从零实现 LLM Training:017. Save Config to Checkpoint
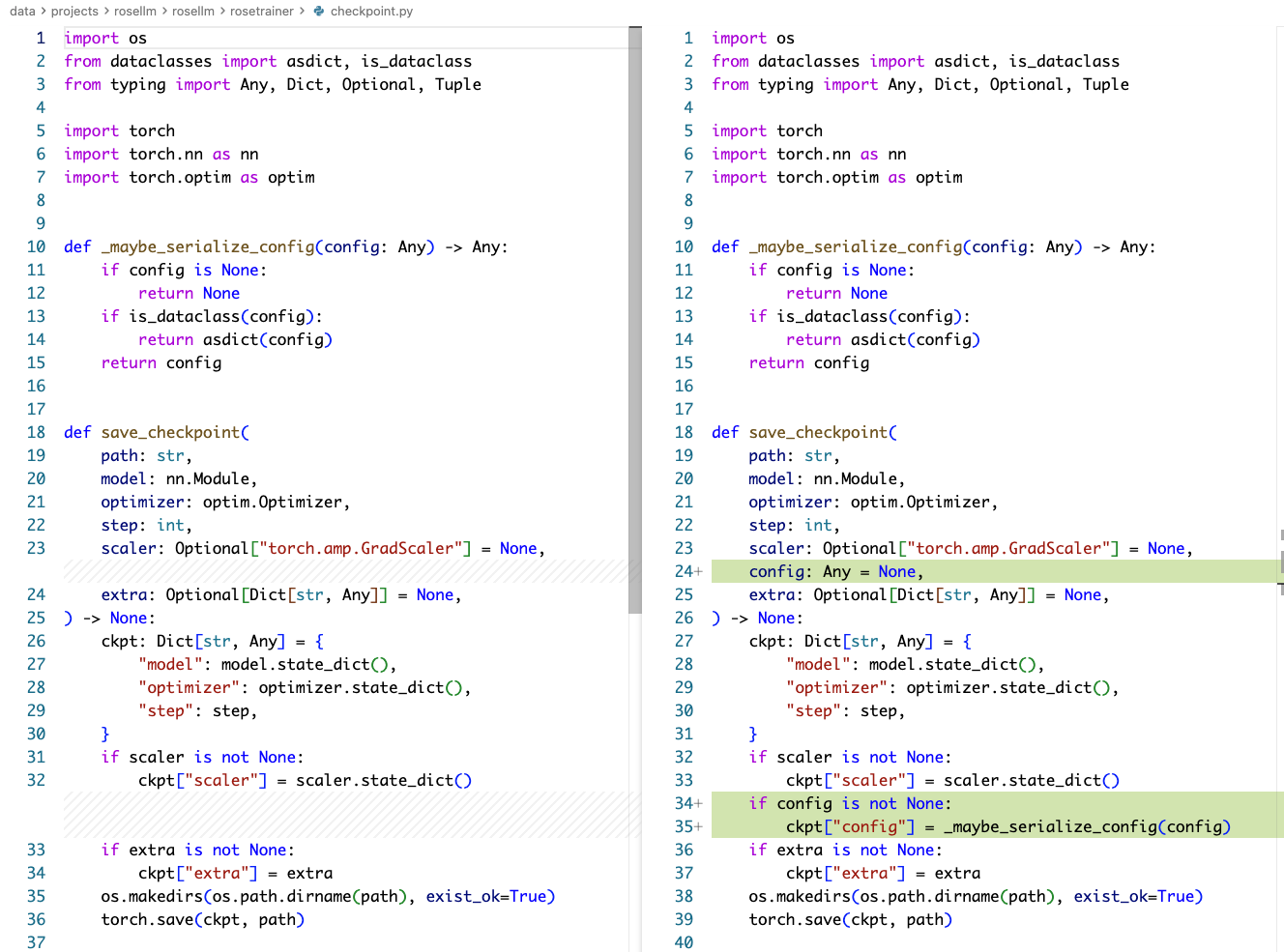
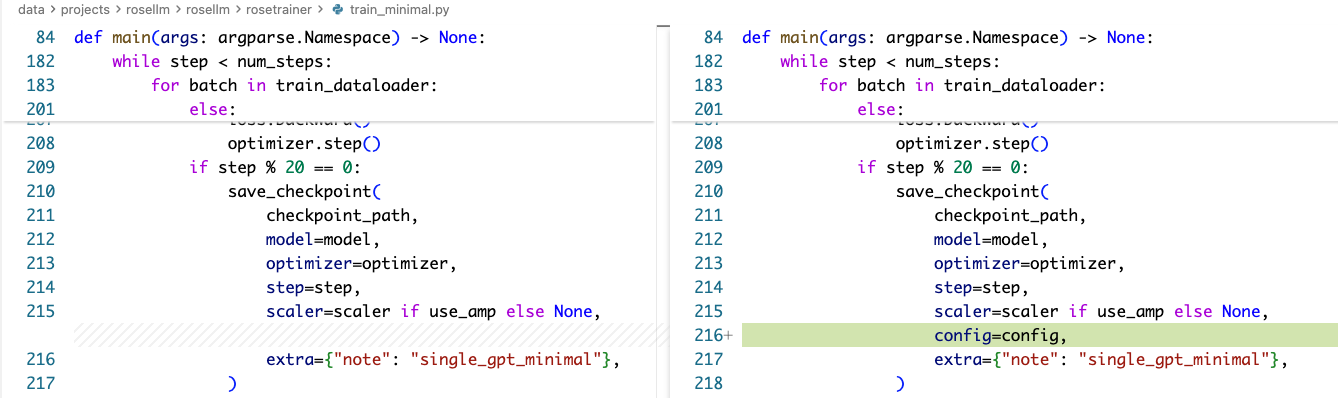
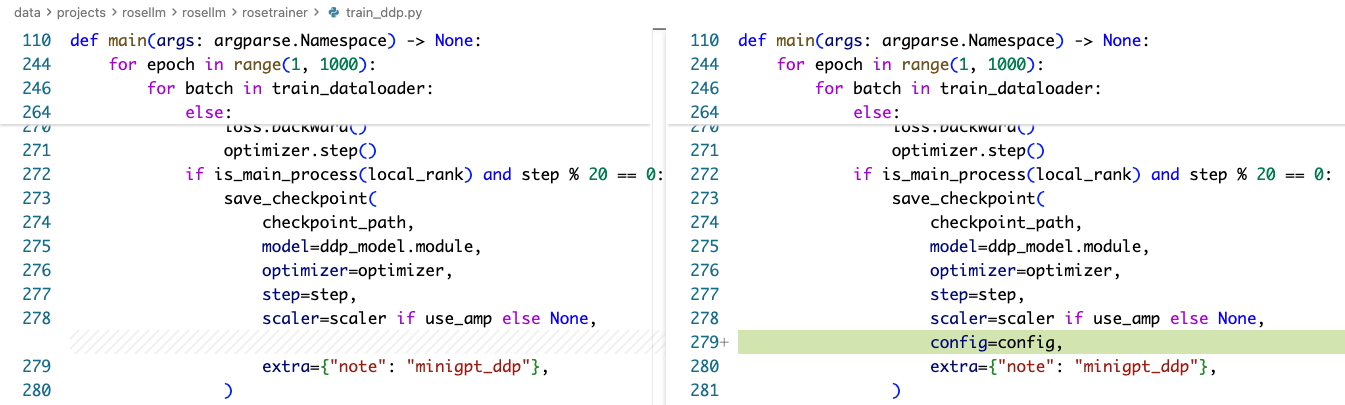
本文这个 PR 解决一些小问题,比如我们之前做简单 generate 的时候,还需要手动指定模型的各种层数等信息,这是非常不合理的,我们在新的 PR 里把 config 保存到 checkpoint 当中,从而加载 checkpoint 的时候可以把模型相关的信息加载出来以进行使用。
checkpont.py
diff 如下:
generate.py

train_minimal.py
train_ddp.py
运行
可以训练一个小模型,然后运行 generate.py 不加任何模型信息试试:
$ python train_minimal.py --train-data data/train.txt
Training started at 2025-11-29 19:02:15
Using device: cuda
Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=2, n_heads=4, d_model=128, d_ff=512, dropout=0.1, use_tensor_parallel=False, batch_size=8, seq_len=32, num_steps=50, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
Token indices sequence length is longer than the specified maximum sequence length for this model (937659 > 1024). Running this sequence through the model will result in indexing errors
total files: 1
total tokens: 937660
train dataset size: 26371
val dataset size: 2930
Starting from scratch
('step 10 / 50 ', 'train loss: 10.7744 ', 'val loss: 10.6844 ', 'val ppl: 43669.8155 ', 'amp: True')
('step 20 / 50 ', 'train loss: 10.3518 ', 'val loss: 10.2473 ', 'val ppl: 28205.1037 ', 'amp: True')
('step 30 / 50 ', 'train loss: 9.5288 ', 'val loss: 9.5297 ', 'val ppl: 13761.9731 ', 'amp: True')
('step 40 / 50 ', 'train loss: 8.7336 ', 'val loss: 8.6702 ', 'val ppl: 5826.8640 ', 'amp: True')
('step 50 / 50 ', 'train loss: 8.0282 ', 'val loss: 7.8578 ', 'val ppl: 2585.8120 ', 'amp: True')
$ python generate.py --checkpoint-path checkpoints/minigpt_single.pt --prompt "你"
Using device: cuda
Found config in checkpoint, ignore cli configs
Loading checkpoint from checkpoints/minigpt_single.pt...
Prompt: 你
Generated text: 你,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,�