从零实现 LLM Inference:019. Paged Attention
在加完 pytorch profiler 之后,顺手做了两个小优化,比如减少 cat 和 slice 的次数,但是这些终究是小打小闹,在本次改动中,我们真正来实现一下 paged attention。
首先我们把 kv block 的管理给换掉,之前我们每一个 kv block id 要对应单独的 tensor,现在我们预先分配好一个大 tensor,后续所有的 kv block 都是直接在这个大 tensor 上的 slice:
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
index 805581c..c2f69de 100644
--- a/rosellm/roseinfer/engine.py
+++ b/rosellm/roseinfer/engine.py
@@ -1337,10 +1337,12 @@ class KVBlockManager:
self._next_block_index: list[int] = [0 for _ in range(num_layers)]
self._free_block_indices: list[list[int]] = [[] for _ in range(num_layers)]
self._block_infos: dict[int, KVBlockInfo] = {}
- self._block_storage: dict[
- int,
- tuple[torch.Tensor, torch.Tensor],
- ] = {} # global_id -> (key_block, value_block)
+ self._k_cache = torch.empty(
+ (num_layers, max_blocks_per_layer, num_heads, block_size, head_dim),
+ device=device,
+ dtype=dtype,
+ )
+ self._v_cache = torch.empty_like(self._k_cache)
self._block_refcounts: dict[int, int] = {}
def _alloc_block_index(self, layer_idx: int) -> int:
@@ -1363,7 +1365,7 @@ class KVBlockManager:
def register_prefill_layer(
self,
layer_idx: int,
- key: torch.Tensor, # [1, H, D, T]
+ key: torch.Tensor, # [1, H, T, D]
value: torch.Tensor,
) -> list[int]:
assert 0 <= layer_idx < self.num_layers
@@ -1389,19 +1391,8 @@ class KVBlockManager:
length=length,
)
self._block_infos[global_id] = info
- k_block = torch.zeros(
- (
- self.num_heads,
- block_size,
- self.head_dim,
- ),
- dtype=self.dtype,
- device=self.device,
- )
- v_block = torch.zeros_like(k_block)
- k_block[:, :length, :] = k_slice[0]
- v_block[:, :length, :] = v_slice[0]
- self._block_storage[global_id] = (k_block, v_block)
+ self._k_cache[layer_idx, block_idx, :, :length, :].copy_(k_slice[0])
+ self._v_cache[layer_idx, block_idx, :, :length, :].copy_(v_slice[0])
self._block_refcounts[global_id] = 1
block_ids.append(global_id)
return block_ids
@@ -1440,7 +1431,6 @@ class KVBlockManager:
self._free_block_indices[layer_idx].append(
info.block_index,
)
- self._block_storage.pop(global_id, None)
def append_token(
self,
@@ -1463,17 +1453,6 @@ class KVBlockManager:
length=0,
)
self._block_infos[global_id] = info
- k_block = torch.zeros(
- (
- self.num_heads,
- self.block_size,
- self.head_dim,
- ),
- dtype=self.dtype,
- device=self.device,
- )
- v_block = torch.zeros_like(k_block)
- self._block_storage[global_id] = (k_block, v_block)
self._block_refcounts[global_id] = 1
block_ids.append(global_id)
last_id = block_ids[-1]
@@ -1493,10 +1472,14 @@ class KVBlockManager:
length=info.length,
)
self._block_infos[new_global_id] = new_info
- k_block_old, v_block_old = self._block_storage[last_id]
- k_block = k_block_old.clone()
- v_block = v_block_old.clone()
- self._block_storage[new_global_id] = (k_block, v_block)
+ self._k_cache[
+ layer_idx,
+ block_idx,
+ ].copy_(self._k_cache[layer_idx, info.block_index])
+ self._v_cache[
+ layer_idx,
+ block_idx,
+ ].copy_(self._v_cache[layer_idx, info.block_index])
self._block_refcounts[new_global_id] = 1
block_ids[-1] = new_global_id
last_id = new_global_id
@@ -1511,25 +1494,15 @@ class KVBlockManager:
length=0,
)
self._block_infos[global_id] = info
- k_block = torch.zeros(
- (
- self.num_heads,
- self.block_size,
- self.head_dim,
- ),
- dtype=self.dtype,
- device=self.device,
- )
- v_block = torch.zeros_like(k_block)
- self._block_storage[global_id] = (k_block, v_block)
self._block_refcounts[global_id] = 1
block_ids.append(global_id)
last_id = global_id
info = self._block_infos[last_id]
- k_block, v_block = self._block_storage[last_id]
+ k_block = self._k_cache[layer_idx, info.block_index]
+ v_block = self._v_cache[layer_idx, info.block_index]
pos = info.length
- k_block[:, pos, :] = key_new
- v_block[:, pos, :] = value_new
+ k_block[:, pos, :].copy_(key_new)
+ v_block[:, pos, :].copy_(value_new)
new_info = KVBlockInfo(
layer=info.layer,
block_index=info.block_index,
@@ -1559,9 +1532,10 @@ class KVBlockManager:
take = end - cur
if take <= 0:
break
- k_block, v_block = self._block_storage[global_id]
- out_k[:, cur:end, :] = k_block[:, :take, :]
- out_v[:, cur:end, :] = v_block[:, :take, :]
+ k_block = self._k_cache[layer_idx, info.block_index]
+ v_block = self._v_cache[layer_idx, info.block_index]
+ out_k[:, cur:end, :].copy_(k_block[:, :take, :])
+ out_v[:, cur:end, :].copy_(v_block[:, :take, :])
cur = end
if cur >= total_len:
break
运行一下 benchmark 看看:
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm$ python -m rosellm.roseinfer.benchmark_scheduler --checkpoint-path rosellm/rosetrainer/checkpoints/gpt2_small_ddp_edu_amp_bf16_init.pt --tokenizer-name gpt2 --device cuda --prompt "Hello" --num-requests 16 --max-new-tokens 16 --mode online --do-sample --top-k 40 --top-p 0.9 --no-stop-on-eos --profile
=== online ===
Requests: 16
Elapsed (prefill/add): 0.177873 seconds
Elapsed (decode/run): 0.426553 seconds
Elapsed (total): 0.604426 seconds
Prompt tokens: 16
Completion tokens: 256
Total tokens: 272
Throughput (completion): 423.54 tokens/s
Throughput (total): 450.01 tokens/s
[profile] wrote: profiles/online_decode.json
接下来我们实现真正的 paged attention,先用纯 pytorch 实现,后续再迁移到 triton / cuda,本次我们先只实现 decode step 时的 paged attention,因为 prefill 时的 paged attention 还要更加复杂。
paged attention 本质实际上是是依次拿 kv blocks 做一个 online attention(online softmax)。
有一个很好地可以用来理解 online attention 的纯 python 代码:
import math
def online_attention(q, ks, vs, scale):
# q: [D]
# ks: list of [D]
# vs: list of [D]
# returns out: [D]
# init using first element to avoid empty
s0 = sum(q[i] * ks[0][i] for i in range(len(q))) * scale
m = s0
l = 1.0
acc = vs[0][:]
for k, v in zip(ks[1:], vs[1:]):
s = sum(q[i] * k[i] for i in range(len(q))) * scale
m_new = max(m, s)
exp_scale_old = math.exp(m - m_new)
exp_s = math.exp(s - m_new)
l = l * exp_scale_old + exp_s
acc = [a * exp_scale_old + exp_s * vv for a, vv in zip(acc, v)]
m = m_new
return [a / l for a in acc]
在全程主要就是维护三个变量:
- m 表示 score 的最大值,用来做 softmax 的稳定版实现,也就是 exp 里面减掉所有值的最大值那个
- l 表示 softmax 分母上的那个 exp 求和,也是带了减去所有值的最大值的那个逻辑的
- acc 表示 softmax 分子上的那个用了 score 做权重的加权 exp 求和,也是带了减去所有值的最大值的那个逻辑的
然后我们可以有一个 pytorch 以及 triton 的实现:
from __future__ import annotations
from dataclasses import dataclass
import torch
try:
import triton
import triton.language as tl
except ImportError: # pragma: no cover
triton = None # type: ignore[assignment]
tl = None # type: ignore[assignment]
TRITON_AVAILABLE = triton is not None
@dataclass(frozen=True)
class PagedKVCache:
k_cache: torch.Tensor
v_cache: torch.Tensor
block_tables: list[torch.Tensor]
context_lens: torch.Tensor
block_size: int
def paged_attention_decode_ref(
q: torch.Tensor, # [B, H, D]
k_new: torch.Tensor, # [B, H, D]
v_new: torch.Tensor, # [B, H, D]
k_cache_layer: torch.Tensor, # [N_BLOCKS, H, BS, D]
v_cache_layer: torch.Tensor, # [N_BLOCKS, H, BS, D], BS: block size
block_table: torch.Tensor, # [B, N_LOGICAL_BLOCKS]
context_lens: torch.Tensor, # [B]
*,
scale: float,
block_size: int,
) -> torch.Tensor: # [B, H, D]
assert q.dim() == 3
assert q.shape == k_new.shape == v_new.shape
assert k_cache_layer.dim() == 4 and v_cache_layer.dim() == 4
assert block_table.dim() == 2
assert context_lens.dim() == 1
assert k_cache_layer.size(2) == block_size
device = q.device
bsz, n_heads, head_dim = q.shape
num_blocks = block_table.size(1)
q_f = q.float()
k_new_f = k_new.float() # [B, H, D]
v_new_f = v_new.float() # [B, H, D]
scores_cur = (q_f * k_new_f).sum(dim=-1) * scale # [B, H]
# m: max logits so far, [B, H]
m = scores_cur
# l: exp-sum, [B, H]
l = torch.ones((bsz, n_heads), device=device, dtype=torch.float32)
# o: weighted sum, [B, H, D]
o = v_new_f
pos = torch.arange(block_size, device=device).view(1, 1, block_size)
for logical_block in range(num_blocks):
block_ids = block_table[:, logical_block] # [B]
k_blk = k_cache_layer[block_ids].float() # [B, H, BS, D]
v_blk = v_cache_layer[block_ids].float() # [B, H, BS, D]
start = logical_block * block_size
valid = (context_lens - start).clamp(min=0, max=block_size) # [B]
mask = pos < valid.view(bsz, 1, 1) # [B, 1, BS] -> broadcast on head dim
scores = torch.einsum("bhd,bhtd->bht", q_f, k_blk) * scale
scores = scores.masked_fill(~mask, -float("inf")) # [B, H, BS]
m_ij = scores.max(dim=-1).values # [B, H]
m_new = torch.maximum(m, m_ij) # [B, H]
exp_scale_old = torch.exp(m - m_new) # [B, H]
exp_scores = torch.exp(scores - m_new.unsqueeze(-1)) # [B, H, BS]
l = l * exp_scale_old + exp_scores.sum(dim=-1) # [B, H]
o = o * exp_scale_old.unsqueeze(-1) + torch.einsum(
"bht,bhtd->bhd", exp_scores, v_blk
)
m = m_new
out = (o / l.unsqueeze(-1)).to(dtype=q.dtype) # [B, H, D]
return out
if TRITON_AVAILABLE:
@triton.jit
def _paged_attn_decode_kernel(
out_ptr,
q_ptr,
k_new_ptr,
v_new_ptr,
k_cache_ptr,
v_cache_ptr,
block_table_ptr,
context_lens_ptr,
stride_kcb: tl.constexpr,
stride_kch: tl.constexpr,
stride_kct: tl.constexpr,
stride_kcd: tl.constexpr,
stride_vcb: tl.constexpr,
stride_vch: tl.constexpr,
stride_vct: tl.constexpr,
stride_vcd: tl.constexpr,
scale: tl.constexpr,
H: tl.constexpr,
D: tl.constexpr,
BLOCK_SIZE: tl.constexpr,
MAX_BLOCKS: tl.constexpr,
):
pid = tl.program_id(0)
b = pid // H
h = pid % H
d = tl.arange(0, D)
base = (b * H + h) * D + d
q = tl.load(q_ptr + base, mask=d < D, other=0.0).to(tl.float32)
k_new = tl.load(k_new_ptr + base, mask=d < D, other=0.0).to(tl.float32)
v_new = tl.load(v_new_ptr + base, mask=d < D, other=0.0).to(tl.float32)
score_cur = tl.sum(q * k_new, axis=0) * scale
m = score_cur
l = 1.0
acc = v_new
context_len = tl.load(context_lens_ptr + b).to(tl.int32)
t = tl.arange(0, BLOCK_SIZE)
for lb in tl.static_range(0, MAX_BLOCKS):
start = lb * BLOCK_SIZE
tok_pos = start + t
tok_mask = tok_pos < context_len
has_any = start < context_len
block_id = tl.load(
block_table_ptr + b * MAX_BLOCKS + lb,
mask=has_any,
other=0,
).to(tl.int32)
k_ptrs = (
k_cache_ptr
+ block_id * stride_kcb
+ h * stride_kch
+ t[:, None] * stride_kct
+ d[None, :] * stride_kcd
)
v_ptrs = (
v_cache_ptr
+ block_id * stride_vcb
+ h * stride_vch
+ t[:, None] * stride_vct
+ d[None, :] * stride_vcd
)
k = tl.load(
k_ptrs,
mask=tok_mask[:, None] & (d[None, :] < D),
other=0.0,
).to(tl.float32)
v = tl.load(
v_ptrs,
mask=tok_mask[:, None] & (d[None, :] < D),
other=0.0,
).to(tl.float32)
scores = tl.sum(k * q[None, :], axis=1) * scale
scores = tl.where(tok_mask, scores, -float("inf"))
m_ij = tl.max(scores, axis=0)
m_new = tl.maximum(m, m_ij)
exp_scale_old = tl.exp(m - m_new)
exp_scores = tl.exp(scores - m_new)
l = l * exp_scale_old + tl.sum(exp_scores, axis=0)
acc = acc * exp_scale_old + tl.sum(exp_scores[:, None] * v, axis=0)
m = m_new
out = acc / l
tl.store(out_ptr + base, out, mask=d < D)
def paged_attention_decode_triton(
q: torch.Tensor, # [B, H, D]
k_new: torch.Tensor, # [B, H, D]
v_new: torch.Tensor, # [B, H, D]
k_cache_layer: torch.Tensor, # [N_BLOCKS, H, BS, D]
v_cache_layer: torch.Tensor, # [N_BLOCKS, H, BS, D]
block_table: torch.Tensor, # [B, MAX_BLOCKS] int32 cuda
context_lens: torch.Tensor, # [B] int32 cuda
*,
scale: float,
block_size: int,
) -> torch.Tensor: # [B, H, D]
if not TRITON_AVAILABLE:
raise RuntimeError(
"paged_attention_decode_triton requires Triton; install it to use --paged-attn"
)
assert q.is_cuda
q = q.contiguous()
k_new = k_new.contiguous()
v_new = v_new.contiguous()
if block_table.dtype != torch.int32:
block_table = block_table.to(torch.int32)
if context_lens.dtype != torch.int32:
context_lens = context_lens.to(torch.int32)
B, H, D = q.shape
out = torch.empty_like(q)
grid = (B * H,)
_paged_attn_decode_kernel[grid](
out,
q,
k_new,
v_new,
k_cache_layer,
v_cache_layer,
block_table,
context_lens,
stride_kcb=k_cache_layer.stride(0),
stride_kch=k_cache_layer.stride(1),
stride_kct=k_cache_layer.stride(2),
stride_kcd=k_cache_layer.stride(3),
stride_vcb=v_cache_layer.stride(0),
stride_vch=v_cache_layer.stride(1),
stride_vct=v_cache_layer.stride(2),
stride_vcd=v_cache_layer.stride(3),
scale=scale,
H=H,
D=D,
BLOCK_SIZE=block_size,
MAX_BLOCKS=block_table.size(1),
num_warps=4,
)
return out
然后我们在 InferenceEngine 里面加一个 use_paged_attention 的 flag,在 decode_step_sessions 方法中判断这个 flag,走 paged attention 逻辑:
if self.use_paged_attention:
from rosellm.rosetrainer.paged_attention import PagedKVCache
block_size = kvm.block_size
num_blocks_max = self.max_blocks_per_seq
max_blocks_per_layer = kvm.max_blocks_per_layer
block_tables_buf = self._get_paged_block_tables_buf(batch_size)
with record_function(
"roseinfer.decode_step_sessions.build_block_tables",
):
block_tables: list[torch.Tensor] = []
for layer_idx in range(num_layers):
offset = layer_idx * max_blocks_per_layer
rows: list[list[int]] = []
for idx, sess in enumerate(sessions):
ids = sess.block_ids_per_layer[layer_idx]
physical = [gid - offset for gid in ids]
if not physical:
physical = [0]
if len(physical) < num_blocks_max:
physical = physical + [0] * (
num_blocks_max - len(physical)
)
else:
physical = physical[:num_blocks_max]
rows.append(physical)
cpu_table = torch.tensor(rows, dtype=torch.int32)
block_table = block_tables_buf[layer_idx, :batch_size]
block_table.copy_(cpu_table)
block_tables.append(block_table)
paged = PagedKVCache(
k_cache=kvm._k_cache,
v_cache=kvm._v_cache,
block_tables=block_tables,
context_lens=lens.to(torch.int32),
block_size=block_size,
)
with record_function(
"roseinfer.model.forward",
):
if self.use_amp:
with autocast(device_type=device.type, dtype=self.amp_dtype):
logits, _, presents = self.model(
input_ids=input_ids,
attention_mask=None,
labels=None,
past_key_values=None,
use_cache=True,
position_ids=position_ids,
paged_kv_cache=paged,
)
else:
logits, _, presents = self.model(
input_ids=input_ids,
attention_mask=None,
labels=None,
past_key_values=None,
use_cache=True,
position_ids=position_ids,
paged_kv_cache=paged,
)
last_logits = logits[:, -1, :] # [B, V]
with record_function("roseinfer.kv.append_token"):
for layer_idx in range(num_layers):
k_step, v_step = presents[layer_idx] # [B, H, 1, D]
k_step = k_step.squeeze(2) # [B, H, D]
v_step = v_step.squeeze(2)
for idx, sess in enumerate(sessions):
kvm.append_token(
layer_idx,
sess.block_ids_per_layer[layer_idx],
k_step[idx],
v_step[idx],
)
return last_logits
这个构造的 paged_kv_cache 也要通过 model 一路传入,传到 MHA 的实现当中去:
def forward(
self,
x: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None, # [B, T]
past_kv: Optional[tuple[torch.Tensor, torch.Tensor]] = None,
return_kv: bool = False,
paged_kv_cache: Optional[PagedKVCache] = None,
layer_idx: int = 0,
):
bsz, seq_len, _ = x.size()
qkv = self.qkv_proj(x)
qkv = qkv.view(bsz, seq_len, 3, self.local_heads, self.d_head)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # [B, H, T, D]
if paged_kv_cache is not None:
if past_kv is not None:
raise ValueError("past_kv and paged_kv_cache cannot be used together")
if seq_len != 1:
raise ValueError("paged attention only supports decode(T=1)")
out_h = paged_attention_decode(
q=q.squeeze(-2), # [B, H, D]
k_new=k.squeeze(-2), # [B, H, D]
v_new=v.squeeze(-2),
k_cache_layer=paged_kv_cache.k_cache[layer_idx],
v_cache_layer=paged_kv_cache.v_cache[layer_idx],
block_table=paged_kv_cache.block_tables[layer_idx],
context_lens=paged_kv_cache.context_lens,
scale=self.d_head**-0.5,
block_size=paged_kv_cache.block_size,
) # [B, H, D]
attn_output = out_h.unsqueeze(2) # [B, H, 1, D]
# [B, 1, H, D]
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(
bsz,
seq_len,
self.local_heads * self.d_head,
)
out = self.out_proj(attn_output)
out = self.dropout(out)
if return_kv:
return out, (k, v)
return out
然后我们可以看一下执行结果对比:
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm$ ./rosellm/benchmark_scheduler.sh
benchmarking scheduler with prefix cache
benchmarking naive scheduler
=== naive ===
Requests: 64
Elapsed: 4.287712 seconds
Prompt tokens: 54784
Completion tokens: 1024
Total tokens: 55808
Throughput (completion,total): 238.82 tokens/s
Throughput (total,total): 13015.80 tokens/s
benchmarking offline scheduler
=== offline summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 3.328733/3.323905 s
Total time p50/mean: 3.412538/3.409548 s
Throughput(completion,decode) p50/mean: 307.62/308.08 tokens/s
Throughput(completion,total) p50/mean: 300.07/300.34 tokens/s
benchmarking offline scheduler with paged attention
=== offline summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 0.552867/0.552553 s
Total time p50/mean: 0.637499/0.636906 s
Throughput(completion,decode) p50/mean: 1852.16/1853.26 tokens/s
Throughput(completion,total) p50/mean: 1606.28/1607.81 tokens/s
benchmarking online scheduler
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 3.547538/3.547915 s
Total time p50/mean: 3.634948/3.633433 s
Throughput(completion,decode) p50/mean: 288.65/288.62 tokens/s
Throughput(completion,total) p50/mean: 281.71/281.83 tokens/s
benchmarking online scheduler with paged attention
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 0.817962/0.817625 s
Total time p50/mean: 0.903413/0.903425 s
Throughput(completion,decode) p50/mean: 1251.89/1252.41 tokens/s
Throughput(completion,total) p50/mean: 1133.48/1133.46 tokens/s
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm$
加了 paged attention 之后,吞吐可以从 281 tokens/s 直接提升到 1133 tokens/s,然后我们再看一下 trace profile 对比:
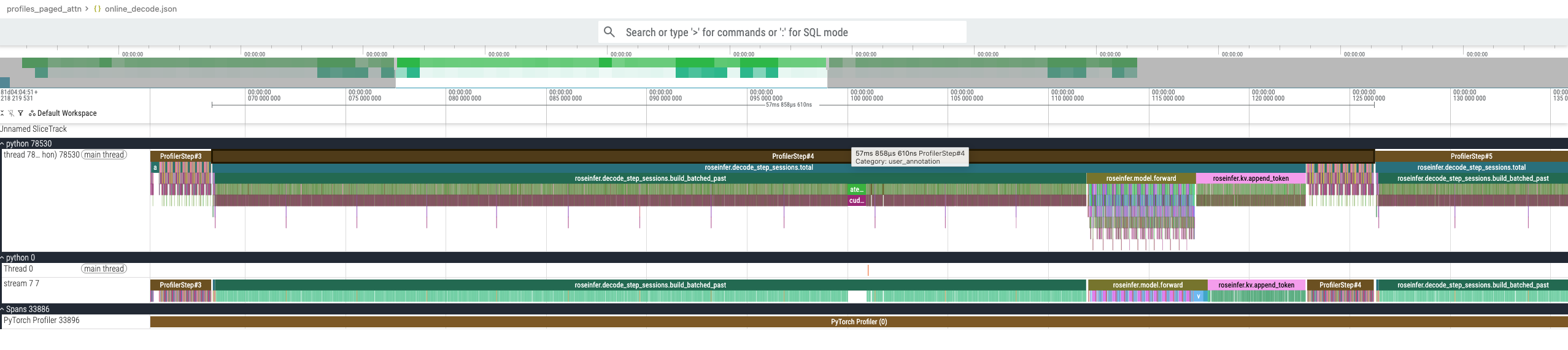
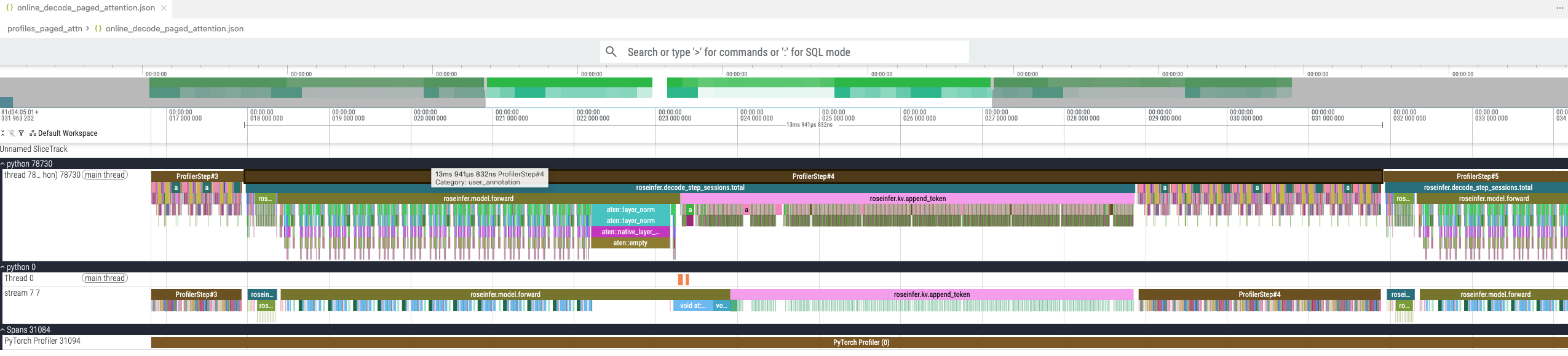
没用 paged attention 的时候一个 step 的开销是 57ms,用了之后是 13ms,并且 build_batched_past 的开销完全干掉了。