从零实现 LLM Inference:041. Batched Sampler(干掉 per-request .item() 同步)
上一版我们把 paged decode 热路径用 CUDA Graph 捕获起来了,model forward 这段 CPU dispatch 明显下降。
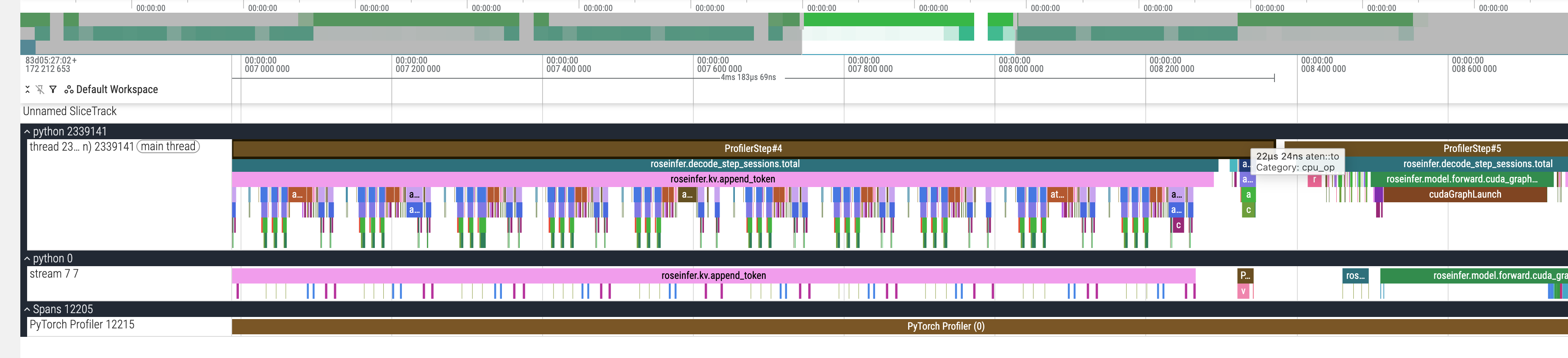
但我在继续看 profile 的时候发现:decode 里还有一个非常“阴间”的点 —— sampling 的 .item()。

现在的执行流程大概是:
decode_step_sessions()一次算出[B, V]的 logits- scheduler 里对每个 request 循环:
torch.argmax(...)或torch.multinomial(...)- 然后
.item()取出 token id,塞进 Python 的generated_ids
这在 CUDA 上等价于:每步触发 B 次 device sync。
以我们的 benchmark 配置:
B=64T=512
仅仅 .item() 就是 64*512=32768 次。CPU thread 会被这些同步点打成碎片,GPU 也更容易出现空洞。
这一版就做一件事:把 sampling 改成 batch,并且把同步次数从 “每步 B 次” 降到 “每步 1 次(或按参数分组后的 G 次)”。
修改完之后的 profile 图,可以看到 item 相关的同步开销都没有了:
代码变更
roseinfer/engine.py
核心做法:
_sample_next_token_batch()真正 batch 化:argmax/multinomial直接对[B, V]做InferenceSession增加apply_token_id():把“写入 token + finished 判断”的语义收敛到一个地方OfflineScheduler.step()/OnlineScheduler.step():- 按
(temperature, top_k, top_p, do_sample)分组(避免不同参数混在一起) - 每组采样一次 →
tolist()一次 → 再按原顺序更新 session
- 按
generate_batch()顺手把 per-token.item()换成一次tolist()
核心 diff:
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
@@
def _sample_next_token_batch(
@@
- batch_size = logits.size(0)
- next_ids = []
- for i in range(batch_size):
- next_id = self._sample_next_token(
- logits=logits[i : i + 1],
- temperature=temperature,
- top_k=top_k,
- top_p=top_p,
- do_sample=do_sample,
- )
- next_ids.append(next_id)
- return torch.tensor(
- next_ids,
- dtype=torch.long,
- device=self.device,
- )
+ if logits.dim() != 2:
+ raise ValueError(
+ f"logits must be 2D [B, V], got shape={tuple(logits.shape)}"
+ )
+ if not do_sample or temperature <= 0.0:
+ return torch.argmax(logits, dim=-1)
+ scaled = logits / float(temperature)
+ filtered = self._top_k_logits(scaled, top_k)
+ filtered = self._top_p_logits(filtered, top_p)
+ probs = torch.softmax(filtered, dim=-1).clamp_min(1e-9)
+ return torch.multinomial(probs, num_samples=1).squeeze(-1)
@@
+ next_list = next_ids.tolist()
for b in range(batch_size):
- token_id = int(next_ids[b].item())
+ token_id = int(next_list[b])
@@
+ next_list = next_ids.tolist()
for b in range(batch_size):
- token_id = int(next_ids[b].item())
+ token_id = int(next_list[b])
@@
class InferenceSession:
@@
- token_id = int(next_token)
+ return self.apply_token_id(int(next_token))
+
+ def apply_token_id(self, token_id: int) -> int | None:
+ if self.finished:
+ return None
+ eng = self.engine
+ token_id = int(token_id)
self.generated_ids.append(token_id)
self.step_count += 1
@@
- token_id = int(next_token)
- self.generated_ids.append(token_id)
- self.step_count += 1
- ...
- return token_id
+ return self.apply_token_id(int(next_token))
@@
class OnlineScheduler:
@@
- for idx, (rid, sess) in enumerate(selected_pairs):
- logits_row = last_logits[idx]
- token_id = sess.apply_batch_logits(logits_row)
+ groups: dict[tuple[float, int, float, bool], list[int]] = {}
+ for i, (_, sess) in enumerate(selected_pairs):
+ key = (
+ float(sess.temperature),
+ int(sess.top_k),
+ float(sess.top_p),
+ bool(sess.do_sample),
+ )
+ groups.setdefault(key, []).append(i)
+
+ next_token_ids: list[int] = [0 for _ in range(len(selected_pairs))]
+ for (temp, top_k, top_p, do_sample), idxs in groups.items():
+ if len(idxs) == len(selected_pairs) and idxs == list(
+ range(len(selected_pairs))
+ ):
+ next_ids = self.engine._sample_next_token_batch(
+ logits=last_logits,
+ temperature=temp,
+ top_k=top_k,
+ top_p=top_p,
+ do_sample=do_sample,
+ )
+ next_token_ids = [int(x) for x in next_ids.tolist()]
+ break
+ idx_t = torch.tensor(idxs, device=self.engine.device, dtype=torch.long)
+ logits_g = last_logits.index_select(0, idx_t)
+ next_ids = self.engine._sample_next_token_batch(
+ logits=logits_g,
+ temperature=temp,
+ top_k=top_k,
+ top_p=top_p,
+ do_sample=do_sample,
+ )
+ next_list = next_ids.tolist()
+ for pos, i in enumerate(idxs):
+ next_token_ids[i] = int(next_list[pos])
+
+ for i, (rid, sess) in enumerate(selected_pairs):
+ token_id = sess.apply_token_id(next_token_ids[i])
if token_id is not None:
step_tokens[rid] = token_id
...
运行
pytest -q
...................... [100%]
=============================== warnings summary ===============================
../anaconda3/lib/python3.10/site-packages/urllib3/util/ssl_.py:260
/data/projects/anaconda3/lib/python3.10/site-packages/urllib3/util/ssl_.py:260: DeprecationWarning: ssl.PROTOCOL_TLS is deprecated
context = SSLContext(ssl_version or PROTOCOL_TLS)
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
22 passed, 1 warning in 1.62s
Benchmark(HF GPT-2)
命令(固定 batch size,让 CUDA Graph 命中,观察 decode 热路径):
python -m rosellm.roseinfer.benchmark_scheduler \
--hf-model-id gpt2 --device cuda \
--prompt "Hello" --num-requests 64 --max-new-tokens 512 \
--mode online --max-batch-size 64 \
--no-stop-on-eos --no-prefix-cache --pretok \
--warmup-runs 1 --repeat-runs 3 \
--paged-attn --cuda-graph
Before
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 3.086967/3.085313 s
Total time p50/mean: 3.259437/3.260032 s
Throughput(completion,decode) p50/mean: 10614.95/10620.69 tokens/s
Throughput(completion,total) p50/mean: 10053.27/10051.52 tokens/s
TTFT p50/mean: 2.67/2.70 ms
TPOT p50/mean: 6.08/6.08 ms/token
Latency p50/mean: 3107.52/3107.88 ms
After
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 2.321829/2.321524 s
Total time p50/mean: 2.496341/2.497009 s
Throughput(completion,decode) p50/mean: 14113.01/14114.89 tokens/s
Throughput(completion,total) p50/mean: 13126.41/13122.91 tokens/s
TTFT p50/mean: 2.71/2.72 ms
TPOT p50/mean: 4.58/4.58 ms/token
Latency p50/mean: 2342.84/2343.89 ms
结论
这次的收益来源非常明确:把 “每步 B 次 .item() 同步” 变成 “每步 1 次 tolist() 同步(或按参数分组后的 G 次)”。
在这组数据里(mean):
- decode 吞吐:
10620.69 → 14114.89 tokens/s(约 +32.9%) - TPOT:
6.08 → 4.58 ms/token(约 -24.7%) - 总延迟:
3107.88 → 2343.89 ms(约 -24.6%)
后面如果要继续压:
- 复用
idx_t/next_token_idsbuffer,减少每步小 tensor 分配 - 让采样结果的 CPU 侧获取更“流式”(比如 pinned CPU buffer + async copy),进一步降低同步点的侵入性