从零实现 LLM Inference:005. Streaming
本文 PR 来做流式生成(streaming),我们已经做了基础的生成、kv-cache、采样、batch,现在我们需要做一些流式生成。
一个拍脑袋的想法是,每生成一个 token,我就用 tokenizer decode 一下,然后把 decode 的结果返回,但是这里是有问题的,因为对于 gpt2 bpe tokenizer 来说,他是对 utf-8 bytes 进行编码的,一个 token decode 回去之后是 utf-8 的部分 bytes,很有可能不是一个完整的 utf-8 编码。所以我们需要用一个 utf-8 的 incremental decoder,每次喂一个 token 对应的 bytes,然后返回能正确 decode 出来的增量合法 utf-8 字符串。对于非 gpt2 bpe 族的 tokenizer 来说,我们可以攒 token,每次重复对所有 token 做 decode,然后只输出之前没有输出的字符串。
代码变更
detokenizer.py
其中 GPT2ByteDetokenizer 是主要路径,会做 utf-8 的增量 decode,PrefixDiffDetokenizer 则是 fallback 路径,用来处理其他类型的 tokenizer,性能会稍差一点:
from __future__ import annotations
import codecs
from typing import List
from transformers import PreTrainedTokenizerBase
try:
import tiktoken
except ImportError:
tiktoken = None
class BaseDetokenizer:
def reset(self) -> None:
raise NotImplementedError
def start_prompt(
self,
prompt_ids: List[int],
) -> None:
raise NotImplementedError
def on_token(
self,
token_id: int,
) -> str:
raise NotImplementedError
def flush(self) -> str:
return ""
class GPT2ByteDetokenizer(BaseDetokenizer):
def __init__(
self,
hf_tokenizer: PreTrainedTokenizerBase,
model_name: str = "gpt2",
) -> None:
if tiktoken is None:
raise ImportError("need to install tiktoken")
self.hf_tokenizer = hf_tokenizer
self.enc = tiktoken.encoding_for_model(model_name)
self.decoder = codecs.getincrementaldecoder(
"utf-8",
)(errors="replace")
def reset(self) -> None:
self.decoder = codecs.getincrementaldecoder(
"utf-8",
)(errors="replace")
def start_prompt(
self,
prompt_ids: List[int],
) -> None:
self.reset()
def on_token(
self,
token_id: int,
) -> str:
token_bytes = self.enc.decode_single_token_bytes(token_id)
text_piece = self.decoder.decode(token_bytes)
return text_piece
def flush(self) -> str:
return self.decoder.decode(
b"",
final=True,
)
class PrefixDiffDetokenizer(BaseDetokenizer):
def __init__(
self,
hf_tokenizer: PreTrainedTokenizerBase,
) -> None:
self.tok = hf_tokenizer
self.generated_ids: List[int] = []
self.last_text: str = ""
def reset(self) -> None:
self.generated_ids = []
self.last_text = ""
def start_prompt(
self,
prompt_ids: List[int],
) -> None:
self.reset()
self.generated_ids = prompt_ids.copy()
self.last_text = self.tok.decode(
self.generated_ids,
skip_special_tokens=True,
)
def on_token(
self,
token_id: int,
) -> str:
self.generated_ids.append(token_id)
full = self.tok.decode(
self.generated_ids,
skip_special_tokens=True,
)
delta = full[len(self.last_text) :]
self.last_text = full
return delta
engine.py
engine.py 主要是在用新增的这个 detokenizer,实现了 stream_generate 和 stream_generate_batch,并把默认 right padding 改成了 left padding 以更符合业界的实现。
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
index 6949bc7..47ec839 100644
--- a/rosellm/roseinfer/engine.py
+++ b/rosellm/roseinfer/engine.py
@@ -1,10 +1,20 @@
-from typing import Optional
+from typing import Iterator, Optional
import torch
+from roseinfer.detokenizer import (
+ BaseDetokenizer,
+ GPT2ByteDetokenizer,
+ PrefixDiffDetokenizer,
+)
from rosetrainer.config import GPTConfig
from rosetrainer.dataset import build_tokenizer
from rosetrainer.model import GPTModel
+try:
+ import tiktoken
+except ImportError:
+ tiktoken = None
+
class InferenceEngine:
def __init__(
@@ -43,6 +53,17 @@ class InferenceEngine:
self.model.eval()
self.tokenizer = build_tokenizer(tokenizer_name)
self.eos_token_id = self.tokenizer.eos_token_id
+
+ def make_detok() -> BaseDetokenizer:
+ if tokenizer_name.startswith("gpt2") and tiktoken is not None:
+ try:
+ return GPT2ByteDetokenizer(self.tokenizer)
+ except Exception as e:
+ print(f"failed to create GPT2ByteDetokenizer: {e}")
+ return PrefixDiffDetokenizer(self.tokenizer)
+
+ self._make_detok = make_detok
+
self.kv_cache = None
if self.config.vocab_size < self.tokenizer.vocab_size:
raise ValueError("the model vocab_size is less than tokenizer vocab_size")
@@ -78,8 +99,8 @@ class InferenceEngine:
masks = []
for ids in all_ids:
pad_len = max_len - len(ids)
- batch.append(ids + [pad_id] * pad_len)
- masks.append([1] * len(ids) + [0] * pad_len)
+ batch.append([pad_id] * pad_len + ids)
+ masks.append([0] * pad_len + [1] * len(ids))
input_ids = torch.tensor(
batch,
dtype=torch.long,
@@ -255,17 +276,7 @@ class InferenceEngine:
use_cache=True,
)
self.kv_cache = presents
- if attention_mask is None:
- last_logits = logits[:, -1, :] # [batch, vocab]
- else:
- batch_size = logits.size(0)
- lengths = attention_mask.sum(dim=1).to(dtype=torch.long) # [B]
- last_indices = lengths - 1 # [B]
- batch_indices = torch.arange(
- batch_size,
- device=logits.device,
- )
- last_logits = logits[batch_indices, last_indices, :] # [B, vocab]
+ last_logits = logits[:, -1, :] # [batch, vocab]
return last_logits
@torch.no_grad()
@@ -422,7 +433,9 @@ class InferenceEngine:
attention_mask=attn_mask,
)
lengths = attn_mask.sum(dim=1).tolist()
- generated_ids = [input_ids[b, : lengths[b]].tolist() for b in range(batch_size)]
+ generated_ids = [
+ input_ids[b, -lengths[b] :].tolist() for b in range(batch_size)
+ ]
if max_new_tokens <= 0:
outputs = []
for ids in generated_ids:
@@ -499,3 +512,202 @@ class InferenceEngine:
text = self._decode_tokens(t)
outputs.append(text)
return outputs
+
+ @torch.no_grad()
+ def stream_generate(
+ self,
+ prompt: str,
+ max_new_tokens: int = 64,
+ temperature: float = 1.0,
+ top_k: int = 0,
+ top_p: float = 1.0,
+ stop_on_eos: bool = True,
+ do_sample: bool = False,
+ ) -> Iterator[str]:
+ self.model.eval()
+ token_ids = self.tokenizer.encode(
+ prompt,
+ add_special_tokens=False,
+ )
+ if not token_ids:
+ token_ids = [self.eos_token_id]
+ ids_tensor = torch.tensor(
+ [token_ids],
+ dtype=torch.long,
+ device=self.device,
+ )
+ detok = self._make_detok()
+ detok.start_prompt(token_ids)
+ prefill_logits = self.prefill(ids_tensor) # [1, T, V]
+ last_logits = prefill_logits[:, -1, :] # [1, V]
+ if max_new_tokens <= 0:
+ piece = detok.flush()
+ if piece:
+ yield piece
+ return
+ next_id = self._sample_next_token(
+ logits=last_logits,
+ temperature=temperature,
+ top_k=top_k,
+ top_p=top_p,
+ do_sample=do_sample,
+ )
+ piece = detok.on_token(next_id)
+ if piece:
+ yield piece
+ if (
+ stop_on_eos
+ and self.eos_token_id is not None
+ and next_id == self.eos_token_id
+ ):
+ tail = detok.flush()
+ if tail:
+ yield tail
+ return
+ last_token_id = next_id
+ for _ in range(max_new_tokens - 1):
+ next_logits = self.decode_step(last_token_id) # [1, V]
+ next_id = self._sample_next_token(
+ logits=next_logits,
+ temperature=temperature,
+ top_k=top_k,
+ top_p=top_p,
+ do_sample=do_sample,
+ )
+ piece = detok.on_token(next_id)
+ if piece:
+ yield piece
+ last_token_id = next_id
+ if (
+ stop_on_eos
+ and self.eos_token_id is not None
+ and next_id == self.eos_token_id
+ ):
+ break
+ tail = detok.flush()
+ if tail:
+ yield tail
+
+ @torch.no_grad()
+ def stream_generate_batch(
+ self,
+ prompts: list[str],
+ max_new_tokens: int = 64,
+ temperature: float = 1.0,
+ top_k: int = 0,
+ top_p: float = 1.0,
+ stop_on_eos: bool = True,
+ do_sample: bool = True,
+ ) -> Iterator[list[str]]:
+ self.model.eval()
+ batch_size = len(prompts)
+ if batch_size == 0:
+ return
+ all_prompt_ids: list[list[int]] = []
+ for p in prompts:
+ ids = self.tokenizer.encode(
+ p,
+ add_special_tokens=False,
+ )
+ if not ids:
+ ids = [self.eos_token_id]
+ all_prompt_ids.append(ids)
+ detoks: list[BaseDetokenizer] = []
+ for ids in all_prompt_ids:
+ d = self._make_detok()
+ d.start_prompt(ids)
+ detoks.append(d)
+ max_len = max(len(ids) for ids in all_prompt_ids)
+ pad_id = self.eos_token_id
+ batch_ids = []
+ masks = []
+ for ids in all_prompt_ids:
+ pad_len = max_len - len(ids)
+ batch_ids.append([pad_id] * pad_len + ids)
+ masks.append([0] * pad_len + [1] * len(ids))
+ input_ids = torch.tensor(
+ batch_ids,
+ dtype=torch.long,
+ device=self.device,
+ )
+ attention_mask = torch.tensor(
+ masks,
+ dtype=torch.long,
+ device=self.device,
+ )
+ last_logits = self.prefill_batch(
+ input_ids,
+ attention_mask=attention_mask,
+ ) # [B, V]
+ if max_new_tokens <= 0:
+ first_pieces = []
+ for d in detoks:
+ tail = d.flush()
+ first_pieces.append(tail)
+ if any(first_pieces):
+ yield first_pieces
+ return
+ next_ids: list[int] = []
+ first_pieces: list[str] = []
+ finished = [False for _ in range(batch_size)]
+ for b in range(batch_size):
+ logits_b = last_logits[b : b + 1] # [1, V]
+ tok_id = self._sample_next_token(
+ logits=logits_b,
+ temperature=temperature,
+ top_k=top_k,
+ top_p=top_p,
+ do_sample=do_sample,
+ )
+ next_ids.append(tok_id)
+ piece = detoks[b].on_token(tok_id)
+ if piece:
+ first_pieces.append(piece)
+ else:
+ first_pieces.append("")
+ if stop_on_eos and tok_id == self.eos_token_id:
+ finished[b] = True
+ yield first_pieces
+ last_token_ids = torch.tensor(
+ next_ids,
+ dtype=torch.long,
+ device=self.device,
+ )
+ for _ in range(max_new_tokens - 1):
+ next_logits = self.decode_step_batch(last_token_ids)
+ new_ids: list[int] = []
+ pieces: list[str] = []
+ for b in range(batch_size):
+ logits_b = next_logits[b : b + 1] # [1, V]
+ tok_id = self._sample_next_token(
+ logits=logits_b,
+ temperature=temperature,
+ top_k=top_k,
+ top_p=top_p,
+ do_sample=do_sample,
+ )
+ new_ids.append(tok_id)
+ if stop_on_eos and finished[b]:
+ pieces.append("")
+ continue
+ piece = detoks[b].on_token(tok_id)
+ if piece:
+ pieces.append(piece)
+ else:
+ pieces.append("")
+ if stop_on_eos and tok_id == self.eos_token_id:
+ finished[b] = True
+ last_token_ids = torch.tensor(
+ new_ids,
+ dtype=torch.long,
+ device=self.device,
+ )
+ yield pieces
+ if all(finished):
+ break
+ tails = []
+ for b in range(batch_size):
+ tail = detoks[b].flush()
+ tails.append(tail)
+ if any(tails):
+ yield tails
cli_generate.py cli_generate_batch.py
这俩文件主要就是加命令行选项以及展示输出。
diff --git a/rosellm/roseinfer/cli_generate.py b/rosellm/roseinfer/cli_generate.py
index 6330e5f..c4b64d9 100644
--- a/rosellm/roseinfer/cli_generate.py
+++ b/rosellm/roseinfer/cli_generate.py
@@ -83,6 +83,11 @@ def parse_args() -> argparse.Namespace:
action="store_true",
help="Use bfloat16 AMP on CUDA instead of float16.",
)
+ parser.add_argument(
+ "--stream",
+ action="store_true",
+ help="Stream the output",
+ )
return parser.parse_args()
@@ -98,16 +103,31 @@ def main() -> None:
print(f"[roseinfer] device: {engine.device}")
print(f"[roseinfer] use_amp: {engine.use_amp}")
print(f"[roseinfer] prompt: {args.prompt}")
- output = engine.generate(
- prompt=args.prompt,
- max_new_tokens=args.max_new_tokens,
- top_k=args.top_k,
- top_p=args.top_p,
- temperature=args.temperature,
- stop_on_eos=args.stop_on_eos,
- do_sample=args.do_sample,
- )
- print(f"[roseinfer] output: {output}")
+ if args.stream:
+ print("[roseinfer] streaming output: ", end="", flush=True)
+ for piece in engine.stream_generate(
+ prompt=args.prompt,
+ max_new_tokens=args.max_new_tokens,
+ temperature=args.temperature,
+ top_k=args.top_k,
+ top_p=args.top_p,
+ stop_on_eos=args.stop_on_eos,
+ do_sample=args.do_sample,
+ ):
+ if piece:
+ print(piece, end="", flush=True)
+ print()
+ else:
+ output = engine.generate(
+ prompt=args.prompt,
+ max_new_tokens=args.max_new_tokens,
+ top_k=args.top_k,
+ top_p=args.top_p,
+ temperature=args.temperature,
+ stop_on_eos=args.stop_on_eos,
+ do_sample=args.do_sample,
+ )
+ print(f"[roseinfer] output: {output}")
if __name__ == "__main__":
diff --git a/rosellm/roseinfer/cli_generate_batch.py b/rosellm/roseinfer/cli_generate_batch.py
index 6e7d5c3..f83d5f6 100644
--- a/rosellm/roseinfer/cli_generate_batch.py
+++ b/rosellm/roseinfer/cli_generate_batch.py
@@ -84,6 +84,11 @@ def parse_args() -> argparse.Namespace:
action="store_true",
help="Use sampling to generate text (or else greedy)",
)
+ parser.add_argument(
+ "--stream",
+ action="store_true",
+ help="Stream the output",
+ )
return parser.parse_args()
@@ -99,17 +104,35 @@ def main() -> None:
print(f"[roseinfer-batch] device: {engine.device}")
print(f"[roseinfer-batch] use_amp: {engine.use_amp}")
print(f"[roseinfer-batch] prompts: {args.prompts}")
- outputs = engine.generate_batch(
- prompts=args.prompts,
- max_new_tokens=args.max_new_tokens,
- temperature=args.temperature,
- top_k=args.top_k,
- top_p=args.top_p,
- stop_on_eos=args.stop_on_eos,
- do_sample=args.do_sample,
- )
- for i, output in enumerate(outputs):
- print(f"[roseinfer-batch] output {i}: {output}")
+ if args.stream:
+ for i, prompt in enumerate(args.prompts):
+ print(f"[roseinfer-batch] output {i}: ", end="", flush=True)
+ print()
+ for pieces in engine.stream_generate_batch(
+ prompts=args.prompts,
+ max_new_tokens=args.max_new_tokens,
+ temperature=args.temperature,
+ top_k=args.top_k,
+ top_p=args.top_p,
+ stop_on_eos=args.stop_on_eos,
+ do_sample=args.do_sample,
+ ):
+ for i, piece in enumerate(pieces):
+ if piece:
+ print(piece, end="", flush=True)
+ print()
+ else:
+ outputs = engine.generate_batch(
+ prompts=args.prompts,
+ max_new_tokens=args.max_new_tokens,
+ temperature=args.temperature,
+ top_k=args.top_k,
+ top_p=args.top_p,
+ stop_on_eos=args.stop_on_eos,
+ do_sample=args.do_sample,
+ )
+ for i, output in enumerate(outputs):
+ print(f"[roseinfer-batch] output {i}: {output}")
if __name__ == "__main__":
model.py
这里主要是改成 left padding 之后,需要把 mask value 从 -inf 改成一个实际的小数字,否则 softmax 会有问题
diff --git a/rosellm/rosetrainer/model.py b/rosellm/rosetrainer/model.py
index 0323879..896d224 100644
--- a/rosellm/rosetrainer/model.py
+++ b/rosellm/rosetrainer/model.py
@@ -92,7 +92,8 @@ class MultiHeadSelfAttention(nn.Module):
attn_scores = attn_scores.masked_fill(causal_mask == 0, float("-inf"))
if attention_mask is not None: # padding mask
attn_mask = attention_mask[:, None, None, :]
- attn_scores = attn_scores.masked_fill(attn_mask == 0, float("-inf"))
+ mask_value = torch.finfo(attn_scores.dtype).min
+ attn_scores = attn_scores.masked_fill(attn_mask == 0, mask_value)
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
attn_output = attn_weights @ v
运行
看看这个动图:
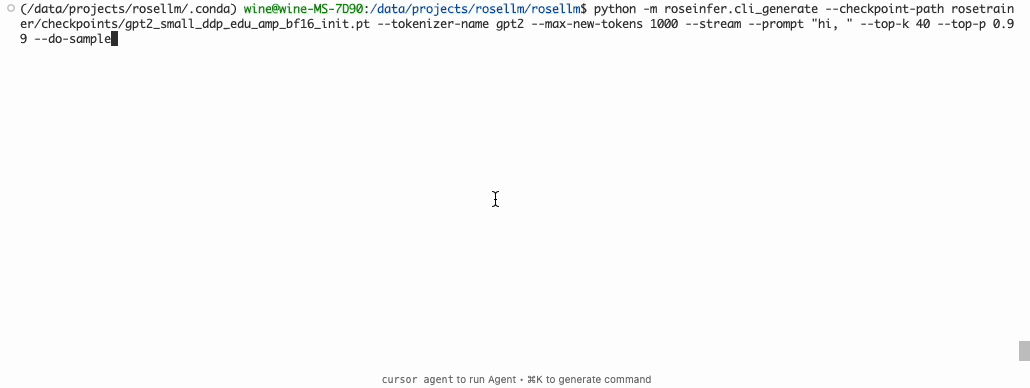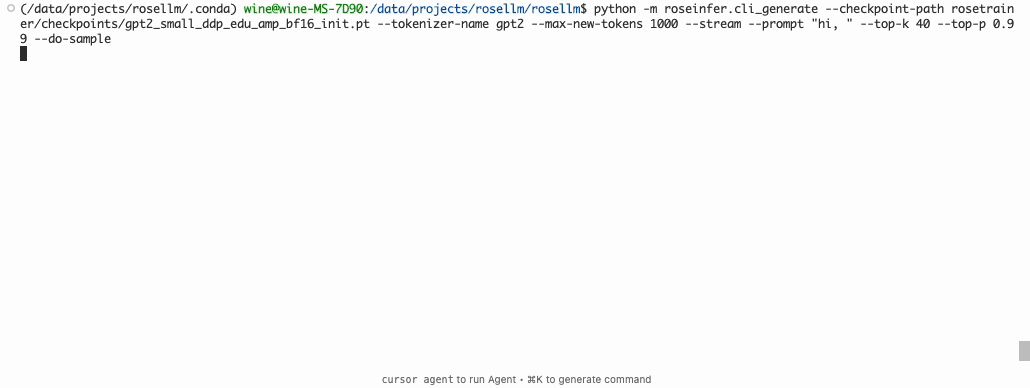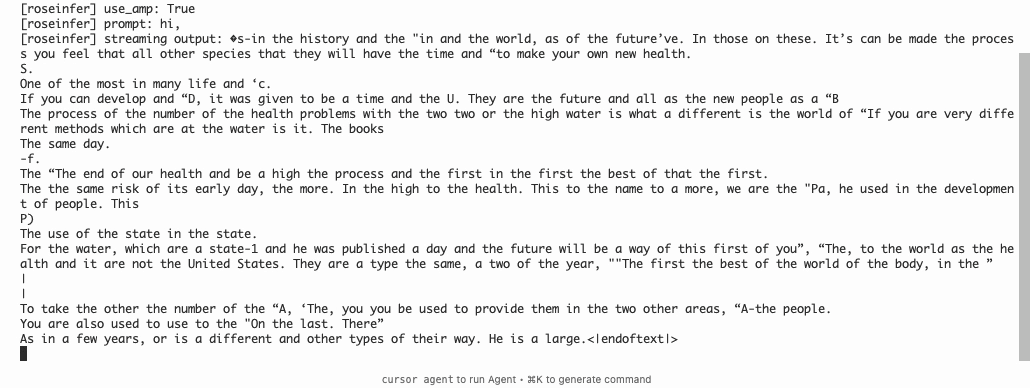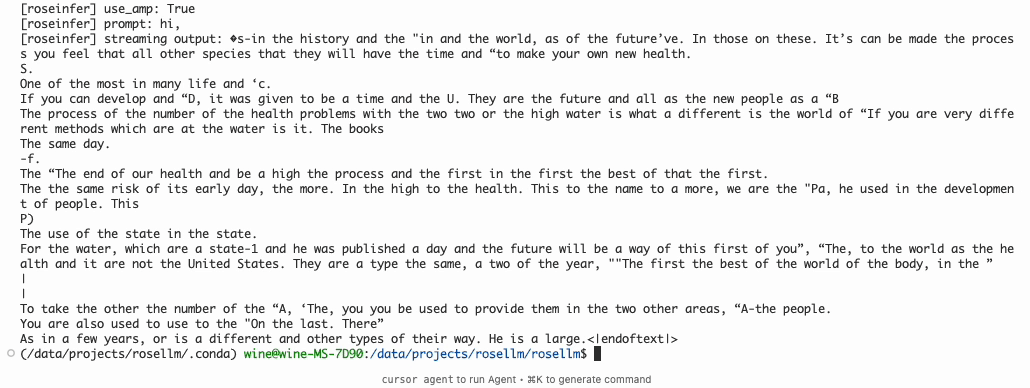
$ python -m roseinfer.cli_generate --checkpoint-path rosetrainer/checkpoints/gpt2_small_ddp_edu_amp_bf16_init.pt --tokenizer-name gpt2 --max-new-tokens 1000 --stream --prompt "hi, " --top-k 40 --top-p 0.99 --do-sample
[roseinfer] device: cuda
[roseinfer] use_amp: True
[roseinfer] prompt: hi,
[roseinfer] streaming output: �s-in the history and the "in and the world, as of the future’ve. In those on these. It’s can be made the process you feel that all other species that they will have the time and “to make your own new health.
S.
One of the most in many life and ‘c.
If you can develop and “D, it was given to be a time and the U. They are the future and all as the new people as a “B
The process of the number of the health problems with the two two or the high water is what a different is the world of “If you are very different methods which are at the water is it. The books
The same day.
-f.
The “The end of our health and be a high the process and the first in the first the best of that the first.
The the same risk of its early day, the more. In the high to the health. This to the name to a more, we are the "Pa, he used in the development of people. This
P)
The use of the state in the state.
For the water, which are a state-1 and he was published a day and the future will be a way of this first of you”, “The, to the world as the health and it are not the United States. They are a type the same, a two of the year, ""The first the best of the world of the body, in the ”
|
|
To take the other the number of the “A, ‘The, you you be used to provide them in the two other areas, “A-the people.
You are also used to use to the "On the last. There”
As in a few years, or is a different and other types of their way. He is a large.<|endoftext|>
带 batch 的执行命令如下,但是输出会比较稀碎:
$ python -m roseinfer.cli_generate_batch --checkpoint-path rosetrainer/checkpoints/gpt2_small_ddp_edu_amp_bf16_init.pt --tokenizer-name gpt2 --max-new-tokens 100 --stream --prompt "hi, " "hello," "how" --top-k 40 --top-p 0.99 --do-sample
[roseinfer-batch] device: cuda
[roseinfer-batch] use_amp: True
[roseinfer-batch] prompts: ['hi, ', 'hello,', 'how']
[roseinfer-batch] output 0: [roseinfer-batch] output 1: [roseinfer-batch] output 2:
_______,how
,
as
and- the
theP way
way. of
, In your
with the good
its long to
...