从零实现 LLM Inference:003. Sampling
本 PR 来做 top-k top-p 这种 sampling 操作,并把整体的 prefill decode 流程规范化,对齐业界 vllm,huggingface 的实现。
代码变更
engine.py
添加 top-k top-p sample_next_token 三个方法:
class InferenceEngine:
# ...
def _top_k_logits(
self,
logits: torch.Tensor, # [..., vocab]
top_k: int,
) -> torch.Tensor:
if top_k <= 0:
return logits
values, _ = torch.topk(logits, top_k) # [..., k]
min_values = values[..., -1, None] # [..., 1]
return torch.where( # [..., vocab]
logits < min_values,
torch.full_like(logits, float("-inf")),
logits,
)
def _top_p_logits(
self,
logits: torch.Tensor, # [..., vocab]
top_p: float,
) -> torch.Tensor:
if top_p <= 0.0 or top_p >= 1.0:
return logits
sorted_logits, sorted_idx = torch.sort( # [..., vocab]
logits,
descending=True,
)
probs = torch.softmax(sorted_logits, dim=-1) # [..., vocab]
cum_probs = torch.cumsum(probs, dim=-1) # [..., vocab]
mask = cum_probs > top_p # [..., vocab]
mask[..., 0] = False # keep at least one token
sorted_logits = sorted_logits.masked_fill(
mask,
float("-inf"),
)
_, inv_idx = torch.sort(
sorted_idx,
dim=-1,
)
logits_filtered = torch.gather(
sorted_logits,
dim=-1,
index=inv_idx,
)
return logits_filtered
def _sample_next_token(
self,
logits: torch.Tensor, # [..., vocab]
temperature: float,
top_k: int,
top_p: float,
do_sample: bool,
) -> int:
if not do_sample or temperature <= 0.0:
next_token = torch.argmax(logits, dim=-1) # [..., 1]
return int(next_token.item())
scaled = logits / float(temperature)
filtered = self._top_k_logits(scaled, top_k)
filtered = self._top_p_logits(filtered, top_p)
probs = torch.softmax(filtered, dim=-1) # [..., vocab]
probs = probs.clamp_min(1e-9)
next_token = torch.multinomial(probs, num_samples=1)[:, 0] # [..., 1]
return int(next_token.item())
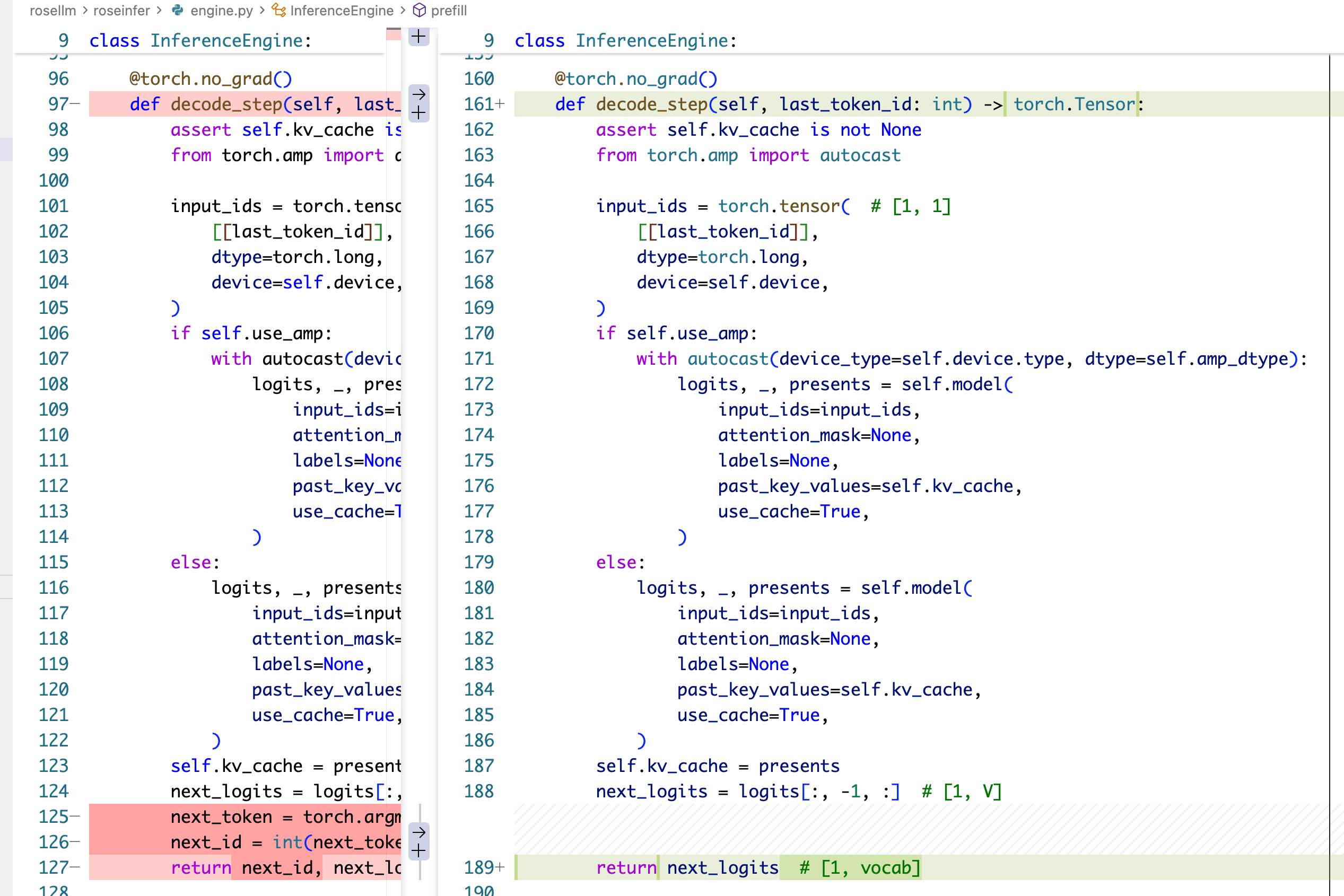
然后改一下 decode 的实现,让他返回 next_logits:
generate 部分则需要大改:
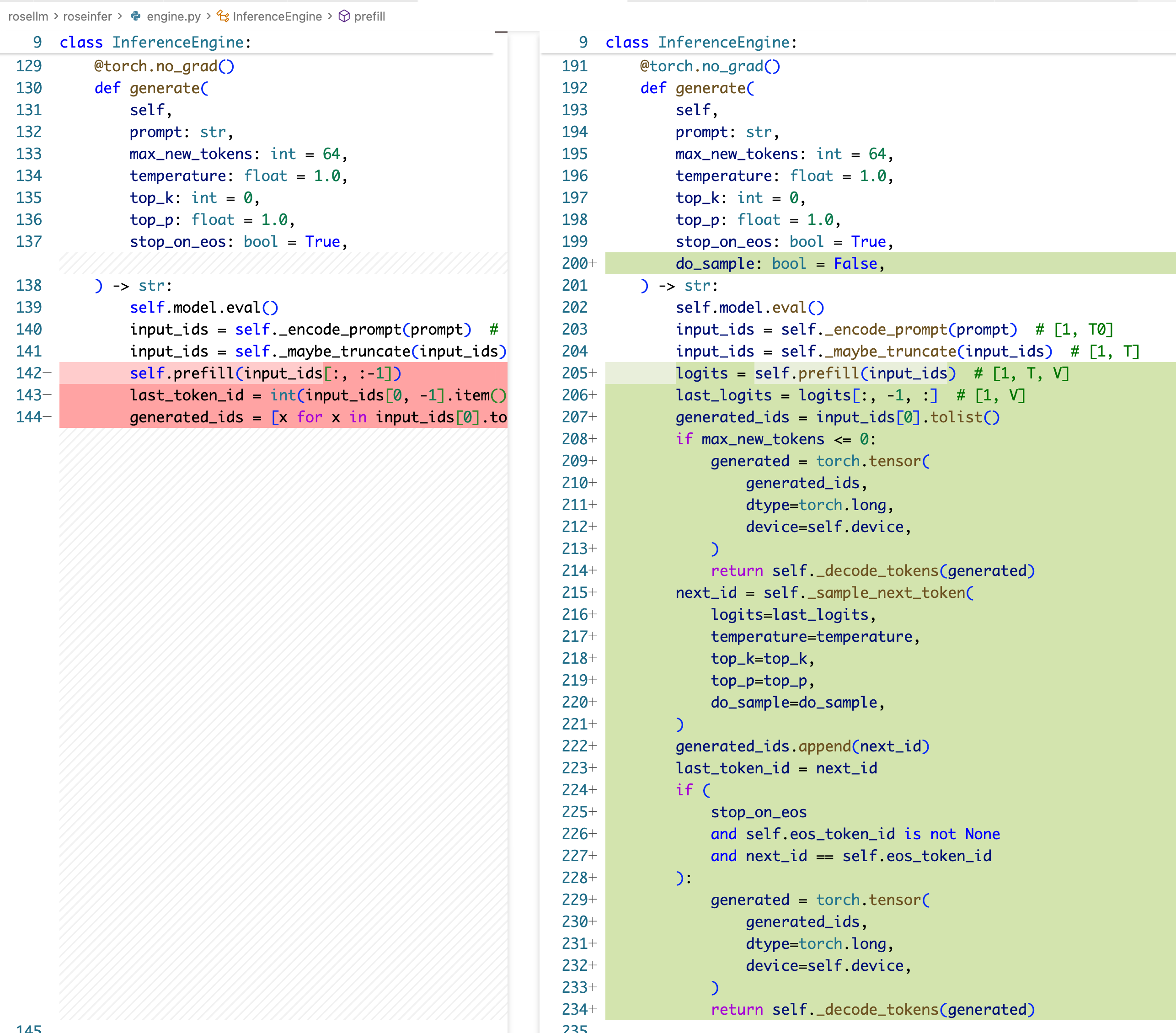
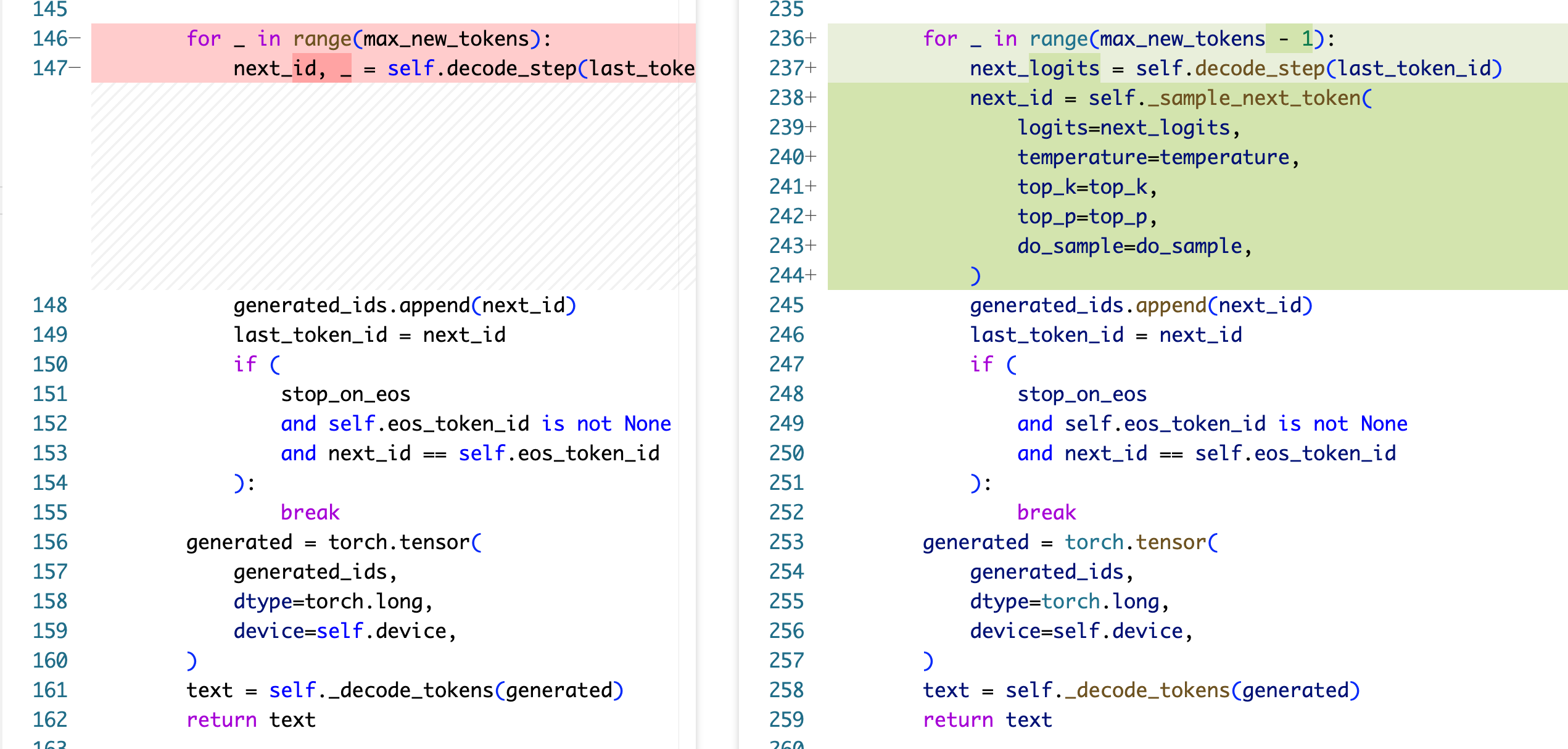
这里有一些比较 subtle 的地方,首先,在 prefill 的时候,是所有的 prompt id 都喂给 prefill,这个时候能得到下一个 token 的 logits,然后我们需要用这个 logits 单独调一下 sample 方法,得出来第一个生成的 token,然后把这个 token 作为 last_token id,正式进入后面的 decode 循环,decode 训练只循环 max_new_tokens-1 次 step,因为我们已经在前面生成了第一个 token!for loop 中每一步就是先走一下 decode_one_step 拿到 next token 的 logits,然后再用 sample 方法去得到要生成的 token。
你会发现这里需要在 for loop 前单独走一下 sample,感觉不是很优雅,所以你说,我们 prefill 的时候可以少走一个 prompt id,把最后一个空出来,这样的话把最后一个没走的 token 作为 last_token id,那么 prefill 后面就能紧接着 for loop decode,但是这样是有问题的,他会影响 Time-To-First-Token (TTFT)的时间,使得第一个 token 的产生没那么及时。
运行
看看效果:
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm$ python -m roseinfer.cli_generate --checkpoint-path rosetrainer/checkpoints/gpt2_small_ddp.pt --tokenizer-name gpt2 --do-sample --temperature 0.8 --top-k 40 --top-p 0.95 --max-new-tokens 64 --prompt "I am"
[roseinfer] device: cuda
[roseinfer] use_amp: True
[roseinfer] prompt: I am
[roseinfer] output: I am a day, and also be an idea of your brain-18.
The United States) and their environment, I was considered to the development is also have been seen a group.
In the two, the most high and the way to a good that the year.
The idea is a "T’
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm$ python -m roseinfer.cli_generate --checkpoint-path rosetrainer/checkpoints/gpt2_small_ddp.pt --tokenizer-name gpt2 --do-sample --temperature 0.8 --top-k 40 --top-p 0.95 --max-new-tokens 64 --prompt "You are"
[roseinfer] device: cuda
[roseinfer] use_amp: True
[roseinfer] prompt: You are
[roseinfer] output: You are a new ways in the health. The following the new world of the day, and the most of the new new system.
The most of the world in the development, you are a part to the first all, the "t, a different in the use and their children.
--’s�
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm$