从零实现 LLM Inference:042. Triton KV Append(把 KV 写入从 4 个 op 合成 1 个 kernel)
paged-attn + CUDA Graph 把 model.forward() 的 CPU dispatch 压下去之后,decode 热路径里还有一段“固定会跑、而且每层都跑”的逻辑:
presents[layer] -> (k_step, v_step)- 写回 KV cache(每层一次)
之前的 fast-path 写法大概是:
index_select选出[B, H, D]的k_src/v_srck_cache[blk, :, pos, :] = .../v_cache[...] = ...
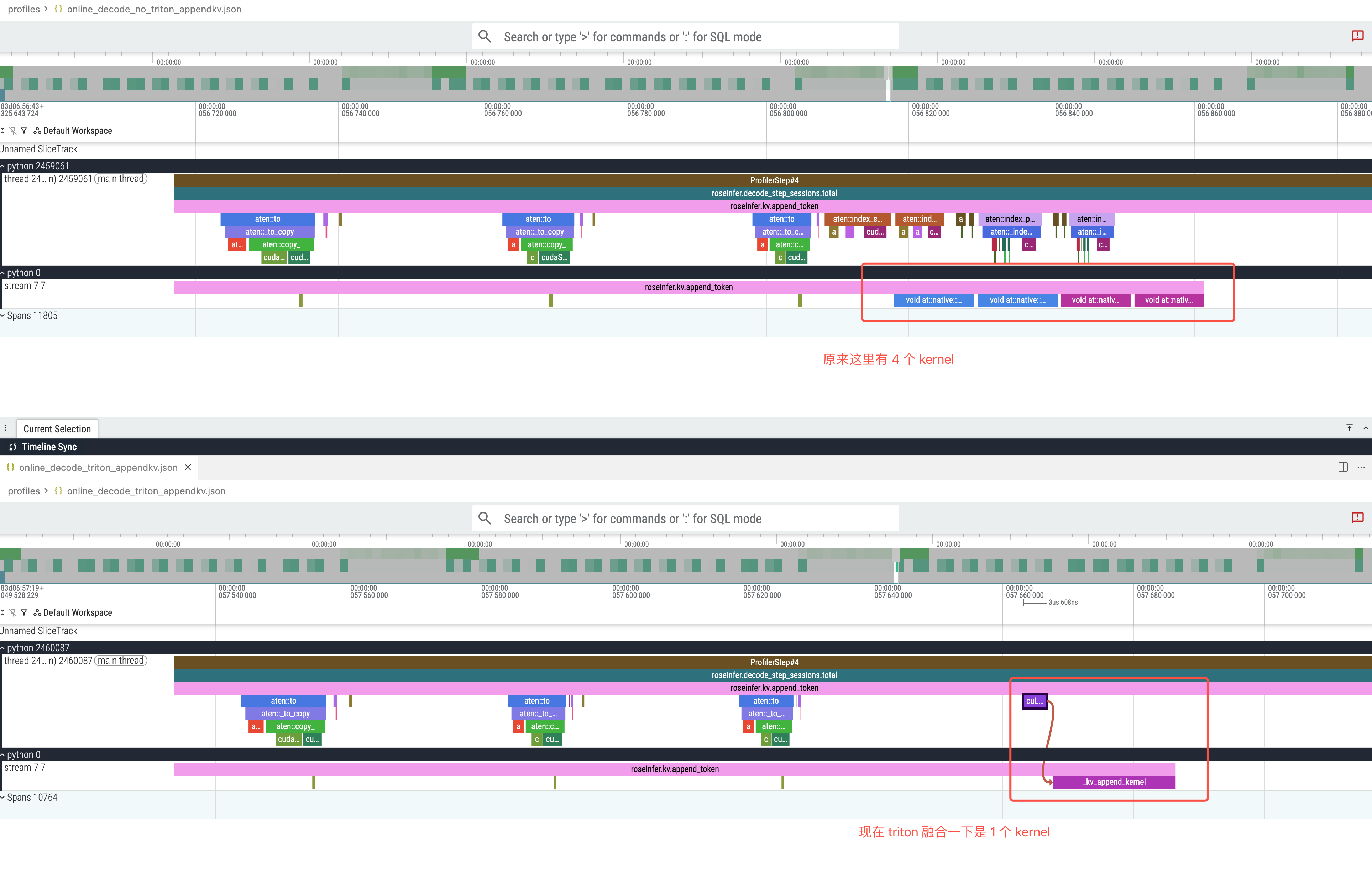
等价于 K/V 各 2 个 op,合计 4 个 kernel(还伴随一些小 tensor 的构造)。
这一版的目标很明确:把 fast-path 的 KV 写入 fuse 成 一次 Triton kernel,并且提供一个 batch size gate(默认 >=128 才启用),避免小 batch 退化。
前后 torch profile 对比:
代码变更
roseinfer/kv_append_triton.py
新增一个最小 Triton kernel:输入 (batch_idx, block_idx, pos),直接把 [B, H, D] 写进 [N_BLOCKS, H, BS, D]。
同时加两个环境变量开关:
ROSELLM_TRITON_KV_APPEND=0/1:总开关(默认开)ROSELLM_TRITON_KV_APPEND_MIN_BATCH=128:小于这个 batch 就不启用(默认 128)
roseinfer/engine.py
KVBlockManager.append_token_batch() 的 fast-path 里:
- CUDA + Triton 可用 + batch size 达标 → 走
kv_append_triton() - 否则保持原来的 torch 写法(fallback)
核心 diff:
diff --git a/rosellm/roseinfer/engine.py b/rosellm/roseinfer/engine.py
@@
if fast_batch_idx:
device = self.device
- idx_t = torch.tensor(...)
- blk_t = torch.tensor(...)
- pos_t = torch.tensor(...)
- k_src = key_new.index_select(0, idx_t)
- v_src = value_new.index_select(0, idx_t)
k_layer = self._k_cache[layer_idx]
v_layer = self._v_cache[layer_idx]
- k_layer[blk_t, :, pos_t, :] = k_src
- v_layer[blk_t, :, pos_t, :] = v_src
+ use_triton = False
+ kv_append_triton = None
+ if device.type == "cuda":
+ try:
+ from rosellm.roseinfer.kv_append_triton import (
+ TRITON_AVAILABLE,
+ TRITON_KV_APPEND_MIN_BATCH,
+ USE_TRITON_KV_APPEND,
+ kv_append_triton as _kv_append_triton,
+ )
+ use_triton = (
+ TRITON_AVAILABLE
+ and USE_TRITON_KV_APPEND
+ and len(fast_batch_idx) >= TRITON_KV_APPEND_MIN_BATCH
+ )
+ kv_append_triton = _kv_append_triton
+ except Exception:
+ use_triton = False
+ kv_append_triton = None
+
+ if use_triton and kv_append_triton is not None:
+ idx_t = torch.tensor(fast_batch_idx, device=device, dtype=torch.int32)
+ blk_t = torch.tensor(fast_block_idx, device=device, dtype=torch.int32)
+ pos_t = torch.tensor(fast_pos, device=device, dtype=torch.int32)
+ kv_append_triton(
+ k_cache_layer=k_layer,
+ v_cache_layer=v_layer,
+ key_new=key_new,
+ value_new=value_new,
+ batch_idx=idx_t,
+ block_idx=blk_t,
+ pos=pos_t,
+ )
+ else:
+ idx_t = torch.tensor(fast_batch_idx, device=device, dtype=torch.long)
+ blk_t = torch.tensor(fast_block_idx, device=device, dtype=torch.long)
+ pos_t = torch.tensor(fast_pos, device=device, dtype=torch.long)
+ k_src = key_new.index_select(0, idx_t)
+ v_src = value_new.index_select(0, idx_t)
+ k_layer[blk_t, :, pos_t, :] = k_src
+ v_layer[blk_t, :, pos_t, :] = v_src
运行
pytest -q
....................... [100%]
=============================== warnings summary ===============================
../anaconda3/lib/python3.10/site-packages/urllib3/util/ssl_.py:260
/data/projects/anaconda3/lib/python3.10/site-packages/urllib3/util/ssl_.py:260: DeprecationWarning: ssl.PROTOCOL_TLS is deprecated
context = SSLContext(ssl_version or PROTOCOL_TLS)
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
23 passed, 1 warning in 2.12s
Benchmark(HF GPT-2)
命令(强行固定 batch size,让 decode 走 paged-attn + CUDA Graph):
python -m rosellm.roseinfer.benchmark_scheduler \
--hf-model-id gpt2 --device cuda \
--prompt "Hello" --num-requests 256 --max-new-tokens 64 \
--mode online --max-batch-size 256 \
--no-stop-on-eos --no-prefix-cache --pretok \
--warmup-runs 1 --repeat-runs 3 \
--paged-attn --cuda-graph
Before(torch fallback)
ROSELLM_TRITON_KV_APPEND=0 ...
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 0.521872/0.521776 s
Total time p50/mean: 1.224037/1.231840 s
Throughput(completion,decode) p50/mean: 31394.65/31400.72 tokens/s
Throughput(completion,total) p50/mean: 13385.22/13301.57 tokens/s
TTFT p50/mean: 2.72/2.75 ms
TPOT p50/mean: 13.32/13.35 ms/token
Latency p50/mean: 842.00/843.64 ms
After(Triton KV append)
ROSELLM_TRITON_KV_APPEND=1 ...
=== online summary ===
Warmup runs: 1
Measured runs: 3
Decode time p50/mean: 0.524918/0.525336 s
Total time p50/mean: 1.228863/1.226365 s
Throughput(completion,decode) p50/mean: 31212.48/31187.74 tokens/s
Throughput(completion,total) p50/mean: 13332.65/13360.01 tokens/s
TTFT p50/mean: 2.72/2.72 ms
TPOT p50/mean: 13.25/13.25 ms/token
Latency p50/mean: 837.51/837.66 ms
KV 写入 microbench(更容易看出趋势)
为了把“KV 写入”这段从 model.forward() 里拆出来单独看,我做了一个最小 microbench(维度用 GPT-2 的 H=12, D=64, BS=64)。
脚本在 scripts/bench_kv_append.py:
python scripts/bench_kv_append.py --batch-sizes 128,256,512,1024,2048
结果(越大 batch,Triton 越能吃到“少 kernel + 更少中间 tensor”的收益):
B=128: baseline 19.02us, triton 19.01us, speedup 1.001x
B=256: baseline 19.61us, triton 19.10us, speedup 1.027x
B=512: baseline 20.08us, triton 18.74us, speedup 1.071x
B=1024: baseline 29.39us, triton 18.69us, speedup 1.572x
B=2048: baseline 50.91us, triton 18.70us, speedup 2.723x
结论
这一版更像是“把路铺好”:
- fast-path KV 写入有了一个 可控、可回退 的 Triton kernel(环境变量 + batch gate)
- correctness 有单测兜底
从端到端看,收益会被 attention 的计算吞掉很多(所以改动更像是在为后面的 kernel 级联优化做准备);但单看 KV 写入这段,batch 够大时的趋势非常清晰:Triton 更吃得住规模。
下一步继续抠的话:
- 把
idx/blk/pos的构造也做成 buffer 复用(进一步减少每步的小 tensor 分配) - 继续按 shape/stride 做 kernel variant(或者再引入轻量 autotune),让小 batch 也能不亏