从零实现 LLM Training:025. Init
本 PR 是为了解决训练模型初始化的问题,之前我们的模型使用的是 pytorch 默认的初始化方式,我训练发现初始的 loss 以及 ppl 会很离谱,而且中间可能出现 NaN,并且 grad_norm 开始时会比较大,例如:
[2025-12-04 11:22:47] ('epoch 1 step 100 / 12000 ', 'lr: 0.000030 ', 'step time: 0.58', 'toks/s (per rank): 7027.40', 'grad norm: 7.6670 ', 'train loss: 26.4076 ', 'val loss: 49.8278 ', 'val ppl: 4364430704881726128128.0000 ', 'dt: 76.89s ', 'eta: 2.54h ', 'amp: True')
正常来说,最开始随机从 vocab 里面猜,对应的 loss 应该是 -log(V),对于 GPT2 词表大小 50257,这个值大概就是 10.82 这个样子。
所以目前这个值明显有点太离谱了。研究了一下主要原因还是模型初始化问题,在 GPT2 官方代码上,主要的 trick 是以下两点:
- 每个 weight 是按照 std 为 0.02 来做初始化的
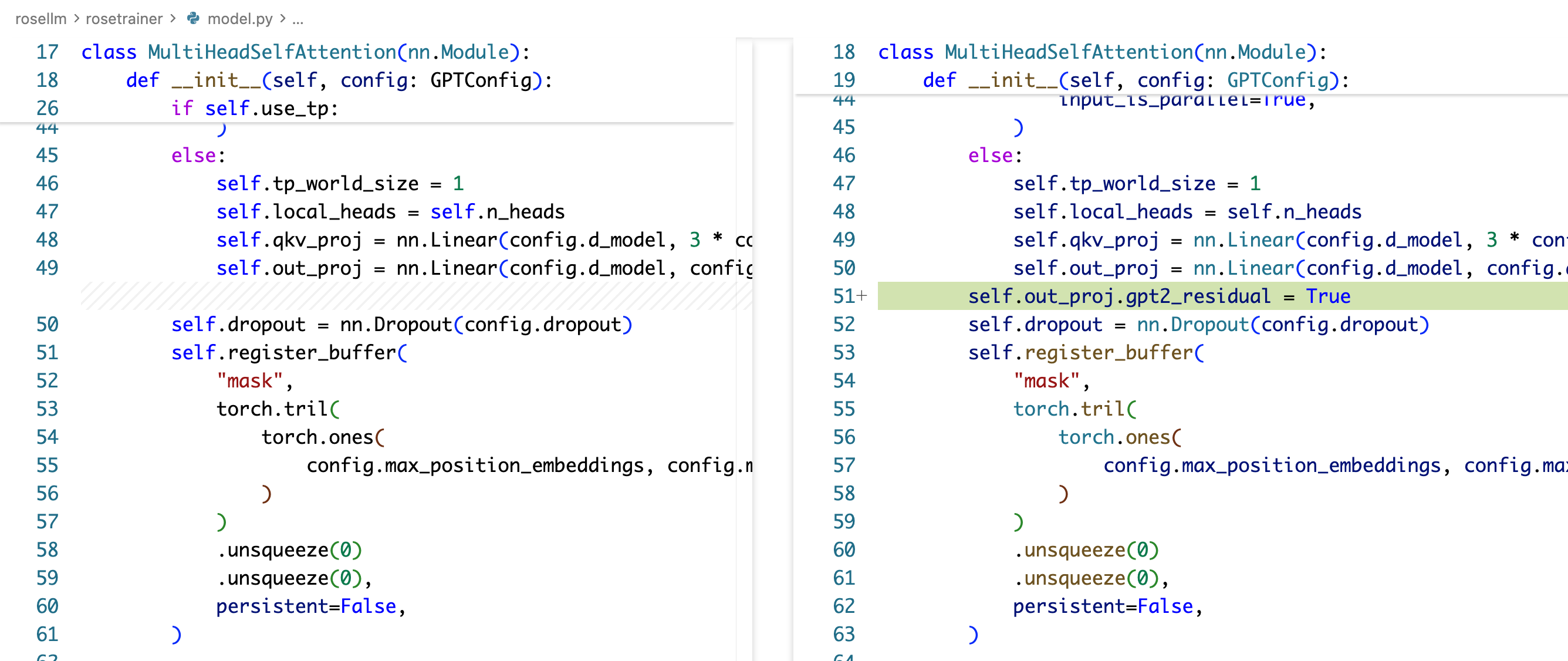
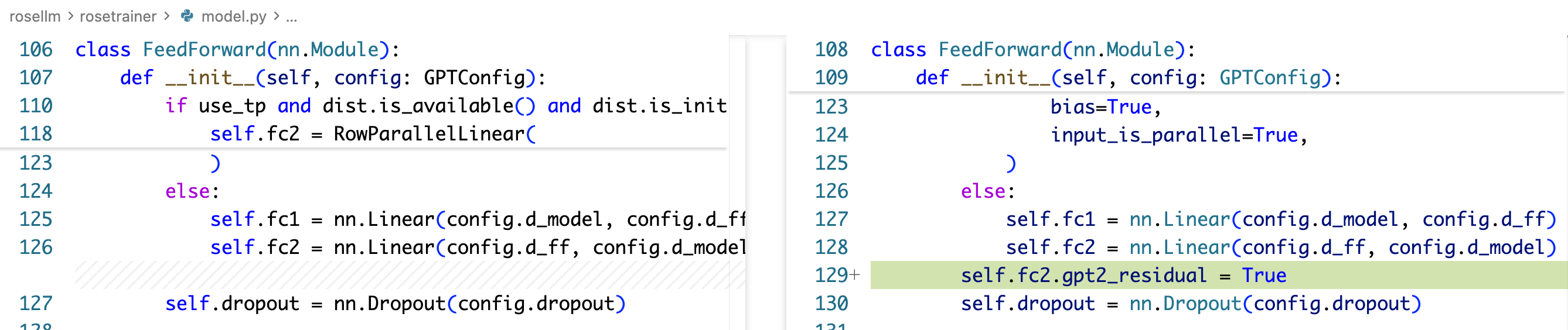
- 在每个 residual add 之前的那个 projection weight 上,会再额外乘上 1/sqrt(2L),其中 L 是总层数,2L 是因为每层有两个 residual add:attention block 最后有一个,ffn block 最后有一个,最后对应实际上就是 attention 的 Wo 权重矩阵的初始化要额外乘上这个因子,ffn 的第二个 down projection 的权重矩阵的初始化要额外乘上这个因子
为什么是 0.02?这个值是一个比较保守的值,这里的理论实际上是每次经过一个矩阵乘法之后,要期望输出的方差能够约等于输入,而输出的方差会是输入方差乘上 d_model(假设矩阵的输入输出都是 d_model),为了让方差稳定,权重矩阵需要乘上 1/sqrt(d_model),对于 GPT2-small 来说,d_model = 768,对于更大的以及现代的模型,d_model 可以到 4096 乃至更大,对应的 1/sqrt(d_model) 大致就是 0.15-0.36(比如我们去看 deepseek v3,他的 d_model 是 7168,这个值算出来大概是 0.012,但是你翻他的 tech report 的话,会发现他用的 std 是 0.006)。
为什么需要额外乘上 1/sqrt(2L)?这里是为了让 residual add 前后的方差稳定,这里需要一个简化,我们简化认为最终的 $y = x + \sum_i^{2L} f_i(x)$ ,然后简化认为 $f_i$ 的输出不改变输入的方差,那么最后的总的方差实际上是 $x$ 加上了一个方差为 $2L \sigma^2$ 的随机变量,为了使加上的这个随机变量的方差不会随着层数增加而爆炸,需要把权重乘上 $1/\sqrt{2L}$。
代码变更
rosellm/rosetrainer/model.py

运行
立竿见影,新跑了一个训练,其实的 loss,grad norm,ppl 都很稳:
[2025-12-04 14:28:06] ('epoch 1 step 100 / 12000 ', 'lr: 0.000030 ', 'step time: 0.58', 'toks/s (per rank): 7055.05', 'grad norm: 1.9290 ', 'train loss: 4.0217 ', 'val loss: 8.2791 ', 'val ppl: 3940.8372 ', 'dt: 76.92s ', 'eta: 2.54h ', 'amp: True')
打的 step 比较粗,第一个打印就是 100 step 了,train loss 以及到 4 了。