从零实现 LLM Training:019. Activation Checkpoint
在做了各种基础训练以及相关展示,我们来做一些优化,第一个引入的优化叫做 activation checkpointing,也就是在前向的时候只保留部分的 activation (而非全部保留),然后在反向的时候对需要的 activation 进行重新计算。
model.py

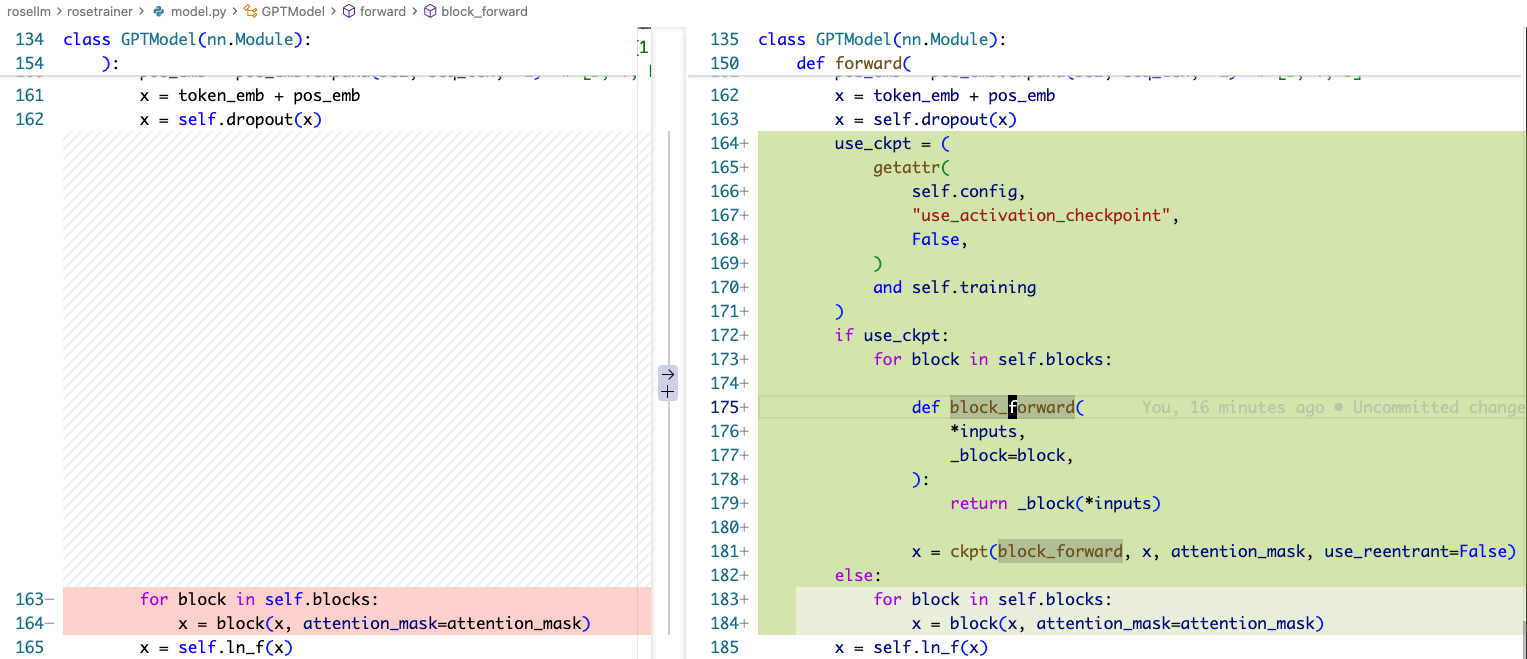
这里基本上就是在用 torch.utils.checkpoint.checkpoint,在 block 的边界做包装,这里面使用了 block_forward 来通过 _block=block 做一个 capture,防止 block 本身在 for loop 中是一直变化的。
其他文件的变更就是加了一个 –use-activation-checkpoint 的 flag 等。
运行
train_simple.py
不开启 activation checkpointing:
$ python train_minimal.py --train-data data/train.txt --num-steps 10000 --n-layers 12 --d-model 768 --d-ff 3072 --n-heads 12 --seq-len 1024 --batch-size 2
[2025-11-30 10:24:58] Training started at 2025-11-30 10:24:58
[2025-11-30 10:24:58] Using device: cuda
[2025-11-30 10:24:58] Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=12, n_heads=12, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=10000, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
[2025-11-30 10:25:02] train dataset size: 824
[2025-11-30 10:25:02] val dataset size: 91
[2025-11-30 10:25:02] steps per epoch: 412
[2025-11-30 10:25:02] Starting from scratch
[2025-11-30 10:25:06] ('epoch 1 step 10 / 10000 ', 'lr: 0.000033 ', 'train loss: 10.0797 ', 'val loss: 9.8353 ', 'val ppl: 18681.7775 ', 'dt: 3.66s ', 'eta: 1.01h ', 'amp: True')
[2025-11-30 10:25:11] ('epoch 1 step 20 / 10000 ', 'lr: 0.000063 ', 'train loss: 8.5636 ', 'val loss: 8.4516 ', 'val ppl: 4682.4463 ', 'dt: 5.13s ', 'eta: 1.22h ', 'amp: True')
[2025-11-30 10:25:15] ('epoch 1 step 30 / 10000 ', 'lr: 0.000093 ', 'train loss: 7.3873 ', 'val loss: 7.2671 ', 'val ppl: 1432.3660 ', 'dt: 3.53s ', 'eta: 1.14h ', 'amp: True')
[2025-11-30 10:25:20] ('epoch 1 step 40 / 10000 ', 'lr: 0.000123 ', 'train loss: 6.0626 ', 'val loss: 5.9116 ', 'val ppl: 369.3091 ', 'dt: 5.23s ', 'eta: 1.21h ', 'amp: True')
[2025-11-30 10:25:24] ('epoch 1 step 50 / 10000 ', 'lr: 0.000153 ', 'train loss: 4.9254 ', 'val loss: 4.7544 ', 'val ppl: 116.0889 ', 'dt: 3.54s ', 'eta: 1.17h ', 'amp: True')
[2025-11-30 10:25:29] ('epoch 1 step 60 / 10000 ', 'lr: 0.000183 ', 'train loss: 4.5156 ', 'val loss: 4.1646 ', 'val ppl: 64.3694 ', 'dt: 5.19s ', 'eta: 1.21h ', 'amp: True')
[2025-11-30 10:25:32] ('epoch 1 step 70 / 10000 ', 'lr: 0.000213 ', 'train loss: 4.0291 ', 'val loss: 3.8643 ', 'val ppl: 47.6683 ', 'dt: 3.53s ', 'eta: 1.18h ', 'amp: True')
[2025-11-30 10:25:38] ('epoch 1 step 80 / 10000 ', 'lr: 0.000243 ', 'train loss: 3.6807 ', 'val loss: 3.6837 ', 'val ppl: 39.7934 ', 'dt: 5.29s ', 'eta: 1.21h ', 'amp: True')
[2025-11-30 10:25:41] ('epoch 1 step 90 / 10000 ', 'lr: 0.000273 ', 'train loss: 3.5640 ', 'val loss: 3.6143 ', 'val ppl: 37.1259 ', 'dt: 3.53s ', 'eta: 1.18h ', 'amp: True')

GPU 显存占用 94.3%
开启 activation checkpointing:
$ python train_minimal.py --train-data data/train.txt --num-steps 10000 --n-layers 12 --d-model 768 --d-ff 3072 --n-heads 12 --seq-len 1024 --batch-size 2 --use-activation-checkpoint
[2025-11-30 10:22:50] Training started at 2025-11-30 10:22:50
[2025-11-30 10:22:50] Using device: cuda
[2025-11-30 10:22:50] Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=12, n_heads=12, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=True, batch_size=2, seq_len=1024, num_steps=10000, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
[2025-11-30 10:22:54] train dataset size: 824
[2025-11-30 10:22:54] val dataset size: 91
[2025-11-30 10:22:54] steps per epoch: 412
[2025-11-30 10:22:54] Starting from scratch
[2025-11-30 10:22:58] ('epoch 1 step 10 / 10000 ', 'lr: 0.000033 ', 'train loss: 10.0108 ', 'val loss: 9.7064 ', 'val ppl: 16421.8628 ', 'dt: 4.06s ', 'eta: 1.13h ', 'amp: True')
[2025-11-30 10:23:04] ('epoch 1 step 20 / 10000 ', 'lr: 0.000063 ', 'train loss: 8.3834 ', 'val loss: 8.3826 ', 'val ppl: 4370.1515 ', 'dt: 5.62s ', 'eta: 1.34h ', 'amp: True')
[2025-11-30 10:23:08] ('epoch 1 step 30 / 10000 ', 'lr: 0.000093 ', 'train loss: 7.5428 ', 'val loss: 7.2707 ', 'val ppl: 1437.5362 ', 'dt: 3.94s ', 'eta: 1.26h ', 'amp: True')
[2025-11-30 10:23:13] ('epoch 1 step 40 / 10000 ', 'lr: 0.000123 ', 'train loss: 6.0176 ', 'val loss: 5.9504 ', 'val ppl: 383.8992 ', 'dt: 5.64s ', 'eta: 1.33h ', 'amp: True')
[2025-11-30 10:23:17] ('epoch 1 step 50 / 10000 ', 'lr: 0.000153 ', 'train loss: 5.1677 ', 'val loss: 4.7937 ', 'val ppl: 120.7478 ', 'dt: 3.94s ', 'eta: 1.28h ', 'amp: True')
[2025-11-30 10:23:23] ('epoch 1 step 60 / 10000 ', 'lr: 0.000183 ', 'train loss: 4.3969 ', 'val loss: 4.1694 ', 'val ppl: 64.6741 ', 'dt: 5.67s ', 'eta: 1.33h ', 'amp: True')
[2025-11-30 10:23:27] ('epoch 1 step 70 / 10000 ', 'lr: 0.000213 ', 'train loss: 3.8108 ', 'val loss: 3.8615 ', 'val ppl: 47.5374 ', 'dt: 3.94s ', 'eta: 1.29h ', 'amp: True')
[2025-11-30 10:23:32] ('epoch 1 step 80 / 10000 ', 'lr: 0.000243 ', 'train loss: 3.5393 ', 'val loss: 3.7169 ', 'val ppl: 41.1351 ', 'dt: 5.61s ', 'eta: 1.32h ', 'amp: True')
[2025-11-30 10:23:36] ('epoch 1 step 90 / 10000 ', 'lr: 0.000273 ', 'train loss: 3.7082 ', 'val loss: 3.6183 ', 'val ppl: 37.2728 ', 'dt: 3.94s ', 'eta: 1.30h ', 'amp: True')

GPU 显存占用 79.4%
train_ddp.py
不开启 checkpointing:
$ torchrun --nproc-per-node=2 train_ddp.py --train-data data/train.txt --num-steps 10000 --n-layers 12 --d-model 768 --d-ff 3072 --dropout 0.1 --max-position-embeddings 1024 --n-heads 12 --seq-len 1024 --batch-size 2
W1130 10:28:57.824000 2940378 site-packages/torch/distributed/run.py:792]
W1130 10:28:57.824000 2940378 site-packages/torch/distributed/run.py:792] *****************************************
W1130 10:28:57.824000 2940378 site-packages/torch/distributed/run.py:792] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W1130 10:28:57.824000 2940378 site-packages/torch/distributed/run.py:792] *****************************************
[2025-11-30 10:28:59] Training started at 2025-11-30 10:28:59
[2025-11-30 10:28:59] [rank 0] Using device: cuda:0
[2025-11-30 10:28:59] Arguments: Namespace(vocab_size=10000, max_position_embeddings=1024, n_layers=12, n_heads=12, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=10000, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_ddp.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, train_data=['data/train.txt'], val_data=[], val_ratio=0.1, tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
total files: 1
total tokens: 937660
[2025-11-30 10:29:01] train dataset size: 824
[2025-11-30 10:29:01] val dataset size: 91
[2025-11-30 10:29:01] steps per epoch: 206
[2025-11-30 10:29:01] [rank 0] Starting from scratch
[2025-11-30 10:29:06] ('epoch 1 step 10 / 10000 ', 'lr: 0.000033 ', 'train loss: 10.1096 ', 'val loss: 9.7510 ', 'val ppl: 17170.9173 ', 'dt: 4.11s ', 'eta: 1.14h ', 'amp: True')
[2025-11-30 10:29:11] ('epoch 1 step 20 / 10000 ', 'lr: 0.000063 ', 'train loss: 8.5313 ', 'val loss: 8.3864 ', 'val ppl: 4386.8414 ', 'dt: 5.06s ', 'eta: 1.27h ', 'amp: True')
[2025-11-30 10:29:14] ('epoch 1 step 30 / 10000 ', 'lr: 0.000093 ', 'train loss: 7.3367 ', 'val loss: 7.2178 ', 'val ppl: 1363.4612 ', 'dt: 3.89s ', 'eta: 1.21h ', 'amp: True')
[2025-11-30 10:29:20] ('epoch 1 step 40 / 10000 ', 'lr: 0.000123 ', 'train loss: 5.9865 ', 'val loss: 5.8378 ', 'val ppl: 343.0253 ', 'dt: 5.50s ', 'eta: 1.28h ', 'amp: True')
[2025-11-30 10:29:24] ('epoch 1 step 50 / 10000 ', 'lr: 0.000153 ', 'train loss: 4.6464 ', 'val loss: 4.6489 ', 'val ppl: 104.4671 ', 'dt: 3.95s ', 'eta: 1.24h ', 'amp: True')
[2025-11-30 10:29:29] ('epoch 1 step 60 / 10000 ', 'lr: 0.000183 ', 'train loss: 4.1313 ', 'val loss: 4.0531 ', 'val ppl: 57.5737 ', 'dt: 5.48s ', 'eta: 1.29h ', 'amp: True')
[2025-11-30 10:29:33] ('epoch 1 step 70 / 10000 ', 'lr: 0.000213 ', 'train loss: 3.8909 ', 'val loss: 3.7790 ', 'val ppl: 43.7723 ', 'dt: 3.89s ', 'eta: 1.26h ', 'amp: True')
[2025-11-30 10:29:39] ('epoch 1 step 80 / 10000 ', 'lr: 0.000243 ', 'train loss: 3.6793 ', 'val loss: 3.6212 ', 'val ppl: 37.3833 ', 'dt: 5.52s ', 'eta: 1.29h ', 'amp: True')
[2025-11-30 10:29:43] ('epoch 1 step 90 / 10000 ', 'lr: 0.000273 ', 'train loss: 3.6830 ', 'val loss: 3.5479 ', 'val ppl: 34.7392 ', 'dt: 3.89s ', 'eta: 1.26h ', 'amp: True')
[2025-11-30 10:29:48] ('epoch 1 step 100 / 10000 ', 'lr: 0.000300 ', 'train loss: 3.3407 ', 'val loss: 3.4929 ', 'val ppl: 32.8801 ', 'dt: 5.49s ', 'eta: 1.29h ', 'amp: True')
[2025-11-30 10:29:52] ('epoch 1 step 110 / 10000 ', 'lr: 0.000300 ', 'train loss: 3.5314 ', 'val loss: 3.4410 ', 'val ppl: 31.2172 ', 'dt: 3.89s ', 'eta: 1.27h ', 'amp: True')
[2025-11-30 10:29:58] ('epoch 1 step 120 / 10000 ', 'lr: 0.000300 ', 'train loss: 3.5555 ', 'val loss: 3.4070 ', 'val ppl: 30.1744 ', 'dt: 5.49s ', 'eta: 1.28h ', 'amp: True')
[2025-11-30 10:30:01] ('epoch 1 step 130 / 10000 ', 'lr: 0.000300 ', 'train loss: 3.4595 ', 'val loss: 3.3724 ', 'val ppl: 29.1471 ', 'dt: 3.90s ', 'eta: 1.27h ', 'amp: True')

GPU 显存占用约 65%
开启 checkpointing:
$ torchrun --nproc-per-node=2 train_ddp.py --train-data data/train.txt --num-steps 10000 --n-layers 12 --d-model 768 --d-ff 3072 --dropout 0.1 --max-position-embeddings 1024 --n-heads 12 --seq-len 1024 --batch-size 2 --use-activation-checkpoint
W1130 10:30:57.455000 2943656 site-packages/torch/distributed/run.py:792]
W1130 10:30:57.455000 2943656 site-packages/torch/distributed/run.py:792] *****************************************
W1130 10:30:57.455000 2943656 site-packages/torch/distributed/run.py:792] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W1130 10:30:57.455000 2943656 site-packages/torch/distributed/run.py:792] *****************************************
[2025-11-30 10:30:58] Training started at 2025-11-30 10:30:58
[2025-11-30 10:30:58] [rank 0] Using device: cuda:0
[2025-11-30 10:30:58] Arguments: Namespace(vocab_size=10000, max_position_embeddings=1024, n_layers=12, n_heads=12, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=True, batch_size=2, seq_len=1024, num_steps=10000, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_ddp.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, train_data=['data/train.txt'], val_data=[], val_ratio=0.1, tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
total files: 1
total tokens: 937660
[2025-11-30 10:31:01] train dataset size: 824
[2025-11-30 10:31:01] val dataset size: 91
[2025-11-30 10:31:01] steps per epoch: 206
[2025-11-30 10:31:01] [rank 0] Starting from scratch
[2025-11-30 10:31:05] ('epoch 1 step 10 / 10000 ', 'lr: 0.000033 ', 'train loss: 10.0178 ', 'val loss: 9.6943 ', 'val ppl: 16225.2376 ', 'dt: 4.28s ', 'eta: 1.19h ', 'amp: True')
[2025-11-30 10:31:11] ('epoch 1 step 20 / 10000 ', 'lr: 0.000063 ', 'train loss: 8.4570 ', 'val loss: 8.3009 ', 'val ppl: 4027.5516 ', 'dt: 5.62s ', 'eta: 1.37h ', 'amp: True')
[2025-11-30 10:31:15] ('epoch 1 step 30 / 10000 ', 'lr: 0.000093 ', 'train loss: 7.3090 ', 'val loss: 7.1587 ', 'val ppl: 1285.2313 ', 'dt: 4.02s ', 'eta: 1.28h ', 'amp: True')
[2025-11-30 10:31:21] ('epoch 1 step 40 / 10000 ', 'lr: 0.000123 ', 'train loss: 5.9710 ', 'val loss: 5.7992 ', 'val ppl: 330.0249 ', 'dt: 5.61s ', 'eta: 1.35h ', 'amp: True')
[2025-11-30 10:31:25] ('epoch 1 step 50 / 10000 ', 'lr: 0.000153 ', 'train loss: 4.7316 ', 'val loss: 4.6642 ', 'val ppl: 106.0796 ', 'dt: 4.06s ', 'eta: 1.30h ', 'amp: True')
[2025-11-30 10:31:30] ('epoch 1 step 60 / 10000 ', 'lr: 0.000183 ', 'train loss: 4.2041 ', 'val loss: 4.0654 ', 'val ppl: 58.2871 ', 'dt: 5.65s ', 'eta: 1.35h ', 'amp: True')

GPU 显存占用约 46%,相较于 65% 减少了 ~29%