从零实现 LLM Inference:011. Online Scheduler
在实现了 python 版的 paged attention 之后,我们可以考虑正式封装出来一个 online scheduler,从而展示真正的 continuous batching 能力,为后面提供 serving 能力做一个铺垫。
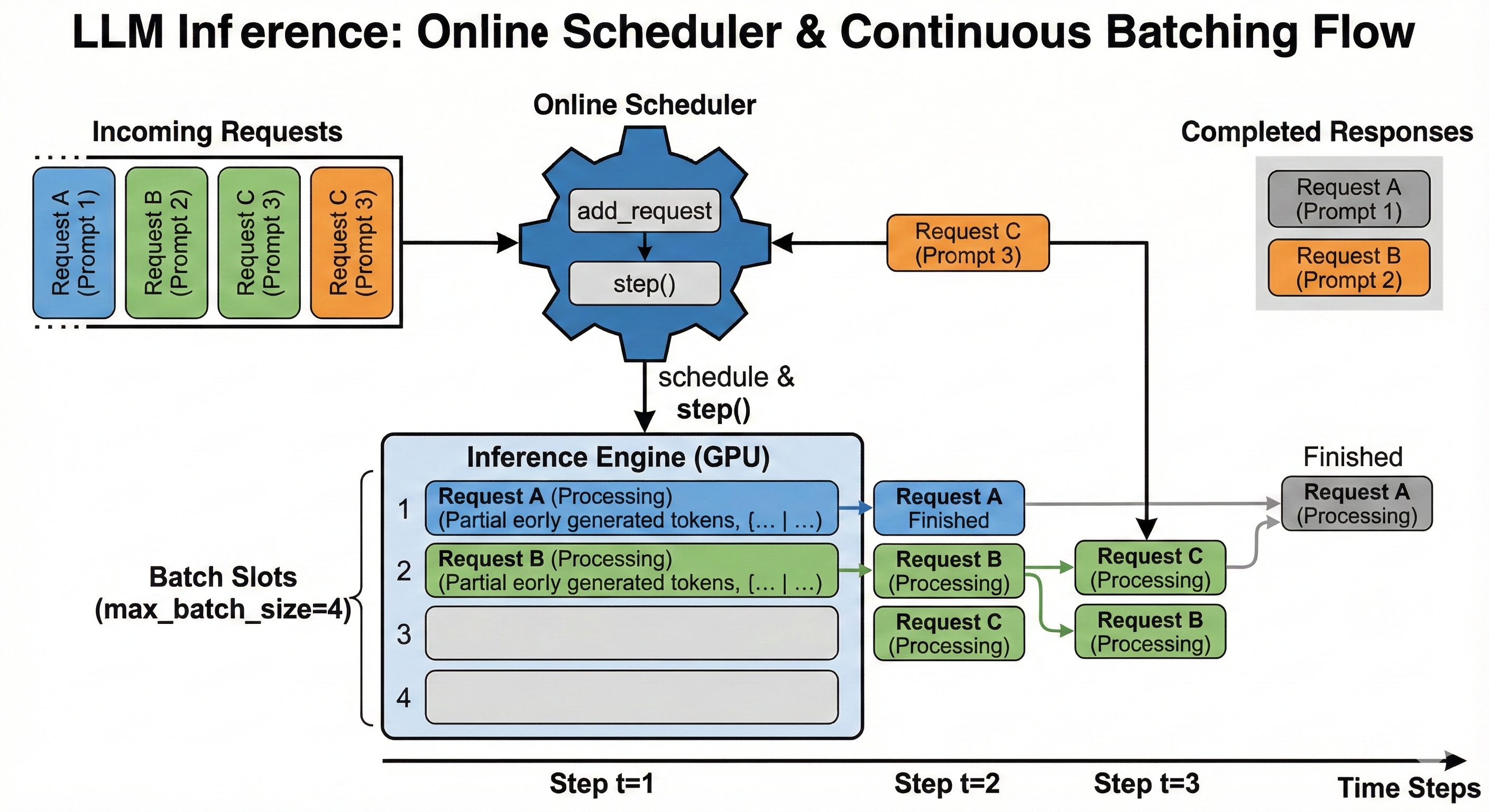
(图片生成自 nano banana)
代码变更
engine.py
class OnlineScheduler:
def __init__(
self,
engine: "InferenceEngine",
max_batch_size: int = 8,
) -> None:
self.engine = engine
self.max_batch_size = max_batch_size
self._sessions: dict[int, InferenceSession] = {}
self._next_request_id: int = 0
self._round_robin_pos: int = 0
@torch.no_grad()
def add_request(
self,
prompt: str,
max_new_tokens: int = 64,
temperature: float = 1.0,
top_k: int = 0,
top_p: float = 1.0,
stop_on_eos: bool = True,
do_sample: bool = False,
) -> int:
eng = self.engine
eng.model.eval()
input_ids = eng._encode_prompt(prompt) # [1, T0]
input_ids = eng._maybe_truncate(input_ids) # [1, T]
session = InferenceSession(eng)
session.input_ids = input_ids
session.set_generation_config(
max_new_tokens=max_new_tokens,
temperature=temperature,
top_k=top_k,
top_p=top_p,
do_sample=do_sample,
stop_on_eos=stop_on_eos,
)
logits = session.prefill(input_ids) # [1, T, V]
last_logits = logits[:, -1, :] # [1, V]
next_token = eng._sample_next_token(
last_logits,
temperature=temperature,
top_k=top_k,
top_p=top_p,
do_sample=do_sample,
)
token_id = int(next_token)
session.generated_ids.append(token_id)
session.step_count = 1
if stop_on_eos:
eos_id = eng.eos_token_id
if eos_id is not None and token_id == eos_id:
session.finished = True
if max_new_tokens > 0 and session.step_count >= max_new_tokens:
session.finished = True
request_id = self._next_request_id
self._next_request_id += 1
self._sessions[request_id] = session
return request_id
def has_unfinished(self) -> bool:
return any(not sess.finished for sess in self._sessions.values())
def is_finished(self, request_id: int) -> bool:
session = self._sessions.get(request_id, None)
return session.finished
@torch.no_grad()
def step(self) -> dict[int, int]:
active_pairs: list[tuple[int, InferenceSession]] = [
(rid, sess) for rid, sess in self._sessions.items() if not sess.finished
]
if not active_pairs:
return {}
num_active = len(active_pairs)
batch_size = min(self.max_batch_size, num_active)
start = self._round_robin_pos % num_active
selected_pairs: list[tuple[int, InferenceSession]] = []
for i in range(batch_size):
idx = (start + i) % num_active
selected_pairs.append(active_pairs[idx])
self._round_robin_pos = (start + batch_size) % num_active
sessions = [sess for _, sess in selected_pairs]
last_logits = self.engine.decode_step_sessions(sessions)
step_tokens: dict[int, int] = {}
for idx, (rid, sess) in enumerate(selected_pairs):
logits_row = last_logits[idx]
token_id = sess.apply_batch_logits(logits_row)
if token_id is not None:
step_tokens[rid] = token_id
if sess.finished:
sess.release_kv_blocks()
return step_tokens
def get_response(self, request_id: int) -> str:
session = self._sessions[request_id]
return session.decode_text()
def pop_response(self, request_id: int) -> str:
session = self._sessions.pop(request_id)
return session.decode_text()
运行
仿照 offline_example.py 改一个 online_example.py 然后运行:
import argparse
from .engine import InferenceEngine, OnlineScheduler
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(
description="Generate text from a model in batch mode",
)
parser.add_argument(
"--checkpoint-path",
type=str,
required=True,
help="Path to checkpoint file",
)
parser.add_argument(
"--tokenizer-name",
type=str,
required=True,
help="Tokenizer name",
)
parser.add_argument(
"--prompts",
type=str,
nargs="+",
required=True,
help="Prompts to generate text from",
)
parser.add_argument(
"--max-new-tokens",
type=int,
default=100,
help="Maximum number of new tokens to generate",
)
parser.add_argument(
"--device",
type=str,
default="cuda",
help="Device to use",
)
parser.add_argument(
"--no-amp",
action="store_true",
help="Disable automatic mixed precision",
)
parser.add_argument(
"--bf16",
action="store_true",
help="Use bfloat16 AMP on CUDA instead of float16.",
)
parser.add_argument(
"--stop-on-eos",
dest="stop_on_eos",
action="store_true",
help="Stop on EOS token",
)
parser.add_argument(
"--no-stop-on-eos",
dest="stop_on_eos",
action="store_false",
help="Do not stop on EOS token",
)
parser.set_defaults(stop_on_eos=True)
parser.add_argument(
"--temperature",
type=float,
default=1.0,
help="Temperature for sampling",
)
parser.add_argument(
"--top-k",
type=int,
default=0,
help="Top-k sampling",
)
parser.add_argument(
"--top-p",
type=float,
default=1.0,
help="Top-p sampling",
)
parser.add_argument(
"--do-sample",
action="store_true",
help="Use sampling to generate text (or else greedy)",
)
parser.add_argument(
"--stream",
action="store_true",
help="Stream the output",
)
return parser.parse_args()
def online_example(engine: InferenceEngine, args: argparse.Namespace) -> None:
scheduler = OnlineScheduler(engine, max_batch_size=4)
request_ids: list[int] = []
for p in args.prompts:
rid = scheduler.add_request(
p,
max_new_tokens=args.max_new_tokens,
temperature=args.temperature,
top_p=args.top_p,
do_sample=args.do_sample,
)
request_ids.append(rid)
step_idx = 0
r = None
while scheduler.has_unfinished():
step_idx += 1
_ = scheduler.step()
if step_idx == 2 and r is None:
# simulate continuous batching
r = scheduler.add_request("Hello, world!")
for rid in request_ids:
if scheduler.is_finished(rid):
print(f"### request {rid}")
print(scheduler.get_response(rid))
print()
else:
print(f"### request {rid} is not finished")
print()
if r is not None:
print(f"### request {r}")
print(scheduler.get_response(r))
print()
def main() -> None:
args = parse_args()
engine = InferenceEngine(
checkpoint_path=args.checkpoint_path,
tokenizer_name=args.tokenizer_name,
device=args.device,
use_amp=not args.no_amp,
bf16=args.bf16,
)
online_example(engine, args)
if __name__ == "__main__":
main()
$ ./online_example.sh
### request 0
hi, vernacular language, in their language, is used to make students feel free from the internet, using the internet, so it will be better to use these words correctly.
Are there words they are using to communicate?
Babies are a common type of food used in the food web, but they do not have any traditional food, like food or food. In other words, they are easy to use, and it can be used in different words, such as, and to make them sound
### request 1
hello, I’m not speaking to me here,
- I’m not speaking to me. I’m reading to myself,
- I am a bit much more close to me,
- I am very much less in my way of life,
- I am a bit harder to make my little bit harder,
- I am a bit more my time,
- I am getting in trouble,
- I am talking to me,
- I am feeling like
### request 2
how we have, it's quite doubtful that we have a lot of information in the world.
However, the body itself that I can't remember is that we have to be in the realm of human beings.
And since the human nature is the same, it's one that actually doesn't exist in it.
Now, when human beings, the human world can fully remember the various ways that humans can actually see it.
This is a whole complex of the most complex of all. It
### request 3
Hello, world!
- The world is a world of great importance.
- The world is a world of great importance.
- The world is a world of great importance.
- The world is a world of great importance.
- The world is a world of great importance.
- The world is a world of great
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm$