从零实现 LLM Inference:018. Performance
在加完 pytorch profiler 之后,我们趁热打铁做几个小优化。
减少 concat 操作
首先我们之前看到有比较多的 GPU 空洞,我们在之前有一个逻辑是要 gather 所有的 kv block,然后把他们拼成 kv cache 做 decode,这里我们的初始实现很糙,会有很多 cat 以及 copy 操作,现在我们可以预先分配一个大 buffer,然后 gather 进入,例如:
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
index bad3b39..5410ee0 100644
--- a/rosellm/roseinfer/engine.py
+++ b/rosellm/roseinfer/engine.py
@@ -725,52 +725,26 @@ class InferenceEngine:
batched_past = []
num_layers = kvm.num_layers
+ num_heads = kvm.num_heads
+ head_dim = kvm.head_dim
with record_function("roseinfer.decode_step_sessions.build_batched_past"):
for layer_idx in range(num_layers):
- k_list = []
- v_list = []
+ k_cat = torch.zeros(
+ [batch_size, num_heads, max_len, head_dim],
+ dtype=kvm.dtype,
+ device=device,
+ )
+ v_cat = torch.zeros_like(k_cat)
for idx, sess in enumerate(sessions):
seq_len = seq_lens[idx]
block_ids = sess.block_ids_per_layer[layer_idx]
- k_seq, v_seq = kvm.gather_sequence(
+ kvm.gather_sequence_into(
layer_idx,
block_ids,
seq_len,
- ) # [1, H, T_i, D]
- T_i = k_seq.size(2)
- if T_i < max_len:
- pad_len = max_len - T_i
- pad_shape = (
- 1,
- k_seq.size(1),
- pad_len,
- k_seq.size(3),
- )
- k_pad = torch.zeros(
- pad_shape,
- dtype=k_seq.dtype,
- device=k_seq.device,
- )
- v_pad = torch.zeros(
- pad_shape,
- dtype=v_seq.dtype,
- device=v_seq.device,
- )
- k_full = torch.cat(
- [k_seq, k_pad],
- dim=2,
- )
- v_full = torch.cat(
- [v_seq, v_pad],
- dim=2,
- )
- else:
- k_full = k_seq
- v_full = v_seq
- k_list.append(k_full)
- v_list.append(v_full)
- k_cat = torch.cat(k_list, dim=0)
- v_cat = torch.cat(v_list, dim=0)
+ k_cat[idx],
+ v_cat[idx],
+ )
batched_past.append((k_cat, v_cat))
with record_function("roseinfer.model.forward"):
if self.use_amp:
@@ -1572,32 +1546,20 @@ class KVBlockManager:
)
self._block_infos[last_id] = new_info
- def gather_sequence(
+ def gather_sequence_into(
self,
layer_idx: int,
block_ids: list[int],
total_len: int,
- ) -> tuple[torch.Tensor, torch.Tensor]:
+ out_k: torch.Tensor, # [H, >=total_len, D]
+ out_v: torch.Tensor, # [H, >=total_len, D]
+ ) -> None:
assert 0 <= layer_idx < self.num_layers
- k_seq = torch.zeros(
- (
- 1,
- self.num_heads,
- total_len,
- self.head_dim,
- ),
- dtype=self.dtype,
- device=self.device,
- )
- v_seq = torch.zeros_like(k_seq)
cur = 0
for global_id in block_ids:
info = self._block_infos[global_id]
- if info is None:
- continue
- if info.layer != layer_idx:
+ if info is None or info.layer != layer_idx:
continue
- k_block, v_block = self._block_storage[global_id]
length = info.length
if length <= 0:
continue
@@ -1605,9 +1567,37 @@ class KVBlockManager:
take = end - cur
if take <= 0:
break
- k_seq[0, :, cur:end, :] = k_block[:, :take, :]
- v_seq[0, :, cur:end, :] = v_block[:, :take, :]
+ k_block, v_block = self._block_storage[global_id]
+ out_k[:, cur:end, :] = k_block[:, :take, :]
+ out_v[:, cur:end, :] = v_block[:, :take, :]
cur = end
if cur >= total_len:
break
+
+ def gather_sequence(
+ self,
+ layer_idx: int,
+ block_ids: list[int],
+ total_len: int,
+ ) -> tuple[torch.Tensor, torch.Tensor]:
+ assert 0 <= layer_idx < self.num_layers
+ k_seq = torch.zeros(
+ (
+ self.num_heads,
+ total_len,
+ self.head_dim,
+ ),
+ dtype=self.dtype,
+ device=self.device,
+ )
+ v_seq = torch.zeros_like(k_seq)
+ self.gather_sequence_into(
+ layer_idx,
+ block_ids,
+ total_len,
+ k_seq,
+ v_seq,
+ )
+ k_seq.unsqueeze_(0)
+ v_seq.unsqueeze_(0)
return k_seq, v_seq
我们重新执行看一下 trace:
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm$ python -m rosellm.roseinfer.benchmark_scheduler --checkpoint-path rosellm/rosetrainer/checkpoints/gpt2_small_ddp_edu_amp_bf16_init.pt --tokenizer-name gpt2 --device cuda --prompt "Hello" --num-requests 16 --max-new-tokens 16 --mode online --do-sample --top-k 40 --top-p 0.9 --profile
=== online ===
Requests: 16
Elapsed (prefill/add): 0.183590 seconds
Elapsed (decode/run): 0.443207 seconds
Elapsed (total): 0.626796 seconds
Prompt tokens: 16
Completion tokens: 256
Total tokens: 272
Throughput (completion): 408.43 tokens/s
Throughput (total): 433.95 tokens/s
[profile] wrote: profiles/online_decode.json
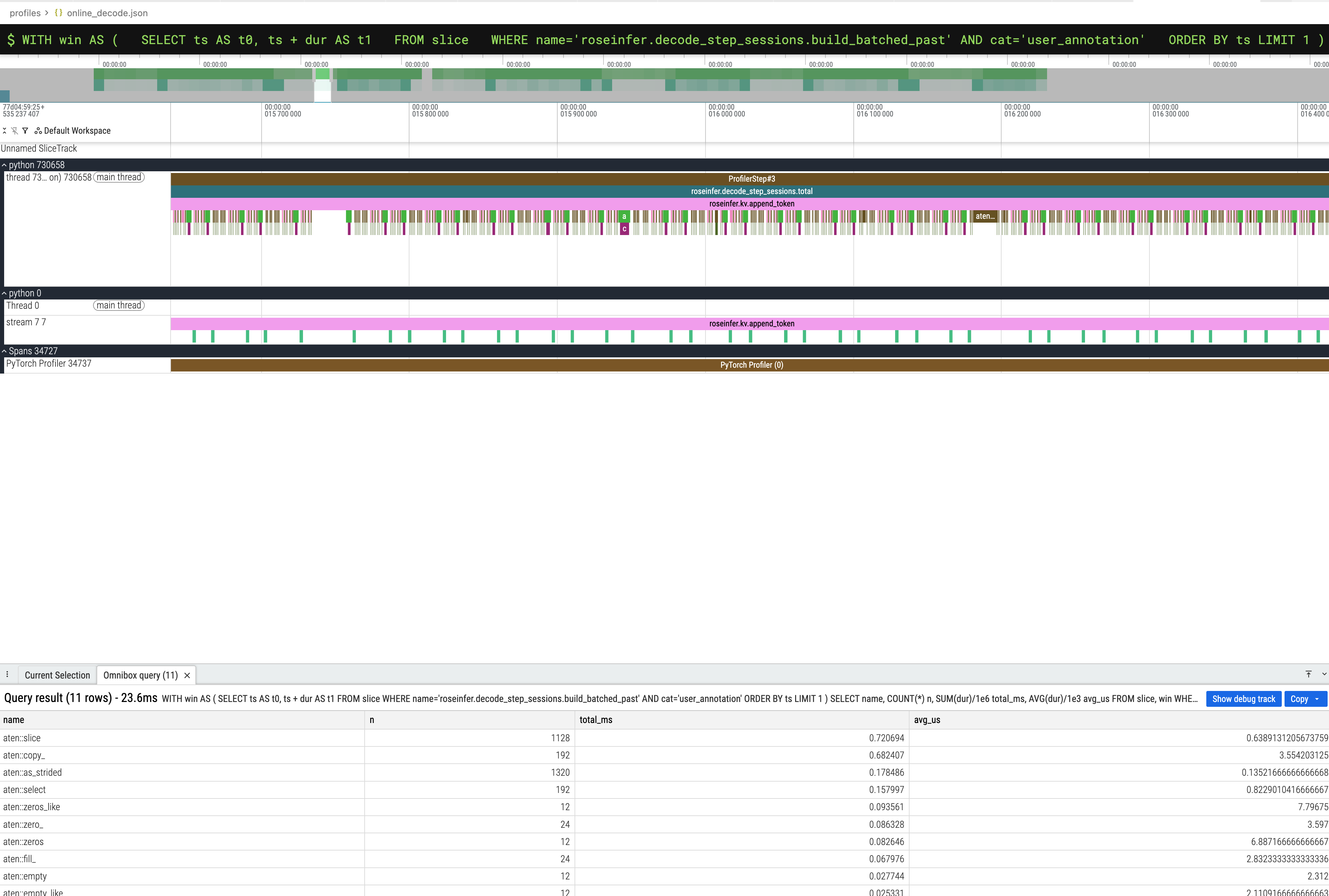
执行以下 SQL 查看 build_batched_past 里面最好是的 aten:: 操作:
WITH win AS (
SELECT ts AS t0, ts + dur AS t1
FROM slice
WHERE name='roseinfer.decode_step_sessions.build_batched_past' AND cat='user_annotation'
ORDER BY ts LIMIT 1
)
SELECT name, COUNT(*) n, SUM(dur)/1e6 total_ms, AVG(dur)/1e3 avg_us
FROM slice, win
WHERE ts>=win.t0 AND ts<win.t1 AND name LIKE 'aten::%'
GROUP BY name
ORDER BY total_ms DESC
LIMIT 25;
结果:
| name | n | total_ms | avg_us |
|---|---|---|---|
| aten::slice | 1128 | 0.720694 | 0.6389131205673759 |
| aten::copy_ | 192 | 0.682407 | 3.554203125 |
| aten::as_strided | 1320 | 0.178486 | 0.13521666666666668 |
| aten::select | 192 | 0.157997 | 0.8229010416666667 |
| aten::zeros_like | 12 | 0.093561 | 7.79675 |
| aten::zero_ | 24 | 0.086328 | 3.597 |
| aten::zeros | 12 | 0.082646 | 6.887166666666667 |
| aten::fill_ | 24 | 0.067976 | 2.8323333333333336 |
| aten::empty | 12 | 0.027744 | 2.312 |
| aten::empty_like | 12 | 0.025331 | 2.1109166666666663 |
| aten::empty_strided | 12 | 0.021201 | 1.76675 |
查看 cat/zeros/empty/copy 的次数和总耗时:
WITH win AS (
SELECT ts AS t0, ts + dur AS t1
FROM slice
WHERE name='roseinfer.decode_step_sessions.build_batched_past' AND cat='user_annotation'
ORDER BY ts LIMIT 1
)
SELECT name, COUNT(*) n, SUM(dur)/1e6 total_ms
FROM slice, win
WHERE ts>=win.t0 AND ts<win.t1
AND name IN ('aten::cat','aten::zeros','aten::zeros_like','aten::empty','aten::empty_like','aten::copy_')
GROUP BY name
ORDER BY total_ms DESC;
| name | n | total_ms |
|---|---|---|
| aten::copy_ | 192 | 0.682407 |
| aten::zeros_like | 12 | 0.093561 |
| aten::zeros | 12 | 0.082646 |
| aten::empty | 12 | 0.027744 |
| aten::empty_like | 12 | 0.025331 |
可以看到 cat 相关操作已经没有了。
减少 slice 操作
然后我们再执行一些 SQL 来看一下下一个要优化的点是什么。
首先我们看一下总览的时间分布:
SELECT cat, name, COUNT(*) n, SUM(dur)/1e6 total_ms, AVG(dur)/1e6 avg_ms
FROM slice
WHERE name LIKE 'roseinfer.%'
AND cat IN ('user_annotation','gpu_user_annotation')
GROUP BY cat, name
ORDER BY total_ms DESC;
| cat | name | n | total_ms | avg_ms |
|---|---|---|---|---|
| user_annotation | roseinfer.decode_step_sessions.total | 3 | 37.372763 | 12.457587666666665 |
| gpu_user_annotation | roseinfer.model.forward | 3 | 16.860876 | 5.620292 |
| user_annotation | roseinfer.model.forward | 3 | 15.130033 | 5.043344333333333 |
| user_annotation | roseinfer.kv.append_token | 3 | 11.559445 | 3.8531483333333334 |
| user_annotation | roseinfer.decode_step_sessions.build_batched_past | 3 | 10.210486 | 3.4034953333333333 |
| gpu_user_annotation | roseinfer.decode_step_sessions.build_batched_past | 3 | 10.138591 | 3.3795303333333333 |
| gpu_user_annotation | roseinfer.kv.append_token | 3 | 9.695246 | 3.2317486666666664 |
| gpu_user_annotation | roseinfer.decode_step_sessions.total | 3 | 0.278961 | 0.092987 |
然后我们看一下 append_token 里面相关的开销:
WITH win AS (
SELECT ts AS t0, ts + dur AS t1
FROM slice
WHERE name='roseinfer.kv.append_token' AND cat='user_annotation'
ORDER BY ts LIMIT 1
)
SELECT name, COUNT(*) n, SUM(dur)/1e6 total_ms, AVG(dur)/1e3 avg_us
FROM slice, win
WHERE ts>=win.t0 AND ts<win.t1 AND name LIKE 'aten::%'
GROUP BY name
ORDER BY total_ms DESC
LIMIT 25;
| name | n | total_ms | avg_us |
|---|---|---|---|
| aten::slice | 1536 | 0.974965 | 0.6347428385416666 |
| aten::copy_ | 192 | 0.681122 | 3.5475104166666664 |
| aten::select | 576 | 0.43875 | 0.76171875 |
| aten::as_strided | 2112 | 0.283673 | 0.13431486742424242 |
接下来我们再看一下 slice,select,copy_ 相关的开销:
WITH win AS (
SELECT ts AS t0, ts + dur AS t1
FROM slice
WHERE name='roseinfer.kv.append_token' AND cat='user_annotation'
ORDER BY ts LIMIT 1
)
SELECT name, COUNT(*) n, SUM(dur)/1e6 total_ms
FROM slice, win
WHERE ts>=win.t0 AND ts<win.t1
AND name IN ('aten::slice','aten::select','aten::copy_','aten::as_strided')
GROUP BY name
ORDER BY total_ms DESC;
| name | n | total_ms |
|---|---|---|
| aten::slice | 1536 | 0.974965 |
| aten::copy_ | 192 | 0.681122 |
| aten::select | 576 | 0.43875 |
| aten::as_strided | 2112 | 0.283673 |
这里 slice 之所以是 1536,是可以算出来的,因为我们有一个这样的操作:
with record_function("roseinfer.kv.append_token"):
for layer_idx in range(num_layers):
k_b, v_b = presents[layer_idx]
for idx, sess in enumerate(sessions):
if sess.finished:
continue
k_new = k_b[
idx : idx + 1,
:,
max_len : max_len + 1,
:,
]
v_new = v_b[
idx : idx + 1,
:,
max_len : max_len + 1,
:,
]
每个 k 实际上对应一个 k_b[idx:idx+1, :, max_len:max_len+1, :],pytorch 一般每个维度一个 slice 操作,所以这里是 4 次 slice,k 和 v 一块则是 8 次,然后我们有 12 层 layer,每个 batch 是 16 的大小,所以对应 12*16*8=1536。select 和 as_strided 主要来自于这些 slice 生成 view,以及 append_token 里面 key_new[0, :, 0, :] 这种再次索引操作。
这里我们可以这样优化一下,在每次开始遍历 layer_idx 的时候就提前 select 好这一层的 kv,避免后面频繁做重复的 slice 操作:
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
index 5410ee0..ffbce00 100644
--- a/rosellm/roseinfer/engine.py
+++ b/rosellm/roseinfer/engine.py
@@ -770,27 +770,17 @@ class InferenceEngine:
last_logits = logits[:, -1, :] # [B, V]
with record_function("roseinfer.kv.append_token"):
for layer_idx in range(num_layers):
- k_b, v_b = presents[layer_idx]
+ k_b, v_b = presents[layer_idx] # [B, H, max_len+1, D]
+ k_step = k_b.select(2, max_len) # [B, H, D]
+ v_step = v_b.select(2, max_len) # [B, H, D]
for idx, sess in enumerate(sessions):
if sess.finished:
continue
- k_new = k_b[
- idx : idx + 1,
- :,
- max_len : max_len + 1,
- :,
- ]
- v_new = v_b[
- idx : idx + 1,
- :,
- max_len : max_len + 1,
- :,
- ]
kvm.append_token(
layer_idx,
sess.block_ids_per_layer[layer_idx],
- k_new,
- v_new,
+ k_step[idx], # [H, D]
+ v_step[idx], # [H, D]
)
return last_logits
@@ -1453,11 +1443,10 @@ class KVBlockManager:
self,
layer_idx: int,
block_ids: list[int],
- key_new: torch.Tensor,
- value_new: torch.Tensor,
+ key_new: torch.Tensor, # [H, D]
+ value_new: torch.Tensor, # [H, D]
) -> None:
assert 0 <= layer_idx < self.num_layers
- assert key_new.size(2) == 1
if not block_ids:
block_idx = self._alloc_block_index(layer_idx)
global_id = self._to_global_block_id(
@@ -1536,8 +1525,8 @@ class KVBlockManager:
info = self._block_infos[last_id]
k_block, v_block = self._block_storage[last_id]
pos = info.length
- k_block[:, pos, :] = key_new[0, :, 0, :]
- v_block[:, pos, :] = value_new[0, :, 0, :]
+ k_block[:, pos, :] = key_new
+ v_block[:, pos, :] = value_new
new_info = KVBlockInfo(
layer=info.layer,
block_index=info.block_index,
然后我们再重新采一下 profile:
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm$ python -m rosellm.roseinfer.benchmark_scheduler --checkpoint-path rosellm/rosetrainer/checkpoints/gpt2_small_ddp_edu_amp_bf16_init.pt --tokenizer-name gpt2 --device cuda --prompt "Hello" --num-requests 16 --max-new-tokens 16 --mode online --do-sample --top-k 40 --top-p 0.9 --profile
=== online ===
Requests: 16
Elapsed (prefill/add): 0.182028 seconds
Elapsed (decode/run): 0.391101 seconds
Elapsed (total): 0.573130 seconds
Prompt tokens: 16
Completion tokens: 256
Total tokens: 272
Throughput (completion): 446.67 tokens/s
Throughput (total): 474.59 tokens/s
[profile] wrote: profiles/online_decode.json
这里其实可以看到我们的 throughput 也是提高了的,从 408 tokens/s 提高到了 446 tokens/s,我们重新看一下 SQL 的执行结果:
WITH win AS (
SELECT ts AS t0, ts + dur AS t1
FROM slice
WHERE name='roseinfer.kv.append_token' AND cat='user_annotation'
ORDER BY ts LIMIT 1
)
SELECT name, COUNT(*) n, SUM(dur)/1e6 total_ms, AVG(dur)/1e3 avg_us
FROM slice, win
WHERE ts>=win.t0 AND ts<win.t1 AND name LIKE 'aten::%'
GROUP BY name
ORDER BY total_ms DESC
LIMIT 25;
| name | n | total_ms | avg_us |
|---|---|---|---|
| aten::copy_ | 192 | 0.707808 | 3.6865 |
| aten::select | 408 | 0.32413 | 0.7944362745098039 |
| aten::slice | 384 | 0.26385 | 0.687109375 |
| aten::as_strided | 792 | 0.123568 | 0.15602020202020203 |
WITH win AS (
SELECT ts AS t0, ts + dur AS t1
FROM slice
WHERE name='roseinfer.kv.append_token' AND cat='user_annotation'
ORDER BY ts LIMIT 1
)
SELECT name, COUNT(*) n, SUM(dur)/1e6 total_ms
FROM slice, win
WHERE ts>=win.t0 AND ts<win.t1
AND name IN ('aten::slice','aten::select','aten::copy_','aten::as_strided')
GROUP BY name
ORDER BY total_ms DESC;
| name | n | total_ms |
|---|---|---|
| aten::copy_ | 192 | 0.707808 |
| aten::select | 408 | 0.32413 |
| aten::slice | 384 | 0.26385 |
| aten::as_strided | 792 | 0.123568 |
可以看到 slice 等开销的数量大幅减少,并且这些数字都可以解释,比如这里的 copy_ 来源是每层每个 request 哥写一次 kv,对应 12*16,然后 408 次 select 来自每层取新 token:k_step = k_b.select(2, max_len) + v_step = … → 12 * 2 = 24,每个 request 取一行:k_step[idx] + v_step[idx] → 12 * 16 * 2 = 384,合计 24 + 384 = 408,而 aten::slice = 384 基本就是 KVBlockManager.append_token() 里这两句造成的 view(每次调用两次):k_block[:, pos, :] 和 v_block[:, pos, :],对应 12 * 16 * 2 = 384。