从零实现 LLM Training:010. Mixed Precision
我们已经实现了 mini-GPT,较为完整的张量并行,在走其他更复杂的并行之前,我们不妨引入一下混合精度训练。
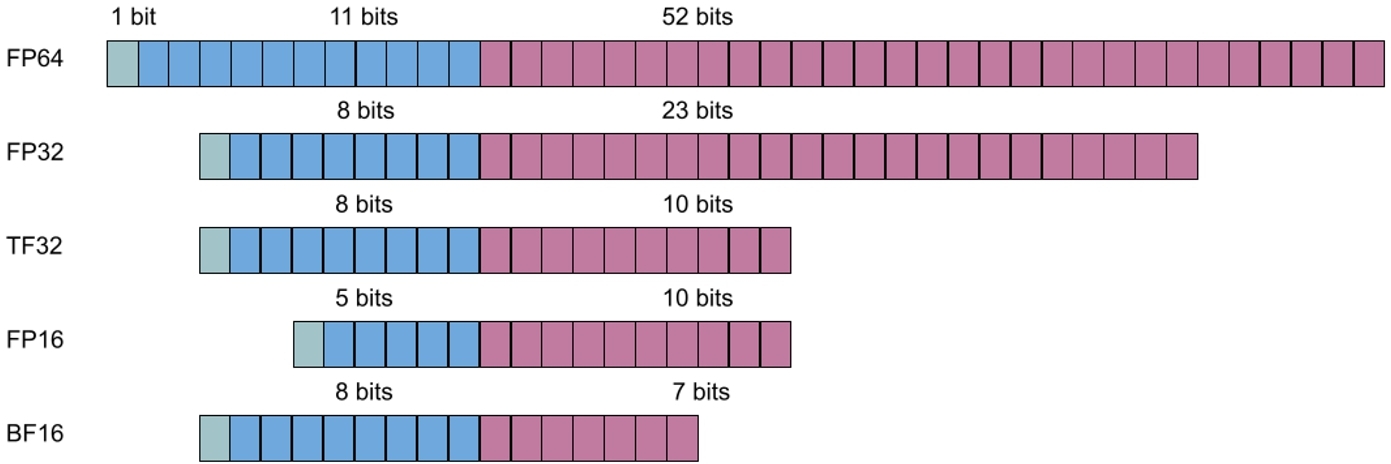
对于一般的情况来说,默认是 FP32 精度的训练,但是为了提高 arithmetic intensity,一般会采用混合精度训练,也就是前向使用 FP16/BF16,在更新 optimizer states 的时候使用 FP32。
常见的精度结构如下:
train_minimal.py
diff --git a/rosellm/rosetrainer/train_minimal.py b/rosellm/rosetrainer/train_minimal.py
index e5800d4..3395fcb 100644
--- a/rosellm/rosetrainer/train_minimal.py
+++ b/rosellm/rosetrainer/train_minimal.py
@@ -1,6 +1,7 @@
import torch
from config import GPTConfig
from model import GPTModel
+from torch.amp import GradScaler, autocast
from torch.utils.data import DataLoader, Dataset
@@ -53,6 +54,8 @@ def main():
shuffle=True,
)
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
+ use_amp = device.type == "cuda"
+ scaler = GradScaler(enabled=use_amp)
model.train()
num_steps = 50
step = 0
@@ -64,15 +67,30 @@ def main():
labels = batch["labels"].to(device)
attention_mask = batch["attention_mask"].to(device)
optimizer.zero_grad()
- logits, loss = model(
- input_ids=input_ids,
- attention_mask=attention_mask,
- labels=labels,
- )
- loss.backward()
- optimizer.step()
+ if use_amp:
+ with autocast(device_type=device.type):
+ logits, loss = model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )
+ scaler.scale(loss).backward()
+ scaler.step(optimizer)
+ scaler.update()
+ else:
+ logits, loss = model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )
+ loss.backward()
+ optimizer.step()
if step % 10 == 0:
- print(f"step {step} / {num_steps} | loss: {loss.item():.4f}")
+ print(
+ f"step {step} / {num_steps} ",
+ f"loss: {loss.item():.4f} ",
+ f"amp: {use_amp}",
+ )
其实用法最主要是引入 torch.amp 的 autocast 以及 GradScaler,然后在 optimizer.zero_grad 之后,使用 autocast 来包住前向的过程。反向的时候用 scaler.scale 包住 loss 再做 backward。这里对 loss 缩放主要是为了避免 FP16 梯度下溢。
train_ddp.py
diff --git a/rosellm/rosetrainer/train_ddp.py b/rosellm/rosetrainer/train_ddp.py
index c821f43..506c135 100644
--- a/rosellm/rosetrainer/train_ddp.py
+++ b/rosellm/rosetrainer/train_ddp.py
@@ -4,6 +4,7 @@ import torch
import torch.distributed as dist
from config import GPTConfig
from model import GPTModel
+from torch.amp import GradScaler, autocast
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset, DistributedSampler
@@ -86,6 +87,8 @@ def main():
sampler=sampler,
)
optimizer = torch.optim.AdamW(ddp_model.parameters(), lr=3e-4)
+ use_amp = device.type == "cuda"
+ scaler = GradScaler(enabled=use_amp)
ddp_model.train()
num_steps = 50
step = 0
@@ -99,15 +102,30 @@ def main():
labels = batch["labels"].to(device) # [B, T]
attention_mask = batch["attention_mask"].to(device) # [B, T]
optimizer.zero_grad()
- logits, loss = ddp_model(
- input_ids=input_ids,
- attention_mask=attention_mask,
- labels=labels,
- )
- loss.backward()
- optimizer.step()
+ if use_amp:
+ with autocast(device_type=device.type):
+ logits, loss = ddp_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )
+ scaler.scale(loss).backward()
+ scaler.step(optimizer)
+ scaler.update()
+ else:
+ logits, loss = ddp_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )
+ loss.backward()
+ optimizer.step()
if is_main_process(local_rank) and step % 10 == 0:
- print(f"[step {step} / {num_steps}] loss = {loss.item():.4f}")
+ print(
+ f"[step {step} / {num_steps}] ",
+ f"loss = {loss.item():.4f} ",
+ f"amp = {use_amp}",
+ )
if step > num_steps:
break
if is_main_process(local_rank):
train_ddp 的修改也比较类似。
运行
$ python train_minimal.py
Using device: cuda
step 10 / 50 loss: 9.3941 amp: True
step 20 / 50 loss: 9.4228 amp: True
step 30 / 50 loss: 9.3186 amp: True
step 40 / 50 loss: 9.3002 amp: True
step 50 / 50 loss: 9.3600 amp: True
$ torchrun --nproc-per-node=2 train_ddp.py
W1127 16:56:36.174000 135233 site-packages/torch/distributed/run.py:792]
W1127 16:56:36.174000 135233 site-packages/torch/distributed/run.py:792] *****************************************
W1127 16:56:36.174000 135233 site-packages/torch/distributed/run.py:792] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W1127 16:56:36.174000 135233 site-packages/torch/distributed/run.py:792] *****************************************
[rank 0] Using device: cuda:0
[step 10 / 50] loss = 9.3852 amp = True
[step 20 / 50] loss = 9.3113 amp = True
[step 30 / 50] loss = 9.3276 amp = True
[step 40 / 50] loss = 9.4181 amp = True
[step 50 / 50] loss = 9.3252 amp = True
Training finished.