从零实现 LLM Training:020. PyTorch Profiler and NVTX
在实现了基础的模型训练,以及 activation checkpointing 之后,我们通过日志以及 nvidia-smi 可以大概看出来开了一些功能之后,耗时以及显存的变化,但是对整个程序运行的认知其实还不够彻底,此时我们需要引入 pytorch profiler 以及 nvtx 等工具来捕捉 trace,以更好地理解程序的行为。
代码变更
主要就是用 pytorch profiler 给代码里面加各种包装,nvtx 也可以用,但是需要 nsight system/compute 看,本文暂时只涉及 pytorch profiler
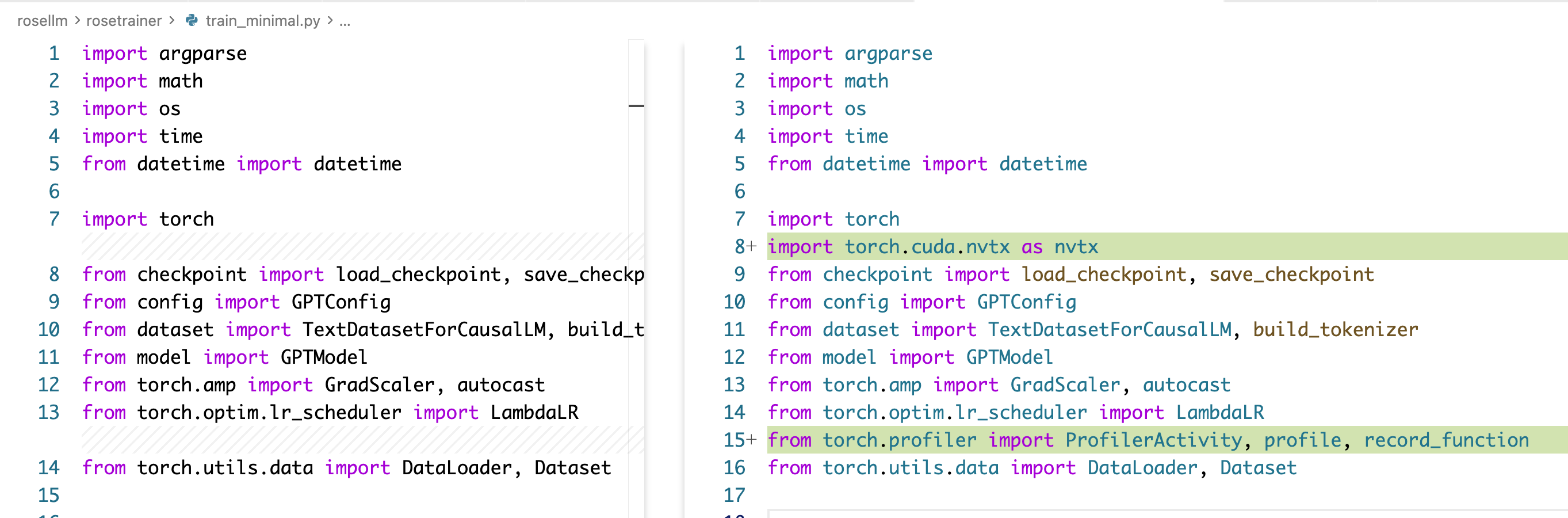
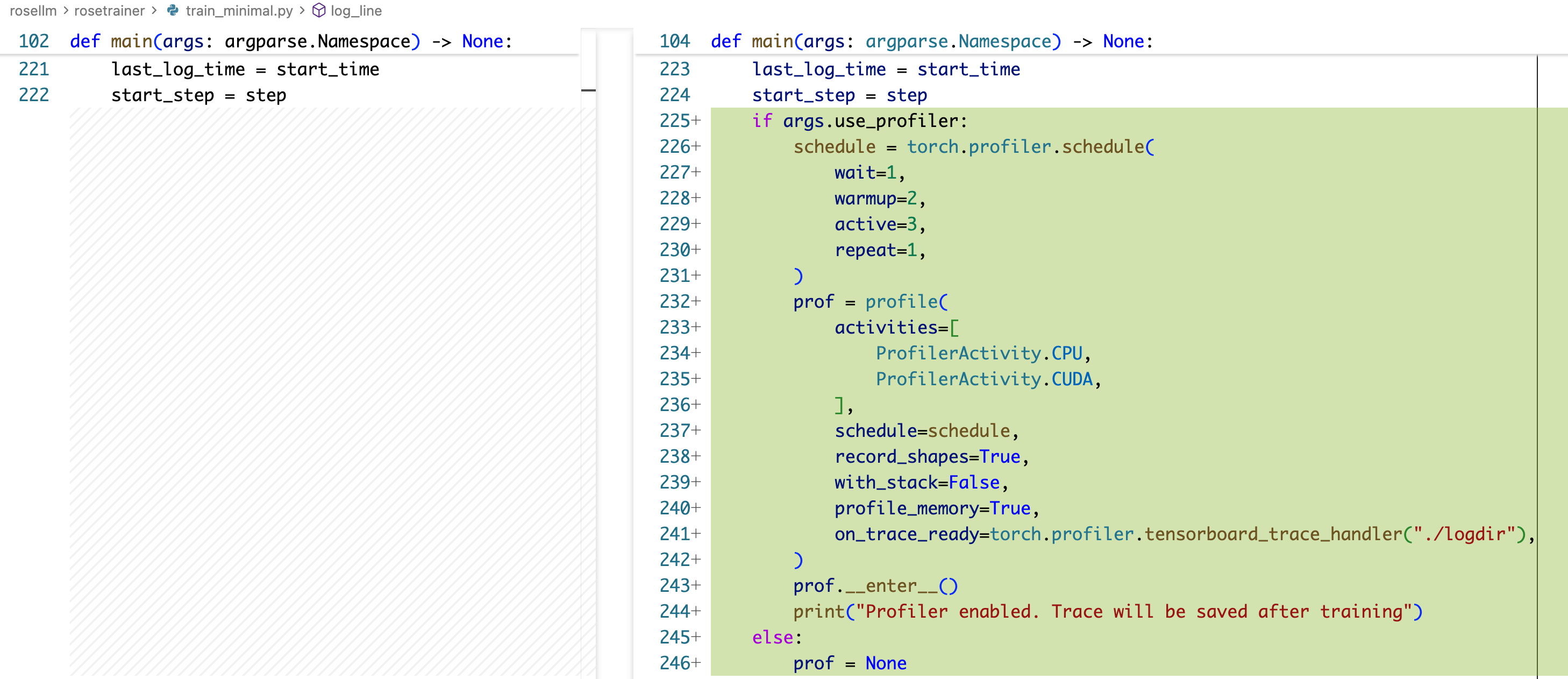

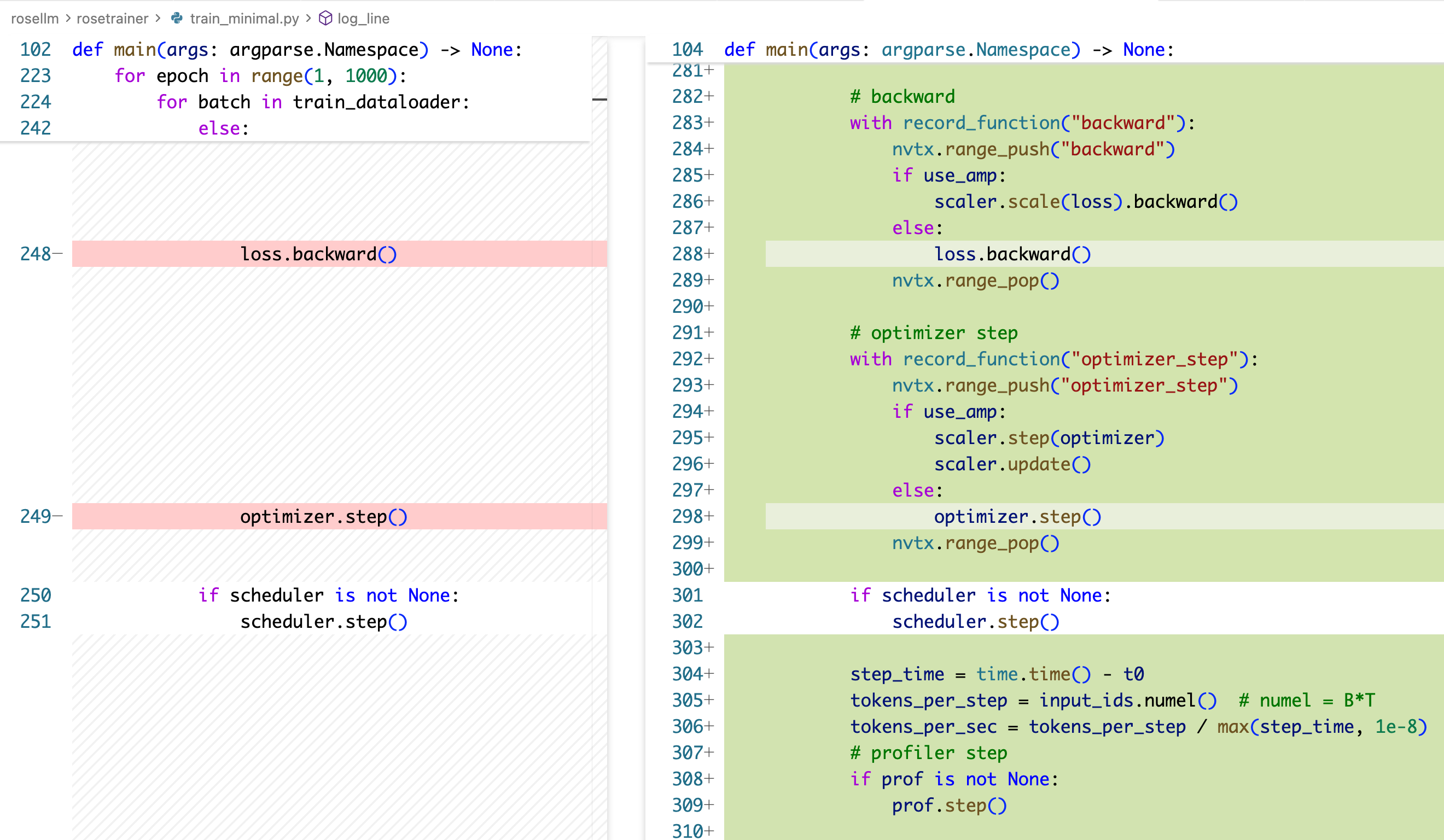
本质上就是初始化一下 torch.profiler.schedule,创建一个 profile,然后用 record_function 去把要研究的地方包一下,nvtx.range_push/pop 也是类似的操作,我们之后就会用到了。
下面我们来看看 profile 解读,对比一下 AMP 以及 activation checkpointing 的效果。
profile 对比
开启 AMP vs 不开启 AMP
先看 profiler step 的时间:
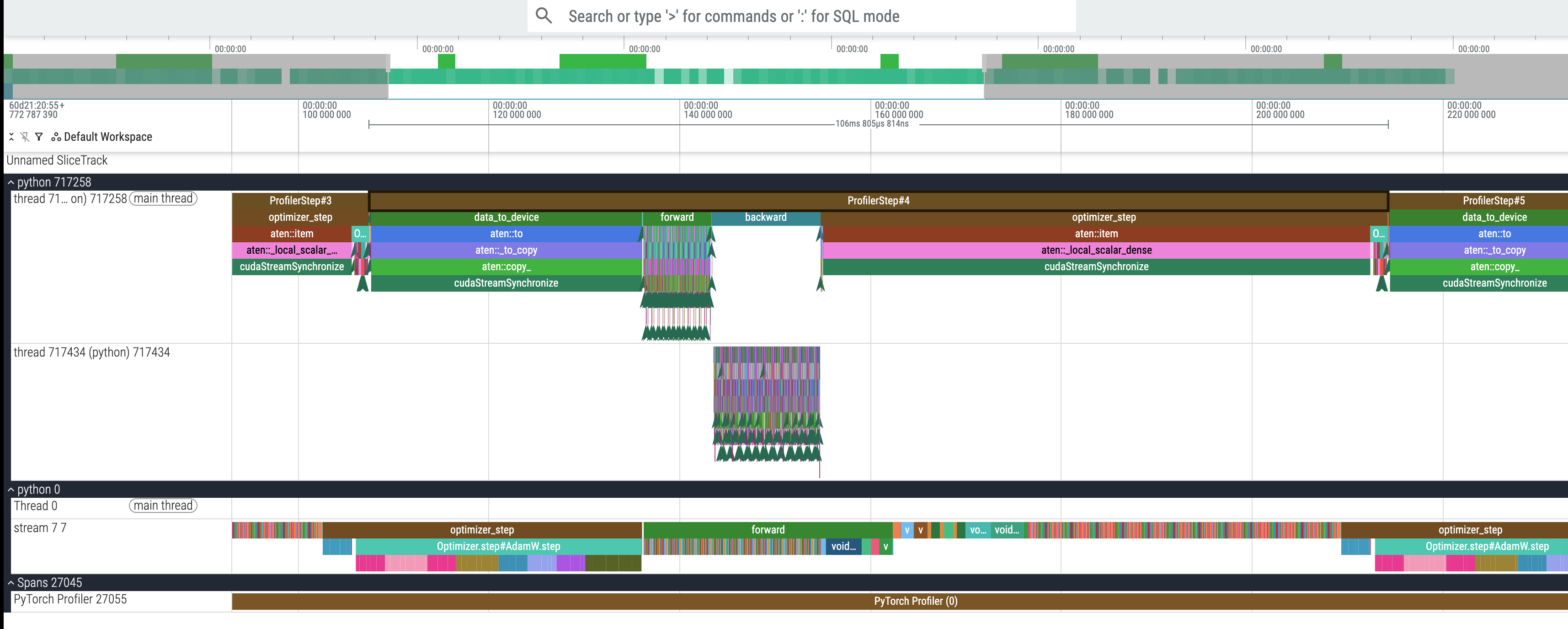
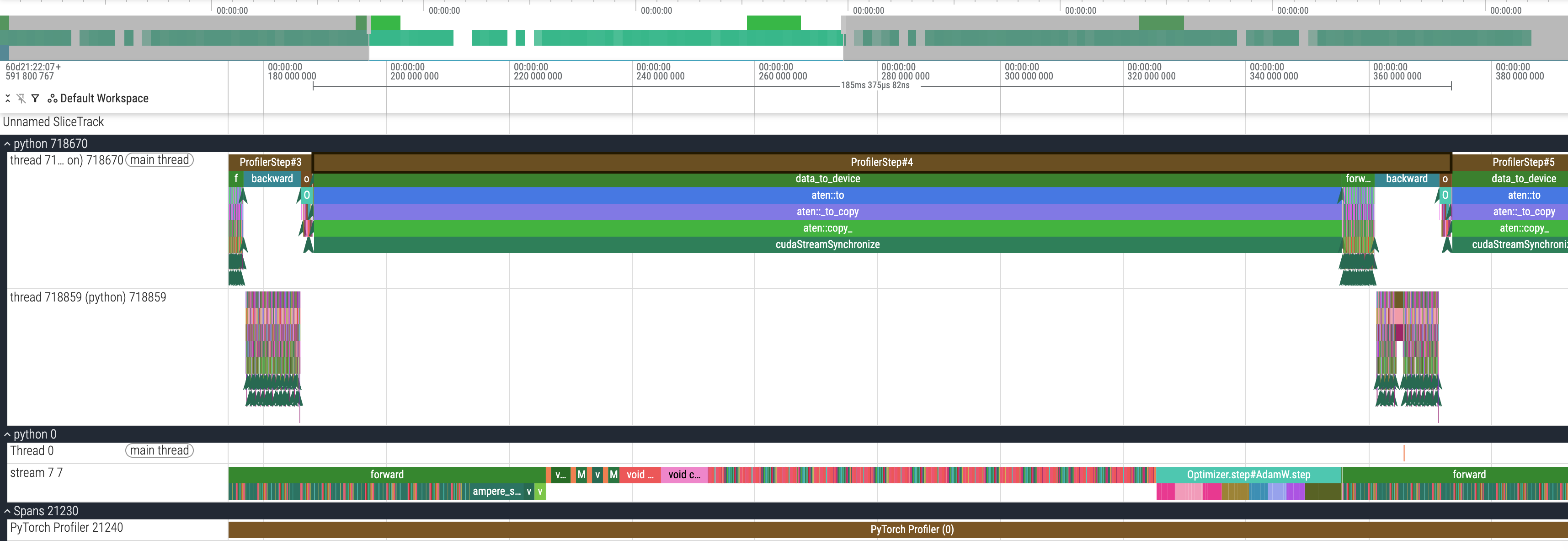
开启的时候是 106ms,不开启的时候是 185ms,开启比不开启快了 42%!
然后我们可以实际去看一下之前我们标注的四个阶段:data_to_device, forward, backward, optimizer_step 在 CPU 上的具体时间对比,可以看到:
| data_to_device | forward | backward | optimizer_step | |
|---|---|---|---|---|
| 使用 AMP | 28ms | 7ms | 11ms | 59ms |
| 不使用 AMP | 167ms | 5ms | 10ms | 1ms |
震惊,怎么看上去 AMP 的前向反向反而时间更长,而 data_to_device 的时间更短了?这是怎么回事?
这里其实是因为 CPU 部分的标签并没有反映真实的时间开销,所有的 GPU cuda kernel 是异步执行的,只有在 cudaStreamSynchronize 的时候才会有显式同步,而这样的显式同步点恰好出现在——没错,出现在 data_to_device 这里,所以我们脑子里可以想这样一件事情,CPU 把前向反向以及 step 的任务依次异步提交给 GPU 去执行,GPU 收到这些任务也是依次执行,然后 CPU 在 data_to_device 的时候有一个 synchronize 操作来等待之前发出的所有 GPU 操作的完成,而没有开 AMP 的时候,他的实际 GPU 执行的前向反向以及 step 耗时较长,所以反映到 data_to_device 那里 synchronize 等了非常长的时间。
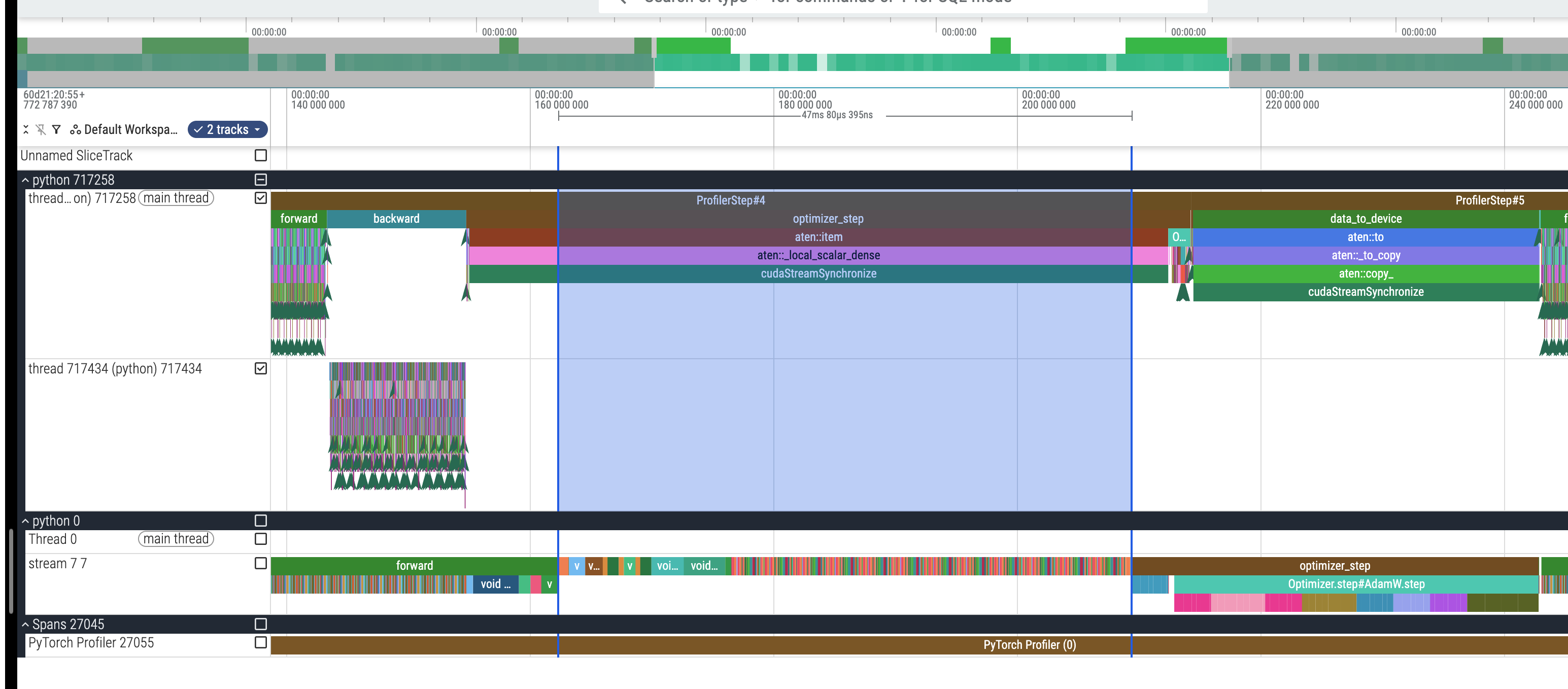
那么各个阶段真实的 GPU 时间呢?我们需要看下面的 python 0 Thread 0 stream 7 7 那里:

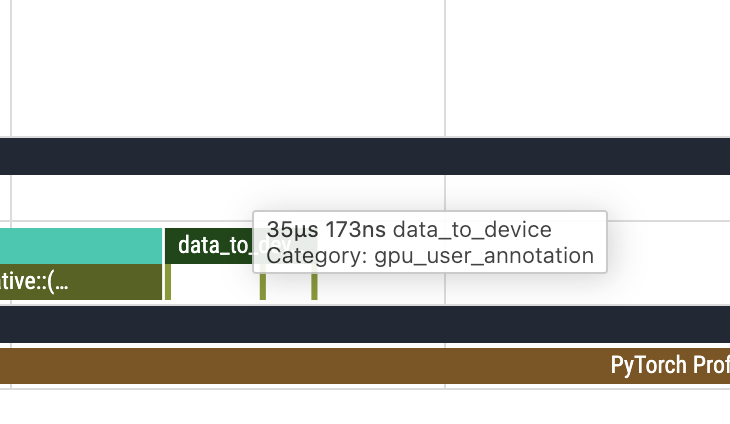
比如我们可以看到,这里的 forward 实际上是 26ms,那么我们重新记录下所有数据(完整数据截图见附录):
| (GPU 时间) | data_to_device | forward | backward | optimizer_step |
|---|---|---|---|---|
| 使用 AMP | 34us | 26ms | 47ms | 33ms |
| 不使用 AMP | 35us | 54ms | 97ms | 30ms |
我们可以看出实际上 data_to_device 的耗时其实挺少的,然后不使用 AMP 的时候,前向反向的时间基本上翻了一倍,而 optimizer step 的时间则是大差不差(“Optimizer 这部分主要是对参数做 elementwise 更新,算术强度不高、内存访问占主导,所以 AMP 在这里提升有限。),接下来我们可以再从 trace 图里面看看 AMP 是用了什么 cuda kernel 来加速的。
我们不妨以 FFN 的第一个 linear layer 来看看对应的 cuda kernel:
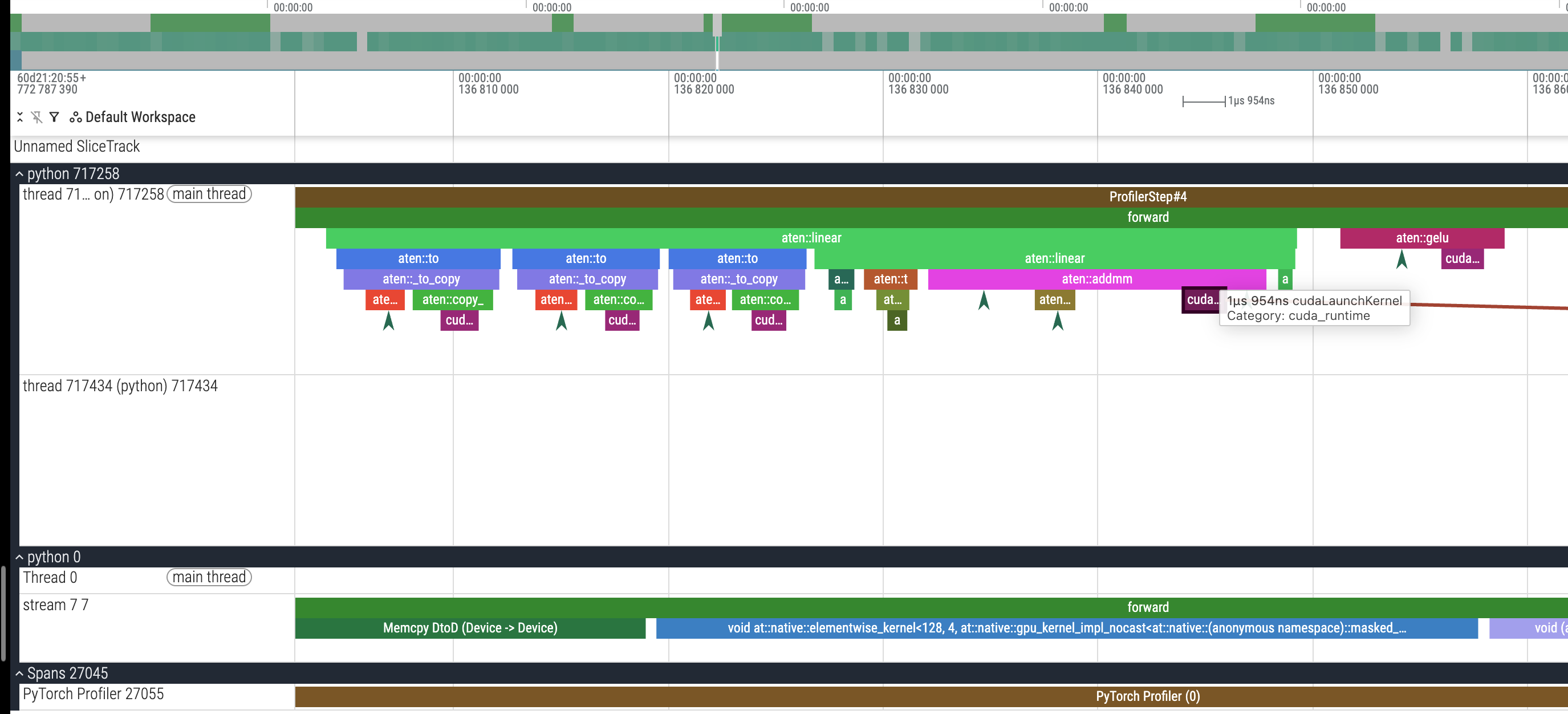
我们可以看到实际的链路是 aten::linear => aten::addmm => cudaLaunchKernel,其中 addmm 的全称就是 add + matrix multiply,我们可以看到 cudaLaunchKernel 有一个飞线在往后指,实际上这里最后就是指到了 stream 7 7 那一行的某一个 cuda kernel 上,我们顺着看一看:
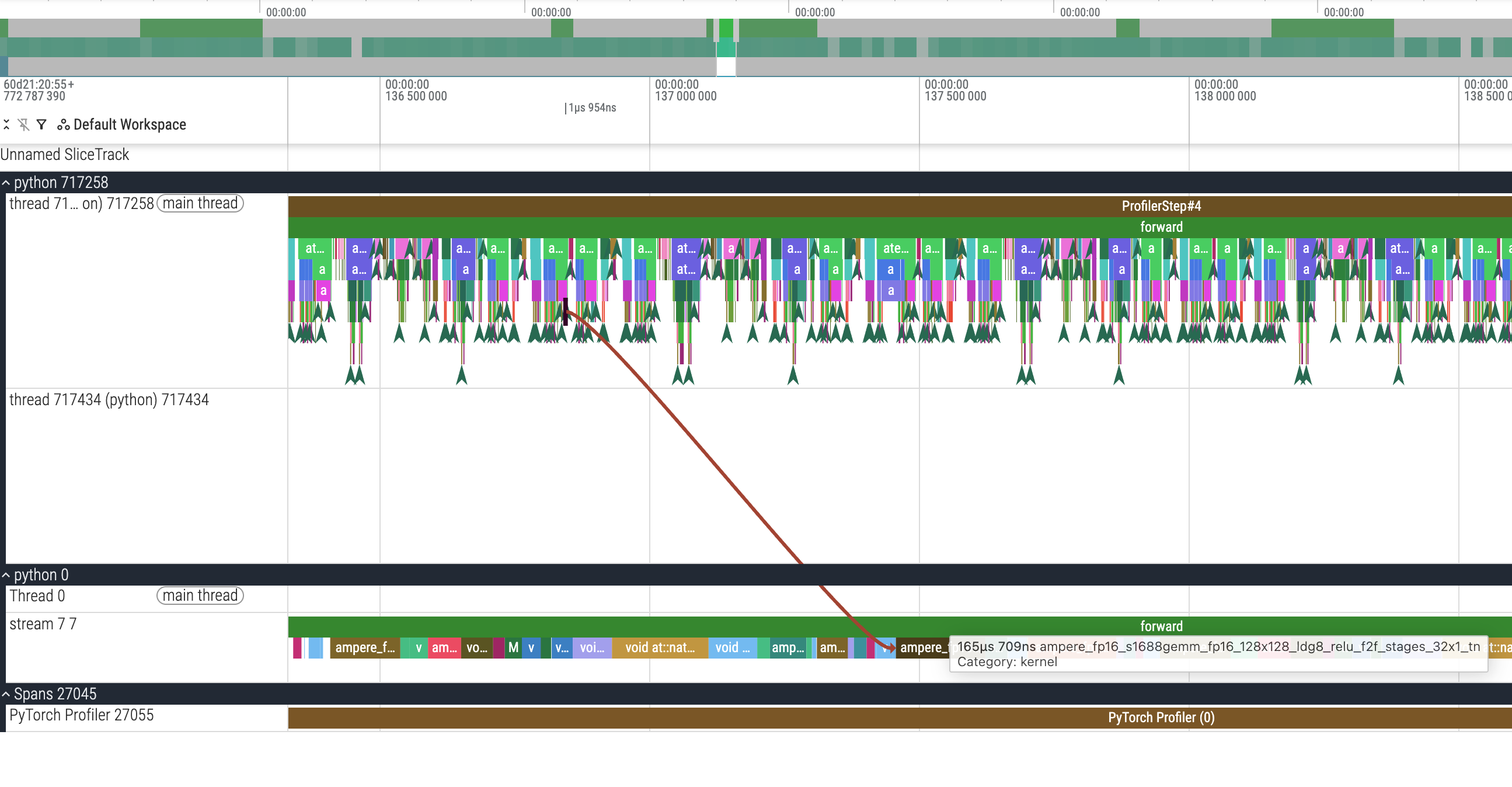
他的名字是 ampere_fp16_s1688gemm_fp16_128x128_ldg8_relu_f2f_stages_32x1_tn,对应 165us,然后我们也对应看一下没有开启 AMP 的:
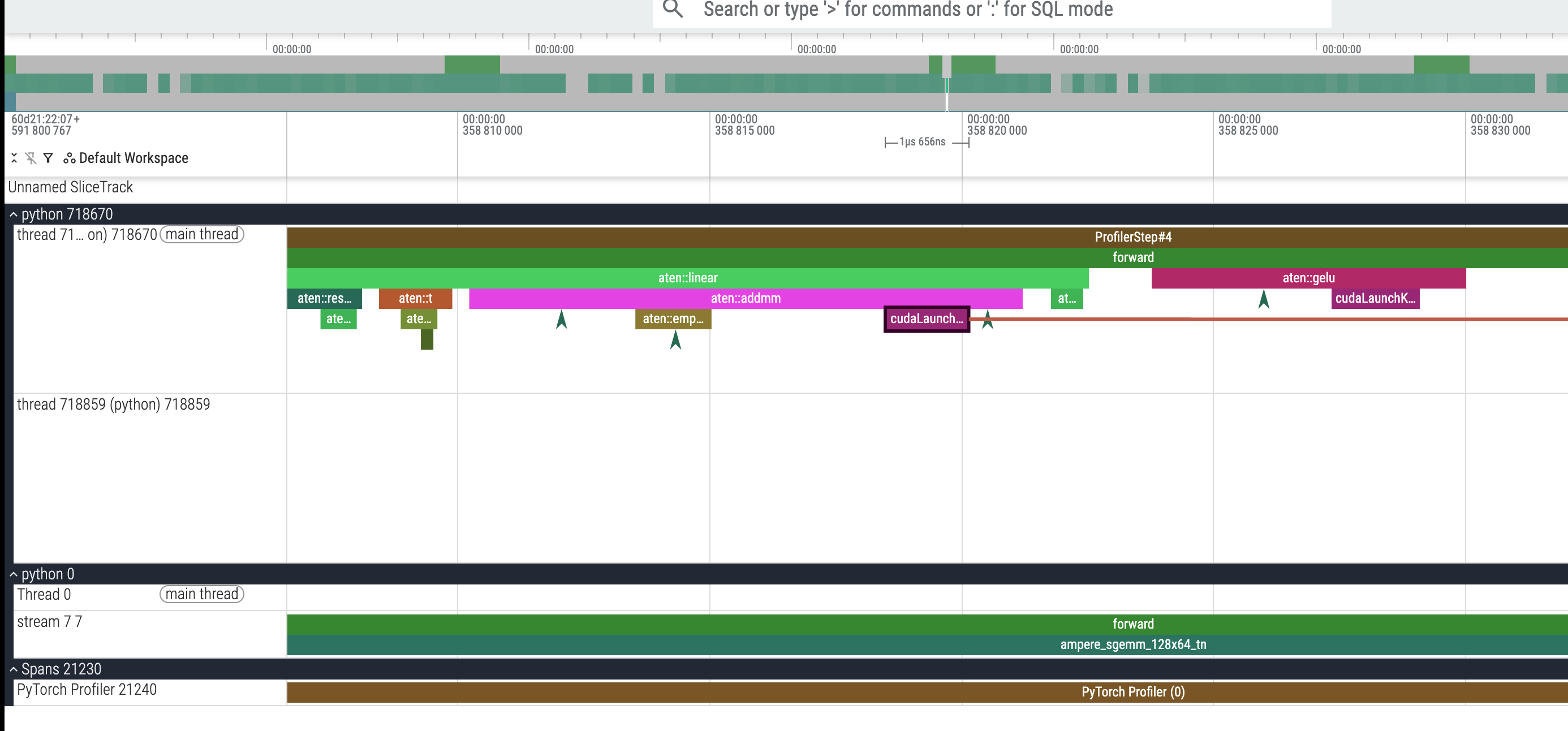
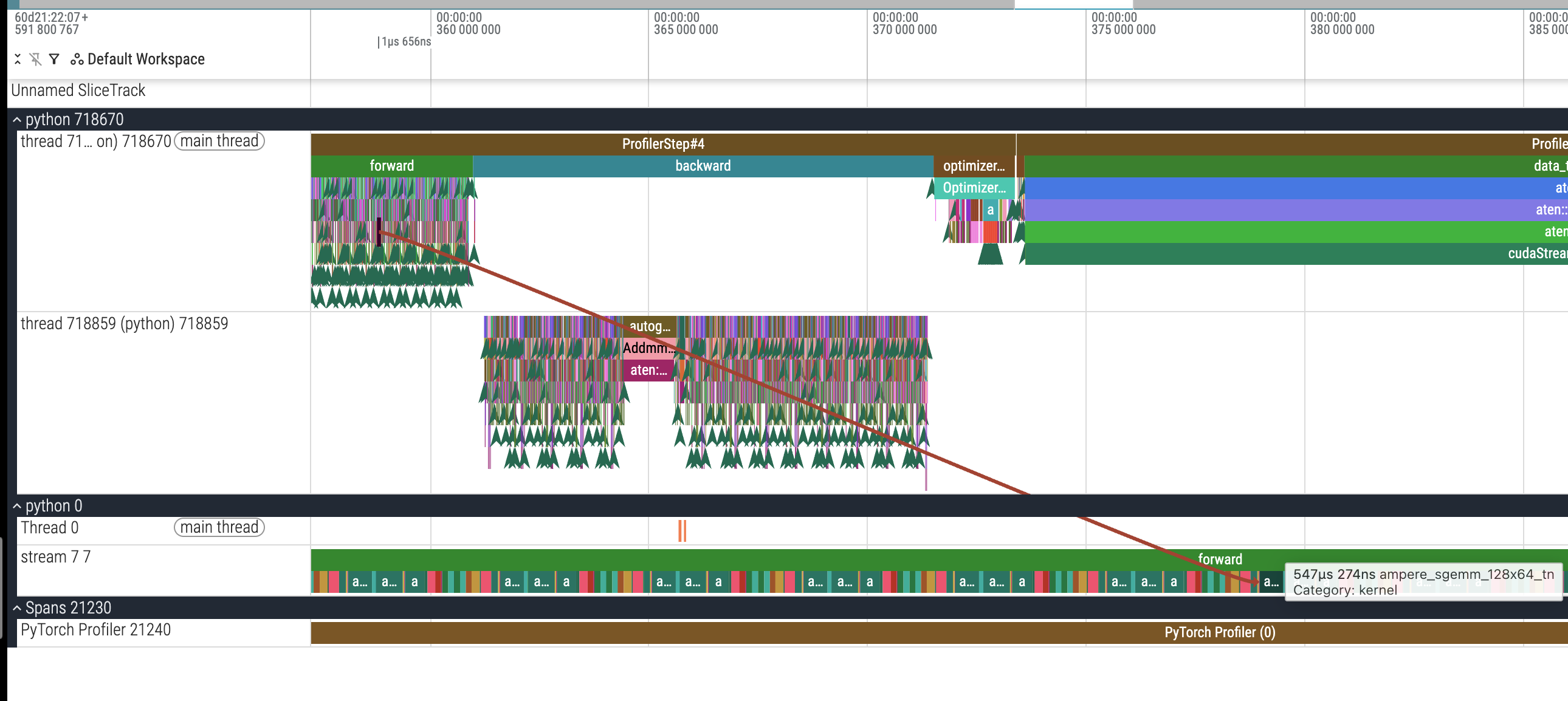
他的名字是 ampere_sgemm_128x64_tn,对应耗时 547us,比开启 AMP 的那个 cuda kernel ampere_fp16_s1688gemm_fp16_128x128_ldg8_relu_f2f_stages_32x1_tn(165us)要多两倍。
这俩 kernel 名是什么鬼?为什么开 AMP 用的这个 kernel 会更快?
- ampere_sgemm_128x64_tn
- sgemm:single precision GEMM (FP32)
- 128x64:表示 tile 的大小(矩阵分块尺寸)
- tn:GEMM layout 的组合标识,比如第一个矩阵是 row-wise,第二个矩阵是 col-wise 这种
- 然后这个 FP32 的 GEMM 是不会用 tensor core 的,只用 cuda core
- 而 cuda core 在 FP32 GEMM 的吞吐比 tensor core 要慢一大截(在 A100 上差 8x 以上,在 4070 上一般差 4x~16x)
- ampere_fp16_s1688gemm_fp16_128x128_ldg8_relu_f2f_stages_32x1_tn
- ampere_fp16:架构+数据类型
- s1688gemm:表示实际的 tensor core 硬件的 tile 是 16x8x8(MxNxK,对应矩阵乘法是 MxN = MxK @ KxN)
- 128x128:表示 thread block 里面使用的软件的 tile
- ldg8:表示 vectorized load global memory 的宽度(8 个元素,比如 8 个 FP16,8 个 FP32 这种)
- relu:表示这个模板的 epilogue 支持带一个 fused relu(但是我们这里其实没用到,我们的 gelu 是单独一个 kernel)
- f2f:fragment to fragment 表示 fragment pipeline 模式,有点高深,以后再细看
- stages_32x1:表示软件 pipeline 的深度,不太懂
- tn:GEMM layout 的组合表示,比如第一个矩阵是 row-wise,第二个矩阵是 col-wise 这种
开了 AMP 比较快的主要原因就是使用了 tensor core,比不开时使用的 cuda core 快很多。
对了,我们可以看一下实际 tokens/s 的对比,开启 AMP 是 19k tokens/s,不开 AMP 是 11k tokens/s,开启的话相当于快了 72%!
$ python train_minimal.py --train-data data/train.txt --use-profiler --n-heads 4 --d-model 768 --d-ff 3072 --n-layers 12 --seq-len 1024 --batch-size 2
[2025-12-01 11:48:45] Training started at 2025-12-01 11:48:45
[2025-12-01 11:48:45] Using device: cuda
[2025-12-01 11:48:45] Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=12, n_heads=4, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=True, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
[2025-12-01 11:48:49] train dataset size: 824
[2025-12-01 11:48:49] val dataset size: 91
[2025-12-01 11:48:49] steps per epoch: 412
[2025-12-01 11:48:49] Starting from scratch
Profiler enabled. Trace will be saved after training
[W1201 11:48:49.294775426 CPUAllocator.cpp:245] Memory block of unknown size was allocated before the profiling started, profiler results will not include the deallocation event
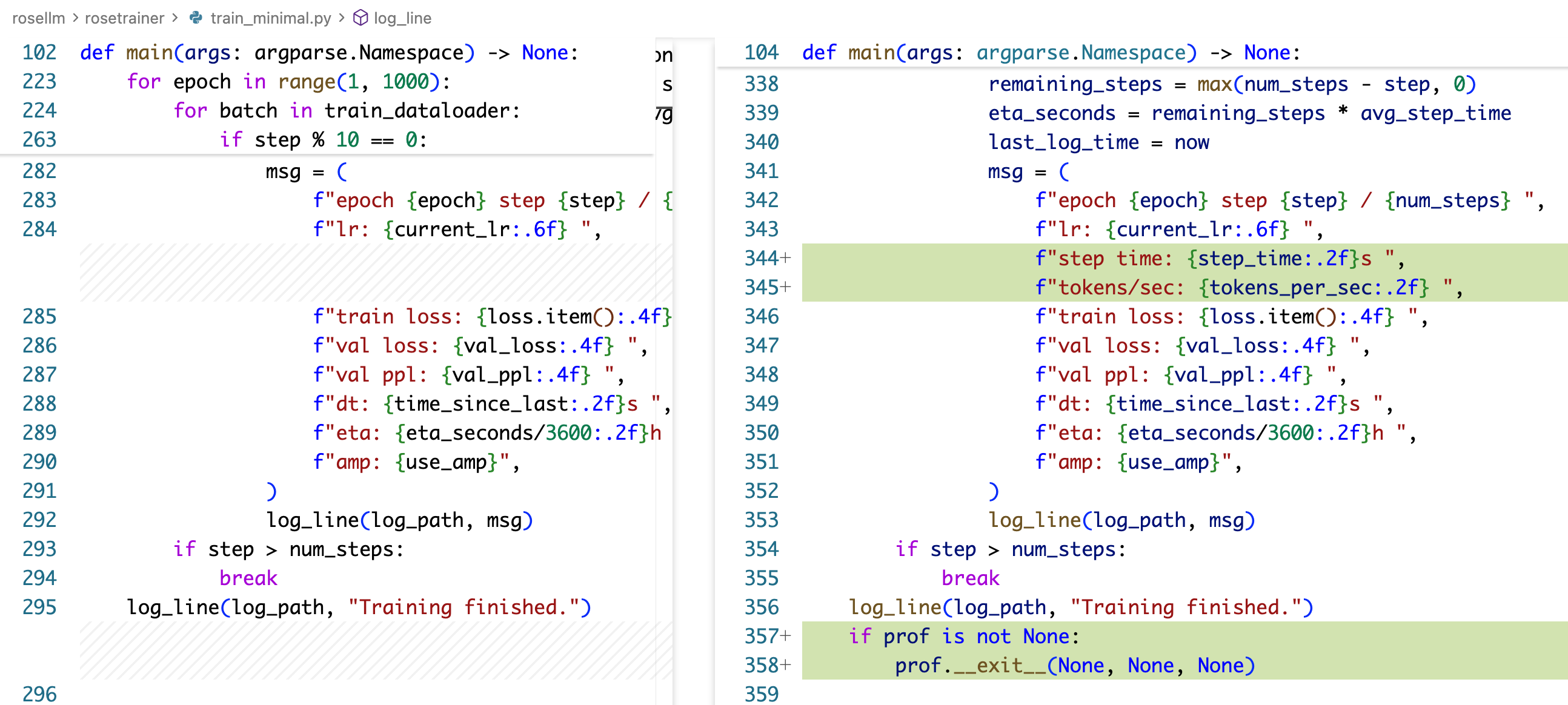
[2025-12-01 11:48:51] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.11s ', 'tokens/sec: 19332.07 ', 'train loss: 10.2511 ', 'val loss: 9.7465 ', 'val ppl: 17094.9530 ', 'dt: 2.55s ', 'eta: 0.00h ', 'amp: True')
[2025-12-01 11:48:55] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.11s ', 'tokens/sec: 19335.46 ', 'train loss: 8.6604 ', 'val loss: 8.3723 ', 'val ppl: 4325.6458 ', 'dt: 3.88s ', 'eta: 0.00h ', 'amp: True')
[2025-12-01 11:48:57] ('epoch 1 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.11s ', 'tokens/sec: 19329.50 ', 'train loss: 7.4427 ', 'val loss: 7.2592 ', 'val ppl: 1421.1899 ', 'dt: 2.13s ', 'eta: 0.00h ', 'amp: True')
[2025-12-01 11:49:01] ('epoch 1 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.11s ', 'tokens/sec: 19274.46 ', 'train loss: 5.9187 ', 'val loss: 5.9142 ', 'val ppl: 370.2608 ', 'dt: 3.88s ', 'eta: 0.00h ', 'amp: True')
[2025-12-01 11:49:03] ('epoch 1 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.11s ', 'tokens/sec: 19313.03 ', 'train loss: 4.8765 ', 'val loss: 4.7719 ', 'val ppl: 118.1494 ', 'dt: 2.14s ', 'eta: 0.00h ', 'amp: True')
[2025-12-01 11:49:03] Training finished.
$ python train_minimal.py --train-data data/train.txt --use-profiler --n-heads 4 --d-model 768 --d-ff 3072 --n-layers 12 --seq-len 1024 --batch-size 2 --no-amp
[2025-12-01 11:49:57] Training started at 2025-12-01 11:49:57
[2025-12-01 11:49:57] Using device: cuda
[2025-12-01 11:49:57] Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=12, n_heads=4, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=True, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=True, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
[2025-12-01 11:50:00] train dataset size: 824
[2025-12-01 11:50:00] val dataset size: 91
[2025-12-01 11:50:00] steps per epoch: 412
[2025-12-01 11:50:01] Starting from scratch
Profiler enabled. Trace will be saved after training
[W1201 11:50:01.113790976 CPUAllocator.cpp:245] Memory block of unknown size was allocated before the profiling started, profiler results will not include the deallocation event
[2025-12-01 11:50:05] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.18s ', 'tokens/sec: 11195.38 ', 'train loss: 9.9836 ', 'val loss: 9.8336 ', 'val ppl: 18649.3216 ', 'dt: 4.57s ', 'eta: 0.01h ', 'amp: False')
[2025-12-01 11:50:11] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.18s ', 'tokens/sec: 11217.63 ', 'train loss: 8.4773 ', 'val loss: 8.4431 ', 'val ppl: 4642.7772 ', 'dt: 5.84s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:15] ('epoch 1 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.18s ', 'tokens/sec: 11165.49 ', 'train loss: 7.4404 ', 'val loss: 7.3306 ', 'val ppl: 1526.3038 ', 'dt: 4.24s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:21] ('epoch 1 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.18s ', 'tokens/sec: 11147.84 ', 'train loss: 6.1299 ', 'val loss: 6.0101 ', 'val ppl: 407.5441 ', 'dt: 5.84s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:25] ('epoch 1 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.18s ', 'tokens/sec: 11131.73 ', 'train loss: 4.9011 ', 'val loss: 4.8457 ', 'val ppl: 127.1976 ', 'dt: 4.26s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:25] Training finished.
开启 activation checkpointing vs 不开启 activation checkpointing
先看 tokens/s,不开启的时候是 11k tokens/s,而开启的时候是 9k tokens/s,慢了 18%,合理,因为这个特性本来就是用时间换空间,所以我们要重点对比显存开销。
$ python train_minimal.py --train-data data/train.txt --use-profiler --n-heads 4 --d-model 768 --d-ff 3072 --n-layers 12 --seq-len 1024 --batch-size 2 --no-amp
[2025-12-01 11:49:57] Training started at 2025-12-01 11:49:57
[2025-12-01 11:49:57] Using device: cuda
[2025-12-01 11:49:57] Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=12, n_heads=4, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=True, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=True, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
[2025-12-01 11:50:00] train dataset size: 824
[2025-12-01 11:50:00] val dataset size: 91
[2025-12-01 11:50:00] steps per epoch: 412
[2025-12-01 11:50:01] Starting from scratch
Profiler enabled. Trace will be saved after training
[W1201 11:50:01.113790976 CPUAllocator.cpp:245] Memory block of unknown size was allocated before the profiling started, profiler results will not include the deallocation event
[2025-12-01 11:50:05] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.18s ', 'tokens/sec: 11195.38 ', 'train loss: 9.9836 ', 'val loss: 9.8336 ', 'val ppl: 18649.3216 ', 'dt: 4.57s ', 'eta: 0.01h ', 'amp: False')
[2025-12-01 11:50:11] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.18s ', 'tokens/sec: 11217.63 ', 'train loss: 8.4773 ', 'val loss: 8.4431 ', 'val ppl: 4642.7772 ', 'dt: 5.84s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:15] ('epoch 1 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.18s ', 'tokens/sec: 11165.49 ', 'train loss: 7.4404 ', 'val loss: 7.3306 ', 'val ppl: 1526.3038 ', 'dt: 4.24s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:21] ('epoch 1 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.18s ', 'tokens/sec: 11147.84 ', 'train loss: 6.1299 ', 'val loss: 6.0101 ', 'val ppl: 407.5441 ', 'dt: 5.84s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:25] ('epoch 1 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.18s ', 'tokens/sec: 11131.73 ', 'train loss: 4.9011 ', 'val loss: 4.8457 ', 'val ppl: 127.1976 ', 'dt: 4.26s ', 'eta: 0.00h ', 'amp: False')
[2025-12-01 11:50:25] Training finished.
$ python train_minimal.py --train-data data/train.txt --use-profiler --n-heads 4 --d-model 768 --d-ff 3072 --n-layers 12 --seq-len 1024 --batch-size 2 --no-amp --use-activation-checkpoint
[2025-12-02 10:05:40] Training started at 2025-12-02 10:05:40
[2025-12-02 10:05:40] Using device: cuda
[2025-12-02 10:05:40] Arguments: Namespace(vocab_size=10000, max_position_embeddings=10000, n_layers=12, n_heads=4, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=True, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=True, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=True, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None)
total files: 1
total tokens: 937660
[2025-12-02 10:05:44] train dataset size: 824
[2025-12-02 10:05:44] val dataset size: 91
[2025-12-02 10:05:44] steps per epoch: 412
[2025-12-02 10:05:44] Starting from scratch
Profiler enabled. Trace will be saved after training
[W1202 10:05:45.700908261 CPUAllocator.cpp:245] Memory block of unknown size was allocated before the profiling started, profiler results will not include the deallocation event
[2025-12-02 10:05:49] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.23s ', 'tokens/sec: 9038.93 ', 'train loss: 10.0389 ', 'val loss: 9.7337 ', 'val ppl: 16876.5354 ', 'dt: 5.09s ', 'eta: 0.01h ', 'amp: False')
[2025-12-02 10:05:55] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.23s ', 'tokens/sec: 9042.11 ', 'train loss: 8.5506 ', 'val loss: 8.4109 ', 'val ppl: 4495.7428 ', 'dt: 6.30s ', 'eta: 0.00h ', 'amp: False')
[2025-12-02 10:06:00] ('epoch 1 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.23s ', 'tokens/sec: 9058.04 ', 'train loss: 7.8459 ', 'val loss: 7.2893 ', 'val ppl: 1464.5323 ', 'dt: 4.67s ', 'eta: 0.00h ', 'amp: False')
[2025-12-02 10:06:06] ('epoch 1 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.23s ', 'tokens/sec: 9051.67 ', 'train loss: 6.1626 ', 'val loss: 5.9229 ', 'val ppl: 373.5099 ', 'dt: 6.28s ', 'eta: 0.00h ', 'amp: False')
[2025-12-02 10:06:11] ('epoch 1 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.23s ', 'tokens/sec: 9013.45 ', 'train loss: 4.7414 ', 'val loss: 4.7548 ', 'val ppl: 116.1379 ', 'dt: 4.70s ', 'eta: 0.00h ', 'amp: False')
[2025-12-02 10:06:11] Training finished.
我看 pytorch trace 主要使用的是 vscode 上的 nCompass Performance Optimization IDE 这个插件,还是很好用的,安装好之后对着 trace json 右键 open with 然后选看 profile 的一项就行了。但是这个 trace 查看主要还是时间维度的查看,内存维度并不多。
如果要看内存的话,可以使用 tensorboard:
pip install tensorboard
pip install torch_tb_profiler
注意这个额外需要 install 的 torch_tb_profiler,没他就看不成 pytorch 的 trace。
然后我们在代码里面让他导出 tensorboard 可以理解的 trace 文件:
prof = profile(
activities=[
ProfilerActivity.CPU,
ProfilerActivity.CUDA,
],
schedule=schedule,
record_shapes=True,
with_stack=False,
profile_memory=True,
on_trace_ready=torch.profiler.tensorboard_trace_handler("./logdir"),
)
执行完就能看到 trace json,肉眼看和之前的 pytorch trace 其实差不多,感觉主要是有个 logdir 以及文件名的约定吧。然后我们跑两次,依次带 activation checkpointing,一次不带。
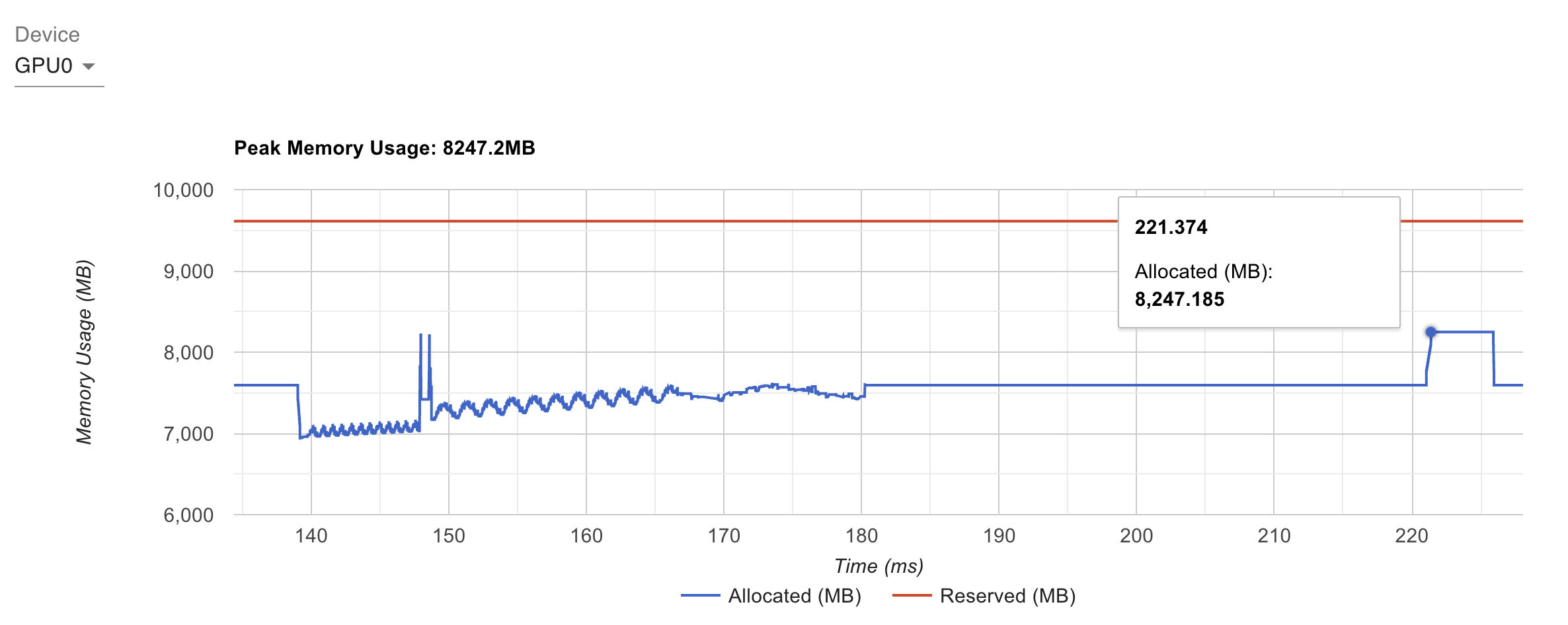
不带 activation checkpointing 的时候,峰值显存占用是 10GB 左右:
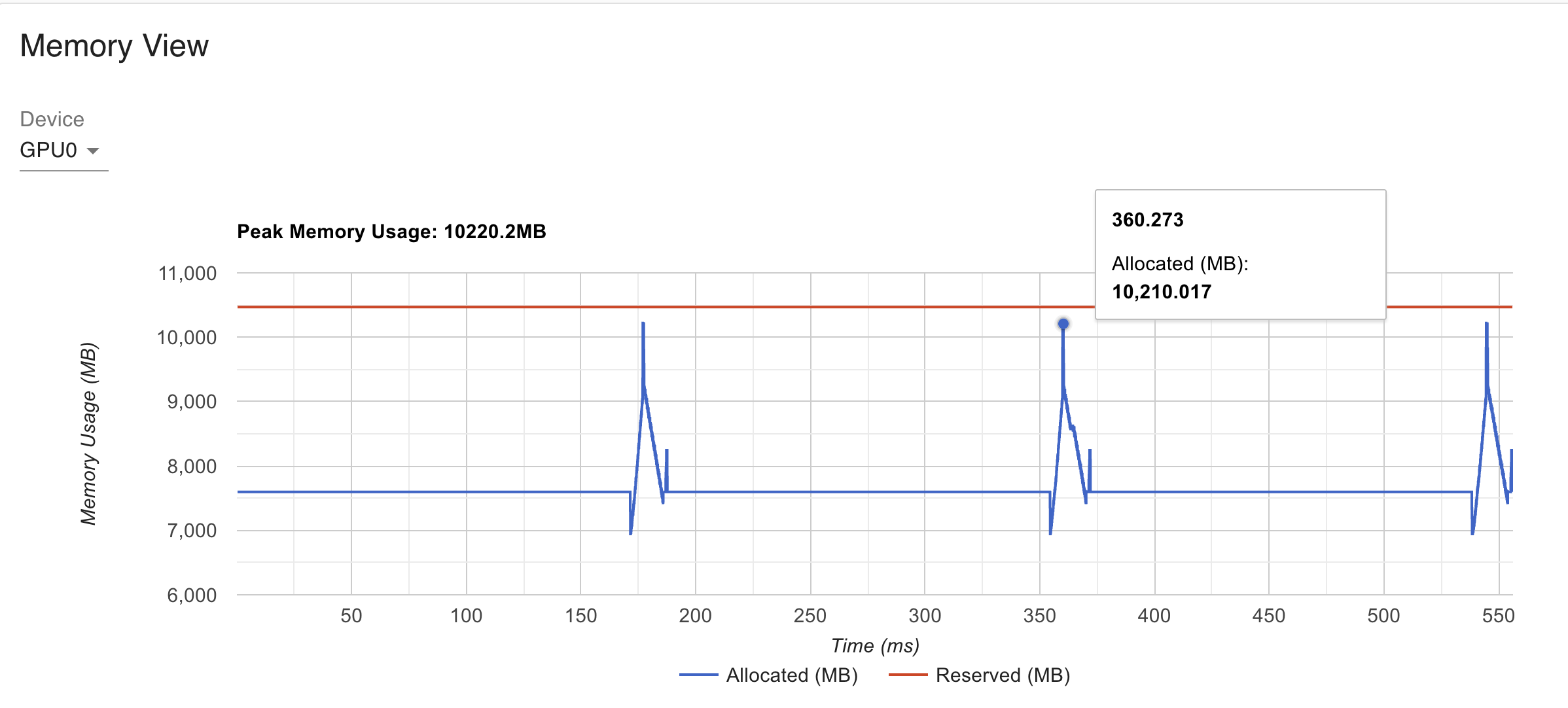
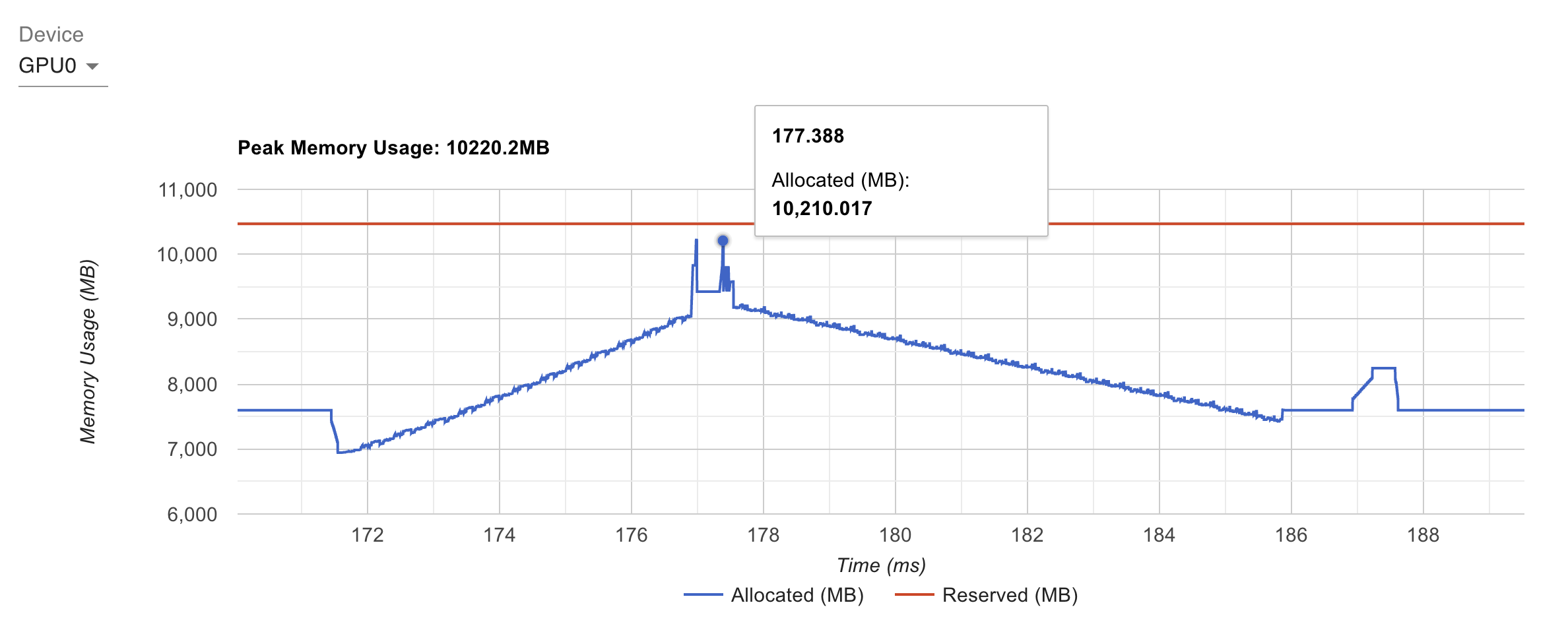
来个特写,172 开始往上走应该是在做前向,178 往后是在做反向,可以大概看到反向耗时是前向的两倍,187 附近的凸起应该是 optimizer step:
详细展开下:
- 172 前面掉了一下:这是上一个 iteration 的显存释放时机(pytorch 的 caching allocator 延迟释放),叫做 iteration reset
- 172 => 176:就是前向,每层的 activation 在逐渐累积
- 177 附近有两个尖峰:应该是准备反向时的 buffer 预分配?
- 178 => 185:反向
- 187 => 188:有个平面,应该是 optimizer step 的时候使用的一些临时 buffer
开启 activation checkpointing 的话,峰值显存占用是 8GB 左右:
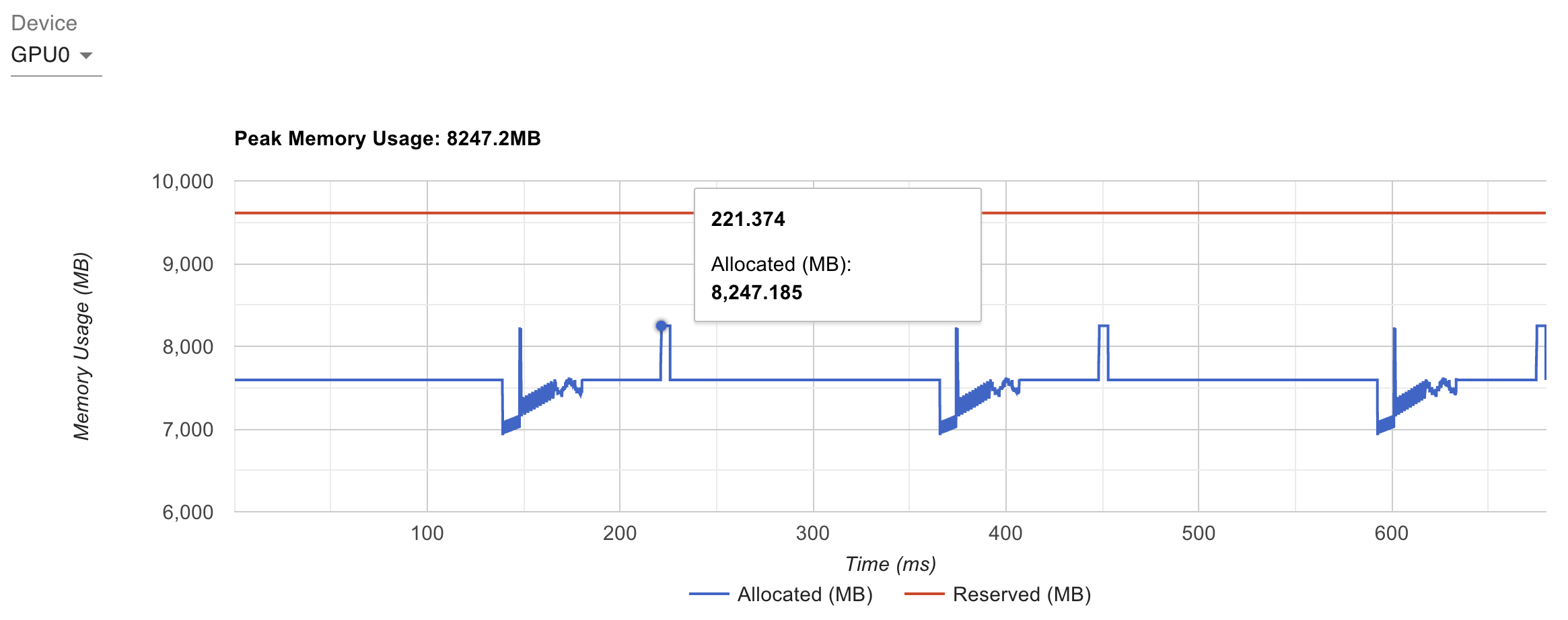
也来个特写,这个就很有特点了,可以发现前向就不是一直增了,因为前向其实只有每层会保留下激活值,然后反向的时候会做重新 forward,每 forward 一个 layer,显存涨一点,然后再做该 layer 的 backward,显存就又降一点:
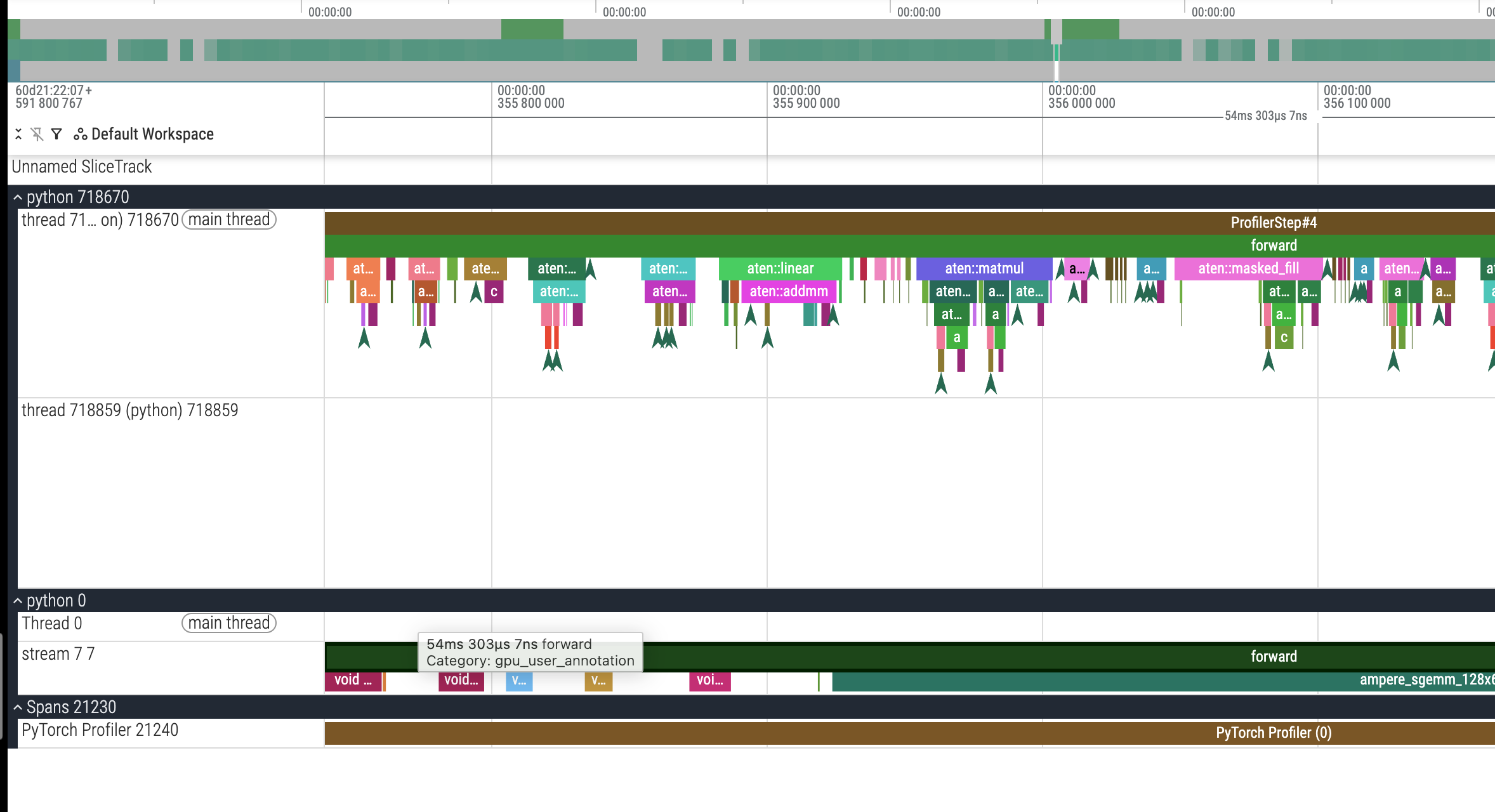
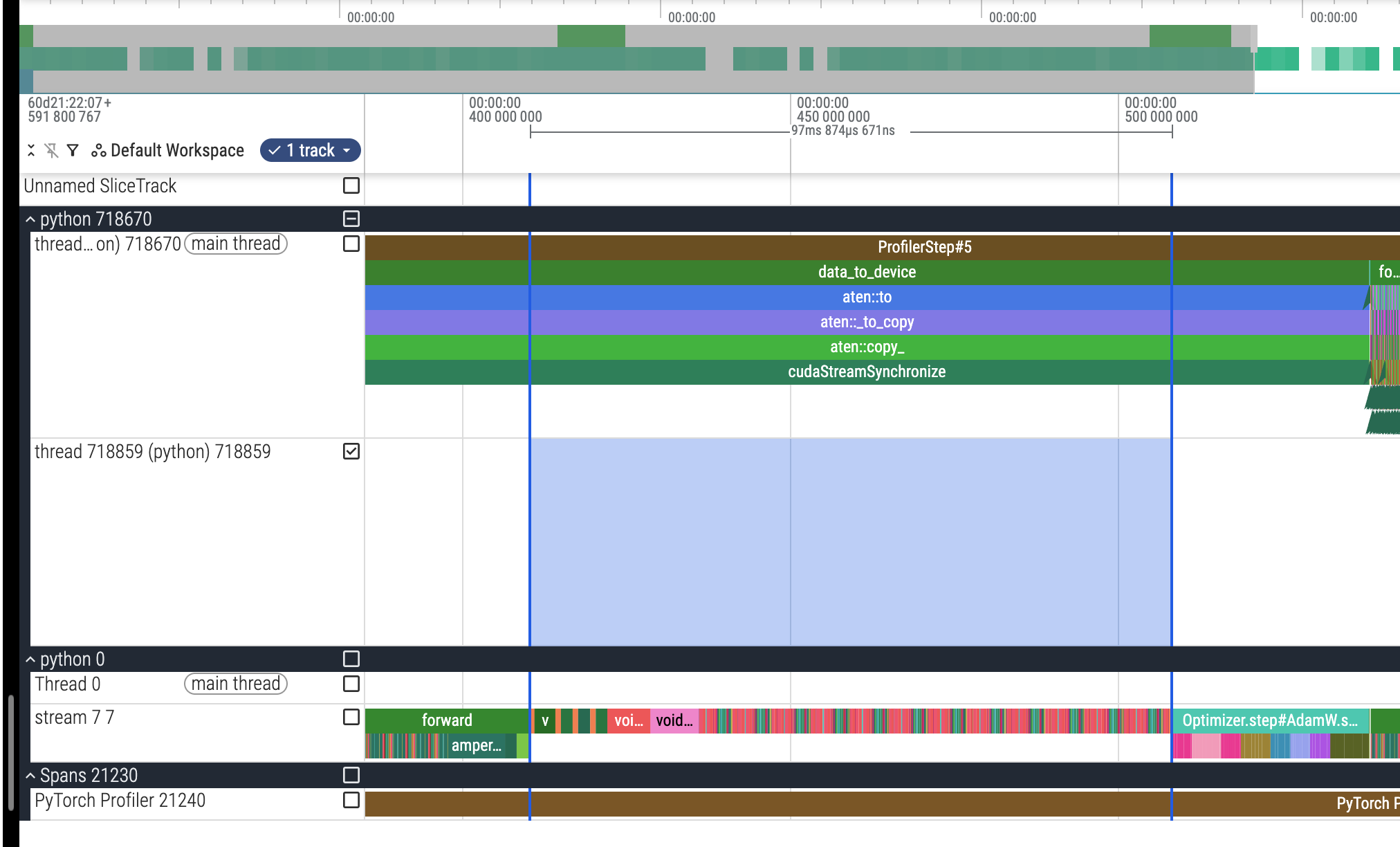
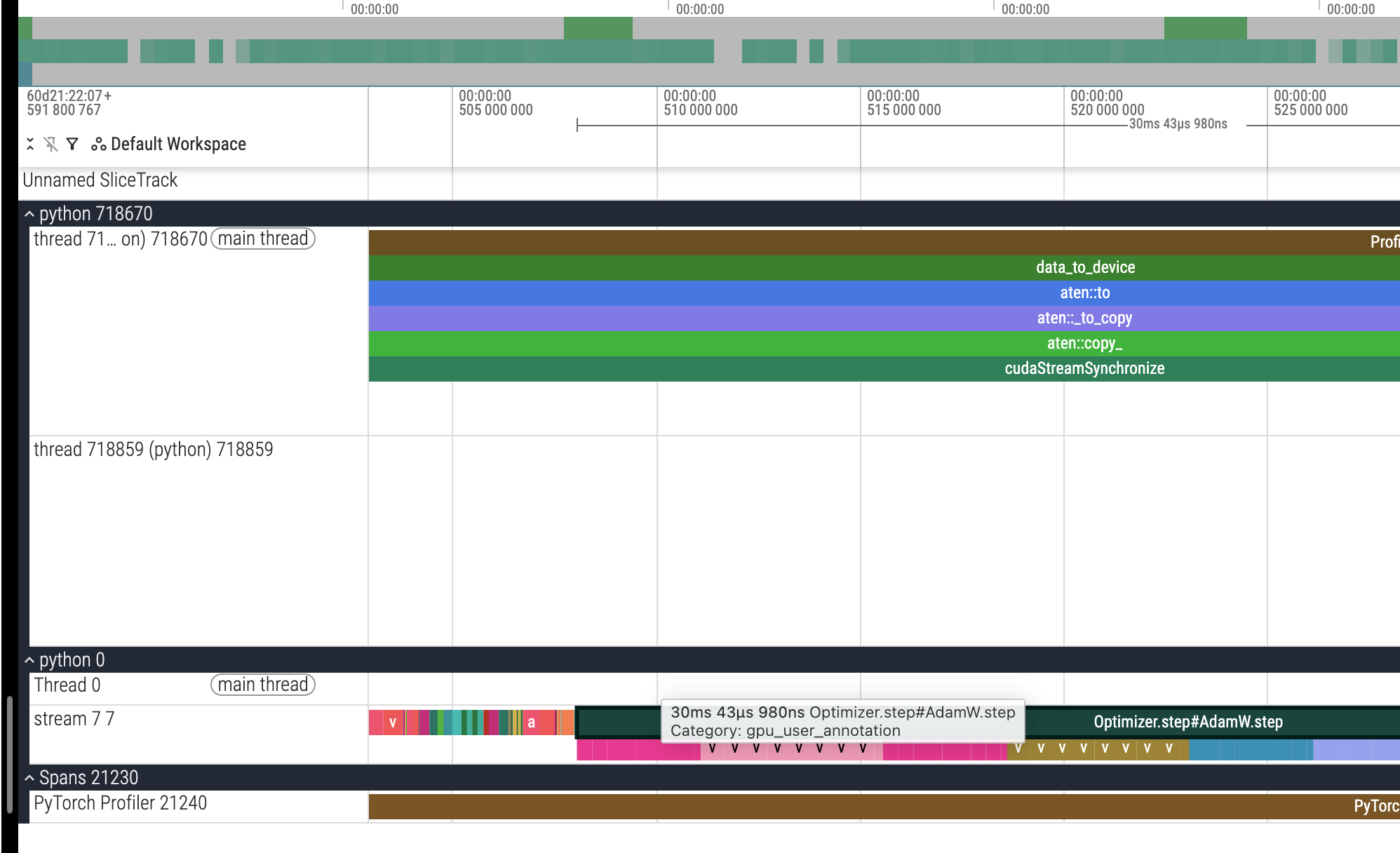
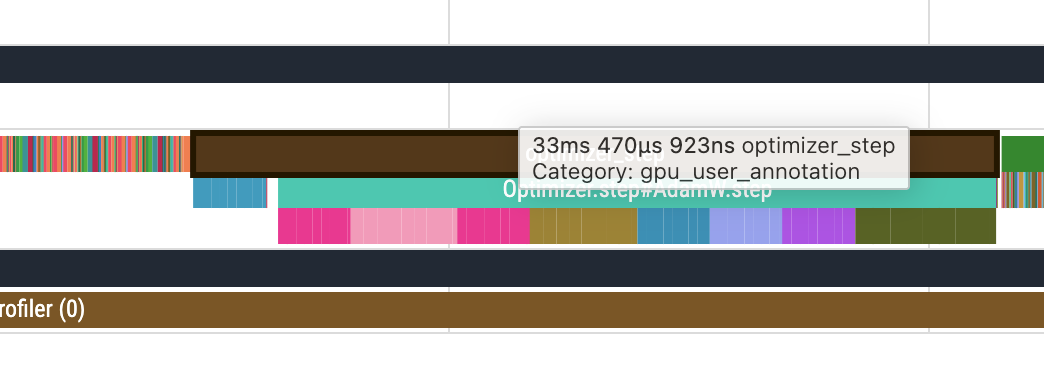
附录:一些数据截图
使用 AMP 的截图:
 不使用 AMP 的截图:
不使用 AMP 的截图: