假设 batch 中每条请求长度相同;第二行是生产环境更真实的变长请求。 来自 key 与 value 两份缓存, 是 batch size, 是层数, 是上下文长度, 是 KV heads, 是 head dim, 是每个数的字节数。
| 估算项 | 代入 | 结果直觉 | 要注意什么 |
|---|---|---|---|
| Flash 形状的 dense MQA cache | 若仍保存 separate /,约 / sequence。 | 这是第一性原理基线,不是 V 实际 compressed cache。 | |
| Pro 形状的 dense MQA cache | 同样基线约 / sequence。 | 如果共享 ,因子 可下降;若再压缩,才接近 V 的实际目标。 | |
| vLLM 相关实现报告 | vLLM blog 给出 DeepSeek V 在 context、 KV cache 下约 / sequence。 | 说明真正的收益来自 hybrid attention + custom cache layout,而不是只靠 MQA。 | 相关实现 这是 vLLM 的公开实现/估算,不等同于 DeepSeek 官方线上服务的全部细节。 |
V 为什么不是普通 PagedAttention:三类 attention,三类状态
Transformers 文档
把每个 decoder block 分成三种 layer type:sliding_attention、
compressed_sparse_attention 和 heavily_compressed_attention。
直觉上,SWA 负责最近局部细节,CSA 负责可检索的远程细节,HCA 负责便宜的全局背景。
| layer type | 官方/实现公开事实 | 推理时缓存什么 | 能安全复用到哪里 |
|---|---|---|---|
| SWA / sliding attention | 官方明确 只看最近 token 的本地窗口。 | 最近窗口的 uncompressed shared state。 | 窗口外 token 可丢弃或通过重算恢复;它本身不提供全局远程记忆。 |
| CSA / compressed sparse attention | 官方明确 低压缩池 + Lightning Indexer + per-query ;Flash 默认 ,Pro 默认 。 | 已闭合的 main compressed entries、indexer entries,以及尚未闭合的 compressor tail/state。 | 闭合到 的整数边界;不足一个 compression group 的 tail 需要保留或重算。 |
| HCA / heavily compressed attention | 官方明确 高压缩池,无 indexer;每个已生成的 pooled entry 都可进入 attention。 | 已闭合的全局摘要 compressed entries,以及 HCA compressor 的未闭合 tail/state。 | 闭合到 的整数边界;最后不足 token 的摘要不能当完整 prefix 复用。 |
适合长期保存、跨请求复用甚至落盘; 是“活请求的滚动状态”。第三行把 prefix 拆成已闭合块和 tail: 因为 , token 边界同时对 CSA 和 HCA 安全。
为什么 on-disk prefix cache 可行,但 tail 不能随便复用
prefix cache 的核心思想很简单:许多请求共享长前缀,例如 system prompt、工具 schema、同一份代码仓库快照、同一篇长文档。 如果前缀完全一样,已经闭合的 compressed entries 是这个前缀的确定函数,就可以用 prefix hash 做键,把它们放在 GPU cache、CPU cache 或磁盘 cache 中。 但未闭合 tail 还没有形成完整 CSA/HCA compression group,直接复用会把位置、因果边界和 compressor state 搞错。
这里把 放进 hash,是为了提醒线上系统必须隔离不同用户/组织的 prefix cache。 取决于 SWA 缓存策略:完整保存、周期 checkpoint,或者完全不保存并重算最近窗口。
| 缓存对象 | 可落盘吗 | 为什么 | 工程风险 |
|---|---|---|---|
| CSA closed compressed entries | 可以 | 每 token 闭合后成为稳定远程候选;prefix 命中时可直接恢复。 | 要同时恢复 main attention cache 和 indexer cache 的一致位置。 |
| HCA closed compressed entries | 可以 | 每 token 生成一个全局摘要;容量小,落盘收益高。 | 如果 prefix 边界不按 对齐,最后一段必须重算。 |
| SWA recent window | 看策略 | 它只覆盖最近 token,保存可降低 tail 重算,丢弃可节省存储。 | 完整保存会增加 SSD/CPU cache 压力;完全不存会拉高命中后的恢复延迟。 |
| CSA/HCA tail state | 通常不作为稳定 prefix 块 | 未闭合 compression group 仍依赖后续 token 形成完整状态。 | 误复用 tail 可能产生因果泄漏、位置错位或 batch 相关漂移。 |
context 推理策略:不是一个技巧,而是一条流水线
| 策略 | 第一性原理解释 | V 相关点 | 不要误读 |
|---|---|---|---|
| chunked prefill | 把超长 prompt 分块送入模型,边算边写 cache,避免一次性 materialize 过大的中间状态。 | CSA/HCA 在 chunk 末尾推进 closed compressed entries;SWA 只保留滚动窗口。 | 切块不会让 attention 语义自动免费;块边界仍要维护 causality、position 和 compressor state。 |
| context parallelism | 沿序列维把 token 分到多个 rank,降低单卡激活/状态压力。 | 远程 compressed entries 与边界 state 需要跨 rank 对齐;这和 data parallel 复制模型不同。 | CP 不是“多开几个 batch”;它切的是一个样本内部的上下文。 |
| prefix reuse | 共享前缀越长,cache hit 省掉的 prefill 越多。 | 闭合 CSA/HCA entries 小而稳定,适合 on-disk prefix cache;tail 与 SWA 状态按策略恢复。 | prefix cache 要隔离租户、模型版本、tokenizer 和 encoding;不能只 hash 原始字符串。 |
| batch-invariant optimization | 同一请求不应因和谁组成 batch 而改变 logits 或采样结果。 | 官方报告强调 deterministic / batch-invariant kernels;vLLM 也讨论 CUDA graphs、kernel fusion 与 decode path 稳定性。 | 这不等于 temperature 为 ,也不等于只固定随机种子。 |
| SWA streaming | 局部精确记忆只保存最近窗口,窗口外通过 compressed long-range path 获取。 | 的 rolling state 让 decode 内存随窗口而非全长增长。 | SWA 不会替代长程检索;它保的是近邻语法、格式和局部引用。 |
| attention sink | 有些 head 在某些 token 上“不需要看任何历史”,sink logit 给它一个安全出口。 | Transformers 文档把 per-head learnable attention sink 标为 shared backbone 组件。 | sink 不是外部检索,也不是把 token 丢掉;它改变的是注意力概率分配。 |
| partial RoPE | 只对 head 的一部分维度施加旋转位置编码,并在 shared 输出上做相应位置处理。 | 公开实现说明 RoPE slice 与 inverse rotation 用来保持相对位置语义。 | 它不是单独让上下文变长的全部原因;它服务 shared KV 与 long-range attention 的数值一致性。 |
| Lightning Indexer | 先在压缩空间里给远程块打分,再只取少量相关块做主 attention。 | CSA 的 选择让模型在 token 中定位相关远程片段。 | 它不是向量数据库;它是模型内部 learned indexer,输入和输出仍在 Transformer attention 路径里。 |
第二行是 CSA 的定位作用:query 只从已经闭合的 compressed entries 中选 个远程块。第三行是 HCA/SWA 的互补:HCA 看所有已闭合全局摘要,SWA 看最近原始窗口。
怎样影响 batching、block 和 tile
这里要分清两个层级。官方/架构语义 是 CSA/HCA 同时闭合的最小共同边界: 个 CSA compressed entries 对齐 个 HCA compressed entry。 相关实现 vLLM 公开文章说它使用 个原始 token 位置作为统一 logical block: C4 block 物理持有 个 compressed entries,C128 block 持有 个 compressed entries。因为 ,它也落在安全闭合边界上。
| 约束 | 公式 | 对 batching 的影响 | 公开边界 |
|---|---|---|---|
| compression phase | batch 中请求处在不同 phase 时,tail/state 不同;scheduler 可以分组、padding 或让 kernel 处理分支。 | 能说明约束来源,但不能推导 DeepSeek 线上 scheduler 具体策略。 | |
| prefix block | 命中最好落在统一边界;否则最后 token 重算。 | vLLM 选择更大的 logical block 是实现选择,不应写成唯一标准。 | |
| kernel tile | tile 越统一,CUDA graph、paged allocator 和 prefix hit 检测越简单;但 padding 可能浪费。 | 公开资料只展示相关实现思路,具体 tile 参数会随硬件、dtype、kernel 版本变化。 | |
| page-size bucket | CSA main、HCA main、indexer、SWA state 的 page size 不同,服务框架需要减少碎片。 | vLLM 文章把五类 cache stack 归到三类 page-size bucket;这是相关实现事实。 |
低精度推理:QAT、、 到底改变什么
模型卡把 Base checkpoint 标为 mixed ,
post-trained checkpoint 标为 mixed;
config 中还能看到 expert_dtype: "fp4" 和 quant_method: "fp8"。
这说明低精度不是“随手把所有张量压成 4 bit”,而是把不同张量放到不同数值格式中,并用 QAT 让模型在训练/后训练时适应量化误差。
官方明确 权重精度
model card 标注 Base 使用 mixed , post-trained 使用 mixed。 这主要影响权重显存、专家 GEMM 带宽和部署硬件要求。
相关实现 cache 精度
vLLM 文章说明其实现中 prefill 使用 KV cache, decode attention cache 使用部分 token-wise , indexer cache 使用 。这是服务实现策略,不是任意框架自动具备。
工程风险 低 bit 边界
低精度会放大 outlier、scale、反量化和 排序误差。尤其 CSA indexer 依赖打分排序,量化误差不只影响数值大小,也可能改变被选中的远程块。
| 对象 | 低精度的收益 | 边界/风险 | 面试答法 |
|---|---|---|---|
| MoE expert weights | 专家参数最多, 能显著降低显存和带宽。 | expert GEMM 需要硬件/内核支持;不同 expert 的激活分布可能不同,scale 管理很重要。 | 说“QAT 让模型适应部署精度”,不要说“4 bit 一定无损”。 |
| activation / GEMM path | 动态量化减少 HBM 读写,提高吞吐。 | scale、rounding、accumulation dtype 会影响可复现性和 batch invariance。 | 低精度是数值系统设计,不只是压缩文件大小。 |
| KV / attention cache | 长上下文最敏感的状态内存下降,直接影响并发。 | RoPE 维度、shared 、indexer cache 可能使用不同 dtype;不能用一个字节数概括全部。 | 先写 dense 公式,再说明 V 的 hybrid cache 会按类型拆账。 |
batch invariance:为什么同一个请求不该因旁边的请求而变
推理服务为了吞吐会动态 batching:同一个请求今天可能和 A、B 拼一起,下一秒可能和 C、D 拼一起。 如果 kernel 选择、规约顺序、split-K、split-KV 或 RNG stream 依赖整个 batch 的形状,同一个请求可能得到不同 logits。 官方报告强调 batch-invariant / deterministic kernel;相关实现文章则展示了 kernel fusion、multi-stream、CUDA graphs 等服务化手段。
第一行只要求请求 自己的状态 不变时 logits 不变;第二行提醒采样随机数也要按请求隔离。 这和训练 deterministic 相关,但不是同一个问题。
长上下文用例:谁真正受益,谁只是花更多钱
| 用例 | 为什么受益 | 仍然不会自动解决什么 | 工程建议 |
|---|---|---|---|
| Search agent | 多轮搜索、网页摘要、工具返回都能保留在同一轨迹里,减少反复压缩上下文的损失。 | 搜索策略、来源可信度和引用验证仍要单独设计;长上下文不会自动让低质量网页变可信。 | 固定 system/tool schema 前缀,尽量提高 prefix cache 命中;把证据分块并保留 URL/时间戳。 |
| Code agent | 仓库结构、报错日志、测试输出、diff 历史可以长期留在上下文里。 | 模型仍可能漏看关键文件;真正可靠还要靠测试、静态检查和工具执行闭环。 | 把 repo snapshot 作为可复用 prefix,后续只追加用户修改和工具结果。 |
| Long-document QA | 合同、论文、财报、审计材料可一次放入更多原文,减少检索漏召。 | token 不等于所有位置同等容易被用到;干扰项和中间位置仍可能影响答案。 | 保留目录、页码、段落 id;对关键结论要求引用原文位置。 |
| 普通短问答 | 几乎不受益,甚至可能因为长 prompt 增加 TTFT。 | 上下文越长不等于模型更聪明;无关信息会增加噪声和成本。 | 短任务用短上下文;只把必要证据放入 prompt。 |
推理工程常见考点:从公式到线上排障
| 考点 | 应该怎么答 | 常见错误 | 排查指标 |
|---|---|---|---|
| prefix cache 命中与隔离 | cache key 至少绑定模型 revision、tokenizer/encoding、prefix tokens、tenant/security boundary 和 cache policy。 | 只 hash 原始 prompt 字符串;忽略系统提示、工具 schema 或用户隔离。 | 、命中后 TTFT、跨租户访问审计。 |
| KV cache 显存估算 | 先用 dense 公式估上界,再按 MQA/shared KV、CSA/HCA compression、SWA window 和 dtype 分项扣减。 | 拿模型文件大小估 KV cache;或者忘记 batch 与上下文长度。 | live tokens、cache bytes/request、eviction rate、OOM 前的 HBM watermark。 |
| prefill/decode tradeoff | prefill 决定 TTFT,decode 决定持续 token latency;chunked prefill 和 disaggregated prefill 能缓解但会增加调度复杂度。 | 只看 tokens/s,不看 first token latency。 | TTFT、TPOT、prefill queue time、decode queue time。 |
| 随机性与 batch invariance | logits path 和 sampler RNG 都要请求级稳定;固定 seed 只是必要条件之一。 | 把 deterministic 等同于 temperature 。 | 同请求不同 batch replay 的 logits diff、sample diff。 |
| 长上下文 eval 与生产流量 | benchmark 通常控制长度、位置和答案;生产流量有共享前缀、工具噪声、短长混合、取消请求和缓存污染。 | 把 benchmark 分数直接等同于线上成功率。 | 真实 prompt 长度分布、prefix 重复率、工具回合数、用户取消率。 |
| 延迟和吞吐取舍 | 吞吐来自大 batch 和高 GPU 利用率;低延迟来自少等待、少 prefill、命中 cache 和稳定 decode。 | 只追求最大 batch size。 | GPU utilization、queue depth、P50/P95 TTFT、P50/P95 TPOT。 |
本章一句话总结
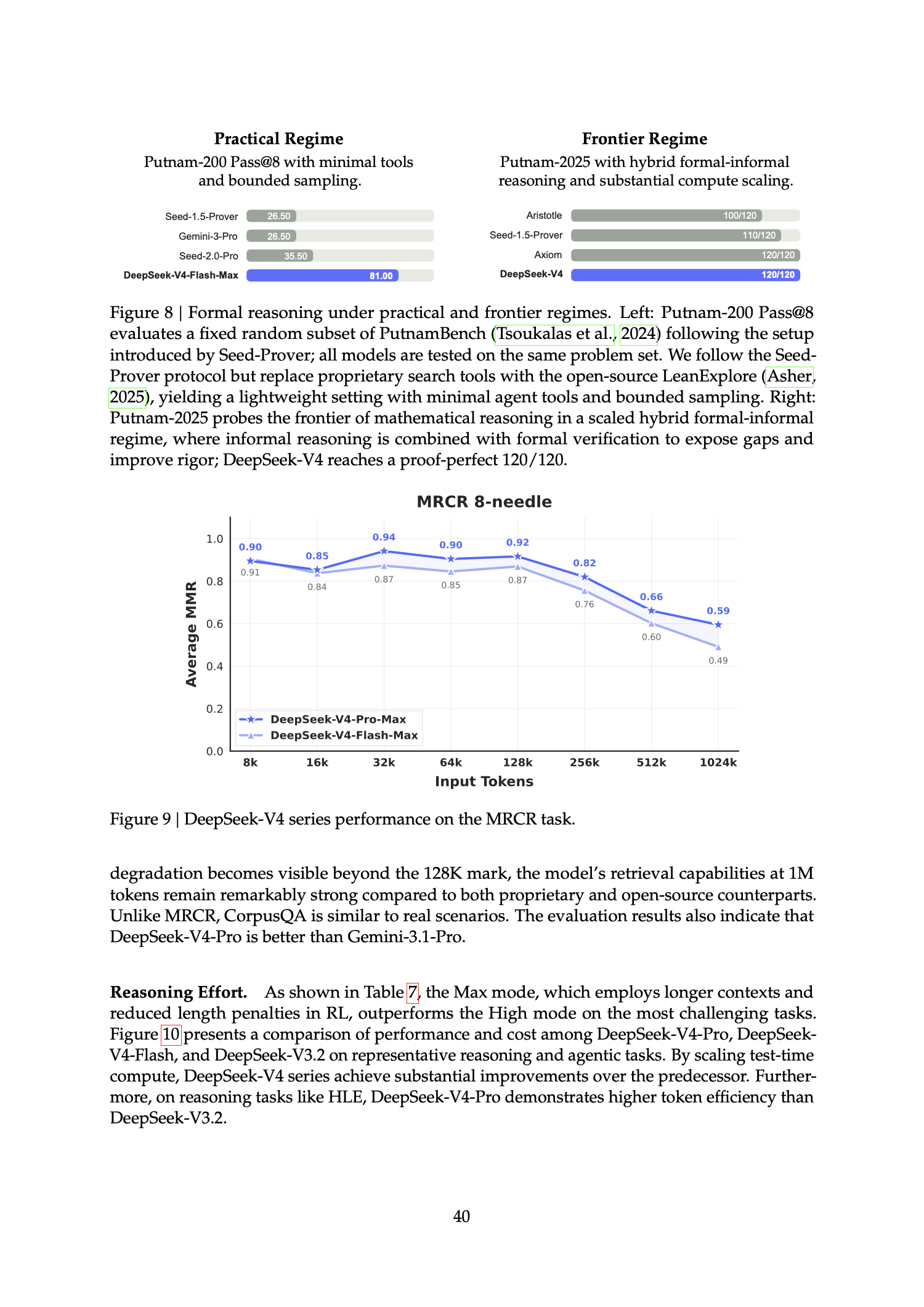
DeepSeek V 的推理创新可以记成一个状态分解: 用 SWA 保最近细节,用 CSA + Lightning Indexer 在压缩空间里找远程细节,用 HCA 保全局摘要, 再用 hybrid cache、prefix reuse、低精度和 batch-invariant kernels 把这套结构变成可服务化的 token 系统。它降低了长上下文成本,但不会把无关上下文、糟糕检索或缺失验证自动变成能力。
Post-Training
后训练:从会续写的 Base,到会做事的 V4
如果把预训练看成“读完整个互联网后学会预测下一个 token”,后训练就是把这个预测器变成可靠助手、推理器、工具调用者和长上下文 agent。 官方明确 DeepSeek V 技术报告 和 HF model card 都把 V4 的后训练描述为两阶段范式:先用 和 分别培养 domain specialists,再用 multi-teacher 把多个专家的能力合成一个统一模型。 工程推断 这个设计的核心不是“把几个模型投票”,而是把多个专家在同一上下文状态下的概率分布,通过 logits-level alignment 写回同一个参数空间。

next-token prior
format + behavior
domain reward
math / code / agent
reverse KL
modes + tools + QAT
第一性原理:为什么 Base model 还不够
Base model 的目标函数很简单:给定前缀 ,最大化真实下一个 token 的概率。这个目标能压进大量知识、语法、代码模式和推理片段,但它不会自动知道“现在应该扮演助手”“工具调用必须可解析”“数学题该多想一会儿”“安全策略和格式约束优先级更高”。后训练就是补上这些行为层面的条件分布。
左边只问“文本里下一个 token 像什么”,右边还问“在当前指令、工具、预算和安全边界下,下一步动作应该是什么”。对普通聊天,这个动作可能是自然语言 token;对 agent,它可能是 工具调用;对 Think Max,它还包含更长的测试时思考预算。
| 后训练部件 | 从第一性原理看它在修什么 | 它不负责什么 | V4 中的边界 |
|---|---|---|---|
| SFT | 把“可能的续写”拉向“人类希望看到的示范答案”。最小化 。 | 它不会自己发现比示范更强的策略,也不会解决示范数据里的偏差。 | 官方明确 V4 specialist 先经过 domain-specific fine-tuning,建立基础能力和格式。 |
| GRPO RL | 对同一 prompt 采样一组回答 ,用组内相对奖励构造 advantage,例如 。 | 它不是万能奖励。奖励若不可验证或被模型钻空子,就会出现 reward hacking。 | 官方明确 V4 specialist RL 使用 ,相关背景来自 DeepSeekMath;GRPO 相比 PPO 的常见讲法是省掉单独 critic/value model。 |
| Domain specialists | 把数学、代码、agent、instruction following、长上下文等任务分开优化,降低“一个 RL 配方同时拉扯所有能力”的干扰。 | 专家强不等于最终统一模型强。直接权重平均会破坏参数几何,混合 RL 也可能让奖励互相冲突。 | 官方明确 报告举了 mathematics、coding、agent、instruction following 等目标域,并说使用超过 个 teacher 蒸馏一个学生。 |
| Distillation / merging | 把 teacher 的分布作为 dense token-level 信号,让 student 在自己的轨迹 上学习。 | 它不是数据集拼接,也不是 model averaging。它合并的是行为分布,不是把专家 checkpoint 逐元素相加。 | 官方明确 V4 用 multi-teacher on-policy distillation 和 reverse 做统一模型 consolidation。 |
SFT、RL、GRM、OPD 的最小数学地图
SFT:学示范
训练信号来自“这个 token 应该出现”。它最适合教格式、语气、工具 schema、基础任务套路。
GRPO:学相对偏好
训练信号来自“同组回答谁更好”。它适合代码测试、数学 verifier、agent 任务成功率等可打分场景。
OPD:学专家分布
训练信号来自 teacher 的完整概率分布。V4 用 reverse ,让学生避免把概率放到 teacher 低支持区域。
Reasoning effort:Non-think、Think High、Think Max
官方明确 V4-Pro 和 V4-Flash 都支持 档 reasoning effort。这里最重要的产品边界是:Think Max 不是“在 prompt 里说请多想一会儿”,而是特殊 system prompt / instruction 配置、不同 RL length penalty 与更长 context window 共同定义的最高 reasoning effort 模式。model card 还建议 Think Max 本地部署时上下文窗口至少 token。
| 模式 | 输出格式 | 训练/系统边界 | 适合场景 | 常见误区 |
|---|---|---|---|---|
| Non-think | </think> 后直接 summary,不生成显式 thinking tokens。 | 低 latency、低风险、短任务优先;也适合不触发官方 tool-calling context path 的 agent 框架。 | 日常问答、简单改写、无需多步验证的操作。 | 不要把它说成“模型不会推理”。它只是产品上不展开显式 reasoning trace。 |
| Think High | <think> thinking tokens </think> summary。 | RL 训练时使用不同 length penalty 和上下文窗口,让模型学会在更大预算下展开推理。 | 复杂规划、代码分析、长文档问答、中等风险判断。 | 不要把 High 和 Max 的分数直接和 Non-think 混比,预算不同。 |
| Think Max | 特殊 system prompt / instruction 在前,再输出 <think> thinking tokens </think> summary。 | 官方明确 Table 给出 Think Max 注入 instruction;评测中 Max 使用更长 context 和更低 length penalty。 | 高难数学、复杂 agent、长上下文检索、多文件代码修复。 | 不要写成“普通用户提示多想一会儿”。它是系统级模式,不是随手加一句话。 |
Specialist 路线:代码、数学、agent、长上下文分别要什么
| 专家方向 | 可用奖励或训练信号 | 为什么不能只靠通用 SFT | V4 后训练接口 |
|---|---|---|---|
| Math specialist | 最终答案 verifier、步骤一致性、hard-to-verify 题目的 GRM rubric。 | 数学难题的关键在搜索路径和错误排除,单条示范只告诉模型“这条路径存在”。 | GRPO 让同题多采样的相对质量进入优化;OPD 再把数学 teacher 的分布注入统一模型。 |
| Code specialist | 单元测试、编译、lint、benchmark、repo 级任务成功率。 | 代码任务需要和环境交互,错误常在执行后才暴露。 | agentic RL rollout、DSec sandbox、WAL 恢复和 OPD 合并共同决定最终能力。 |
| Agent specialist | 工具调用成功率、轨迹长度、恢复后的状态一致性、任务完成度。 | agent 的动作不是纯文本答案,而是“思考、调用工具、读结果、继续计划”的长轨迹。 | DSML schema、interleaved thinking、Quick Instruction、sandbox trajectory log 都服务这个方向。 |
| Long-context specialist | MRCR / CorpusQA 等长上下文任务、百万 token rollout 中的稳定性与检索正确率。 | token 下,训练数据、cache、rollout、I/O 都会成为学习信号之外的瓶颈。 | 百万 token RL / OPD 使用 fault-tolerant rollout、shared-memory dataloader 和系统章节的 hybrid cache 能力。 |
官方明确两阶段范式
V4 报告明确说 mixed RL stage 被 替代:先培养 experts,再让 unified student 在自己的轨迹上最小化 reverse 。
工程推断为什么先养专家
数学、代码、agent 和长上下文的 reward 函数不同。先把任务拆开,可以降低奖励冲突;最后用 OPD 合并,避免在线上维护多个模型和路由器。
业界解读为什么适合 agent
Hugging Face blog 把 V4 的价值概括为高效长上下文叠加 agent 专属后训练。这个判断是解读,不等同于官方 benchmark 以外的质量保证。
GRM:不是“奖励模型换个名字”
对 easy-to-verify 任务,reward 可以来自测试用例、规则答案或 verifier;对 hard-to-verify 任务,例如复杂开放题、长程规划、模糊质量判断,传统 RLHF 常训练一个 scalar reward model 输出 。 官方明确 V4 报告说它不沿用传统 scalar-based reward model,而是用 rubric-guided RL data 和 Generative Reward Model 评估 policy trajectories,并直接对 GRM 做 RL 优化。直觉上,GRM 更像会按评分细则写评语的评审员,而不是只输出一个分数的打分器。
工程推断 GRM 的收益是把评价过程显式化,便于 hard-to-verify 任务泛化;风险是 reward hacking 仍然存在,只是从“骗一个标量”变成“迎合一个生成式评审过程”。因此生产系统仍需要规则 verifier、采样审计和人工抽检。
DSML、interleaved thinking 与 Quick Instruction
DSML tool calls
官方明确
V4 引入带专用 |DSML| token 的 XML-like 工具调用 schema。官方
encoding README
和
encoding_dsv4.py
才是接入边界。
Tool schema skeleton
核心结构是
<|DSML|tool_calls>、
<|DSML|invoke name="...">、
<|DSML|parameter name="..." string="true|false">。string 参数原样写,非 string 参数按 JSON 值写。
Interleaved thinking
官方明确 工具调用场景完整保留 reasoning content,包括跨 user message 边界;普通对话仍丢弃上一轮 thinking。若框架把工具结果伪装成 user message,官方提醒可能无法受益于 enhanced reasoning persistence。
Quick Instruction
官方明确 V4 把搜索触发、标题、query、authority、domain、URL 读取判断等辅助任务做成 special tokens,直接接在主模型输入后,复用已经计算好的 cache。
为什么对 search 重要
搜索前通常要先判断“要不要搜、搜什么、来源权威性要求是什么”。若另起小模型,必须重复 prefill;Quick Instruction 用同一前缀并行做这些判断,降低用户感知 。
为什么对 agent 重要
agent 的第一步经常不是回答,而是选择工具、生成查询、判断 URL 是否需要读取。Quick Instruction 把这些前置决策变成主模型原生任务,减少额外模型维护成本。
OPD:multi-teacher online policy distillation
V4 的 OPD 最容易被误解成“多个老师投票”。更准确的说法是:学生 先按自己的当前策略生成轨迹,再在这些 on-policy 状态 上,查询多个 teacher 的完整词表分布 ,并最小化加权 reverse 。这样合并的是“每个上下文状态下哪些 token 应该更有概率”,不是合并 checkpoint 权重。
这里 是报告中的 teacher 规模级别, 是 teacher / 任务重要性权重。报告说权重通常由 expert 的相对重要性决定;它没有公开完整 scheduler 细节,所以不能把 写成某个具体线上路由公式。
玩具例子中,学生当前更偏向第 个 token;数学老师也支持它,代码老师却支持第 个 token。OPD 的权重调度不是简单平均 ,而是按当前任务上下文让相关 teacher 的分布产生更大约束。
| 概念 | 正确定义 | 直觉 | 面试易错点 |
|---|---|---|---|
| On-policy | ,训练状态来自学生自己的生成轨迹。 | 学生会在自己的错误状态上收到 teacher 反馈,减少只看 teacher 标准轨迹的 exposure bias。 | 不要说成“拿老师答案离线 SFT”。 |
| Reverse | ,按学生分布取期望。 | 模式寻求,惩罚学生把概率放在 teacher 认为很低的位置。 | 不要和 forward 混淆,后者更偏向覆盖 teacher 的支持集。 |
| Full vocabulary | 对 的完整 logits 分布计算 KL。 | 比只看采样 token 的估计方差更低,训练更稳。 | 不要忽略系统成本,完整 logits 是显存、I/O 和 kernel 问题。 |
| Multi-teacher | 多个 domain expert 按权重给出分布约束。 | 把数学、代码、agent 等能力合进一个 student。 | 不是 majority vote,也不是 model averaging。 |
OPD 为什么变成系统工程
Teacher weights offload
官方明确 teacher 权重可集中存储并按需加载,使用类似 ZeRO 的参数分片缓解 和 压力。
Hidden states instead of logits
官方明确 对所有 teacher 物化 logits 太贵。V4 缓存最后一层 hidden states,训练时再过对应 prediction head 重建完整 logits。
Teacher index sorting
官方明确 训练样本按 teacher index 排序,使每个 teacher head 每个 mini-batch 只需加载一次,并且任一时刻设备内最多驻留一个 teacher head。
TileLang KL kernel
官方明确 exact KL divergence 由专用 TileLang kernel 计算,以减少动态内存分配。这里的瓶颈不是公式难,而是大词表 softmax、logits 对齐和归约。
QAT:、 和“不是无损神话”
官方明确 V4 在 post-training 阶段引入 FP4 Quantization-Aware Training ,让 model、teacher 和 reference model 适应量化带来的精度退化。它把 用在两个高收益位置:MoE expert weights,以及 CSA indexer 的 Query-Key 路径。HF model card 也标注 post-trained checkpoints 是 mixed precision,其中 MoE expert parameters 使用 ,多数其他参数使用 。
QAT 和 PTQ 的差别在这里:PTQ 是训练后再量化,模型没有在训练目标里“见过”量化误差;QAT 在训练/后训练时把量化误差纳入 forward path,再用 straight-through estimator 近似传梯度。 Jacob et al. 是 QAT 常见背景文献;V4 的具体工程边界以官方报告为准。
| QAT 事实 | 官方描述 | 工程含义 | 不要夸大成 |
|---|---|---|---|
| 格式 | 比 多 个 exponent bits,动态范围更大。 | 在满足 block scale 条件时,FP4-to-FP8 dequantization 可不额外损失已量化信息。 | “FP4 和 FP8 本身无损”或“任意权重都无损”。 |
| block / scaling 边界 | FP4 sub-block 是 tiles,FP8 quantization block 是 tiles;报告说当前权重经验上满足尺度条件。 | 量化正确性依赖块布局、尺度范围和权重分布,不能脱离实现谈格式。 | “低 bit 只改 dtype,不改系统”。 |
| indexer QK path | CSA indexer 的 QK activations 在 中缓存、加载和相乘;index scores 从 到 。 | selector 获得 加速,同时保持 KV entry recall。 | “所有 attention 都变成 FP4”。 |
| rollout 与部署一致 | 推理和 RL rollout 无反向传播,直接使用 native FP4 quantized weights,而不是 simulated quantization。 | 采样时看到的策略更接近线上部署策略,减少 train-serving skew。 | “QAT 只为省显存”。它也在控制行为一致性。 |
-token RL、WAL 与系统章节的关系
官方明确 V4 的 post-training infrastructure 直接服务 ultra-long-context RL 和 OPD:rollout 长度到 token 时,问题不只是“模型能不能看见”,还包括 GPU 抢占、硬件故障、per-token fields 太大、batch packing 和 I/O overlap。系统章节讲的 hybrid attention、heterogeneous KV cache、prefix reuse、batch-invariant kernels 是能力底座;本章讲的是这些底座如何进入后训练闭环。
生成 token
每个 request 自回归 decode。每产生一个 token,就立即追加到 token-granular 。
抢占或故障
集群级抢占会暂停 inference engine 并保存未完成请求的 cache;严重硬件故障则可从 WAL token 重跑 prefill。
恢复继续
恢复时使用持久化 WAL 和保存的 cache 继续 decode,避免从头重采样导致短回答更容易“幸存”的 length bias。
这条式子解释为什么“中断后从头生成”在数学上不正确:如果每个时间片都有中断概率 ,长回答更容易被打断。只重生成失败请求会让训练数据偏向短输出。WAL 保留已经采样的 token,是为了保持 rollout 分布正确。
| 系统能力 | 后训练里为什么需要 | 和系统章节的接口 |
|---|---|---|
| Preemptible rollout service | RL / OPD 需要大量自回归采样,长上下文下单条请求耗时更久,更容易遇到抢占。 | token-granular WAL、KV cache 保存、batch-invariant deterministic stack。 |
| Shared-memory dataloader | 百万 token rollout 的 heavy per-token fields 不能在每个 worker 内重复复制。 | metadata 全局 shuffle / packing,per-token fields 消费后按 mini-batch 释放。 |
| DSec sandbox | agentic AI 的训练和评测需要函数调用、容器、microVM、full VM 等真实执行环境。 | DSec trajectory log 支持 fast-forward、provenance 和 deterministic replay;这和 rollout WAL 是同一类“可恢复轨迹”思想。 |
官方模型卡里的接入提醒
官方明确
V4 发布页说明本次没有提供 Jinja-format chat template,而是提供 encoding 目录,把 OpenAI-compatible messages 编码成模型输入字符串,并把 completion text 解析回消息。真实接入时不能默认 tokenizer 的
apply_chat_template 覆盖全部行为;thinking mode、历史
reasoning_content、DSML tool calls、Quick Instruction 都应按官方 encoding 脚本组织。
Transformers DeepSeek-V4 docs
主要说明架构实现边界,不替代 model card 的对话编码约定。
面试考点和误区速查
| 题目 | 好答案要点 | 常见错误 |
|---|---|---|
| SFT vs RL | SFT 学示范分布,RL 用 reward 改变策略偏好;SFT 负责格式和初始化,RL 负责探索更优行为。 | 说“SFT 已经等价于偏好优化”。 |
| GRPO vs PPO | GRPO 用同 prompt 的 group reward 估计相对 advantage,常见优势是省掉单独 value / critic model;PPO 是更通用的 clipped policy optimization 框架。 | 说“GRPO 不需要 reward”或“GRPO 一定比 PPO 好”。 |
| GRM 与 reward hacking | GRM 用生成式评审处理 hard-to-verify 任务,能把 rubric 推理纳入评价;仍需要防止模型迎合评审模式。 | 把 GRM 当成绝对可靠的人类裁判替代品。 |
| OPD vs model averaging | OPD 在学生 on-policy 状态上对齐多个 teacher 的输出分布;model averaging 是参数级合并,可能破坏专家能力。 | 说“把十几个专家权重平均一下”。 |
| OPD vs voting | OPD 使用 full-vocabulary logits 和 teacher 权重,学习的是概率几何;投票只看离散输出。 | 说“多数老师同意哪个答案就学哪个答案”。 |
| QAT vs PTQ | QAT 在训练路径中模拟/使用量化误差并反传,PTQ 是训练后量化;V4 还让 rollout 直接用 native FP4,贴近部署。 | 把 说成“无损压缩”。 |
| Think Max 的产品边界 | Think Max 是特殊 system prompt / instruction、上下文预算、length penalty 和输出格式共同定义的模式。 | 说“普通 prompt 让模型多想一会儿就是 Max”。 |
| Quick Instruction | 它用 special tokens 复用主模型 KV cache 做搜索触发、query、authority、domain、URL 读取等前置任务。 | 把它理解为另一个小模型或普通工具调用。 |
| -token RL | 百万 token 后训练的关键是 rollout correctness、内存分层、I/O、WAL 和 sandbox,而不只是模型配置里的 max position。 | 只说“context window 大,所以训练自然可行”。 |
本章一句话总结
官方明确 DeepSeek V 后训练的主线是 ,并在工具调用、interleaved thinking、Quick Instruction、QAT、fault-tolerant rollout 和 DSec 上做系统配套。 工程推断 面试里最重要的抽象是:V4 不是只“更会想”,而是把多种任务分布、长上下文系统和部署精度一起纳入后训练闭环。
Evaluation
评测:不是“谁第一”,而是“在什么条件下解决了什么任务”
评测的第一性原理很朴素:给模型一个输入 ,让它产生输出 ,再用某个评分器 比较它和标准答案、环境状态或人类偏好。真正复杂的是 :prompt、few-shot 示例、temperature、reasoning effort、工具、上下文长度、搜索系统、verifier、agent harness 都属于评测环境。 所以 DeepSeek V 不能用一个总榜单概括,而要拆成 Base、Instruct、Non-think、Think High、Think Max、 context、formal reasoning、search、code agent 和 real-world task 多条轴。
官方明确 DeepSeek V 技术报告、 Hugging Face model card、 Transformers DeepSeek-V 文档、 Hugging Face 解读 和 DeepSeek API 发布页 给出了四个公开 checkpoint、Base 与 Instruct 表、reasoning modes、长上下文与真实任务评测。 工程推断 本章会把 cost、latency、可复现性、judge bias 等读表边界讲清楚;这些边界是工程解释,不应反向写成官方结论。
这些是代表数值,不是一张可直接相减的总榜。前两个来自 Base 表;后四个来自 Think Max、agent 或 formal regime,prompt、工具、采样预算和验证器都不同。
一张图看懂评测为什么要拆轴
模型阶段不同
Base 主要测试预训练后“续写下一个 token”的底座能力;Instruct/Post-trained 测 SFT、RL、OPD 后的对话、工具和推理行为。
测试时计算不同
Non-think、Think High、Think Max 改变 thinking budget 和上下文预算。官方评测里知识/推理任务常用 三档。
评分器不同
看字符串, 看补丁是否过测试, Lean verifier 看形式证明是否被 proof checker 接受。
环境不同
Search、SWE、Terminal Bench、MCPAtlas、Toolathlon 都不是纯文本问答;模型要在工具、文件系统、命令行或搜索结果里行动。
上下文不同
token 能力要看长程检索、跨段推理、位置偏差和缓存成本;不是把短题塞长就等于长上下文评测。
风险不同
Leaderboard contamination、judge model bias、工具 harness 差异和采样次数都会影响结果;读表时要先读 protocol,再读分数。
Base model evaluation:看底座,不看聊天体验
Base model 是只经过预训练的模型。它的训练目标仍然接近 , 所以评测一般用固定 prompt、zero-shot/few-shot 示例和标准答案打分。这里的关键问题是: “底座是否存住知识、是否有语言理解、是否能做基础代码数学、是否能读长上下文?” 它不等同于聊天产品里“会不会调用工具、会不会遵守格式、会不会主动分解任务”。
| Base 评测类别 | 官方报告列出的 benchmark | 指标与代表值 | 读法 |
|---|---|---|---|
| World Knowledge | AGIEval、MMLU、MMLU-Redux、MMLU-Pro、MMMLU、C-Eval、CMMLU、MultiLoKo、Simple-QA verified、SuperGPQA、FACTS Parametric、TriviaQA | Pro-Base: MMLU ,MMLU-Pro ,Simple-QA verified | 官方明确 Pro-Base 明显强于 Flash-Base,尤其知识密集任务;Flash 参数更小,知识存储天然更吃亏。 |
| Language & Reasoning | BBH、DROP、HellaSwag、WinoGrande、CLUEWSC | Pro-Base: DROP ,HellaSwag ,WinoGrande | 这些任务多是固定答案或抽取式/选择式;它们测“底层理解”,但不能代表长链推理或 agent 执行。 |
| Code & Math | BigCodeBench、HumanEval、GSM8K、MATH、MGSM、CMath | Pro-Base: HumanEval ,GSM8K ,MATH | Base 的代码/数学通常不带复杂工具循环;它说明底座会不会写函数、解题和泛化,不说明仓库级修复能力。 |
| Long Context | LongBench-V | Pro-Base: ,Flash-Base: | LongBench-V 强调 realistic long-context multitasks;它比单 needle 更综合,但仍是 benchmark,不等于生产流量。 |
Base 分数的边界
官方明确 Base 表在同一内部框架、同一设置下比较 DeepSeek-V-Base、V-Flash-Base、V-Pro-Base。 读表原则 这类横向比较最适合回答“架构、数据和规模升级后底座有没有变强”;它不适合回答“哪个 chat model 最适合写生产代码”。
Instruct model evaluation:看后训练后的“会做事”能力
Instruct/Post-trained model 不是只续写。它要读用户意图、选择是否显式思考、调用工具、遵守输出格式、在多轮里保留状态,还要在 RL/OPD 后形成稳定的偏好。 因此 DeepSeek V 的 Instruct 表必须和后训练章节一起读: Think Max 不是“同一模型随便多写几句”,而是官方定义的高 reasoning effort 模式,涉及特殊 system prompt/instruction、更长上下文和不同训练/评测预算。
| 模式 | 官方定义/接口 | 评测含义 | 面试说法 |
|---|---|---|---|
| Non-think | 快速、直觉式响应;DeepSeek API 可用 thinking toggle 关闭 thinking。 | 适合低风险日常任务,通常上下文和输出 token 更少,延迟与成本更可控。 | 它不是“不会推理”,而是不显式消耗大规模 test-time reasoning。 |
| Think High | 显式 thinking;API 文档中 reasoning_effort="high" 是普通 thinking 请求默认 effort。 | 官方标准评测中,High 常用更大的上下文预算,例如知识/推理任务的 。 | High 是“更认真解题”的常规高推理档,适合复杂问题、规划和多步分析。 |
| Think Max | 最大 reasoning effort;model card 建议 Think Max 至少使用 context。 | 用于探索能力边界,尤其在 HLE、Apex、LiveCodeBench、MRCR、BrowseComp 等任务上拉开差距。 | Max 是 evaluation mode,不应和普通线上低延迟请求的体验直接混比。 |
读 DeepSeek V 的 Instruct 表时,先确认 , 再确认是否有 web search、Python、bash/file-edit、Lean compiler 或其他工具。一个榜单只固定了某个 ,不是“模型本体”的唯一分数。
核心指标:公式先行,再看榜单
| 指标 | 公式/定义 | 适用场景 | 误读风险 |
|---|---|---|---|
| ,其中 是采样数, 是通过数。 | 代码、数学、工具任务;DeepSeek 表中 LiveCodeBench、GPQA、HLE、BrowseComp、MCPAtlas、Toolathlon 常用。 | 不是 ;采样 次的成本、延迟和选择策略都不同。 | |
| MMLU、C-Eval、CMMLU、LongBench-V 等固定答案任务。 | Exact Match 对等价表达不宽容;“语义正确但字符串不一致”可能被判错,除非 benchmark 有额外归一化。 | ||
| OpenAI MRCR 多 needle 长上下文检索;公开 dataset card 说明用 SequenceMatcher ratio 打分。 | 它不是纯二值正确率;模型可能部分复制正确内容而得到中间分。读 token 分数时还要看 needle 数和位置。 | ||
| SWE-bench Verified、SWE Pro、SWE Multilingual 等仓库修复任务。 | 通过测试不等于补丁一定优雅、安全或可维护;也受 agent scaffolding、文件编辑工具、时间限制和测试质量影响。 | ||
| Terminal Bench 、CorpusQA、选择题或执行结果可判定任务。 | 同叫 Accuracy,样本分布可能完全不同;Terminal、QA、选择题不能只因单位相同就混比。 | ||
| Lean verifier | Putnam-、Putnam-、PutnamBench、formal math agent。 | Lean 接受的是形式证明对象,不是“自然语言看起来对”。同时工具、搜索、Mathlib 版本和采样预算会极大影响成绩。 | |
| Cost / latency | 真实搜索、agent、长上下文、Think Max 体验评估。 | 工程推断 公式是读表框架,不是官方账单模型;线上价格、缓存命中、并行工具调用和排队会改变实际成本。 |
官方 Instruct 表:同模型、不同 effort 的可比边界
Table 是理解 V 评测的关键,因为它把 Flash / Pro 与 Non-think / High / Max 放在同一张表里。 可以比较同一 benchmark、同一模型族、同一 evaluation harness 下的 mode 差异;不要把它和 Base 表、real-world 人评表、第三方榜单直接相减。
| Benchmark | Flash Non-think | Flash High | Flash Max | Pro Non-think | Pro High | Pro Max | 结论 |
|---|---|---|---|---|---|---|---|
| MMLU-Pro | 知识题中 Pro 更稳;Max 对纯知识不一定总比 High 大幅提升。 | ||||||
| GPQA Diamond | 硬 STEM 推理明显吃 reasoning effort。 | ||||||
| LiveCodeBench | LiveCodeBench 强调按日期控制污染;Think 模式让竞赛代码有巨大提升。 | ||||||
| 长上下文检索不只靠窗口大小;思考预算会改善定位、顺序和抗干扰。 | |||||||
| CorpusQA | CorpusQA 更像真实语料问答,Pro-Max 最高,但 High 已经吃到主要增益。 | ||||||
| Terminal Bench | CLI agent 任务更依赖 Pro 的规模、工具轨迹和长程状态管理。 | ||||||
| SWE Verified | 仓库修复已接近饱和区,评测要特别看 contamination、harness 和验证测试。 |
Think High vs Think Max:能力、预算和后训练边界
官方明确 Max 更适合难题
报告说明 Max 使用更长上下文和 reduced length penalties,在最难任务上通常超过 High,例如 Apex、Apex Shortlist、LiveCodeBench、MRCR、BrowseComp。
官方明确 不是所有题都值得 Max
MMLU-Pro 中 Flash High 与 Flash Max 基本持平;简单知识题可能被检索/记忆上限主导。
工程推断 Max 的成本边界
Max 通常意味着更多 reasoning tokens、更长 TTFT、更多工具循环和更大上下文 cache。业务上要比较 ,不是只追最高分。
Formal reasoning:Lean verifier 为什么比“看答案像不像”更硬
自然语言数学答案可以“看起来合理但藏着漏洞”。形式化推理的做法是把命题和证明写成 Lean 代码,让 Lean kernel 检查 proof object。 官方明确 DeepSeek V formal math 评测使用 、Lean compiler、semantic tactic search engine、最多 次 tool calls 和 max reasoning effort;提交只有被 strict verifier comparator 接受才算正确。
Putnam- practical regime
固定随机子集、minimal tools、bounded sampling,并使用 LeanExplore 替代私有搜索工具。报告 Figure 给出 DeepSeek-V4-Flash-Max 。
Putnam- frontier regime
混合 informal reasoning、自验证和 formal agent,并使用 substantial compute scaling。报告给出 DeepSeek-V4 ,与 Axiom 同为满分。
PutnamBench 背景
PutnamBench 把 Putnam 竞赛问题形式化到 Lean、Isabelle 和部分 Coq,是 neural theorem proving 的高难 benchmark;DeepSeek 的 Putnam- 是其固定子集评测。
| Formal score | 看起来像什么 | 真正衡量什么 | 不能怎样比较 |
|---|---|---|---|
| 采样 次至少一次通过。 | 在轻量工具和 bounded sampling 下找到可验证 Lean 证明的能力。 | 不能当成单次回答正确率;也不能和无工具自然语言数学分数混比。 | |
| Putnam- 满分。 | 在更强 compute scaling 和 hybrid formal-informal pipeline 下的 frontier 能力。 | 不能说普通 API 请求就稳定达到这个水平;它是特定 formal agent regime。 |
长上下文: token 不等于“生产永远可靠”
长上下文评测至少有三类:needle/retrieval 类、QA/综合阅读类、多跳/agent trace 类。 DeepSeek V 的官方材料同时覆盖 MRCR、 CorpusQA 和 LongBench-V。 它们都叫 long context,但考点不同。
| Benchmark | 任务形态 | DeepSeek V 官方结果 | 生产差异 |
|---|---|---|---|
| MRCR | 多轮对话中藏入 个相似 needle,要求返回第 个目标;OpenAI dataset card 给出 到 的 bins。 | Pro-Max Table : ;Figure 显示 内稳定, 仍有竞争力。 | 真实日志会有坏格式、重复片段、工具噪声、跨语言、时间顺序和隐私脱敏;needle 分数只是“长程定位”的一部分。 |
| CorpusQA | 长语料问答,更接近真实材料阅读和证据定位。 | Pro-Max ,Flash-Max ,Pro High 。 | 线上 CorpusQA 类问题还会受检索召回、文档切分、缓存命中、引用格式和输出长度影响。 |
| LongBench-V | 官网描述为 个多选题,覆盖 single-document QA、multi-document QA、long in-context learning、dialogue history、code repo、structured data 等类别。 | Base 表中 Pro-Base 。 | 它有可靠多选评分,但生产请求通常是开放生成;用户还关心引用、可解释性和失败恢复。 |
官方明确 Hugging Face config 里 ,官方服务也宣称 context。 工程推断 生产流量仍要单独测 prefix cache、长前缀 prefill、位置偏差、工具结果膨胀、用户是否愿意等待 TTFT,以及同一长文多轮复用时的缓存命中。
Agent / Search / Code:模型分数和系统分数交织
Agent 评测最容易被误读。一个 coding agent 成绩并不只来自模型本体,还来自工具集合、编辑器、bash 环境、超时策略、重试策略、上下文管理、测试命令、文件系统状态和 sandbox。 DeepSeek 报告也明确说 SWE、Terminal-Bench、SWE-Pro、SWE Multilingual 使用内部 evaluation framework,给模型 bash 和 file-edit 工具,最大交互步数 、最大 context 。
| Agent 类别 | 代表 benchmark | 官方 Pro-Max 数值 | 读法 |
|---|---|---|---|
| 仓库修复 | SWE Verified、SWE Pro、SWE Multilingual | SWE Verified ,SWE Pro ,SWE Multilingual | 看最终补丁是否通过验证;OpenAI 对 SWE-bench Verified 的介绍强调它是 human-validated subset,但后续社区也持续讨论污染和测试质量。 |
| 命令行任务 | Terminal Bench | 模型要持续读 shell 输出、改文件、运行命令、处理错误;延迟和工具 I/O 是能力的一部分。 | |
| 搜索 agent | BrowseComp、HLE w/ tools | BrowseComp ,HLE w/ tools | 报告说明搜索任务使用 in-house harness、web search 和 Python 工具,最大 steps 与 context。 |
| 工具泛化 | MCPAtlas Public、Toolathlon | MCPAtlas ,Toolathlon | Toolathlon 官方介绍覆盖 个应用、 个工具、 个任务;这类分数更接近长程工具执行。 |
| 内部 R&D coding | DeepSeek 自建 题,来自 内部工程师任务 | V4-Pro-Max Pass Rate ;Sonnet ,Opus ,Opus Thinking | 官方明确 这是内部 R&D workload;读表边界 可说明真实工程相关性,但外部难完全复现。 |
Real-world search 与 RAG:为什么可复现性更难
DeepSeek 报告把 search 作为真实任务单独讨论:非 thinking 模式使用 Retrieval-Augmented Search,thinking 模式使用 agentic search。 官方明确 Table 中 Agentic Search 相对 RAG 的总对比为: 。 Table 给出均值成本:Agentic Search tool calls 、prefill tokens、output tokens;RAG prefill tokens、output tokens。
为什么 agentic search 更强
它可以先搜索、读结果、发现缺口、再改 query、再验证,而不是一次性把检索结果塞给模型。复杂问题的收益更大。
为什么不可简单复现
搜索引擎索引会变,网页内容会变,地区和时间会变,工具返回格式会变。Search eval 应记录日期、query、工具、缓存和判分规则。
为什么成本要一起看
Agentic Search 比 RAG 多工具调用和输出 token。报告说成本只 marginally more expensive,但生产侧仍需按自己的价格、并发和缓存重新测。
White-collar tasks:开放任务更像产品评审
白领任务不是标准答案题。官方构造了 个高级中文专业任务,覆盖 个行业,用 in-house agent harness、Bash 和 web search,并让标注者盲评四个维度: Task Completion、Instruction Following、Content Quality、Formatting Aesthetics。 Figure 给出 overall win/tie/lose 为 ,也就是 non-loss 。
| 维度 | 官方描述的强项 | 官方描述的短板 | 面试怎么讲 |
|---|---|---|---|
| Task Completion | 能主动补充洞察和自验证步骤,解决核心问题。 | 开放任务仍依赖人评 rubric。 | 这是“任务完成度”,不是 。 |
| Content Quality | 长文生成更深入、连贯,符合专业语气。 | 事实性仍要结合搜索证据和引用。 | 内容质量常受 judge preference 影响,需要多评审和盲评。 |
| Instruction Following | 整体可遵守任务约束。 | 偶尔忽略特定格式约束,略落后 Opus。 | 格式约束不是“智能低”,更像执行细节、模板和工具链问题。 |
| Formatting Aesthetics | 遵守中文正式文档层级编号。 | PPT/视觉排版仍有明显提升空间。 | 报告生成类任务要把内容、结构、视觉分开打分。 |
哪些分数能横向比较,哪些不能
| 比较方式 | 可比性 | 理由 | 正确做法 |
|---|---|---|---|
| 同一表、同一 benchmark、同一 metric、同一 mode | 较强 | 例如 Table 中 Flash High vs Pro High 的 GPQA Diamond。 | 可以讨论规模、后训练和 architecture 的影响。 |
| 同一 benchmark,不同 reasoning effort | 中等 | 可以看 test-time scaling,但成本和延迟不同。 | 同时报告 、tokens、wall-clock、工具次数。 |
| Base 表 vs Instruct Max 表 | 弱 | Base 是 few-shot/zero-shot 底座;Max 是后训练模型加高思考预算。 | 只能说“评测对象不同”,不能直接说一个分数“打败”另一个。 |
| vs | 弱 | 变大等于增加采样和选择机会。 | 同报采样数、温度、selection/verifier 策略和总 token 成本。 |
| SWE Verified vs internal R&D coding | 弱 | 一个是公开 benchmark,一个是内部真实任务集;题源、工具、评分都不同。 | 把内部评测当真实工作负载信号,不当公开 leaderboard 替代品。 |
| Search eval 跨日期复现 | 很弱 | 网页、搜索排名、知识时效、工具返回都会变。 | 冻结 corpus 或记录检索快照;否则只能做产品回归,不宜做论文式绝对比较。 |
面试考点与常见误区
| 考点 | 正确回答 | 危险说法 |
|---|---|---|
| Pass@ vs Pass@ | 衡量 次采样至少一次成功,适合有 verifier 的任务;成本约随采样、输出和验证增长。 | “Pass@ 比 Pass@ 高,所以模型本体更强 倍。” |
| EM vs semantic correctness | 是字符串或归一化答案匹配;语义正确可能因格式不同被判错。 | “EM 低说明模型完全不会。” |
| Leaderboard contamination | 公开题集可能进入训练数据或被针对性优化;LiveCodeBench 用日期控制污染,SWE-bench Verified 也有后续质量与污染争议。 | “公开榜单最高就是所有真实任务最好。” |
| Tool-use eval | 工具任务测的是 model + harness + environment;必须报告工具、最大步数、上下文、超时、文件编辑权限和评分脚本。 | “SWE 分数就是纯模型能力。” |
| Judge model bias | 白领写作、creative writing、开放问答常需要人评或 judge model;要盲评、多维 rubric、仲裁和一致性统计。 | “LLM judge 说赢就客观赢。” |
| Real-world search 可复现性 | 搜索结果随时间变化;可复现评测要冻结网页、记录查询、固定地区和工具版本,或者把它定位成持续产品回归。 | “今天跑出来 ,任何人任何时间都应完全一致。” |
| Long context 真实性 | needle、CorpusQA、多文档、多跳、agent trace 各测一部分;生产还要看缓存、成本、位置偏差和用户容忍延迟。 | “支持 token 就能稳定理解任意 token 文档。” |
| Think Max 边界 | Think Max 是官方 high-effort evaluation/product mode,和后训练里的 length penalty、上下文预算、system instruction 有关。 | “把普通 prompt 写成请多想一会儿就是 Max。” |
本章一句话总结
官方明确 DeepSeek V 评测覆盖 Base、Instruct、reasoning effort、formal math、 context、agent、search、white-collar 和内部 R&D coding。 工程推断 真正会读表的人不会问“一个分数谁高”,而会问: 是谁、 是什么、 有哪些、 多长、 怎样判分,以及 是否值得。
Interview
深度面试题库与复习路线
这一章把前面所有机制改写成“能答、能推、能接追问”的面试题库。答题时先标定资料层级: 官方明确 以 DeepSeek_V4.pdf、 Hugging Face model card 和 DeepSeek API 发布页 为事实来源; 相关实现 以 Transformers DeepSeek-V 文档、 vLLM serving 文章 和官方/社区工程仓库解释落地边界; 背景论文 用 DeepSeek-V、DeepSeekMoE、MTP、Muon、mHC、DeepSeekMath/GRPO 帮助解释来龙去脉; 评论 只用于给出工程取舍,不把未公开实现写成事实。
答题路线:同一道题按时间预算切换深度
| 场景 | 怎么开头 | 必须覆盖 | 何时收束 |
|---|---|---|---|
| 秒版 | “DeepSeek V 是 MoE 长上下文模型族,Pro/Flash 都支持 context;核心升级是 CSA/HCA/SWA 混合注意力、mHC、Muon 和后训练 OPD。” | 模型族、参数量、上下文、三大架构升级、一个风险边界。 | 用一句话落到“长上下文不是万能记忆,而是成本可承受的容量”。 |
| 分钟版 | 先写普通 attention 的 cache 公式,再说明 V 用压缩和稀疏检索改写读历史的方式。 | CSA 的 、HCA 的 、SWA 的 窗口、MoE activated params、OPD reverse 。 | 回答“为什么不只看 leaderboard”:模式、工具、context 和成本不同。 |
| 白板版 | 画 ,在 attention 分支旁画 CSA/HCA/SWA 三路缓存。 | 、、、MTP loss、GRPO/OPD 公式。 | 用“容量、计算、显存、稳定性、评测协议”五个词检查有没有漏维度。 |
| 系统设计版 | 从线上请求开始拆:prefill、decode、prefix cache、batching、低精度、工具链、评测回归。 | Flash vs Pro 选择、cache hit 成本、 文档切块、agent trace 管理、污染隔离。 | 把方案压成 四指标。 |
| 研究讨论版 | 先承认事实边界:论文/模型卡可当事实,vLLM/Transformers 是公开实现,未公开训练数据和线上 scheduler 只能推断。 | 为什么 mHC 稳定深层信号、为什么 noaux 不是无均衡、为什么 OPD 不是模型平均、为什么 MTP 不是 speculative decoding。 | 给出可证伪实验:消融 CSA/HCA/SWA、不同 effort、污染控制、真实 agent harness。 |
面试流程图:从问题到追问
先定事实
Pro 是 total / activated;Flash 是 total / activated;两者支持 context。
再讲瓶颈
普通长上下文难在 cache 线性增长和 attention 读历史成本。 公式先行,才能自然引出压缩、稀疏和 prefix cache。
连接机制
CSA 负责远程稀疏召回,HCA 负责全局粗摘要,SWA 负责局部精细依赖,mHC 负责深层流动,MoE 负责容量扩张。
回答代价
任何机制都要说代价:压缩会丢细节,稀疏检索会有召回风险,MoE 会带通信热点,低精度会带排序和 scale 风险。
接住追问
追问通常落到公式、cache layout、训练稳定性、post-training on-policy、评测协议或真实业务接入。
标明边界
说清“官方明确”“相关实现”“工程推断”“个人评论”。边界感本身就是高级答案的一部分。
公式卡片:深度题必须会从这里推
cache 显存
是 key/value 两份缓存。若 , 粗略得到 bytes,约 。这只是普通 GQA 风格账本;公开 vLLM 实现给出 V 在 context、 cache 下约 的估算。
MoE total vs activated
面试不要把 当作每 token 都计算的量。 官方明确 Pro 是 activated,Flash 是 activated;MoE 的价值是容量大、激活稀疏。
bias update
bias 影响“选谁”,gate 权重仍用原始 score。若专家负载 高于目标 ,下一步 bias 下降;这不是“不做负载均衡”。
MTP loss
MTP 是训练辅助目标,让 trunk 学会预测多个未来 token;它不是线上 speculative decoding 本身,也不保证一次 decode 必然吐多个 token。
mHC / Sinkhorn
是 Birkhoff polytope,行列和都为 。直觉是多条 residual stream 可以互相混合,但混合矩阵受约束,降低深层放大风险。
OPD reverse
OPD 不是把 teacher 权重平均。学生在自己的 on-policy 轨迹上看多个 teacher 的 full-vocabulary 分布,reverse 会惩罚学生把概率放到老师不支持的区域。
GRPO 目标
。 GRPO 用同题多样本的相对奖励估计 advantage,减少对单独 critic 的依赖。
与成本
token 是 CSA 和 HCA 都闭合的安全边界。即使有压缩, 仍会带来 prefill、cache、工具轨迹和评测成本,不能当免费记忆。
业务成本估算
工程推断 这不是官方账单公式,而是面试估算框架。官方价格页会变化;设计方案时要单独算 cache hit、输出 token、工具调用和失败重试。
核心题库一:模型族、规格、架构与注意力
| 问题 | 考察点 | Answer skeleton | 常见错误 | Follow-up |
|---|---|---|---|---|
| DeepSeek V 的 Pro 和 Flash 到底差在哪? | 模型族事实、activated params、场景选择。 | 官方明确 Pro: ,Flash: ,都支持 context。答题先说 Pro 知识和复杂 agent 更强,再说 Flash 延迟/成本更适合高频任务。 | 把 HF 页面显示的文件参数量、total params 和 activated params 混成一个数;说 Flash 是“缩水版不能推理”。 | 如果业务每天 input tokens,如何按失败成本和输出长度选择? |
| 为什么 context 不是万能记忆? | 容量与性能、成本、位置偏差、检索质量。 | 先写 和 ,再说 V 通过 CSA/HCA/SWA 降低读历史成本,但模型仍要定位证据、抗干扰和付出 prefill/工具成本。 | 把“能放进去”说成“永远能找对”;忽略用户容忍延迟和输出 token 成本。 | 同一份 文档,什么时候直接塞上下文,什么时候做 RAG? |
| CSA、HCA、SWA 的分工是什么? | 混合注意力、局部/远程/全局三路记忆。 | CSA 用低压缩率 加 Lightning Indexer 做远程 ;HCA 用 给全局粗摘要;SWA 保留最近 的未压缩局部依赖。 | 说 HCA “看全部原始 token”;说 SWA 能代替长程检索;忽略压缩块必须已闭合。 | 如果 needle 在 处,CSA/HCA/SWA 分别提供什么信号? |
| Lightning Indexer 为什么不是普通向量数据库? | 模型内 learned sparse attention 与外部检索的差别。 | 它在模型内部用 query 对压缩 entries 打分,选 后进入 attention;输入、位置、mask、RoPE 和梯度语境都属于 Transformer 路径。外部向量库检索的是文本块或 embedding,不是每层 attention state。 | 把 CSA 讲成 RAG;把 indexer 命中等价为语义检索召回率。 | 为什么 indexer cache 量化可能改变最终答案?提示: 排序会变。 |
| 为什么 会出现在 prefix cache 和 batching 里? | 压缩边界、因果安全、实现对齐。 | CSA 每 token 形成低压缩 entry,HCA 每 token 形成高压缩 entry; 是两者都闭合的最小共同边界。prefix cache 命中最好只复用闭合块,tail 重算。 | 以为所有实现都必须用 做物理 block;vLLM 用 是相关实现选择。 | 如果请求前缀长度是 ,闭合部分和 tail 分别是多少? |
核心题库二:mHC、MoE/MTP、训练与稳定性
| 问题 | 考察点 | Answer skeleton | 常见错误 | Follow-up |
|---|---|---|---|---|
| mHC 相比普通 residual connection 解决什么? | 多 stream、Birkhoff polytope、信号传播稳定性。 | 普通 residual 是单通道 。 mHC 保持多条 stream,用 Sinkhorn 投影得到近似 doubly-stochastic 的混合矩阵,让跨 stream 混合更丰富,同时约束放大。 | 把 mHC 说成 residual scaling 或 adapter;只背“稳定”但讲不出约束集合。 | 为什么 doubly stochastic matrix 的行列和约束有助于非扩张直觉? |
| Hash routing 在前几层为什么有意义? | MoE 冷启动、早期语义弱、静态 token-id 到 expert-id 分配。 | 相关实现
Transformers 文档说明前几层可用 checkpoint 中 frozen tid2eid 选择 expert;学习 gate 仍给权重。好答案要说它减少早期 router 不稳定,让专家先获得分配信号。
| 说 hash_moe 完全没有 learned gate;说静态 hash 会贯穿所有层。 | 如果高频 token 都落到同一 expert,会发生什么,后续 routed MoE 怎样缓解? |
| DeepSeekMoE 给 V 的 MoE 答案提供什么背景? | 专家专业化、shared expert、细粒度 routed experts、参数账本。 | 背景论文 DeepSeekMoE 的主线是让专家更细粒度、更专业化,同时保留 shared expert 处理共通知识。回答 V 时要把这个思想和官方 、 hash_moe、routed MoE、noaux load balancing 连起来。 | 把 DeepSeekMoE 论文细节原封不动说成 V 公开实现;只说“MoE 省计算”而不说专业化与通信代价。 | 为什么 shared expert 不能简单删除?如果删除,通用语言和格式能力可能怎么受影响? |
| 为什么不是“不做负载均衡”? | aux-loss-free routing、bias update、gate 权重。 | 选择专家用 ,计算 gate 用原始 。bias 按负载偏离目标更新,序列级小权重 balance loss 作为补充。它避免 auxiliary loss 直接扭曲主目标,但仍做均衡。 | 把 noaux 说成没有任何均衡;把 correction bias 当成可反传参数。 | 为什么 gate 不用校正后的 score?如果用了会怎样影响专家输出? |
| MTP 和 speculative decoding 有什么区别? | 训练目标 vs 推理加速策略。 | MTP 是辅助训练 loss: 。 Speculative decoding 是线上用 draft/verify 或多 token proposal 加速。MTP 可以给推理提供额外信息,但不是同一个概念。 | 说 MTP 让模型每步必然输出 个 token;忽略 verifier/acceptance 机制。 | 如果用 MTP head 做 draft,接受率受哪些分布差异影响? |
| Muon 和 AdamW 为什么要分工? | 矩阵正交化、参数类型、训练稳定性。 | 官方明确 V 用 Muon 改善收敛和稳定性;背景论文 Muon 针对矩阵更新做正交化。答题要说大矩阵适合 Muon,而 embedding、norm、bias、部分 gates/head 可能保留 AdamW,更符合参数几何。 | 说 Muon 是 AdamW 的完全替代;把“更快收敛”说成任何超参都不用调。 | 为什么矩阵参数能谈谱范数/正交化,而 scalar bias 不适合这样处理? |
| 训练数据应该怎么答,哪些不能乱猜? | 公开事实、数据配方边界、评测污染意识。 | 官方明确 model card/报告称预训练使用超过 diverse high-quality tokens。面试要说“数据规模和多样性是公开事实;具体清洗规则、来源比例、合成配方若未公开就不能编”。再接评测污染:公开 benchmark 要用日期切分、私有集和去重审计控制。 | 把没有公开的中文/英文/代码比例说成确定数字;用 benchmark 高分反推训练集一定包含某题。 | 如果你要给公司做内部评测,怎样用相似度检索和时间切分降低训练/评测泄漏? |
| 为什么 sparse attention 不是从训练第 天就打开? | dense warmup、indexer 信号、稳定性。 | 早期表示还没成型,indexer 的召回信号容易不可靠;先 dense 建立基础语言和长程表示,再在更长上下文阶段引入 sparse/compressed path,能降低训练不稳定风险。 | 只说“省算力所以越早越好”;忽略 sparse miss 会改变训练信号。 | 如果 CSA indexer 早期召回错块,梯度会怎样污染 compressor 和主 attention? |
| 训练稳定性里 Anticipatory Routing、SwiGLU Clamping、determinism 分别管什么? | MoE 热点、激活爆炸、可复现定位。 | Anticipatory Routing 处理 routing target 与设备负载;SwiGLU Clamping 控制 expert 内激活 outlier;deterministic training 让 loss spike 可复现、可定位、可回滚。三者分别作用在路由、数值和调试闭环。 | 把 deterministic training 说成固定 random seed;把 clamping 说成任意截断无代价。 | 为什么 MoE spike 比 dense FFN 更难定位? |
核心题库三:系统、推理、后训练、评测与接入
| 问题 | 考察点 | Answer skeleton | 常见错误 | Follow-up |
|---|---|---|---|---|
| 为什么 V 不能直接套普通 PagedAttention? | 异构 cache、压缩 state、prefix reuse。 | 普通 PagedAttention 主要管理同构 token-level KV。V 同时有 CSA/HCA closed compressed blocks、indexer cache、SWA window、compressor residual state 和 tail hidden states;cache 命中还要看闭合边界和 encoding/tokenizer。 | 只说“block size 改一下”;忽略 compressor state 与 prefix cache 的交接。 | vLLM 为什么用统一 logical block 和 page-size buckets?这属于官方模型事实还是相关实现? |
| EP overlap 的本质瓶颈是什么? | MoE all-to-all、expert GEMM、通信隐藏条件。 | MoE token dispatch/combine 需要 ,expert GEMM 是计算主体。 重叠的目标是让 , 而不是简单“通信免费”。 | 只背“通信计算重叠”;不讲 token 分布、热点 expert 和 microbatch/wave pipeline。 | 如果某些 expert 热,all-to-all 和 GEMM 哪个先成为瓶颈? |
| OPD 为什么必须 on-policy?reverse 有什么含义? | 后训练、多 teacher、轨迹分布。 | On-policy 表示学生在自己当前策略产生的上下文上学习,避免只模仿 teacher 离线样本而遇到分布漂移。 Reverse 从学生分布出发,惩罚学生给 teacher 低概率 token 分配高概率。 | 把 OPD 当模型平均、logit averaging 或普通离线蒸馏;忽略 full-vocabulary KL 的系统成本。 | 为什么 token rollout 会让 OPD 更像系统工程问题? |
| GRPO 在 V 后训练里怎样回答? | critic-free RL、组内相对 reward、verifiable reward。 | 先说 GRPO 来自 DeepSeekMath/R1 路线,用同题 个样本的相对奖励估计 advantage; 再写 和 clipped objective; 最后说明 V specialist 先 SFT/RL,再 OPD 合并。 | 把 GRPO 说成“没有 KL 约束”;把所有后训练都归为 RL。 | 如果 reward 是 LLM judge 而不是 verifier,方差和偏差怎么控制? |
| Think Max 是不是普通 prompt 写“多想一会儿”? | reasoning effort、system instruction、上下文预算。 | 官方明确 Think Max 是最大 reasoning effort 模式,模型卡建议至少 context;报告里还涉及 special instruction、length penalty 和评测预算。它不是用户随手加一句话。 | 把 Think High/Max 和普通 chain-of-thought prompt 混同;忽略输出 token 与工具成本。 | 什么时候 Max 不值得?请用 回答。 |
| 评测时为什么不能只拿一个 leaderboard 分数说强弱? | protocol、mode、tools、sampling、污染。 | 先列 ; 再解释 、 、 不能混比;最后说 Live/日期切分和私有任务能缓解污染。 | 把 SWE 分数当纯模型能力;把 和 当同成本比较。 | 如何设计一个不被 prompt 和公开题污染的内部 agent benchmark? |
| V 的限制和后续方向怎么答才不空泛? | 复杂架构、长上下文延迟、稳定性机理、未来多模态/稀疏方向。 | 先说官方承认架构由多种已验证组件组合而相对复杂;再把限制落到工程上: context 仍有 latency/cost,CSA/HCA/SWA 带 cache 复杂度,MoE 带通信和热点,后训练 agent 依赖 sandbox/verifier。最后说未来方向包括简化架构、更多稀疏轴、多模态和长程 agent。 | 只说“还不完美”;或者反过来把 preview 模型吹成没有长上下文代价。 | 如果让你做下一版消融,你会先拆 CSA、HCA、SWA、mHC 还是 OPD?为什么? |
| 接入时为什么不能假设有普通 Jinja chat template? | encoding、DSML、tool call、thinking parser。 |
官方 model card 展示通过 encoding 脚本把 OpenAI-compatible messages 转成模型输入;vLLM 也需要 DeepSeek V
tokenizer/tool-call/reasoning parser。实用答案要说格式、thinking mode、tool schema 和输出解析一起适配。
| 把工具调用塞进普通 user message;忽略 reasoning_content、DSML 和 parser。 | 如何在不泄漏 tool schema 的前提下复用 prefix cache? |
实用接入题:从面试答案落到工程决策
| 问题 | 建议答法 | 定量抓手 | 风险控制 |
|---|---|---|---|
| Flash vs Pro 怎么选? | Flash 适合高频、低延迟、成本敏感、简单 agent;Pro 适合知识密集、复杂推理、长程代码/搜索 agent 和高失败成本任务。 | 用 对比失败重试成本 。 | 灰度路由:低风险默认 Flash,高不确定性或工具失败升级 Pro/Max。 |
| 量化形态怎么选? | 官方权重:Base mixed ,post-trained mixed ;服务端还可能分别量化 expert weights、attention cache、indexer cache。 | 显存收益约按 估;长上下文常由 cache 而非权重单独主导。 | 低 bit 要测 outlier、scale、 排序稳定性和回归集;不要假设 bit 无损。 |
| 如何估算一次 context 请求成本? | 拆成 cache miss 输入、cache hit 输入、输出、工具调用、失败重试和排队延迟。 | 。 | 定期查官方价格页;价格和折扣会变,不要把某天价格写死进长期 SLA。 |
| 长文档/搜索/agent pipeline 怎么设计? | 先结构化文档和工具结果,再决定哪些进入共享 prefix、哪些进检索索引、哪些只保留摘要。对关键证据保留 URL、时间、chunk id 和引用片段。 | prefix 命中收益约 ; agent 成本随工具轮数 累加。 | 避免把所有历史无脑追加;为搜索结果做去重、来源评分、过期检查和引用校验。 |
| 如何避免 prompt 和评测污染? | 生产 prompt 不直接复制 benchmark 题;内部评测用时间切分、私有题、变体生成、冻结网页和工具版本;报告中同时记录模型版本、parser、context、sampling、工具权限。 | 用 或近似相似度审计,而不只看平均分。 | 不要用线上用户输入直接回灌评测集;agent trace 要脱敏、去重并标记来源。 |
常见坑:一句话纠偏
| 错误说法 | 正确说法 | 追问时怎么接 |
|---|---|---|
| context 等于万能长期记忆。 | 它是容量上限;有效使用还受 prefill、decode、cache、检索和位置偏差约束。 | 写 和 ,再谈 pipeline。 |
| MTP 就是 speculative decoding。 | MTP 是训练辅助目标;speculative decoding 是推理加速策略。 | 写 MTP loss,并解释 draft/verify 需要 acceptance。 |
| OPD 是多个模型权重平均。 | OPD 是学生 on-policy 轨迹上对多个 teacher distribution 做 reverse 蒸馏。 | 写 。 |
| Think Max 是普通 prompt 技巧。 | Think Max 是官方高 effort 模式,涉及 system instruction、context budget、length penalty 和评测设置。 | 问任务是否值得 Max,用 判断。 |
| FlashMLA / TileLink 是 V 论文组件。 | 它们是相关 kernel/overlap 背景或实现生态;V 报告核心组件是 CSA/HCA/SWA、mHC、MoE/MTP、Muon、OPD 等。 | 先标注“相关实现/系统背景”,再说明它们帮助理解哪个瓶颈。 |
| Leaderboard 一个分数能说明全部能力。 | 分数依赖模型版本、reasoning effort、context、tools、sampling、verifier 和污染控制。 | 先问 protocol,再比较同类指标;不要混比 与 。 |
复习路线:从入门到研究讨论
本章一句话总结
会答 DeepSeek V 面试题,不是把缩写串起来,而是能从 cache 和 MoE 参数账本出发,解释 CSA/HCA/SWA、mHC、MTP、Muon、OPD、GRPO 和评测协议为什么必须一起出现; 同时在每个结论旁标清事实、推断和评论边界。
Limits
限制、边界与未来方向:把能力说清楚,也把不能说的说清楚
这一章不是“免责声明”,而是整本书的校准器。DeepSeek V 的公开材料确实支持很多强结论: token context、CSA/HCA/SWA 混合注意力、MegaMoE、mHC、Muon、 QAT、OPD、DSec sandbox、长上下文与 agent 评测等;但强结论必须带来源边界。 官方明确 以 DeepSeek_V4.pdf、 HF model card、 config.json 和 DeepSeek API 发布页 为准; 相关实现 Transformers 文档、 vLLM serving 文章 和 NVIDIA Megatron Bridge 文档 说明开源生态怎样落地模型; 评论/解读 Hugging Face blog、 Syntax Dispatch review 等适合理解业界关注点,但不能替代官方事实。
本章的核心句式是 source boundary: “官方报告/模型卡明确说了什么;公开实现能说明什么;从系统原理可以合理推断什么;哪些话不该说。” 这样读 V,既不会低估它把长上下文做成可服务系统的难度,也不会把 context、MoE、MTP、OPD、QAT 或 leaderboard 分数夸成没有边界的万能能力。
先给公式边界:大能力不等于无代价
第一行说长上下文容量不是长期记忆,模型不会自动把一百万 token 全部可靠、可解释、无成本地保存成个人记忆。 第二行说 CSA/HCA/SWA 把远程历史压缩和稀疏化,但仍要付 indexer、compressed cache、tail state、调度和数值误差成本。 第三行把 MoE 与低精度的常见误读拆开:总参数给容量,每 token 激活参数给近似计算量;低精度给成本收益,但不是数学上的无损等价。
来源边界矩阵:哪些能说,哪些只能推断,哪些不应声称
| 主题 | 官方事实 | 合理工程推断 | 不应声称 |
|---|---|---|---|
| 上下文长度 | model card、config 与 API 页面都把 V 放在 token context 语境里。 | 长上下文服务瓶颈会落在 prefill、prefix cache、SWA tail、compressed cache、batching、工具轨迹和用户可接受延迟上。 | “支持 token 就等于无限记忆,任何位置都同等可靠。” |
| Hybrid attention | 报告和 Transformers 文档明确区分 sliding attention、compressed sparse attention、heavily compressed attention。 | CSA/HCA/SWA 是容量、带宽、延迟和召回率的折中;远程信息会经过压缩、索引和 选择。 | “它等价于免费 dense attention,完全没有检索漏召或压缩误差。” |
| MoE 参数量 | 公开资料给出 Flash/Pro 的 total params 与 activated params;DeepSeekMoE 路线强调 expert specialization。 | 总参数主要代表容量和专家池,activated params 更接近每 token 前向计算账本;router 稳定性和负载均衡会影响实际吞吐。 | “ 参数就是每个 token 都算 参数。” |
| MTP | 报告沿用 Multi-Token Prediction 作为训练增强路径,相关背景见 MTP paper。 | MTP 可能让表示更关注未来多个 token,并可启发 speculative decoding 设计。 | “官方线上服务一定启用了 speculative decoding,且收益直接来自 MTP。” |
| OPD | 报告把 on-policy distillation 用作多个 specialist 到统一模型的 consolidation,并使用 reverse 。 | OPD 是行为分布对齐,不是权重平均;它能缓解多 teacher 合并,但仍受 teacher 质量、任务权重和采样分布限制。 | “OPD 可以无损合并所有 teacher,任何 specialist 能力都不会丢。” |
| QAT / / | model card 与 config 标注 Base/Post-trained 的混合精度,报告说明 QAT 让训练/后训练适应部署精度。 | 量化收益来自显存和带宽下降;风险来自 scale、outlier、rounding、accumulation dtype 和 indexer 排序误差。 | “ / 一定没有任何精度损失。” |
| 服务系统 | 报告明确讨论 prefix cache、batch-invariant decoding、deterministic kernels、DSec、 等系统能力。 | vLLM 等公开实现能说明 cache layout、logical block、dtype 和 serving pipeline 的一种落地方式。 | “从 vLLM 文章可以反推出 DeepSeek 私有线上 scheduler、租户隔离、cache 淘汰和硬件拓扑。” |
| 评测成绩 | 报告列出 Base、Instruct、Think Max、long-context、formal、search、agent、white-collar 等评测。 | 分数要和 mode、tool、context、采样次数、verifier、日期和成本一起读。 | “一个 leaderboard 名次就能代表所有真实任务体验。” |
官方明确的限制与未来方向
架构仍然复杂
官方明确 报告承认 V 为了效率与稳定性组合了多种已验证组件和技巧。 本文连接 这对应前文的 CSA/HCA/SWA、mHC、MoE、Muon、MTP、QAT、DSec 和 WAL:每个模块都解决一个真实瓶颈,也增加理解、实现和调参成本。
稳定性机理仍要研究
官方明确 Anticipatory Routing 与 SwiGLU Clamping 被用于缓解训练不稳定。 工程含义 稳定不只是 loss 曲线好看,还涉及 router 负载、expert 激活、低精度数值、长序列并行和 batch-invariant kernel 的共同约束。
更多稀疏轴
官方明确 报告提到继续探索稀疏方向,例如 sparse embedding。 本文连接 MoE 稀疏在 FFN,CSA 稀疏在 attention,未来可能把 token embedding、memory、retrieval、tool trace 也纳入稀疏账本。
低延迟仍是方向
官方明确 报告把 low-latency long-context serving 放在未来方向里。 工程含义 、decode token latency、batch size、cache hit rate 和吞吐之间有拉扯;“能跑长上下文”不等于“每次交互都秒回”。
长期多轮 agent
官方明确 long-horizon, multi-round agentic tasks 是后续重点。 本文连接 这会继续放大 DSec、工具权限、trajectory logging、deterministic replay、长期记忆、错误恢复和 agent eval 的重要性。
多模态与数据策展
官方明确 报告提到多模态能力和更强的数据策展/合成策略。 工程含义 多模态不是把图片 token 拼进去这么简单;它会重新改变 tokenizer、context 预算、检索、评测、版权和安全边界。
技术边界:把前文章节的“强能力”逐一收束
| 能力 | 为什么强 | 真正边界 | 正确说法 |
|---|---|---|---|
| context | 让代码仓库、长文档、工具轨迹和多轮对话可放进同一请求窗口。 | 上下文是可见输入,不是可写可检索的永久记忆;位置偏差、检索漏召、attention 压缩和输出预算都会影响结果。 | “V 支持百万 token 输入容量,但长期记忆仍要靠外部 state、summary、retrieval 和产品层策略。” |
| CSA/HCA/SWA | 用局部精确窗口、压缩远程候选和全局摘要降低 与 attention 成本。 | 压缩和稀疏选择引入近似;Lightning Indexer 的排序、closed block 边界和 tail 重算都会影响服务行为。 | “Hybrid attention 是成本可控的长上下文机制,不是 dense attention 的免费替身。” |
| MoE / MegaMoE | 大 expert 池提升容量,每 token 只路由到少量 expert。 | router 抖动、expert 热点、all-to-all 通信、负载均衡和 expert specialization 可解释性仍是系统和研究问题。 | “总参数代表可用容量,activated params 更接近单 token 计算量,两者必须分开报。” |
| MTP | 训练时让模型预测多个未来 token,可能改善表征和数据效率。 | 训练目标不自动等于线上 speculative decoding;线上还需要 draft、verify、reject、调度和延迟收益评估。 | “MTP 是训练增强;是否用于 speculative serving 需要单独证据。” |
| OPD | 把多个 specialist 的行为用 on-policy 方式蒸馏到统一模型,减少手工 ensemble。 | teacher 之间可能冲突;reverse 会塑造偏好,但不能保证所有长尾能力完整保留。 | “OPD 是多 teacher consolidation,不是无损 merge。” |
| QAT 与低精度 | 把训练/后训练纳入部署精度,让 expert 和 路径更可用。 | 量化误差可能影响 logits、router、indexer、 和 batch invariance;不同框架的 kernel 与 scale 策略不同。 | “QAT 降低精度退化风险,不等于证明低精度完全无损。” |
系统边界:公开系统资料能说明“形状”,不能反推出私有线上实现
系统章节已经讲过,V 的长上下文不是模型文件单独完成的。 prefix cache、on-disk cache、batch-invariant decoding、deterministic kernels、DSec、、 EROFS/overlaybd、WAL、trajectory logging 都是在把模型能力变成服务能力。 但这里最容易 overclaim:公开论文和 vLLM/NVIDIA 文档能说明“这样的模型怎样可以被框架支持”,不能证明 DeepSeek API 内部一定使用同样的 block size、cache eviction、tenant isolation、scheduler 或硬件拓扑。
低延迟和高吞吐天然拉扯。更大的 batch 更容易填满 GPU,但会增加排队、padding、tail phase 分歧和单请求等待。 prefix cache 命中能降低 prefill,但必须隔离租户、模型版本、tokenizer、encoding 和权限。
| 系统能力 | 可从公开资料确认 | 仍不能反推出 | 工程接入建议 |
|---|---|---|---|
| Prefix cache | 报告和推理章节展示 compressed cache / state cache 的分离;vLLM 讨论相关 cache layout。 | 私有服务的 hash key、跨租户隔离、SSD/CPU/GPU 层级、淘汰策略和计费策略。 | 接入时自己测 system prompt、工具 schema、仓库快照的 cache hit;不要把一次命中延迟当长期 SLA。 |
| 安全隔离 | DSec 作为 sandbox 平台,结合工具执行、镜像层、trajectory log 和 replay 支撑 agent 训练/评测。 | 线上 API 对用户工具、网络、文件系统、secret、浏览器和 third-party MCP 的具体隔离规则。 | 生产 agent 要默认最小权限,记录 tool call provenance,并把 prompt 注入、数据外泄和命令执行分开审计。 |
| / DSec storage | 是 DeepSeek 开源系统基础设施,可帮助理解镜像、checkpoint、cache 和共享层压力。 | DeepSeek API 当前是否以及怎样把 用在每条线上请求路径。 | 可以借鉴共享只读层、写入层隔离和快速恢复思想;不要把开源仓库细节写成产品内部事实。 |
| Batch-invariant decoding | 报告强调同一请求不应因 batch 组合改变结果,相关实现关注 deterministic / fused kernels。 | 每个服务端 kernel、采样 RNG、CUDA graph、split-KV 和 multi-stream 的具体实现。 | 在自己系统里做回归测试:固定 prompt、seed、temperature、batch 组合,比较 logits 或输出漂移。 |
| 低延迟与吞吐 | 官方把低延迟列为未来方向;vLLM 展示一种高效 serving 实现路径。 | 私有服务的排队算法、优先级、硬件规格、限流、SLA 和多租户调度。 | 按自己的 分布压测,分别报告 。 |
评测边界:分数要连同协议一起读
V 的评测覆盖很广:Base 表看底座,Instruct 表看后训练和 reasoning effort, LongBench-V、 MRCR 看长上下文, LiveCodeBench、SWE、Terminal Bench、MCPAtlas、Toolathlon、BrowseComp 和 white-collar tasks 看工具与真实任务。 边界在于:这些不是同一个 。模型、prompt、reasoning effort、工具、采样次数、verifier、日期、搜索索引、上下文长度和成本都可能变。
| 评测类别 | 能回答的问题 | 主要风险 | 读表原则 |
|---|---|---|---|
| Leaderboard / 标准题集 | 在固定 benchmark protocol 下,某个模型配置相对其它模型的表现。 | 训练污染、prompt 泄漏、样本过拟合、指标单一、不同榜单 protocol 不一致。 | 先读 split、时间、few-shot、temperature、scoring,再读名次。 |
| Long-context benchmark | 模型能否在长输入里检索、跟踪、多跳和整合信息。 | needle 任务过窄、位置偏差、答案字符串评分、长 prompt 成本被忽略。 | 同时报告 context length、needle 数、位置分布、 / 、latency 和 cache 策略。 |
| Agent / search eval | 模型能否在工具、网页、终端、文件系统和多轮环境中完成任务。 | 搜索索引随日期变化,网页可变,工具 harness 差异大,失败可能来自环境而非模型。 | 记录日期、地区、工具版本、最大步数、超时、权限、检索快照和失败分类。 |
| LLM judge / 人评 | 开放写作、白领任务、格式美学和内容质量。 | judge bias、模型偏好、rubric 模糊、盲评不足、裁判与被评模型同源。 | 用多维 rubric、盲评、仲裁、一致性统计;不要把 judge win-rate 当唯一真值。 |
| 形式化推理 | Lean/Isabelle/Coq 等 verifier 是否接受 proof object。 | 工具链版本、Mathlib 版本、搜索预算、采样次数和 proof repair 影响很大。 | 把自然语言推理、formal proof、verifier pass 分开报告。 |
未来研究方向:从“能用”走向“更简单、更稳、更可解释”
更强稀疏注意力
未来不只是把窗口加长,而是让模型更可靠地决定“远程看哪里、摘要保什么、何时退回 dense 或检索”。 关键指标不是单步 FLOPs,而是 的联合 Pareto 前沿。
Router 稳定性
MegaMoE 的问题会从“有没有足够 expert”转向“expert 怎样稳定专门化、怎样避免热点、怎样解释路由决策”。 可研究 router loss、temperature、capacity factor、expert dropout 和线上负载反馈。
Expert specialization 可解释性
DeepSeekMoE 给了 specialization 方向,但具体 expert 学到什么仍难解释。 更好的 probes、activation attribution、任务聚类和路由可视化能帮助定位退化与偏见。
长期记忆与工具调用
长期 agent 需要把 context、external memory、tool state、user preference 和安全权限拆开管理。 token 是输入窗口,不是数据库,也不是审计日志。
Formal reasoning
形式化证明的下一步不是只提高 Pass@,还要降低搜索成本、提高 proof repair、对齐自然语言解释与 verifier 接受的 proof。
Multimodal
多模态会带来新的 token 预算、位置编码、跨模态 attention、数据治理和评测问题。 真正的难点是让图像、文档、表格、视频和工具轨迹在同一个 agent loop 里可验证地协作。
低成本部署
、prefix cache、稀疏 attention 和 MoE 都在降成本,但部署还要面对 kernel 支持、显存碎片、batch phase、硬件代际和监控告警。
服务端可观测性
未来系统需要像数据库一样观测 LLM serving: 、prefill tokens、decode TPS、tool latency、router hotspot、quant error 和 batch drift 都要可追踪。
数据策展与合成
数据不是越多越好。长上下文、agent、formal、multimodal 数据都需要 provenance、质量过滤、污染控制、合成验证和跨语言覆盖。
工程师与面试的实用答法:避免 overclaim
| 场景 | 推荐说法 | 避免说法 |
|---|---|---|
| 介绍模型能力 | “官方资料显示 V 支持百万 token context,并用 CSA/HCA/SWA 降低长上下文服务成本。” | “它能完美记住无限历史。” |
| 解释 MoE | “总参数和每 token activated params 分开报;大 expert 池给容量,路由后只激活子集。” | “ 参数都参与每次推理。” |
| 谈 serving | “vLLM 展示了一种公开实现路径;DeepSeek 私有线上细节不能从中反推。” | “DeepSeek API 肯定用和 vLLM 完全一样的 page size、scheduler 和 cache。” |
| 谈 QAT | “QAT 让模型适应目标精度,降低低 bit 部署退化。” | “ 和 质量完全一样。” |
| 谈评测 | “分数要和 model、mode、tools、context、sampling、verifier、日期和成本一起读。” | “某榜第一,所以任何真实任务都最好。” |
| 写方案或接入文档 | “把官方事实、公开实现、本文推断分三段;对未公开线上实现用‘可能/需要压测/不能确认’。” | “把评论文章、框架 blog 和官方报告混成同一级证据。” |
本章一句话总结
DeepSeek V 的边界不是削弱它,而是让它更可信: 官方明确 复杂架构、稳定性机制、稀疏方向、低延迟、长期 agent、多模态和数据策展都被列为限制或未来方向; 工程推断 真正成熟的表达方式是同时写出 、 、 和 。
Glossary
全书术语词典 + 速查索引
这一章把全书的缩写、公式、配置字段和评测指标合到一张地图里。读法很简单:先看“一句话解释”建立第一性含义,再看“V4 语境”知道它在 DeepSeek V 里具体指什么,最后用“误解/索引”回到对应章节和资料。术语解释以 DeepSeek-V 技术报告、 model card、 Transformers 文档 和相关背景论文/工程项目为准;全网解读只用来解释为什么这些词容易被误读。
这两行是本术语表的主轴:语言模型先把文本变成 token,再用 Transformer/MoE/Attention/mHC 计算 logits; 训练时降低 next-token loss,推理时围绕 、 、 cache、 和 throughput 付工程成本。
事实层
参数量、上下文长度、精度、tokenizer、模型族、混合注意力和后训练流程,优先看官方报告、HF model card、公开
config.json 与 encoding 脚本。术语表里的 官方明确 表示可直接回到这些资料。
实现层
Transformers、vLLM、DeepGEMM、TileLang、、FlashMLA、TileLink 能解释公开实现路径或系统背景,但不能反推出 DeepSeek 私有线上 scheduler、cache eviction 或硬件拓扑。
误解层
如果一句话把 context 说成“只是 RoPE 变长”,把 说成“每 token 都算”,或把 FlashMLA/TileLink 说成 V4 架构模块,就需要回到本索引校准。
基础:从 token 到一次请求
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| token | 模型真正读写的离散符号,可能是一个汉字、英文词片段、空格片段或控制符。 | 所有长度、吞吐和上下文预算都按 token 计,例如 。 | 不是“字数”。中文、英文、代码和 special tokens 的切分不同。见 基础、预训练。 |
| embedding | 把 token id 查表成向量:。 | V4 的后续 Transformer block、mHC、attention 和 MoE 都处理这些向量,而不是直接处理字符串。 | embedding 不是“词义字典”的静态解释;它会在上下文层层变换。见 总架构。 |
| logits | softmax 前的未归一化分数 。 | OPD、QAT、解码采样和评测都可能直接关心 logits 分布,而不只是最后采样出的 token。 | logits 不是概率;只有经过 softmax 才满足 。见 后训练。 |
| softmax | 把 logits 变成概率:。 | attention 权重和词表概率都会用到 softmax;V4 的 reverse 也基于完整词表概率。 | softmax 会放大相对差异;数值稳定和低精度格式会影响实现。见 系统工程。 |
| next-token loss | 预测真实下一个 token 的负对数似然:。 | V4 仍以语言建模目标为底座,再叠加 MTP、SFT、GRPO、OPD 等训练信号。 | 不是“只学接龙所以不会推理”;推理能力来自数据、结构、后训练和工具环境共同塑形。见 预训练。 |
| cache | 推理时缓存历史 key/value 或压缩状态,避免每步重新计算整个历史。 | V4 的 cache 不是单一 dense KV,而是 CSA/HCA compressed blocks、SWA tail state、hybrid precision 和 on-disk prefix cache 的组合。 | KV cache 省的是重复计算和带宽,不会让长上下文“免费”。见 推理与缓存。 |
| prefill | 处理用户给定前缀 ,一次性建立初始 hidden states 与 cache。 | 长上下文场景下 prefill 是主要成本之一;CSA/HCA/SWA 旨在避免普通 attention 的 爆炸。 | prefill 快不等于 decode 快;二者瓶颈不同。见 Attention、推理。 |
| decode | 已有 cache 后逐 token 生成:。 | decode 关注每步读取多少 cache、MoE 路由通信、batch-invariant kernel 和采样一致性。 | decode 不是一次性生成整段;通常每步只确认一个新 token。见 系统工程。 |
| Time To First Token:从请求进入到第一个输出 token 返回的延迟。 | Quick Instruction 复用主模型已算好的 cache,目标之一就是减少搜索/工具前置判断的 TTFT。 | TTFT 不是总完成时间;长回答还要看 decode throughput。见 后训练、推理。 | |
| throughput | 单位时间处理或生成的 token 数,常写作 。 | V4 的吞吐受 batch、上下文长度、MoE expert load、cache 命中、kernel 和网络通信共同决定。 | 不要只用参数量推断吞吐;同一模型在不同服务栈差异很大。见 系统。 |
| context length | 模型一次请求可纳入的最大 token 窗口 。 | V4 公开配置给出 ,报告常称 token context。 | context length 不是记忆、判断或事实性保证;能放下不等于一定能找对。见 限制。 |
模型族、参数与 tokenizer
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| Flash-Base | Flash 规模的预训练底座。 | ,每 token 激活约 ;主要用于底座能力与架构研究。 | Base 不是默认聊天助手。见 模型族。 |
| Flash | Flash 规模的 post-trained 模型。 | 同样是 ,但经过对话、工具、推理和 OPD 等后训练。 | “Flash 更便宜”是部署倾向,不是所有任务固定更优。见 评测。 |
| Pro-Base | Pro 规模的预训练底座。 | ,每 token 激活约 ;用于观察最大底座能力。 | 不要拿 Base 分数直接和 Think Max 分数混比。见 模型族。 |
| Pro | Pro 规模的 post-trained 模型。 | 容量更大、层更深、隐藏维更宽,适合高难推理、复杂 agent 和知识密集任务候选。 | 上限更高不等于每个业务 prompt 都更划算。见 限制。 |
| total params | checkpoint 中所有参数的总量 。 | Flash 为 ,Pro 为 。 | 总参数代表容量,不等于单 token 计算量。见 MoE/MTP。 |
| activated params | 一个 token 实际走过的参数量 。 | MoE 让 ;每 token 只选 个 routed experts 加 shared expert。 | 不要说 Pro 每个 token 都计算 参数。见 总架构。 |
| vocab size | token id 的可选集合大小 。 | 公开 config 中 ;报告中 是量级简称。 | vocab size 不是模型知识量;它只是 tokenizer 输出空间。见 预训练。 |
| special tokens | 不是自然语言词片段,而是控制结构、边界、工具调用或搜索判断的特殊 token。 | V4 在 DeepSeek-V tokenizer 上新增 context construction tokens,并使用 DSML 与 Quick Instruction tokens。 | 不要把 special tokens 当普通文本随便拼;接入要看 encoding README。见 后训练。 |
| token splitting | 训练中让模型不要过度依赖某些固定合并 token 边界的 tokenizer 技巧。 | V4 继承相关路线,目标是提升对不同切分、代码符号和长文本边界的鲁棒性。 | 它不是增加 vocab size;是训练数据/tokenizer 接口层的稳健性设计。见 预训练。 |
| Fill-in-Middle:给前缀和后缀,让模型补中间。 | 可写作 ;对代码补全和编辑很重要。 | FIM 不是聊天模板;它是预训练/代码数据构造能力。见 预训练。 |
架构原语:Transformer、归一化和位置
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| Transformer | 用 self-attention、FFN/MoE、residual 和归一化反复更新 token 表示的架构骨架。 | V4 仍是 decoder-only causal LM,但在 block 内加入 mHC、CSA/HCA/SWA、DeepSeekMoE 和 MTP。 | 不是“完全新架构”,也不是“普通 Transformer 只扩 RoPE”。见 总架构。 |
| RMSNorm | 按 root mean square 稳定向量尺度:。 | V4 在主干、query 和 compressed KV entry 等位置使用 RMSNorm 来稳定长上下文 logits。 | RMSNorm 不是 LayerNorm 的同名替换;它不减均值。见 总架构。 |
| RoPE | Rotary Positional Embedding:用旋转把位置信息写进 query/key。 | V4 使用 YaRN 风格 scaling 支撑 context,但长上下文效率还依赖 hybrid attention。 | 长上下文不只是 RoPE scaling。见 Attention。 |
| partial RoPE | 只对 head dimension 的一部分施加 RoPE。 | 公开配置中 、,比例为 。 | 不是所有 head 维度都携带位置旋转;这和 shared MQA 配套。见 总架构。 |
| attention sink | 每个 head 的可学习 sink logit,让注意力质量不必全部分给历史 token。 | 在超长上下文中,sink 可降低无关历史被迫吸收注意力的噪声。 | 它不是额外的真实 token,也不是检索器。见 Attention。 |
| query / RMSNorm | 对 query 和 compressed KV entry 分别归一化,再计算相似度。 | V4 用它稳定 CSA/HCA 的 indexer 与 attention logits,报告也因此不再使用 QK-Clip。 | 不要把它说成普通 block norm 的重复;它发生在 attention 内部。见 总架构。 |
| grouped output projection | 把 attention heads 分组后做低秩输出投影,控制输出混合成本。 | Flash 使用 ,Pro 使用 ,公开 output rank 为 。 | 它是 attention 输出投影,不是 MoE expert 分组。见 总架构。 |
| shared MQA | Multi-Query Attention 中多个 query heads 共享更少的 KV 状态;V4 进一步让 compressed 与 共享表示。 | 公开配置中 ,有助于降低 cache 与带宽。 | 不是说 query head 只有一个;是 KV head/压缩状态共享。见 推理缓存。 |
mHC:多 residual stream 和受约束混合
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| Hyper-Connection | 把一条 residual stream 扩成多条可读写、可混合的 stream。 | 可写为 。 | 它不是多头注意力;混合维度是 residual stream,不是 token。见 mHC。 |
| mHC | Manifold-Constrained Hyper-Connections:给 Hyper-Connection 的 residual mixing 加几何约束。 | V4 在 attention site 和 MoE site 周围都使用 mHC,控制深层信号传播。 | mHC 不选择 expert,也不压缩 KV cache;它管 residual topology。见 mHC。 |
| Sinkhorn-Knopp | 反复行归一化、列归一化,把正矩阵投影到近似 doubly stochastic 形式。 | V4 公开配置使用 次迭代生成 。 | 不是训练后处理;它在 forward 中可微执行。见 mHC。 |
| Birkhoff polytope | doubly stochastic 矩阵集合:。 | mHC 要求 residual mixing ,防止深层复合无界放大或吞掉信号。 | “每行和为 ”还不够,列和也必须为 。见 mHC。 |
| 每个 token 维护的 residual stream 数。 | V4 公开值为 ;状态可看作 。 | 不是 attention heads 数,也不是 expert 数。见 mHC。 | |
| state compression | 在 mHC 语境中,指多 residual stream 最终要被控制、读写并在输出侧合回普通 hidden state。 | DeepseekV4HyperHead 会把 条 stream collapse 到 LM head 可用的表示。 | 不要和 CSA/HCA 的 KV compression 混淆;一个管 residual state,一个管历史 cache。见 mHC、Attention。 |
Attention、索引和缓存
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| CSA | Compressed Sparse Attention:先按 压缩历史,再由 query 选相关块。 | Flash 默认 ,Pro 默认 ,由 Lightning Indexer 选 compressed entries。 | CSA 不是全量 dense attention;它是 query-specific sparse retrieval。见 Attention。 |
| HCA | Heavily Compressed Attention:用更强压缩率保留全局摘要。 | V4 中 ,不使用 Lightning Indexer,而是把重压缩 entries 作为全局 compressed view。 | HCA 不是“更差的 CSA”;它解决的是全局摘要,不是 query-specific TopK。见 Attention。 |
| SWA | Sliding Window Attention:只看最近窗口的精细 token 依赖。 | V4 使用 的局部窗口补足 CSA/HCA 压缩后的近邻细节。 | SWA 的 不是最大 context;它只是局部窗口。见 Attention。 |
| Lightning Indexer | 为 CSA 快速选择当前 query 应该读哪些 compressed entries 的索引器。 | 稀疏 attention 引入前要 warm up indexer;QAT 还会让 indexer QK path 使用 。 | 它不是搜索引擎或 RAG;只是 attention 内部的索引选择器。见 预训练、后训练。 |
| hybrid cache | 不同层/不同 attention 类型使用不同 cache 表示和精度。 | V4 同时管理 CSA/HCA compressed cache、SWA tail state cache、 混合存储和磁盘前缀复用。 | 不是一个统一 dense KV 数组;不能用普通 MHA cache 公式直接估算全部细节。见 推理。 |
| on-disk prefix cache | 把已闭合的 compressed prefix blocks 写到磁盘,跨请求复用长前缀。 | 对齐粒度可理解为 ,因为 CSA/HCA compression 需要完整块。 | 不能复用未闭合 tail,也不能保证所有请求命中。见 推理与缓存。 |
MoE、路由与 MTP
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| DeepSeekMoE | 把 FFN 拆成 shared expert 和 routed experts,每个 token 只激活少数专家。 | Flash 每层 routed experts 为 ,Pro 为 ;每 token 选 个 routed experts。 | MoE 省激活计算,但带来 expert load 与 通信。见 MoE/MTP。 |
| expert | MoE 中的一套局部 FFN 参数,可看作专门处理一部分 token/模式的子网络。 | shared expert 处理共同知识,routed experts 由 router 按 token 选择。 | 不要把 expert 解释成人类专家或可读知识库;其专门化通常不可直接解释。见 限制。 |
| router | 根据当前 token hidden state 选择专家集合并给出 gate 权重。 | V4 的 learned router 结合 correction bias、 和原始 score gate。 | router 不是检索外部文档;它只在模型内部选 experts。见 MoE/MTP。 |
| Hash routing | 把 token id 映射到 expert 候选的确定性早期路由方法。 | V4 前 个 MoE layers 使用 Hash routing,降低 learned routing 冷启动风险。 | 不是全模型都用 hash,也不是后训练工具路由。见 总架构。 |
| auxiliary-loss-free load balancing | 不主要靠传统 router auxiliary loss,而用校正偏置影响 TopK 选择来平衡专家负载。 | V4 保留 bias update 和很小 sequence-wise balance loss,目标是减少负载失衡而不过度污染主 LM 目标。 | “auxiliary-loss-free”不等于没有负载均衡。见 预训练。 |
| V4 使用的辅助损失自由路由配置名。 | ,但 gate 权重按原始 score 归一化。 | 不要说 bias 直接进入最终 gate 概率;它主要影响选择。见 MoE/MTP。 | |
| 专家分数校正偏置,用于把过热/过冷 experts 往更均衡方向推。 | 公开训练描述中 bias update 步长量级为 。 | 它不是模型知识参数的主要来源,也不是用户侧可调开关。见 预训练。 | |
| sequence-wise balance loss | 在单条序列内部鼓励专家使用不要过度集中。 | V4 保留很小权重,例如 。 | 它很小,不应被说成主要训练目标。见 预训练。 |
| MTP | Multi-Token Prediction:除下一个 token 外,训练时额外预测更远未来 token。 | V4 使用 的 MTP 模块,增强未来依赖训练信号。 | MTP 是训练信号,不等于 API 一次返回多个 token。见 MoE/MTP。 |
| speculative decoding boundary | 推测解码用便宜模型或额外头猜未来 token,再由主模型验证。 | MTP 可被解读为支持 speculative 路线的训练背景,但公开 config 不能直接推出 V4 线上一定怎样 speculative decoding。 | 不要把 num_nextn_predict_layers 写成产品 API 或线上实现承诺。见 限制。 |
训练、优化器与系统工程
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| Muon | 面向矩阵参数的优化器,把动量梯度近似正交化后更新权重。 | V4 用 Muon 更新大多数矩阵参数,以支持大模型稳定训练。 | Muon 不是完全替代 AdamW;小参数仍走 AdamW。见 预训练。 |
| AdamW | 带 decoupled weight decay 的自适应一阶优化器。 | V4 用 AdamW 更新 embedding、prediction head、RMSNorm、mHC gates/biases 等小而敏感参数。 | 不要说 V4 “只用 Muon”。见 预训练。 |
| hybrid Newton-Schulz | 用多次矩阵乘迭代近似矩阵正交化,避免每步做昂贵 SVD。 | Muon 中的 对梯度方向做结构化处理,V4 用 matmul 支撑系统效率。 | 它不是普通梯度裁剪;目标是更新方向几何。见 系统工程。 |
| dense-to-sparse | 先用 dense attention 训练稳定表示,再切换到 sparse attention。 | V4 在 sequence length 阶段引入 sparse attention,并先 warm up Lightning Indexer。 | 不是从第 步就 sparse。见 预训练。 |
| Anticipatory Routing | 用历史参数提前计算/缓存路由索引,以缓解 loss spike 时的路由不稳定。 | 它服务预训练稳定性,在特定阶段启用以打断 MoE outlier 与 routing 的恶性循环。 | 不是推理功能,也不是永久用旧模型训练。见 预训练。 |
| SwiGLU Clamping | 限制 expert 内部 SwiGLU 激活的异常值。 | V4 用它压住 routed expert outliers,减少训练 loss spike。 | 不是用户侧 decoding trick。见 预训练。 |
| DeepGEMM | DeepSeek 开源的高性能 GEMM/kernel 工程项目。 | 帮助实现 batch-invariant、确定性和 MoE 相关高吞吐矩阵乘路径。 | 它是系统实现背景,不是模型层名称。见 系统工程。 |
| MegaMoE | DeepGEMM 语境下用于 MoE dispatch、两层线性、SwiGLU、combine 的 fused/wave pipeline kernel。 | 目标是降低 MoE expert 动态 shape 带来的 launch、读写和通信重叠成本。 | 不是新的路由算法;router 仍由 MoE 机制决定。见 系统工程。 |
| TileLang | tile 级 kernel 编程模型,用较高层抽象生成高性能算子。 | V4 相关系统中用于 mHC 小矩阵、FP4 indexer、OPD full-vocabulary KL 等特殊 kernel。 | TileLang 是 kernel 工具,不是模型结构。见 系统工程。 |
| Host Codegen | 生成 host 侧 launch、shape 绑定和调度 glue code 的编译能力。 | 服务特殊 kernel 的运行时编排,降低手写边界逻辑错误。 | 不是 neural module,也不改变模型函数。见 系统工程。 |
| Z3 / SMT | 用 satisfiability modulo theories 检查整数索引、shape、tile 边界等约束。 | TileLang 的 compile-time integer expression analysis 会用 Z3 证明索引和边界关系。 | Z3 不只是“帮长上下文切块”;它是一般整数约束分析工具。见 系统工程。 |
| context parallelism / CP | 沿序列维把超长上下文切给多个 rank 处理。 | V4 的 context 需要 CP 处理激活、边界 KV 和压缩 KV 的跨 rank 通信。 | CP 不是 data parallel;它切的是上下文维度。见 系统工程。 |
| DSec | DeepSeek Elastic Compute:用于 agent 后训练/评测的 sandbox 基础设施。 | 结合 Rust gateway、Edge、Watcher、trajectory logging、deterministic replay 和文件系统共享,支撑大规模真实环境 rollout。 | DSec 不是模型架构 block。见 后训练、系统。 |
| Fire-Flyer File System:DeepSeek 开源高性能分布式文件系统。 | 用于理解 checkpoint、镜像、cache、sandbox 文件层和共享存储压力。 | 不能从 推断 DeepSeek API 每条请求路径。见 限制。 | |
| FlashMLA | DeepSeek 开源 attention kernel 库。 | 可作为长上下文 attention kernel 背景;官方仓库主要指向 V3/V3.2/DSA 相关使用。 | 不要写成 V4 架构组件;V4 架构关键词是 CSA/HCA/SWA。见 系统。 |
| TileLink | 用 tile-centric primitives 生成 compute-communication overlap kernel 的研究背景。 | 帮助理解 V4 的 fine-grained EP overlap 和 wave pipeline 为什么围绕 tile/通信阶段设计。 | TileLink 不是 V4 报告命名组件。见 系统工程。 |
后训练、精度和评测指标
| 术语 | 一句话解释 | DeepSeek V 语境 | 常见误解 / 关联章节 |
|---|---|---|---|
| SFT | Supervised Fine-Tuning:用高质量示范答案训练模型按目标格式和行为输出。 | V4 先用 domain-specific fine-tuning 建立 specialist 的基础能力。 | SFT 不会自动发现比示范更强的策略。见 后训练。 |
| GRPO | Group Relative Policy Optimization:同题采样一组回答,用组内相对奖励更新策略。 | V4 specialist RL 使用 GRPO,背景来自 DeepSeekMath/R1 路线。 | GRPO 仍依赖 reward/verifier 质量,不是万能推理开关。见 后训练。 |
| GRM | Generative Reward Model:用生成式评审处理 hard-to-verify 任务。 | V4 用 rubric-guided RL data 和 GRM 评估 policy trajectories。 | GRM 不是简单 scalar reward model;但 reward hacking 风险仍在。见 后训练。 |
| DSML | DeepSeek tool-call markup,用 |DSML| special token 和 XML-like 标签表达工具调用。 | 核心标签包括 <|DSML|tool_calls>、<|DSML|invoke>、<|DSML|parameter>。 | 接入时不要手写猜格式,应看 encoding README/脚本。见 后训练。 |
| interleaved thinking | 工具调用场景中,reasoning content 和工具调用/结果交错保留。 | V4 在 tool-calling 场景保留跨轮 reasoning history,普通对话仍丢弃上一轮 thinking。 | 不是所有对话都保存完整 thinking;产品路径不同。见 后训练。 |
| Quick Instruction | 用专用 special tokens 让主模型完成搜索触发、query/title/authority/domain/URL 等辅助判断。 | 复用已算好的主模型 cache,减少另起模型带来的 TTFT。 | 不是 RAG 本身;它是搜索/工具前置决策接口。见 后训练。 |
| OPD | On-Policy Distillation:学生在自己生成轨迹上学习多个 teacher 的分布。 | V4 用 multi-teacher OPD 合并超过 个 specialist teacher 的能力。 | OPD 不是模型权重平均,也不是多数投票。见 后训练。 |
| reverse | ,按学生分布取期望。 | V4 OPD 用 reverse KL,目标是避免学生把概率放到 teacher 认为低支持的区域。 | 不要和 forward 混淆。见 后训练。 |
| QAT | Quantization-Aware Training:训练/后训练时让模型见到量化误差。 | V4 在 post-training 阶段引入 FP4 QAT,使 rollout 与部署更一致。 | QAT 不等于无损量化;它只是让模型适应误差。见 后训练。 |
| bit 浮点格式,指数 bit、尾数 bit。 | V4 post-trained checkpoints 把 MoE expert weights 和 CSA indexer QK path 等高收益位置推向 FP4。 | 不要说整个模型都是 FP4;多数其他参数仍是 FP8 mixed。见 模型族。 | |
| bit 浮点格式,指数 bit、尾数 bit。 | 公开 quantization config 使用 FP8 mixed precision;Base model card 也标注 FP8 mixed。 | FP8 比 FP4 动态范围大,但也不是“无损原始权重”。见 后训练。 | |
| Think High | 生成显式 <think> 段的高 reasoning effort 模式。 | 用于需要较长推理但不一定使用最高预算的任务。 | 分数不能和 Non-think 直接混比,预算不同。见 评测。 |
| Think Max | 最高 reasoning effort,带特殊 system prompt/instruction、更长预算和不同 length penalty。 | V4 评测中 Max 常用于高难数学、复杂 agent、长上下文任务。 | 不是“用户提示多想一会儿”这么简单;是系统级模式。见 后训练。 |
| 采样 次,至少一次通过的比例。 | 常用于代码/数学等可验证任务,受采样次数和验证器影响。 | 不能和 当同一成本比较。见 评测。 | |
| Exact Match:答案与标准答案完全匹配的比例。 | LongBench-V、问答类任务常用 EM 读长上下文精确命中。 | EM 严格但不总能衡量部分正确或表达等价。见 评测。 | |
| MRCR 任务中的匹配/解析质量指标。 | 用于衡量长上下文多轮指代跟踪能力,尤其在 context 下观察抗干扰。 | 读 MMR 要同时看上下文长度、干扰项和模式。见 评测。 | |
| SWE 类任务中成功修复并通过验证的问题比例。 | 代码 agent/仓库修复任务常用它描述真实 issue 是否被解决。 | 它受 harness、工具权限、交互步数和测试覆盖影响,不只是模型能力。见 评测。 | |
| Accuracy:正确率。 | V4 报告中不同 benchmark 的 口径可能对应选择题、检索问答、agent 完成等不同任务。 | 不同 benchmark 的 Acc 不能脱离样本、工具、prompt 和预算横向硬比。见 评测。 |
Cite
参考资料与阅读路线
本节不是无序链接堆,而是把前文材料按证据强度分层。读者先用官方主源确认事实,再用实现文档理解落地, 最后才看论文背景和社区评论。凡是本文写成 官方明确 的主张,必须能回到 DeepSeek 技术报告、模型仓库、配置文件、encoding 文档或 DeepSeek API 发布页;凡是 工程推断 或 评论/解读,只能作为理解路线,不能替代官方事实。
第一遍:事实核对
从 DeepSeek V PDF、HF 四个模型仓库、
config.json、encoding 和 API 发布页开始,确认参数规模、上下文上限、量化格式、
模型模式和评测口径。
第二遍:实现边界
读 Transformers、vLLM 和 Megatron Bridge,理解 、 cache、tool parser、reasoning parser、parallelism 和 serving 约束。它们是相关实现,不代表 DeepSeek 官方线上服务的全部细节。
第三遍:背景与评论
用 DeepSeek-V、DeepSeekMoE、MTP、Muon、mHC、GRPO、OPD、QAT 和系统工程资料解释来龙去脉;SyntaxDispatch、Medium、MarkTechPost 等只用于了解业界关注点和常见误读。
官方主源:可直接支持 V 事实
- 官方主源 DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. 支持:模型族总览、 Pro、 Flash、 token context、Hybrid Attention、mHC、Muon、MTP、MegaMoE、 DSec、QAT、OPD、评测表和限制。用于:全文所有“官方明确”结论,尤其模型族、架构、训练、系统、后训练、评测、限制。
- 官方发布 DeepSeek-V4 HF collection、 Pro、 Flash、 Pro-Base、 Flash-Base 模型仓库; 以及 ModelScope 镜像: Pro、 Flash、 Pro-Base、 Flash-Base。 支持:checkpoint 名称、下载入口、license、权重格式和模型家族归属。用于:模型族、接入与部署章节。
- 官方配置 Pro config、
Flash config、
Pro-Base config、
Flash-Base config。
支持:
max_position_embeddings、layer types、MoE / hash routing / mHC / attention 参数、tokenizer 与模型类声明。 用于:模型族、架构、Attention、推理、术语表。 - 官方接口 DeepSeek-AI. encoding README 与 encoding_dsv4.py。 支持:V 不提供 Jinja chat template、如何把 OpenAI-compatible messages 编码为输入串、如何解析 completion、thinking mode 和 special tokens 的边界。用于:后训练、API 接入、术语表。
- 官方发布 DeepSeek API Docs. DeepSeek V4 Preview Release. 支持:API 模型名、Expert/Instant 或 Thinking/Non-Thinking 产品说法、官方服务 context 宣称、旧模型退役时间和 API 兼容性提示。用于:基础、模型族、评测、限制。注意:产品发布页的营销表述仍要和技术报告、评测协议分开读。
官方/实现文档:用于落地,不自动等同于 DeepSeek 官方服务
- 相关实现 Hugging Face Transformers. DeepSeek-V4 model documentation. 支持:Transformers 对 V 的 config、attention layer、cache layer、mHC、MoE routing、 mask layout 和示意图复现实验。用于:架构、Attention、推理、术语表。边界:这是 HF 实现文档,不是 DeepSeek 训练细节披露。
- 解读/实现入口 Hugging Face. DeepSeek-V4: a million-token context that agents can actually use. 支持:HF 对四个 checkpoint、reasoning modes、agent workloads 和 Hub 使用方式的解读。用于:基础、评测、限制。 边界:博客中的价值判断和行业判断是解读;具体指标仍回到 DeepSeek 报告。
- 相关实现
vLLM. DeepSeek V4 in vLLM: Efficient Long-context Attention.
支持:vLLM serving 参数、
tokenizer-mode deepseek_v4、tool/reasoning parser、 KV cache、 indexer cache 和长上下文显存估算。用于:推理与缓存、系统工程、接入。 边界:这些是 vLLM 公开实现和部署建议,不代表 DeepSeek 官方线上服务配置。 - 相关实现 NVIDIA Megatron Bridge. DeepSeek V4 docs. 支持:Megatron Bridge 对 V model features、parallelism、checkpoint conversion、inference scripts 和 known limitations 的整理。用于:系统工程、推理、面试。边界:这是 NVIDIA 生态实现文档,不能替代官方报告。
背景论文:解释机制来源,不单独证明 V 采用细节
- 背景论文 DeepSeek-AI. DeepSeek-V3 Technical Report. 支持:DeepSeek-V 的 MLA、DeepSeekMoE、auxiliary-loss-free load balancing、MTP、训练稳定性和 V 对比基线。用于:架构、MoE/MTP、训练、限制。
- 背景论文 Dai et al. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. 支持:fine-grained routed experts、shared experts、expert specialization 的基础概念。用于:MoE/MTP、术语表、面试。
- 背景论文 Gloeckle et al. Better & Faster Large Language Models via Multi-token Prediction. 支持:MTP 作为训练目标的动机、收益和与一次生成多个 token 的区别。用于:MoE/MTP、训练、术语表。
- 背景论文 Jordan et al. Muon is Scalable for LLM Training. 支持:Muon 优化器、orthogonalized momentum / update geometry 的背景。用于:训练、系统工程、面试。
- 背景论文 Hyper-Connections 与 mHC: Manifold-Constrained Hyper-Connections. 支持:多 residual stream、doubly stochastic / Sinkhorn 约束、identity mapping 与深层训练稳定性的背景。用于:mHC、架构、术语表。
- 背景论文 DeepSeek-AI. DeepSeekMath 与 Schulman et al. Proximal Policy Optimization Algorithms. 支持:GRPO/RL 路线和 PPO 对比的基础语境。用于:后训练、评测、面试。边界:V 的 GRPO 具体使用以 V 报告为准。
- 背景论文 Ouyang et al. Training language models to follow instructions with human feedback 与 Bai et al. Constitutional AI: Harmlessness from AI Feedback. 支持:RLHF、RLAIF、preference model、reward model 和 alignment 后训练的基础概念。用于:后训练、限制。边界:它们不证明 V 使用同一 RLHF/RLAIF 配方,只解释术语来源。
- 背景论文 Song and Zheng. A Survey of On-Policy Distillation for Large Language Models. 支持:OPD 的 on-policy student trajectories、teacher feedback、-divergence / KL 视角和 exposure bias 背景。用于:后训练、系统工程。边界:V 的 multi-teacher reverse 仍以官方报告为准。
- 背景论文 Jacob et al. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. 支持:QAT 与 PTQ 的基本差别、训练时适应量化误差的思想。用于:后训练、推理、术语表。边界:V 的 边界以报告和 model card 为准。
系统工程资料:说明工程背景和边界
- 官方明确 DeepSeek V PDF 的系统章节。支持:MegaMoE、batch-invariant decoding、deterministic kernels、 prefix cache、DSec sandbox、rollout WAL、shared-memory dataloader 和 在 V 语境里的作用。用于:系统工程、推理、后训练、限制。
- 相关实现 DeepSeek-AI. DeepGEMM. 支持: GEMM、MoE grouped GEMM、Lightning Indexer scoring、HC kernels 和 MegaMoE fused / overlapped kernel 的工程背景。用于:系统工程、训练、推理。边界:仓库是 kernel 库,不是 V 架构模块说明书。
- 系统背景 Tile-AI. TileLang paper、 TileLang GitHub 与 Z3 theorem prover. 支持:tile-level kernel DSL、FlashAttention/MLA 类 kernel 示例、Z3/SMT symbolic reasoning 用于索引和边界正确性分析。 用于:系统工程、OPD full-vocabulary kernel、术语表。
- 系统背景 DeepSeek-AI. 3FS: Fire-Flyer File System、 Linux kernel. EROFS documentation、 containerd. overlaybd. 支持:高性能分布式文件系统、只读镜像层和远程 block image 的背景知识。用于:DSec sandbox、文件系统共享、checkpoint/cache、限制。 边界:DSec 的具体架构和使用方式来自 V 报告。
- 系统背景 DeepSeek-AI. FlashMLA. 支持:DeepSeek 生态中的 MLA attention kernel、KV cache 低层实现背景和长上下文 kernel 压力。用于:系统工程、Attention 边界。 边界:FlashMLA 不是 V 报告命名的 Hybrid Attention 架构组件。
- 系统背景 Zheng et al. TileLink: Generating Efficient Compute-Communication Overlapping Kernels using Tile-Centric Primitives. 支持:计算和通信重叠、tile-centric primitives、EP overlap 的一般工程背景。用于:系统工程、MoE/MegaMoE 边界。 边界:TileLink 不是 V 报告中的组件名。
评测资料:解释分数口径和 benchmark 边界
- 官方明确 DeepSeek V PDF 的 evaluation tables 与 figures。 支持:Base/Instruct、Non-Think/High/Max、、 、、 、CorpusQA、Agentic Search、internal R&D workload 等分数。 用于:评测、面试、限制。边界:报告分数依赖 prompt、工具、预算、harness 和评测时间,不能脱离协议横比。
- benchmark LongBench-V. 支持:realistic long-context multitasks、长度分布、multiple-choice 可靠评分和长上下文理解/推理边界。用于:评测、限制。
- benchmark OpenAI. MRCR dataset card. 支持:multi-round coreference resolution、长上下文多 needle 跟踪、SequenceMatcher ratio 等评分背景。用于:评测、术语表。
- benchmark OpenAI. Introducing SWE-bench Verified. 支持:human-validated SWE-bench subset、coding agent 修复任务的 口径。 用于:评测、限制。边界:SWE Pro、SWE Multilingual 和内部 agent harness 的细节以 V 报告为准。
- benchmark LiveCodeBench. 支持:contamination-free code benchmark、按日期切分、 代码评测口径。 用于:评测、面试。
- benchmark LeanExplore 与 PutnamBench. 支持:Lean declaration search、formal proof verifier、Putnam 形式化 benchmark。 用于:formal reasoning、评测、面试。边界:DeepSeek 的 Putnam 子集和采样预算以报告为准。
- benchmark Merrill et al. Terminal-Bench、 Scale Labs. MCP-Atlas、 Toolathlon. 支持:terminal/container 任务、MCP 工具编排、multi-tool agent task 和 工具能力口径。用于:评测、系统工程、限制。
- benchmark OpenAI. BrowseComp / BrowseComp release page 与 GDPval release page. 支持:agentic browsing、short-answer verifiable search、white-collar task proxy 和真实任务评测边界。用于:评测、限制。 边界:DeepSeek 报告中的 Agentic Search 和 CorpusQA 仍以报告原表为准。
业界解读与二手评论:只能作为阅读入口
- 评论/解读 Syntax Dispatch review. 支持:长上下文、稀疏注意力和工程可用性的社区解读。用于:基础、Attention、限制。边界:不作为参数、评测或训练事实来源。
- 评论/解读 Artgor. DeepSeek V4 review on Medium. 支持:百万 token context 为什么需要 efficient attention 的二手解释。用于:基础、Attention、限制。边界:正文任何官方数字仍回到 report/model card/config。
- 评论/解读 MarkTechPost. DeepSeek AI releases DeepSeek-V4 article. 支持:行业媒体对 CSA/HCA、 context 和发布信息的摘要。用于:Attention、限制。 边界:媒体摘要可能压缩或改写原意,引用事实时优先使用 DeepSeek 官方源。