从零实现 LLM Training:023. Gradient Accumulation and Clip Gradient Norm
本文 PR 主要来实现几个和梯度相关的非常重要功能:
- gradient accumulation
- clip gradient norm
首先第一个主要是用来扩充 effective batch size 的,比如我的 GPU 的显存小的可怜,每次只能塞的 batch size 为 1,但是我又想有比较大的 batch size 从而能够使梯度的噪声不至于那么大,那么我们就可以通过多次前向反向后再做一次 optimizer step(而不是每次前向反向后直接做 optimizer step),这里需要注意有一个 loss /= grad_accum_steps 因为我们是积累多个 steps 的梯度。
另一个则是 clip gradient norm,也就是对梯度范数进行裁剪,梯度范数实际上就是梯度里面所有数各自的平方加起来,然后最后开根号,范数直观意义上就是表示这个梯度整体数值大概是多大,理想情况下应该是在 1 以内,防止过大导致训崩,所以一般做梯度范数为 1 的梯度范数裁剪,裁剪的时候要注意如果使用了 AMP 的话需要先调用 scaler.unscale_(optimizer) 来去掉 AMP 的 scale 操作。
核心代码变更
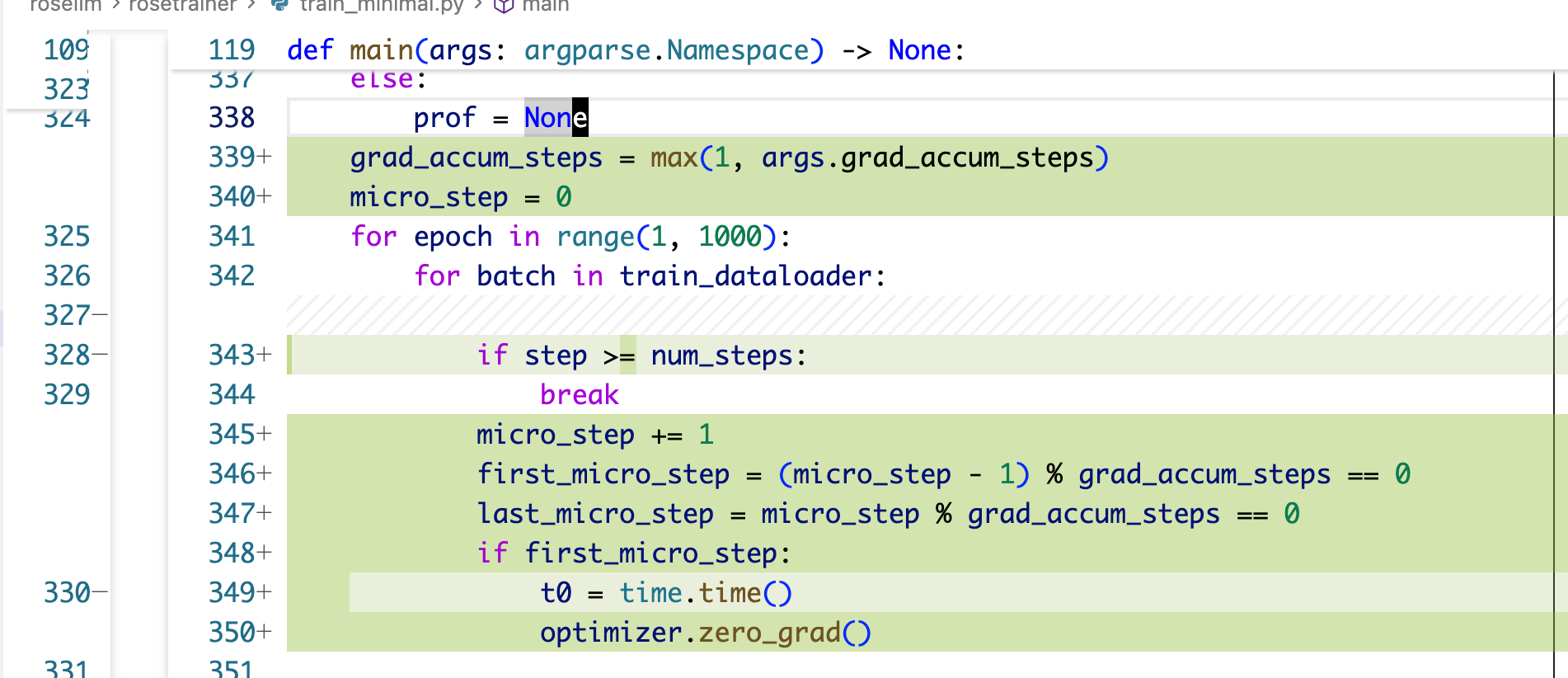
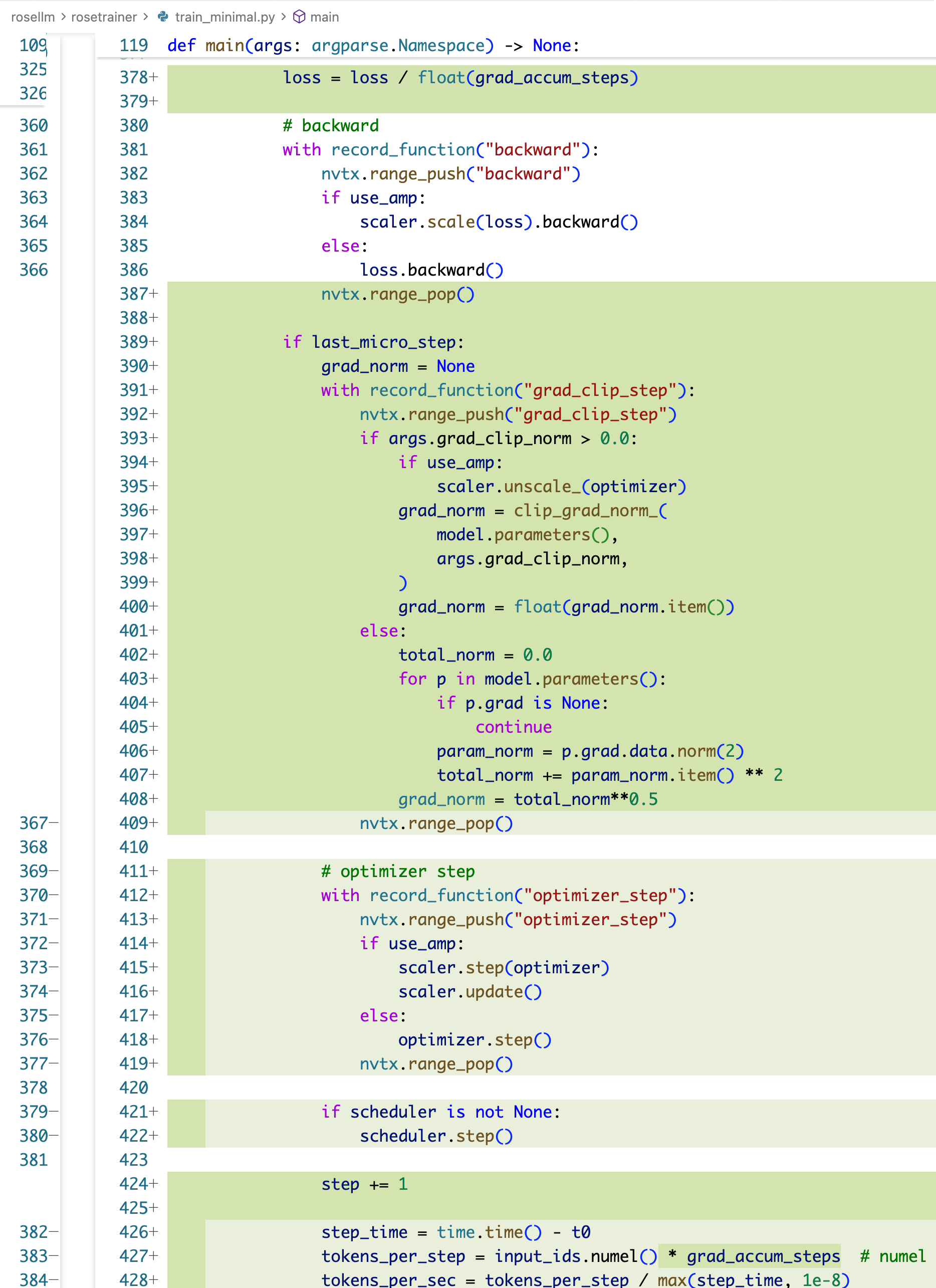
train_ddp.py 的代码变更类似。
运行
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm/rosetrainer$ ./train_gpt2_small_minimal.sh
wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: Currently logged in as: guoqizhou123123 (guoqizhou123123-tencent) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: Tracking run with wandb version 0.19.8
wandb: Run data is saved locally in /data/projects/rosellm/rosellm/rosetrainer/wandb/run-20251202_200347-tlne3zj3
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run northern-sunset-7
wandb: ⭐️ View project at https://wandb.ai/guoqizhou123123-tencent/rosetrainer
wandb: 🚀 View run at https://wandb.ai/guoqizhou123123-tencent/rosetrainer/runs/tlne3zj3
[2025-12-02 20:03:48] Training started at 2025-12-02 20:03:48
[2025-12-02 20:03:48] Using device: cuda
[2025-12-02 20:03:48] Arguments: Namespace(vocab_size=50257, max_position_embeddings=1024, n_layers=12, n_heads=12, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/gpt2_small_minimal.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=False, seed=42, grad_accum_steps=2, grad_clip_norm=1.0, train_data=['data/train.txt'], val_data=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=100000, data_seed=42, data_mode='text', train_npy=[], val_npy=[], use_wandb=True, wandb_project='rosetrainer', wandb_run_name=None)
total files: 1
total tokens: 100000
[2025-12-02 20:03:50] train dataset size: 88
[2025-12-02 20:03:50] val dataset size: 9
[2025-12-02 20:03:50] steps per epoch: 44
[2025-12-02 20:03:51] Starting from scratch
[2025-12-02 20:03:54] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.29s ', 'tokens/sec: 14060.44 ', 'grad norm: 2.2948 ', 'train loss: 4.9909 ', 'val loss: 9.8618 ', 'val ppl: 19183.9024 ', 'dt: 3.27s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:03:59] ('epoch 1 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.29s ', 'tokens/sec: 14042.51 ', 'grad norm: 2.7618 ', 'train loss: 4.3298 ', 'val loss: 8.5735 ', 'val ppl: 5289.3874 ', 'dt: 4.73s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:04:02] ('epoch 2 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.29s ', 'tokens/sec: 14045.78 ', 'grad norm: 2.6866 ', 'train loss: 3.7137 ', 'val loss: 7.3583 ', 'val ppl: 1569.2035 ', 'dt: 3.11s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:04:07] ('epoch 2 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.29s ', 'tokens/sec: 14046.11 ', 'grad norm: 1.9740 ', 'train loss: 3.0307 ', 'val loss: 5.7499 ', 'val ppl: 314.1686 ', 'dt: 4.80s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:04:10] ('epoch 3 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.29s ', 'tokens/sec: 14046.43 ', 'grad norm: 1.2691 ', 'train loss: 2.2031 ', 'val loss: 4.3959 ', 'val ppl: 81.1191 ', 'dt: 3.11s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:04:10] Training finished.
wandb:
wandb:
wandb: Run history:
wandb: amp ▁▁▁▁▁
wandb: grad_norm ▆██▄▁
wandb: lr ▁▃▅▆█
wandb: step_time ▁█▇▇▆
wandb: tokens_per_sec █▁▂▂▃
wandb: train/loss █▆▅▃▁
wandb: val/loss █▆▅▃▁
wandb: val/ppl █▃▂▁▁
wandb:
wandb: Run summary:
wandb: amp 1
wandb: grad_norm 1.26913
wandb: lr 0.00015
wandb: step_time 0.2916
wandb: tokens_per_sec 14046.43304
wandb: train/loss 2.20305
wandb: val/loss 4.39592
wandb: val/ppl 81.11907
wandb:
wandb: 🚀 View run northern-sunset-7 at: https://wandb.ai/guoqizhou123123-tencent/rosetrainer/runs/tlne3zj3
wandb: ⭐️ View project at: https://wandb.ai/guoqizhou123123-tencent/rosetrainer
wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20251202_200347-tlne3zj3/logs
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm/rosetrainer$ ./train_gpt2_small_ddp.sh
W1202 20:04:22.473000 2780229 site-packages/torch/distributed/run.py:792]
W1202 20:04:22.473000 2780229 site-packages/torch/distributed/run.py:792] *****************************************
W1202 20:04:22.473000 2780229 site-packages/torch/distributed/run.py:792] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W1202 20:04:22.473000 2780229 site-packages/torch/distributed/run.py:792] *****************************************
wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: Currently logged in as: guoqizhou123123 (guoqizhou123123-tencent) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: Tracking run with wandb version 0.19.8
wandb: Run data is saved locally in /data/projects/rosellm/rosellm/rosetrainer/wandb/run-20251202_200425-q6y5u4li
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run still-wood-8
wandb: ⭐️ View project at https://wandb.ai/guoqizhou123123-tencent/rosetrainer
wandb: 🚀 View run at https://wandb.ai/guoqizhou123123-tencent/rosetrainer/runs/q6y5u4li
[2025-12-02 20:04:26] Training started at 2025-12-02 20:04:26
[2025-12-02 20:04:26] [rank 0] Using device: cuda:0
[2025-12-02 20:04:26] Arguments: Namespace(vocab_size=50257, max_position_embeddings=1024, n_layers=12, n_heads=12, d_model=768, d_ff=3072, dropout=0.1, use_tensor_parallel=False, use_activation_checkpoint=False, batch_size=2, seq_len=1024, num_steps=50, lr=0.0003, no_amp=False, checkpoint_path='checkpoints/gpt2_small_ddp.pt', resume=False, lr_scheduler='cosine', warmup_steps=100, use_profiler=False, seed=42, grad_accum_steps=2, grad_clip_norm=1.0, train_data=['data/train.txt'], val_data=[], val_ratio=0.001, data_mode='text', train_npy=[], val_npy=[], tokenizer_name='gpt2', use_toy_data=False, max_tokens=100000, data_seed=42, use_wandb=True, wandb_project='rosetrainer', wandb_run_name=None)
total files: 1
total tokens: 100000
total files: 1
total tokens: 100000
[2025-12-02 20:04:28] train dataset size: 96
[2025-12-02 20:04:28] val dataset size: 1
[2025-12-02 20:04:28] steps per epoch: 24
[2025-12-02 20:04:28] [rank 0] Starting from scratch
[2025-12-02 20:04:34] ('epoch 1 step 10 / 50 ', 'lr: 0.000033 ', 'step time: 0.55', 'toks/s (per rank): 7396.99', 'grad norm: 2.0187 ', 'train loss: 5.0777 ', 'val loss: 9.8426 ', 'val ppl: 18817.6630 ', 'dt: 5.77s ', 'eta: 0.01h ', 'amp: True')
[2025-12-02 20:04:41] ('epoch 2 step 20 / 50 ', 'lr: 0.000063 ', 'step time: 0.55', 'toks/s (per rank): 7419.99', 'grad norm: 2.6765 ', 'train loss: 4.2946 ', 'val loss: 8.5512 ', 'val ppl: 5172.7062 ', 'dt: 7.24s ', 'eta: 0.01h ', 'amp: True')
[2025-12-02 20:04:47] ('epoch 3 step 30 / 50 ', 'lr: 0.000093 ', 'step time: 0.55', 'toks/s (per rank): 7405.65', 'grad norm: 2.5235 ', 'train loss: 3.6666 ', 'val loss: 7.2297 ', 'val ppl: 1379.7863 ', 'dt: 5.55s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:04:54] ('epoch 4 step 40 / 50 ', 'lr: 0.000123 ', 'step time: 0.55', 'toks/s (per rank): 7385.33', 'grad norm: 1.8517 ', 'train loss: 2.8361 ', 'val loss: 5.6246 ', 'val ppl: 277.1675 ', 'dt: 7.24s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:05:00] ('epoch 5 step 50 / 50 ', 'lr: 0.000153 ', 'step time: 0.55', 'toks/s (per rank): 7426.97', 'grad norm: 1.2541 ', 'train loss: 2.1491 ', 'val loss: 4.2860 ', 'val ppl: 72.6787 ', 'dt: 5.55s ', 'eta: 0.00h ', 'amp: True')
[2025-12-02 20:05:00] Training finished.
wandb:
wandb:
wandb: Run history:
wandb: amp ▁▁▁▁▁
wandb: global_tokens_per_sec ▃▇▄▁█
wandb: grad_norm ▅█▇▄▁
wandb: lr ▁▃▅▆█
wandb: tokens_per_sec_per_rank ▃▇▄▁█
wandb: train/loss █▆▅▃▁
wandb: val/loss █▆▅▃▁
wandb: val/ppl █▃▁▁▁
wandb:
wandb: Run summary:
wandb: amp 1
wandb: global_tokens_per_sec 14853.93592
wandb: grad_norm 1.25406
wandb: lr 0.00015
wandb: tokens_per_sec_per_rank 7426.96796
wandb: train/loss 2.14906
wandb: val/loss 4.28605
wandb: val/ppl 72.67867
wandb:
wandb: 🚀 View run still-wood-8 at: https://wandb.ai/guoqizhou123123-tencent/rosetrainer/runs/q6y5u4li
wandb: ⭐️ View project at: https://wandb.ai/guoqizhou123123-tencent/rosetrainer
wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20251202_200425-q6y5u4li/logs
(/data/projects/rosellm/.conda) wine@wine-MS-7D90:/data/projects/rosellm/rosellm/rosetrainer$