从零实现 LLM Inference:017. Profiler
在这个 PR 里,我们加上 pytorch profiler,在之前写简易的训练框架时,其实我们就已经看过一次 pytorch profiler 了,现在在推理框架上,我们依然需要性能观测工具,来为我们的性能优化做依据。
代码变更
核心是使用 torch.profiler 里面的 ProfilerActivity, profile, schedule 等工具,然后我们在 decode_step_sessions 里面加上一段段的 with record_function 来对不同的代码段打标记,从而可以在 profiler 上展示。
diff --git a/rosellm/roseinfer/benchmark_scheduler.py b/rosellm/roseinfer/benchmark_scheduler.py
index 2337088..35e8d24 100644
--- a/rosellm/roseinfer/benchmark_scheduler.py
+++ b/rosellm/roseinfer/benchmark_scheduler.py
@@ -1,8 +1,11 @@
import argparse
+import os
import time
+from pathlib import Path
from typing import List, Optional
import torch
+from torch.profiler import ProfilerActivity, profile, schedule
from .engine import InferenceEngine, OfflineScheduler, OnlineScheduler
@@ -109,6 +112,17 @@ def parse_args() -> argparse.Namespace:
action="store_true",
help="Disable prefix cache",
)
+ parser.add_argument(
+ "--profile",
+ action="store_true",
+ help="Enable profiler",
+ )
+ parser.add_argument(
+ "--profile-dir",
+ type=str,
+ default="profiles",
+ help="Directory to save profiler output",
+ )
return parser.parse_args()
@@ -223,8 +237,23 @@ def benchmark_offline(
maybe_sync_cuda(engine)
t2 = time.perf_counter()
- outputs_by_id = scheduler.run()
- maybe_sync_cuda(engine)
+ prof = None
+ trace_path = None
+ if args.profile:
+ out_dir = Path(args.profile_dir)
+ out_dir.mkdir(parents=True, exist_ok=True)
+ trace_path = os.fspath(out_dir / "offline_run.json")
+ sched = schedule(wait=1, warmup=2, active=3, repeat=1)
+ with profile(
+ activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
+ schedule=sched,
+ ) as prof:
+ outputs_by_id = scheduler.run()
+ prof.step()
+ maybe_sync_cuda(engine)
+ else:
+ outputs_by_id = scheduler.run()
+ maybe_sync_cuda(engine)
outputs: List[str] = []
for rid in request_ids:
@@ -241,6 +270,9 @@ def benchmark_offline(
prefill_elapsed=prefill_elapsed,
decode_elapsed=decode_elapsed,
)
+ if prof is not None and trace_path is not None:
+ prof.export_chrome_trace(trace_path)
+ print(f"[profile] wrote: {trace_path}")
def benchmark_online(
@@ -274,9 +306,25 @@ def benchmark_online(
maybe_sync_cuda(engine)
t2 = time.perf_counter()
- while scheduler.has_unfinished():
- scheduler.step()
- maybe_sync_cuda(engine)
+ prof = None
+ trace_path = None
+ if args.profile:
+ out_dir = Path(args.profile_dir)
+ out_dir.mkdir(parents=True, exist_ok=True)
+ trace_path = os.fspath(out_dir / "online_decode.json")
+ sched = schedule(wait=1, warmup=2, active=3, repeat=1)
+ with profile(
+ activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
+ schedule=sched,
+ ) as prof:
+ while scheduler.has_unfinished():
+ scheduler.step()
+ prof.step()
+ maybe_sync_cuda(engine)
+ else:
+ while scheduler.has_unfinished():
+ scheduler.step()
+ maybe_sync_cuda(engine)
outputs: List[str] = []
for rid in request_ids:
@@ -293,6 +341,9 @@ def benchmark_online(
prefill_elapsed=prefill_elapsed,
decode_elapsed=decode_elapsed,
)
+ if prof is not None and trace_path is not None:
+ prof.export_chrome_trace(trace_path)
+ print(f"[profile] wrote: {trace_path}")
def main() -> None:
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
index 19438b0..bad3b39 100644
--- a/rosellm/roseinfer/engine.py
+++ b/rosellm/roseinfer/engine.py
@@ -2,14 +2,16 @@ from collections import OrderedDict
from typing import Iterator, NamedTuple, Optional
import torch
-from roseinfer.detokenizer import (
+from torch.profiler import record_function
+
+from rosellm.roseinfer.detokenizer import (
BaseDetokenizer,
GPT2ByteDetokenizer,
PrefixDiffDetokenizer,
)
-from rosetrainer.config import GPTConfig
-from rosetrainer.dataset import build_tokenizer
-from rosetrainer.model import GPTModel
+from rosellm.rosetrainer.config import GPTConfig
+from rosellm.rosetrainer.dataset import build_tokenizer
+from rosellm.rosetrainer.model import GPTModel
try:
import tiktoken
@@ -678,141 +680,145 @@ class InferenceEngine:
self,
sessions: list["InferenceSession"],
) -> torch.Tensor:
- assert sessions
- from torch.amp import autocast
+ with record_function("roseinfer.decode_step_sessions.total"):
+ assert sessions
+ from torch.amp import autocast
- device = self.device
- batch_size = len(sessions)
- kvm = self.kv_manager
+ device = self.device
+ batch_size = len(sessions)
+ kvm = self.kv_manager
- last_ids: list[int] = []
- seq_lens: list[int] = []
- for sess in sessions:
- if sess.finished:
- continue
- assert sess.generated_ids
- last_ids.append(sess.generated_ids[-1])
- seq_len = sess.prompt_length + sess.step_count - 1
- seq_lens.append(seq_len)
- assert len(last_ids) == batch_size
- lens = torch.tensor(seq_lens, device=device, dtype=torch.long)
- max_len = max(seq_lens)
-
- input_ids = torch.tensor( # [B, 1]
- last_ids,
- dtype=torch.long,
- device=device,
- ).view(batch_size, 1)
- past_mask = torch.arange(
- max_len,
- device=device,
- ).unsqueeze(
- 0
- ) < lens.unsqueeze(1)
- new_mask = torch.ones(
- batch_size,
- 1,
- device=device,
- dtype=past_mask.dtype,
- )
- attention_mask = torch.cat(
- [past_mask, new_mask],
- dim=1,
- ).to(torch.long)
-
- batched_past = []
- num_layers = kvm.num_layers
- for layer_idx in range(num_layers):
- k_list = []
- v_list = []
- for idx, sess in enumerate(sessions):
- seq_len = seq_lens[idx]
- block_ids = sess.block_ids_per_layer[layer_idx]
- k_seq, v_seq = kvm.gather_sequence(
- layer_idx,
- block_ids,
- seq_len,
- ) # [1, H, T_i, D]
- T_i = k_seq.size(2)
- if T_i < max_len:
- pad_len = max_len - T_i
- pad_shape = (
- 1,
- k_seq.size(1),
- pad_len,
- k_seq.size(3),
- )
- k_pad = torch.zeros(
- pad_shape,
- dtype=k_seq.dtype,
- device=k_seq.device,
- )
- v_pad = torch.zeros(
- pad_shape,
- dtype=v_seq.dtype,
- device=v_seq.device,
- )
- k_full = torch.cat(
- [k_seq, k_pad],
- dim=2,
- )
- v_full = torch.cat(
- [v_seq, v_pad],
- dim=2,
- )
- else:
- k_full = k_seq
- v_full = v_seq
- k_list.append(k_full)
- v_list.append(v_full)
- k_cat = torch.cat(k_list, dim=0)
- v_cat = torch.cat(v_list, dim=0)
- batched_past.append((k_cat, v_cat))
- if self.use_amp:
- with autocast(
- device_type=device.type,
- dtype=self.amp_dtype,
- ):
- logits, _, presents = self.model(
- input_ids=input_ids,
- attention_mask=attention_mask,
- labels=None,
- past_key_values=tuple(batched_past),
- use_cache=True,
- )
- else:
- logits, _, presents = self.model(
- input_ids=input_ids,
- attention_mask=attention_mask,
- labels=None,
- past_key_values=tuple(batched_past),
- use_cache=True,
- )
- last_logits = logits[:, -1, :] # [B, V]
- for layer_idx in range(num_layers):
- k_b, v_b = presents[layer_idx]
- for idx, sess in enumerate(sessions):
+ last_ids: list[int] = []
+ seq_lens: list[int] = []
+ for sess in sessions:
if sess.finished:
continue
- k_new = k_b[
- idx : idx + 1,
- :,
- max_len : max_len + 1,
- :,
- ]
- v_new = v_b[
- idx : idx + 1,
- :,
- max_len : max_len + 1,
- :,
- ]
- kvm.append_token(
- layer_idx,
- sess.block_ids_per_layer[layer_idx],
- k_new,
- v_new,
- )
- return last_logits
+ assert sess.generated_ids
+ last_ids.append(sess.generated_ids[-1])
+ seq_len = sess.prompt_length + sess.step_count - 1
+ seq_lens.append(seq_len)
+ assert len(last_ids) == batch_size
+ lens = torch.tensor(seq_lens, device=device, dtype=torch.long)
+ max_len = max(seq_lens)
+
+ input_ids = torch.tensor( # [B, 1]
+ last_ids,
+ dtype=torch.long,
+ device=device,
+ ).view(batch_size, 1)
+ past_mask = torch.arange(
+ max_len,
+ device=device,
+ ).unsqueeze(
+ 0
+ ) < lens.unsqueeze(1)
+ new_mask = torch.ones(
+ batch_size,
+ 1,
+ device=device,
+ dtype=past_mask.dtype,
+ )
+ attention_mask = torch.cat(
+ [past_mask, new_mask],
+ dim=1,
+ ).to(torch.long)
+
+ batched_past = []
+ num_layers = kvm.num_layers
+ with record_function("roseinfer.decode_step_sessions.build_batched_past"):
+ for layer_idx in range(num_layers):
+ k_list = []
+ v_list = []
+ for idx, sess in enumerate(sessions):
+ seq_len = seq_lens[idx]
+ block_ids = sess.block_ids_per_layer[layer_idx]
+ k_seq, v_seq = kvm.gather_sequence(
+ layer_idx,
+ block_ids,
+ seq_len,
+ ) # [1, H, T_i, D]
+ T_i = k_seq.size(2)
+ if T_i < max_len:
+ pad_len = max_len - T_i
+ pad_shape = (
+ 1,
+ k_seq.size(1),
+ pad_len,
+ k_seq.size(3),
+ )
+ k_pad = torch.zeros(
+ pad_shape,
+ dtype=k_seq.dtype,
+ device=k_seq.device,
+ )
+ v_pad = torch.zeros(
+ pad_shape,
+ dtype=v_seq.dtype,
+ device=v_seq.device,
+ )
+ k_full = torch.cat(
+ [k_seq, k_pad],
+ dim=2,
+ )
+ v_full = torch.cat(
+ [v_seq, v_pad],
+ dim=2,
+ )
+ else:
+ k_full = k_seq
+ v_full = v_seq
+ k_list.append(k_full)
+ v_list.append(v_full)
+ k_cat = torch.cat(k_list, dim=0)
+ v_cat = torch.cat(v_list, dim=0)
+ batched_past.append((k_cat, v_cat))
+ with record_function("roseinfer.model.forward"):
+ if self.use_amp:
+ with autocast(
+ device_type=device.type,
+ dtype=self.amp_dtype,
+ ):
+ logits, _, presents = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=None,
+ past_key_values=tuple(batched_past),
+ use_cache=True,
+ )
+ else:
+ logits, _, presents = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=None,
+ past_key_values=tuple(batched_past),
+ use_cache=True,
+ )
+ last_logits = logits[:, -1, :] # [B, V]
+ with record_function("roseinfer.kv.append_token"):
+ for layer_idx in range(num_layers):
+ k_b, v_b = presents[layer_idx]
+ for idx, sess in enumerate(sessions):
+ if sess.finished:
+ continue
+ k_new = k_b[
+ idx : idx + 1,
+ :,
+ max_len : max_len + 1,
+ :,
+ ]
+ v_new = v_b[
+ idx : idx + 1,
+ :,
+ max_len : max_len + 1,
+ :,
+ ]
+ kvm.append_token(
+ layer_idx,
+ sess.block_ids_per_layer[layer_idx],
+ k_new,
+ v_new,
+ )
+ return last_logits
class InferenceSession:
运行
运行如下命令来生成 profile.json
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm$ python -m rosellm.roseinfer.benchmark_scheduler --checkpoint-path rosellm/rosetrainer/checkpoints/gpt2_small_ddp_edu_amp_bf16_init.pt --tokenizer-name gpt2 --device cuda --prompt "Hello" --num-requests 16 --max-new-tokens 16 --mode online --do-sample --top-k 40 --top-p 0.9 --profile --profile-dir profiles
=== online ===
Requests: 16
Elapsed (prefill/add): 0.177381 seconds
Elapsed (decode/run): 0.464943 seconds
Elapsed (total): 0.642325 seconds
Prompt tokens: 16
Completion tokens: 230
Total tokens: 246
Throughput (completion): 358.07 tokens/s
Throughput (total): 382.98 tokens/s
[profile] wrote: profiles/online_decode.json
用工具打开这个 profile 看一眼,首先是远景:
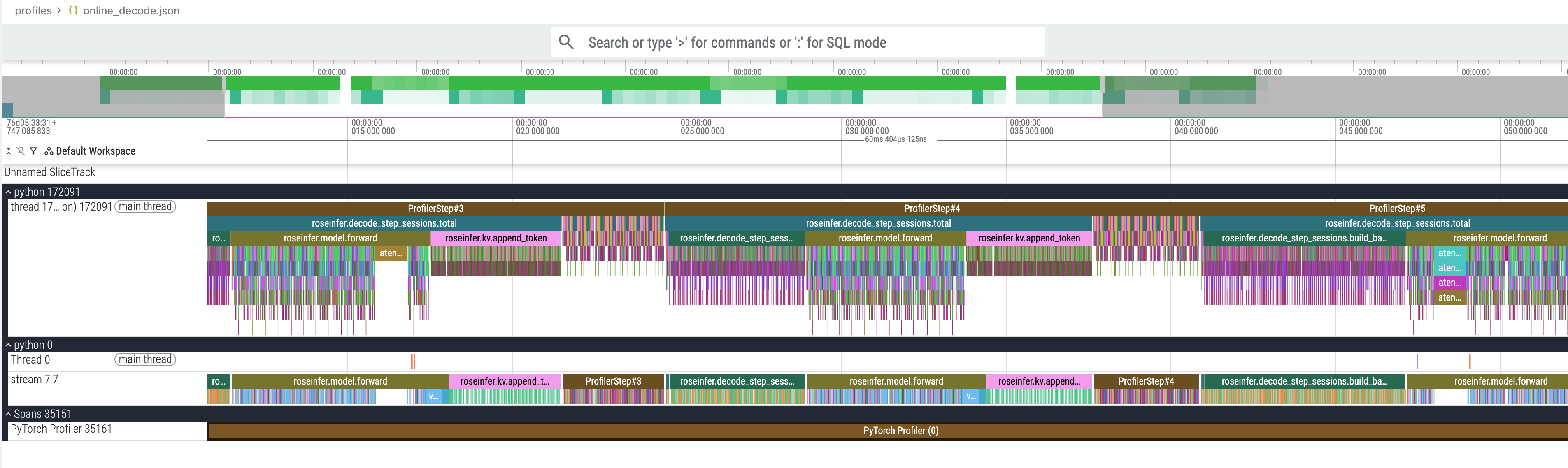
然后选一个 build_batched_past 的近景:
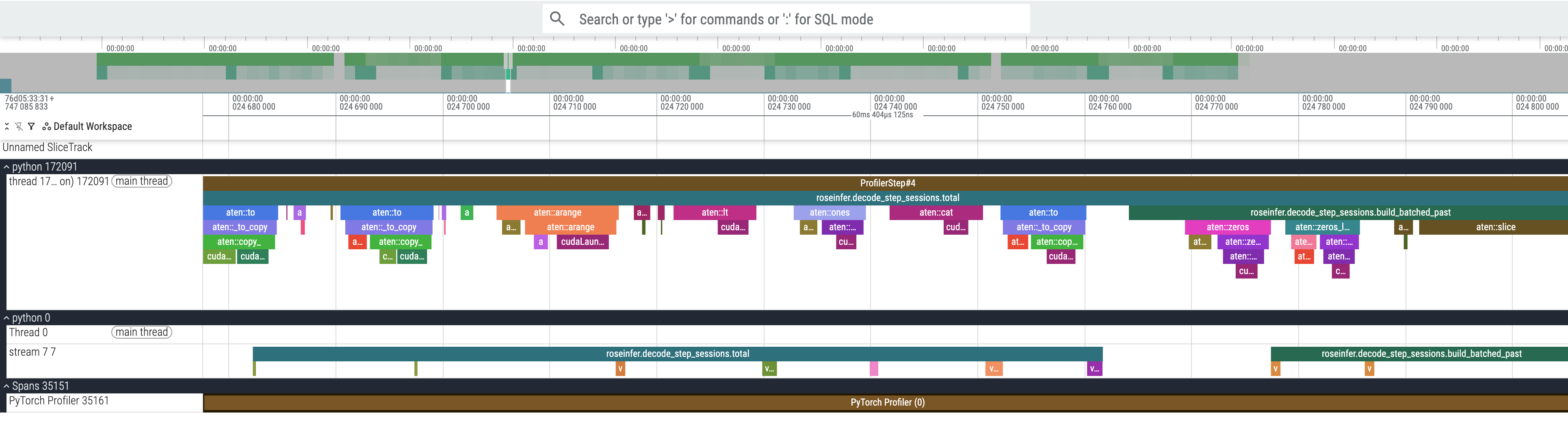
我们从下面的 GPU kernel 执行的情况可以发现有非常多的空洞,并且仔细研究一下 build_batched_past 会发现有很多 zero cat 等操作,非常多的小 kernel 在 launch,导致了不必要的开销。在下一个 PR 我们来解决这一问题以进行针对性的优化。