从零实现 LLM Training:022. FineWebNPYDataset
本文这个 PR 主要是为了使数据正规化,有一个标准的 benchmark,我找了 fineweb-edu-10B 的数据,并且通过 GPT2 tokenizer 做好了分词,存成了一个个的 .npy 文件,所以本文这个 PR 就是引入这个 FineWebNPYDataset 数据集 class。
代码变更
dataset.py
class FineWebNPYDataset(Dataset):
def __init__(
self,
file_paths: List[str],
seq_len: int,
max_tokens: Optional[int] = None,
seed: Optional[int] = None,
random_start: bool = True,
) -> None:
super().__init__()
if not file_paths:
raise ValueError("file_paths is empty")
self.seq_len = seq_len
arrays: List[np.ndarray] = []
total = 0
for path in file_paths:
arr = np.load(path, mmap_mode="r")
if arr.ndim != 1:
raise ValueError(f"array {path} is not 1D")
arr = arr.astype(np.int64, copy=False)
if max_tokens is not None:
remaining = max_tokens - total
if remaining <= 0:
break
if arr.shape[0] > remaining:
arr = arr[:remaining]
arrays.append(arr)
total += arr.shape[0]
if not arrays:
raise ValueError("no arrays loaded")
self.tokens = np.concatenate(arrays, axis=0)
self.total_tokens = int(self.tokens.shape[0])
if self.total_tokens < seq_len:
raise ValueError("the total number of tokens is less than seq_len")
max_id = int(self.tokens.max())
self.vocab_size = max_id + 1
max_start = self.total_tokens - seq_len
num_samples = self.total_tokens // seq_len
if num_samples > max_start + 1:
num_samples = max_start + 1
if seed is None:
rng = random.Random()
else:
rng = random.Random(seed)
if random_start:
candidates = list(range(max_start + 1))
if num_samples < len(candidates):
start_indices = rng.sample(candidates, num_samples)
else:
rng.shuffle(candidates)
start_indices = candidates
else:
start_indices = [i * seq_len for i in range(num_samples)]
self.start_indices = np.array(start_indices, dtype=np.int64)
self.num_samples = int(self.start_indices.shape[0])
def __len__(self) -> int:
return self.num_samples
def __getitem__(self, idx: int):
start = int(self.start_indices[idx])
end = start + self.seq_len
ids = self.tokens[start:end]
input_ids = torch.from_numpy(ids).long()
attention_mask = torch.ones(self.seq_len, dtype=torch.long)
labels = input_ids.clone()
return {
"input_ids": input_ids,
"labels": labels,
"attention_mask": attention_mask,
}
train_minimal.py train_ddp.py
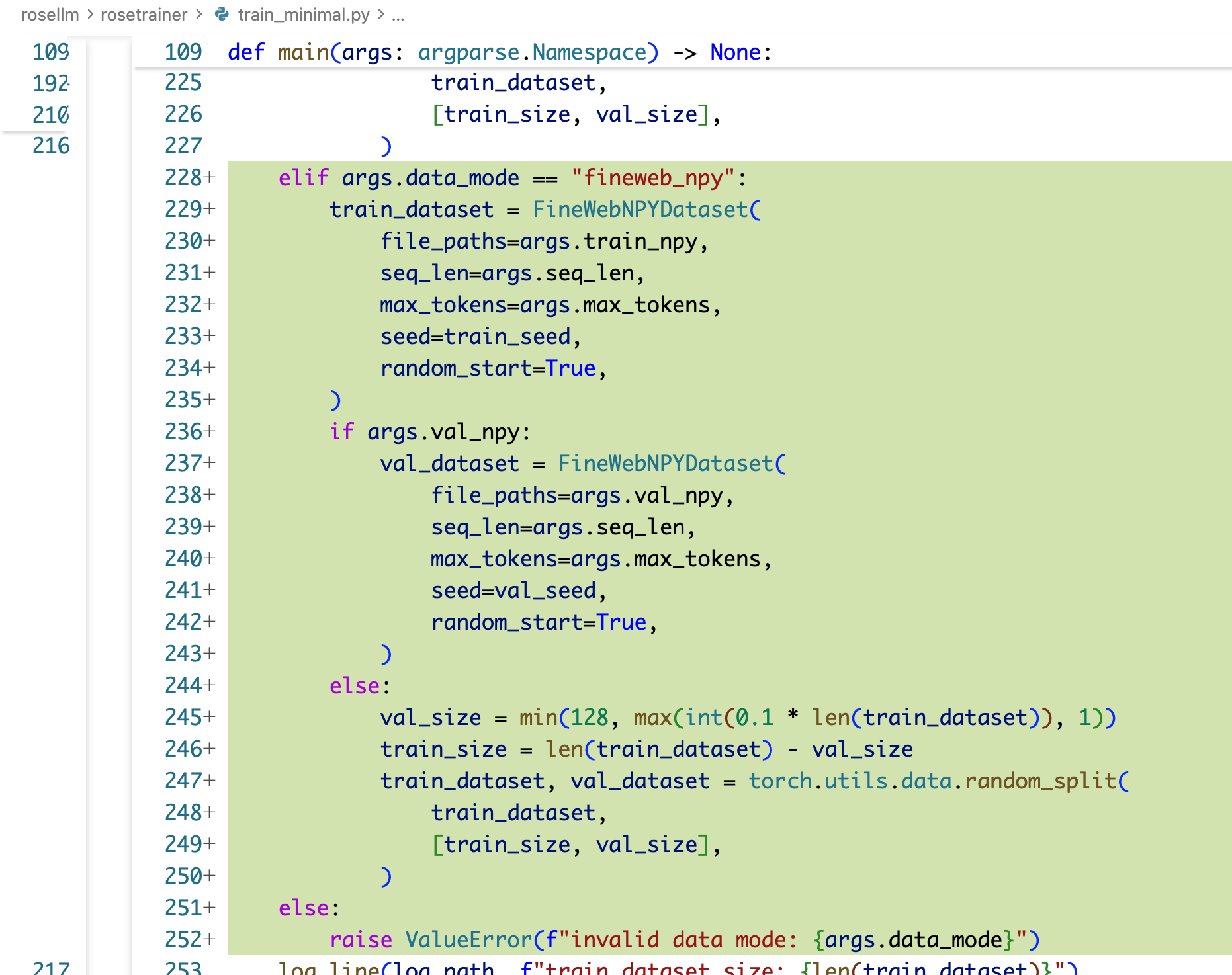
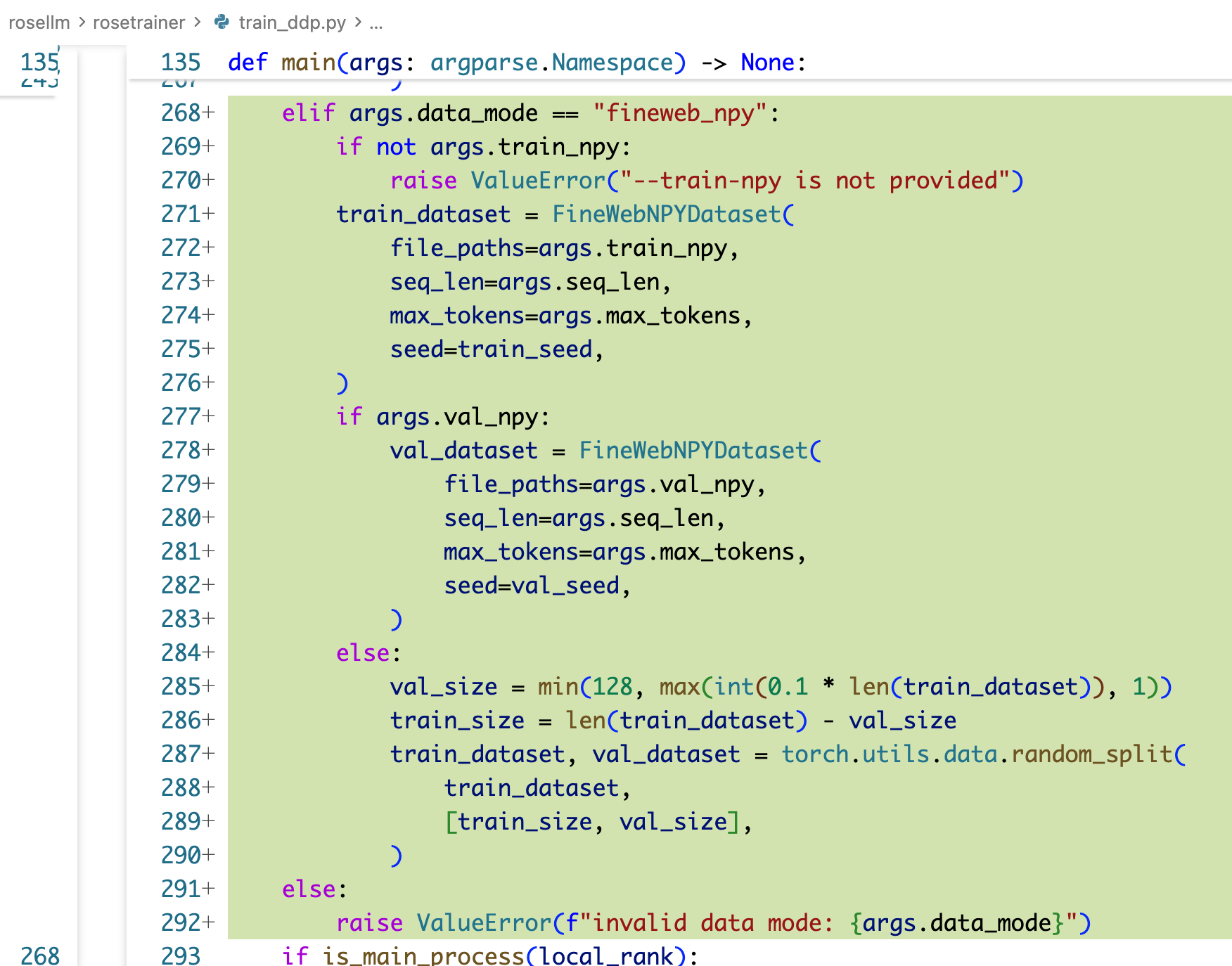
运行
$ python train_minimal.py --data-mode fineweb_npy --train-npy /data2/datasets/edu_fineweb10B/edufineweb_train_000001.npy --seq-len 1024 --batch-size 2 --num-steps 50 --vocab-size 50257 --tokenizer-name gpt2 --use-wandb --wandb-project mini-llm-fineweb
wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: Currently logged in as: guoqizhou123123 (guoqizhou123123-tencent) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: Tracking run with wandb version 0.19.8
wandb: Run data is saved locally in /data/projects/rosellm/rosellm/rosetrainer/wandb/run-20251202_174452-rggo8gdo
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run winter-waterfall-8
wandb: ⭐️ View project at https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb
wandb: 🚀 View run at https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb/runs/rggo8gdo
[2025-12-02 17:44:53] Training started at 2025-12-02 17:44:53
[2025-12-02 17:44:53] Using device: cuda
[2025-12-02 17:44:53] Arguments: Namespace(vocab_size=50257, max_position_embeddings=10000, n_layers=2, n_heads=4, d_model=128, d_ff=512, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_single.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=False, train_data=[], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None, data_mode='fineweb_npy', train_npy=['/data2/datasets/edu_fineweb10B/edufineweb_train_000001.npy'], val_npy=[], use_wandb=True, wandb_project='mini-llm-fineweb', wandb_run_name=None)
[2025-12-02 17:44:55] train dataset size: 96632
[2025-12-02 17:44:55] val dataset size: 1024
[2025-12-02 17:44:55] steps per epoch: 48316
[2025-12-02 17:44:56] Starting from scratch
[2025-12-02 17:44:59] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.02s ', 'tokens/sec: 99062.81 ', 'train loss: 10.9550 ', 'val loss: 10.9691 ', 'val ppl: 58054.0725 ', 'dt: 3.14s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:45:02] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.02s ', 'tokens/sec: 101286.84 ', 'train loss: 10.9252 ', 'val loss: 10.9418 ', 'val ppl: 56486.5656 ', 'dt: 3.10s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:45:05] ('epoch 1 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.02s ', 'tokens/sec: 101148.49 ', 'train loss: 10.8977 ', 'val loss: 10.8943 ', 'val ppl: 53869.2858 ', 'dt: 2.96s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:45:08] ('epoch 1 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.02s ', 'tokens/sec: 101284.45 ', 'train loss: 10.8502 ', 'val loss: 10.8153 ', 'val ppl: 49774.9702 ', 'dt: 3.11s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:45:11] ('epoch 1 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.02s ', 'tokens/sec: 101140.16 ', 'train loss: 10.6642 ', 'val loss: 10.6673 ', 'val ppl: 42927.0406 ', 'dt: 2.96s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:45:11] Training finished.
wandb:
wandb:
wandb: Run history:
wandb: amp ▁▁▁▁▁
wandb: lr ▁▃▅▆█
wandb: step_time █▁▁▁▁
wandb: tokens_per_sec ▁████
wandb: train/loss █▇▇▅▁
wandb: val/loss █▇▆▄▁
wandb: val/ppl █▇▆▄▁
wandb:
wandb: Run summary:
wandb: amp 1
wandb: lr 0.00015
wandb: step_time 0.02025
wandb: tokens_per_sec 101140.15603
wandb: train/loss 10.66421
wandb: val/loss 10.66726
wandb: val/ppl 42927.0406
wandb:
wandb: 🚀 View run winter-waterfall-8 at: https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb/runs/rggo8gdo
wandb: ⭐️ View project at: https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb
wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20251202_174452-rggo8gdo/logs
$ torchrun --nproc-per-node=2 train_ddp.py --data-mode fineweb_npy --train-npy /data2/datasets/edu_fineweb10B/edufineweb_train_000001.npy --seq-len 1024 --batch-size 2 --num-steps 50 --vocab-size 50257 --tokenizer-name gpt2 --use-wandb --wandb-project mini-llm-fineweb-ddp
W1202 17:48:48.576000 2626521 site-packages/torch/distributed/run.py:792]
W1202 17:48:48.576000 2626521 site-packages/torch/distributed/run.py:792] *****************************************
W1202 17:48:48.576000 2626521 site-packages/torch/distributed/run.py:792] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W1202 17:48:48.576000 2626521 site-packages/torch/distributed/run.py:792] *****************************************
wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: Currently logged in as: guoqizhou123123 (guoqizhou123123-tencent) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: Tracking run with wandb version 0.19.8
wandb: Run data is saved locally in /data/projects/rosellm/rosellm/rosetrainer/wandb/run-20251202_174851-59yojrsq
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run gentle-waterfall-1
wandb: ⭐️ View project at https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb-ddp
wandb: 🚀 View run at https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb-ddp/runs/59yojrsq
[2025-12-02 17:48:52] Training started at 2025-12-02 17:48:52
[2025-12-02 17:48:52] [rank 0] Using device: cuda:0
[2025-12-02 17:48:52] Arguments: Namespace(vocab_size=50257, max_position_embeddings=10000, n_layers=2, n_heads=4, d_model=128, d_ff=512, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/minigpt_ddp.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=False, train_data=[], val_data=[], val_ratio=0.1, data_mode='fineweb_npy', train_npy=['/data2/datasets/edu_fineweb10B/edufineweb_train_000001.npy'], val_npy=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=None, data_seed=None, use_wandb=True, wandb_project='mini-llm-fineweb-ddp', wandb_run_name=None)
[2025-12-02 17:48:56] train dataset size: 97528
[2025-12-02 17:48:56] val dataset size: 128
[2025-12-02 17:48:56] steps per epoch: 24382
[2025-12-02 17:48:56] [rank 0] Starting from scratch
[2025-12-02 17:48:59] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.17', 'toks/s (per rank): 12323.59', 'train loss: 10.9936 ', 'val loss: 10.9822 ', 'val ppl: 58818.5771 ', 'dt: 2.12s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:49:01] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.17', 'toks/s (per rank): 12393.18', 'train loss: 10.9534 ', 'val loss: 10.9522 ', 'val ppl: 57081.4484 ', 'dt: 1.97s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:49:02] ('epoch 1 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.17', 'toks/s (per rank): 12384.12', 'train loss: 10.9138 ', 'val loss: 10.8984 ', 'val ppl: 54092.0985 ', 'dt: 1.83s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:49:04] ('epoch 1 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.17', 'toks/s (per rank): 12393.66', 'train loss: 10.7998 ', 'val loss: 10.8016 ', 'val ppl: 49097.3859 ', 'dt: 1.96s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:49:06] ('epoch 1 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.17', 'toks/s (per rank): 12348.94', 'train loss: 10.6749 ', 'val loss: 10.6058 ', 'val ppl: 40369.3415 ', 'dt: 1.89s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 17:49:06] Training finished.
wandb:
wandb:
wandb: Run history:
wandb: amp ▁▁▁▁▁
wandb: global_tokens_per_sec ▁█▇█▄
wandb: lr ▁▃▅▆█
wandb: tokens_per_sec_per_rank ▁█▇█▄
wandb: train/loss █▇▆▄▁
wandb: val/loss █▇▆▅▁
wandb: val/ppl █▇▆▄▁
wandb:
wandb: Run summary:
wandb: amp 1
wandb: global_tokens_per_sec 24697.87879
wandb: lr 0.00015
wandb: tokens_per_sec_per_rank 12348.93939
wandb: train/loss 10.67491
wandb: val/loss 10.60583
wandb: val/ppl 40369.34146
wandb:
wandb: 🚀 View run gentle-waterfall-1 at: https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb-ddp/runs/59yojrsq
wandb: ⭐️ View project at: https://wandb.ai/guoqizhou123123-tencent/mini-llm-fineweb-ddp
wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20251202_174851-59yojrsq/logs