从零实现 LLM Inference:035. Paged Attention Fast Path
上一版我们把 prefill admission / decode loop 的调度策略逐步补齐了;但在算子层面,paged attention 这条路目前还没“跑顺”。
这次 mini PR 聚焦一个很具体的问题:paged attention decode(T=1) 的 fast path。
直觉上,paged attention 的 forward 已经完全不依赖 attention_mask(由 block_table + context_lens 决定有效 token 范围),所以 decode 每一步不应该再构建 dense 的 [B, L] mask。
但我们在 InferenceEngine.decode_step_sessions() 里,哪怕走 paged attention 分支,仍然会每步做:
torch.arange(max_len)->past_mask->cat->attention_mask
这段既有额外的 kernel/alloc,也会制造没必要的 GPU traffic。
另外一个小点:block_table 当前是每步从 Python list 构建出来,然后 per-layer 做 CPU->GPU copy;我们可以用一个 pinned CPU staging buffer 把 H2D copy 变成一次 non_blocking=True 的大拷贝。
代码变更
roseinfer/engine.py
- paged attention 分支不再构建
attention_mask(只保留position_ids+lens)。 - 增加
_get_paged_block_tables_cpu_buf():复用 pinned CPU buffer。 block_tables的 H2D copy 合并成一次,并标注一个新的 profiler range:roseinfer.decode_step_sessions.h2d_block_tables。
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
index c41ed51..5c7f8b6 100644
--- a/rosellm/roseinfer/engine.py
+++ b/rosellm/roseinfer/engine.py
@@ -128,6 +128,8 @@ class InferenceEngine:
)
self._paged_block_tables_buf: torch.Tensor | None = None
self._paged_block_tables_capacity: int = 0
+ self._paged_block_tables_cpu_buf: torch.Tensor | None = None
+ self._paged_block_tables_cpu_capacity: int = 0
@@ -869,6 +871,28 @@ class InferenceEngine:
self._paged_block_tables_capacity = cap
return self._paged_block_tables_buf
+ def _get_paged_block_tables_cpu_buf(
+ self,
+ batch_size: int,
+ ) -> torch.Tensor:
+ if (
+ self._paged_block_tables_cpu_buf is None
+ or self._paged_block_tables_cpu_capacity < batch_size
+ ):
+ cap = max(batch_size, self._paged_block_tables_cpu_capacity * 2, 16)
+ self._paged_block_tables_cpu_buf = torch.empty(
+ (
+ self.config.n_layers,
+ cap,
+ self.max_blocks_per_seq,
+ ),
+ device="cpu",
+ dtype=torch.int32,
+ pin_memory=(self.device.type == "cuda"),
+ )
+ self._paged_block_tables_cpu_capacity = cap
+ return self._paged_block_tables_cpu_buf
@@ -893,7 +917,6 @@ class InferenceEngine:
seq_lens.append(seq_len)
assert len(last_ids) == batch_size
lens = torch.tensor(seq_lens, device=device, dtype=torch.long)
- max_len = max(seq_lens)
@@ -901,22 +924,6 @@ class InferenceEngine:
device=device,
).view(batch_size, 1)
position_ids = lens.view(batch_size, 1)
- past_mask = torch.arange(
- max_len,
- device=device,
- ).unsqueeze(0) < lens.unsqueeze(1)
- new_mask = torch.ones(
- batch_size,
- 1,
- device=device,
- dtype=past_mask.dtype,
- )
- attention_mask = torch.cat(
- [past_mask, new_mask],
- dim=1,
- ).to(torch.long)
num_layers = kvm.num_layers
@@
max_blocks_per_layer = kvm.max_blocks_per_layer
block_tables_buf = self._get_paged_block_tables_buf(batch_size)
+ block_tables_cpu = self._get_paged_block_tables_cpu_buf(batch_size)
with record_function(
"roseinfer.decode_step_sessions.build_block_tables",
):
- block_tables: list[torch.Tensor] = []
for layer_idx in range(num_layers):
@@
- cpu_table = torch.tensor(rows, dtype=torch.int32)
- block_table = block_tables_buf[layer_idx, :batch_size]
- block_table.copy_(cpu_table)
- block_tables.append(block_table)
+ tmp = torch.tensor(rows, dtype=torch.int32)
+ block_tables_cpu[layer_idx, :batch_size].copy_(tmp)
+ with record_function(
+ "roseinfer.decode_step_sessions.h2d_block_tables",
+ ):
+ block_tables_buf[:, :batch_size].copy_(
+ block_tables_cpu[:, :batch_size],
+ non_blocking=True,
+ )
+ block_tables = [
+ block_tables_buf[layer_idx, :batch_size]
+ for layer_idx in range(num_layers)
+ ]
@@
return last_logits
+ max_len = max(seq_lens)
+ past_mask = torch.arange(
+ max_len,
+ device=device,
+ ).unsqueeze(0) < lens.unsqueeze(1)
+ new_mask = torch.ones(
+ batch_size,
+ 1,
+ device=device,
+ dtype=past_mask.dtype,
+ )
+ attention_mask = torch.cat(
+ [past_mask, new_mask],
+ dim=1,
+ ).to(torch.long)
运行
pytest -q
22 passed, 1 warning in 1.66s
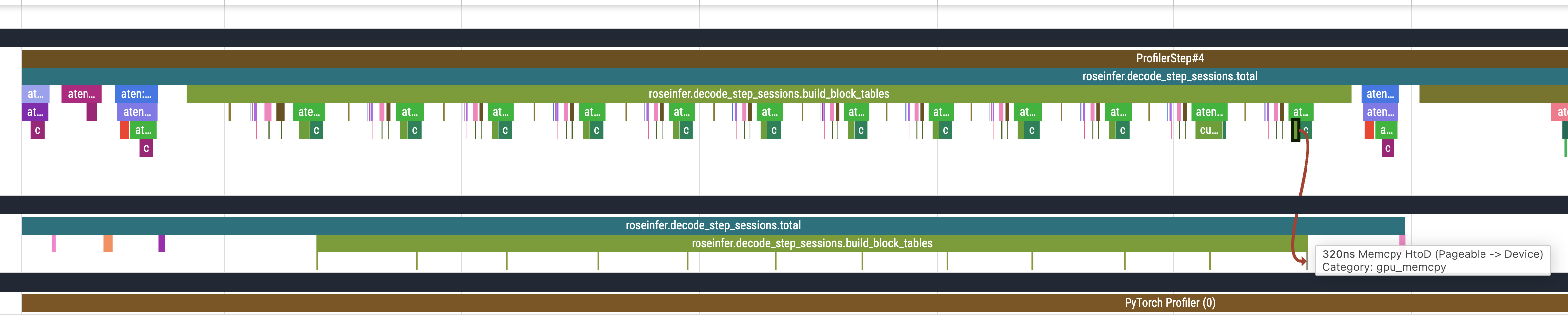
Trace 图对比
修改之前,我们可以发现在 build block tables 的时候会有很多次 HtoD 的 kernel launch,修改之后就只有一次 HtoD 的 kernel launch 了:

Benchmark(HF GPT-2)
为了让对比更稳定:
- 用
--pretok把 tokenizer 的耗时移出计时区间 - 用
--no-stop-on-eos固定每个请求 decode 的 token 数 - 用
--no-prefix-cache避免 prefix cache/COW 干扰
Before
python -m rosellm.roseinfer.benchmark_scheduler \
--hf-model-id gpt2 --device cuda \
--prompt "Hello" --num-requests 16 --max-new-tokens 256 \
--mode online --max-batch-size 8 \
--no-stop-on-eos --no-prefix-cache --pretok \
--warmup-runs 1 --repeat-runs 3 \
--paged-attn
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 2.145921/2.146833 s
Total time p50/mean: 2.188248/2.190020 s
Throughput(completion,decode) p50/mean: 1908.74/1907.93 tokens/s
Throughput(completion,total) p50/mean: 1871.82/1870.31 tokens/s
TTFT p50/mean: 2.68/2.67 ms
TPOT p50/mean: 8.45/8.46 ms/token
Latency p50/mean: 2157.70/2159.16 ms
After
python -m rosellm.roseinfer.benchmark_scheduler \
--hf-model-id gpt2 --device cuda \
--prompt "Hello" --num-requests 16 --max-new-tokens 256 \
--mode online --max-batch-size 8 \
--no-stop-on-eos --no-prefix-cache --pretok \
--warmup-runs 1 --repeat-runs 3 \
--paged-attn
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 2.132166/2.133335 s
Total time p50/mean: 2.174574/2.176261 s
Throughput(completion,decode) p50/mean: 1921.05/1920.00 tokens/s
Throughput(completion,total) p50/mean: 1883.59/1882.13 tokens/s
TTFT p50/mean: 2.65/2.66 ms
TPOT p50/mean: 8.40/8.40 ms/token
Latency p50/mean: 2143.61/2145.06 ms
这次提升不算大(GPT-2 context=1024,本身 block_table 很小),但方向是对的:paged attention 的 decode path 先把“无意义的 dense mask 构建”和“碎片化的 H2D copy”清掉,后面再继续往 block_table 常驻 GPU / 增量更新 / 更大 context 的模型推进。