从零实现 LLM Inference:002. KV-Cache
再实现了 greedy generate 之后,我们接下来来实现 kv-cache 部分,之前我们每次生成一个新的 token,都要把过去的所有 token 都过一遍 forward,但是实际上其中过往历史的 kv-cache 是可以复用的,这样之后没生成一个新 token 的时候,只需要把前一个 token 过一下 forward 就行了。
代码变更
首先我们需要改模型的部分,让模型的 attention layer 能够处理推理时的 kv-cache,此处我们要从入口传入旧的 kv-cache,然后返回新的 kv-cache(为什么不在 class 里面存 kv-cache 字段?因为这样会导致 class 变成有状态的,会和请求绑定)。
rosetrainer/model.py
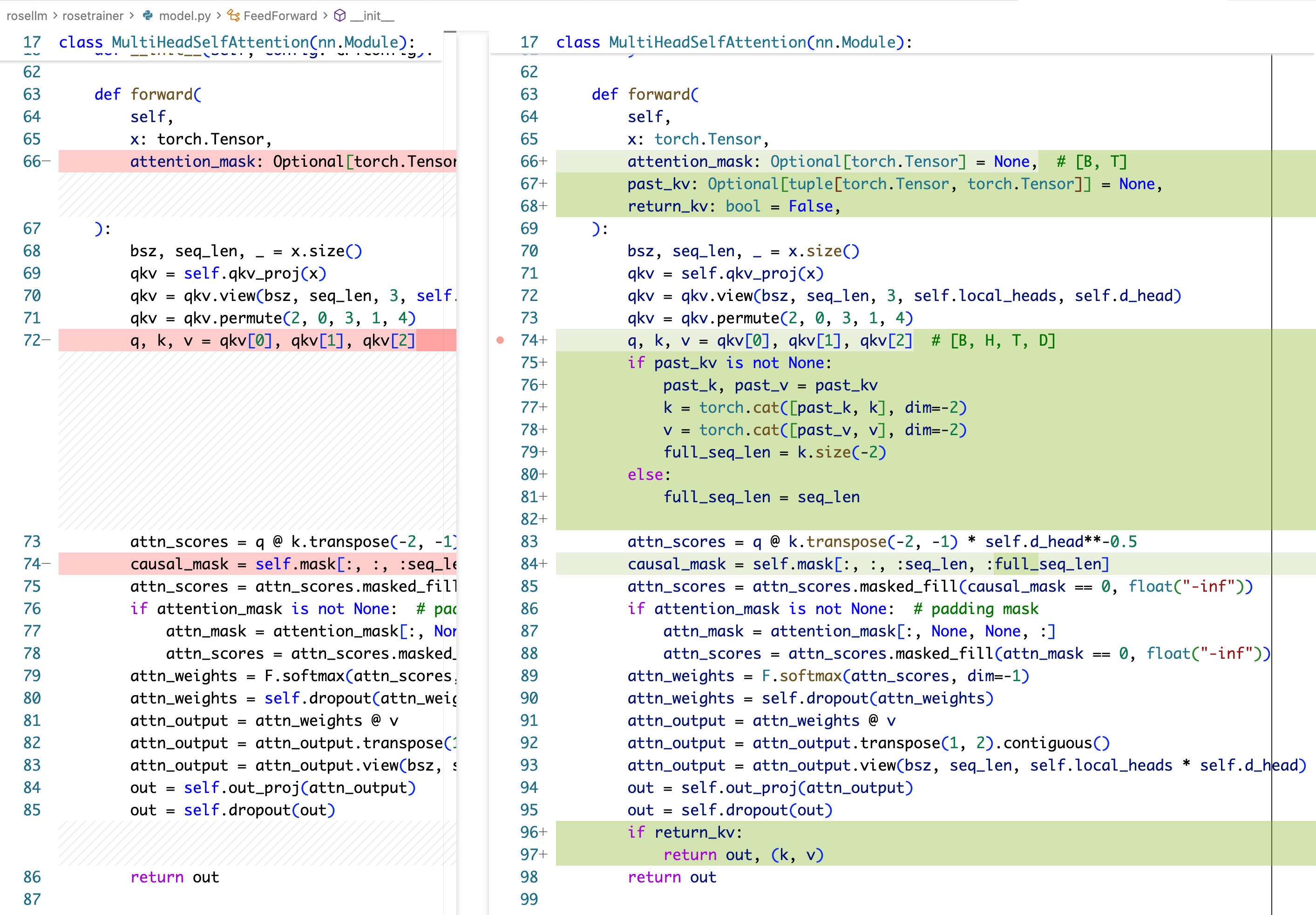
入参要加上 past_kv,还有一个 return_kv 的 bool 变量,在生成当前的 q,k,v 之后,要把新的 k,v 拼到 past_kv 后面。
!!!注意,以上代码有个严重的 bug,causal_mask 不但需要改后面的 full_seq_len,还需要改第一个维度:
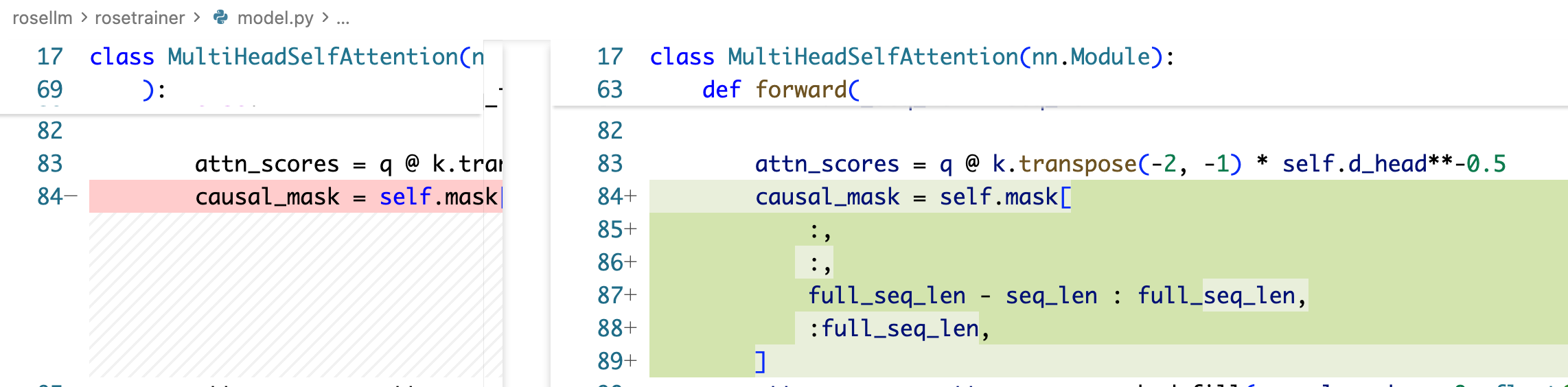
相当于我们在 decode 的时候只传了一个 token,实际上 seq_len 是 1,然后他需要 attention mask 中间的位置,也就是 full_seq_len-seq_len 到 full_seq_len 的这部分 mask。
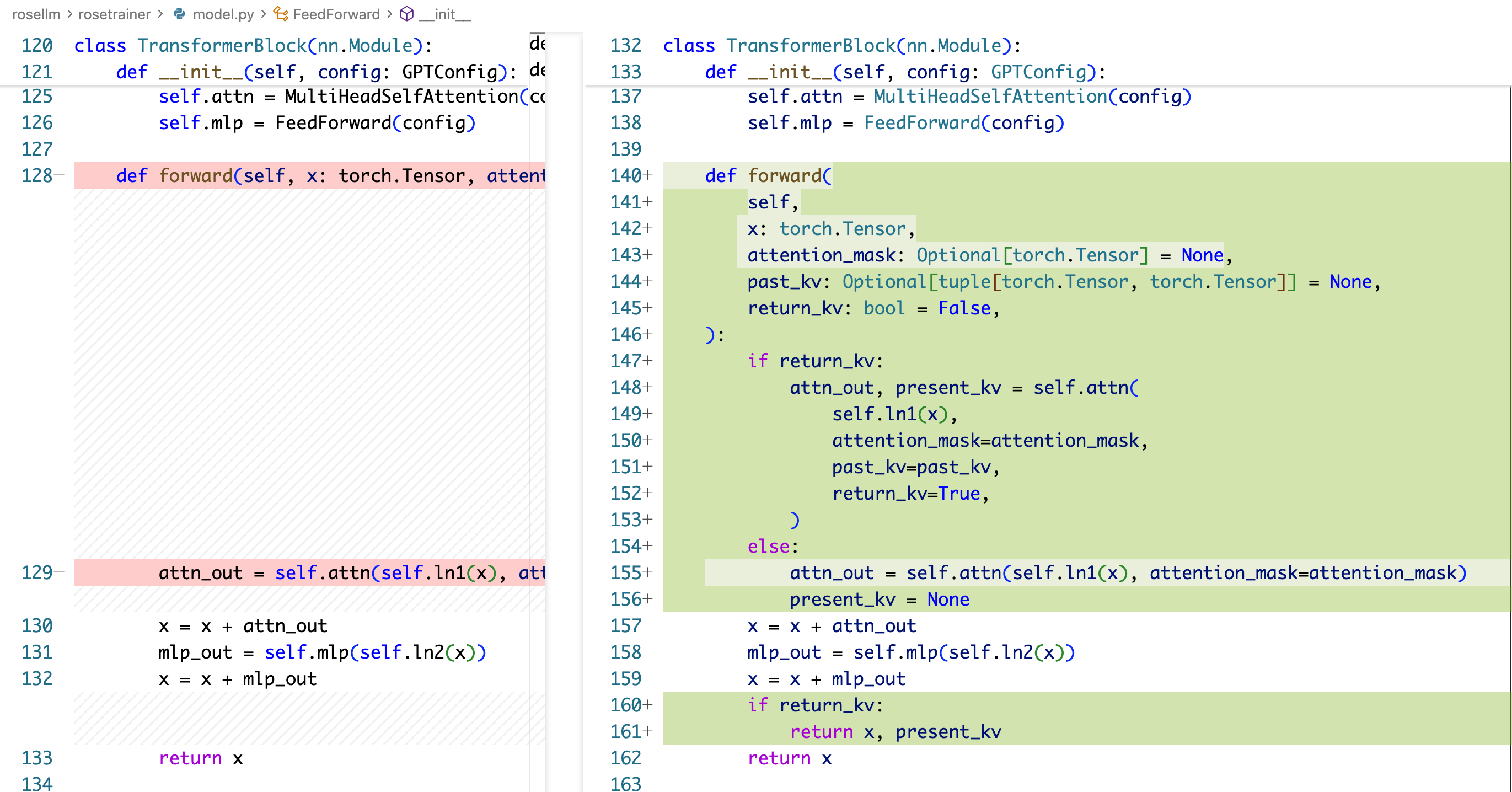
在 TransformerBlock 部分,同样是添加 past_kv 和 return_kv 这两个入参,并进行透传。
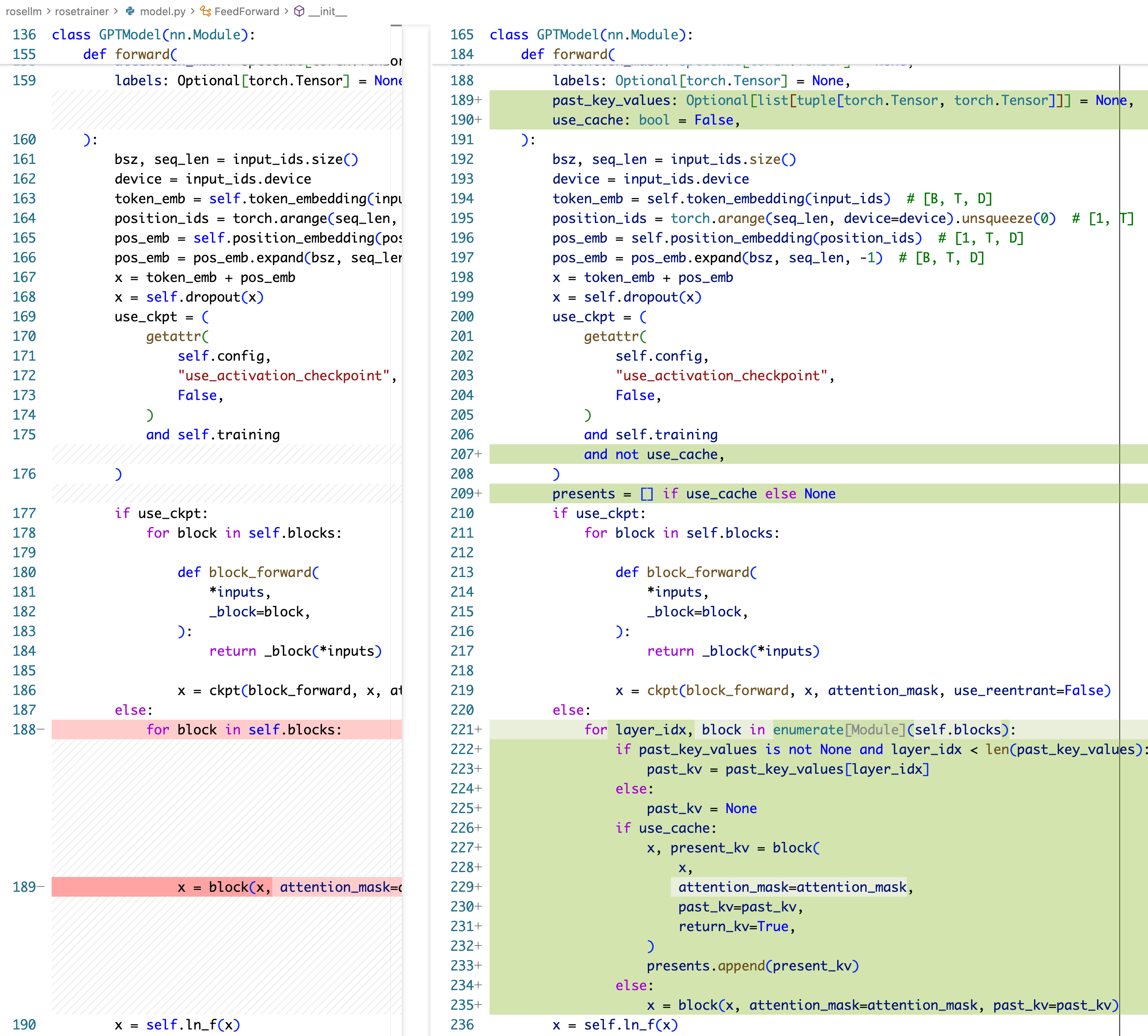
在 GPTModel 的 forward,则是需要添加 past_kv 入参,和 use_cache 入参,use_cache 主要来控制不使用 activation checkpointing(推理时不需要这个),然后在各个 block forward 的时候去收集一下各个 block 的 kv-cache。
!!!注:以上代码也有一个严重的 bug,由于我们 decode 的时候每次新传一个 token,但是他的实际 position 需要加上 past_kv 的长度,因此要这样写:
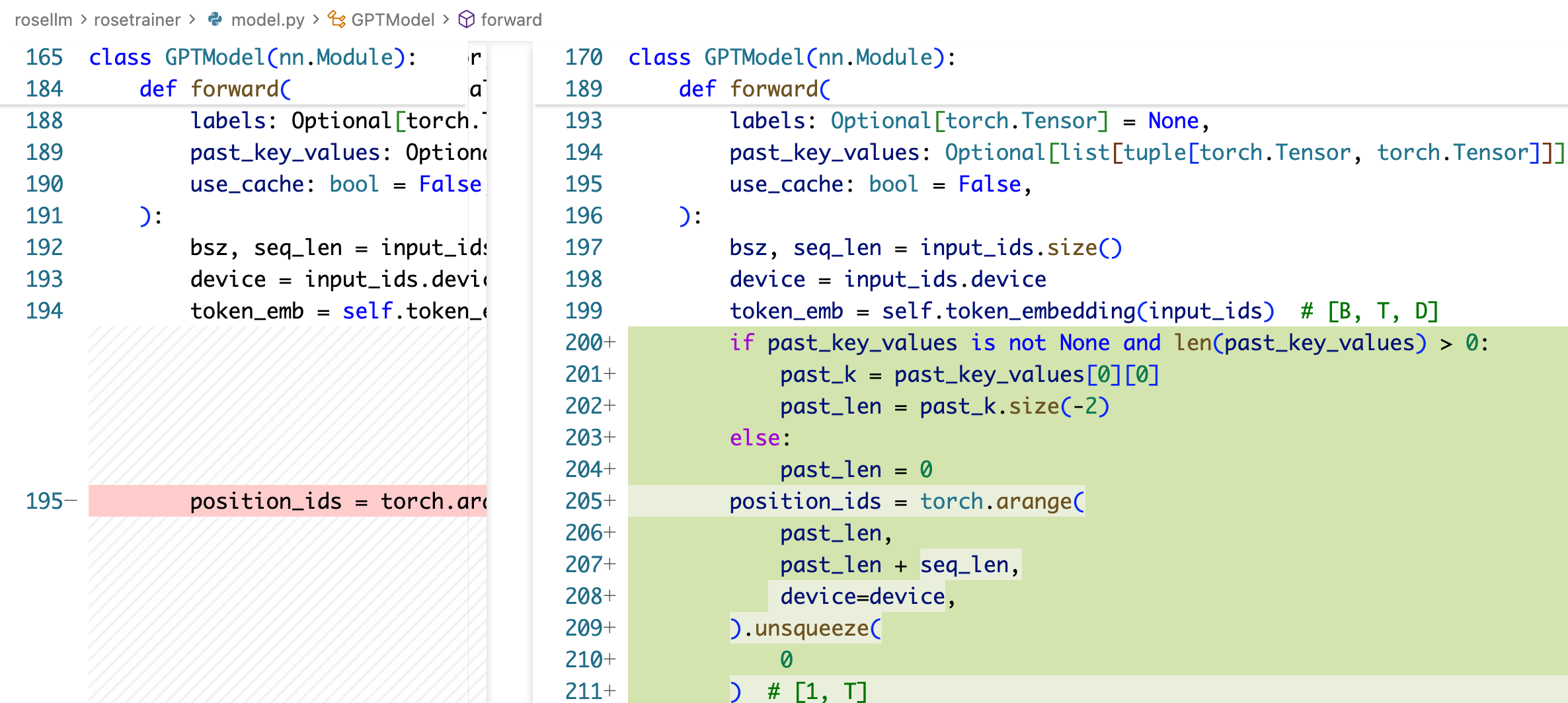
主要就是 position_ids 不应该还是 torch.arange(seq_len),而应该是 torch.arange(past_len, past_len+seq_len) 这里。
运行
把之前的生成再跑一遍:
$ python -m roseinfer.cli_generate --checkpoint-path rosetrainer/checkpoints/gpt2_small_minimal.pt --prompt "hello" --
tokenizer-name "gpt2"
[roseinfer] device: cuda
[roseinfer] use_amp: True
[roseinfer] prompt: hello
[roseinfer] output: hello...