Codex 源码剖析:002. 工具、审批与沙箱
上一篇把一次用户输入从 TUI 追到了 run_turn。这一篇看 run_turn 里最危险、也最体现工程边界的部分:模型输出一个工具调用之后,Codex 如何判断它到底是什么工具、能不能并行、是否会修改环境、要不要审批、应该在哪个 sandbox attempt 下执行,以及如何把结果安全地喂回下一次模型请求。
如果只看 agent loop 的概念,它很短:
model -> action -> observation -> model
但 coding agent 的工程难点不在这行伪代码,而在 action 落地的一瞬间。模型说“运行测试”“改文件”“调用 MCP 工具”只是意图;真正执行时,系统必须重新回答一组更硬的问题:
- 模型看到的工具 schema 和真实 handler 如何分离?
- 哪些工具只读,哪些工具可能修改文件或启动进程?
- 并行工具调用如何避免互相踩状态?
- 审批和 sandbox 是每个工具自己判断,还是由统一 runtime 判断?
apply_patch、MCP、Apps、dynamic tools 这些形态能否共用同一条执行链?
本文使用的 Codex 源码版本仍是 openai/codex@ac4332c。OpenClaw 只作为对照系统,用来说明另一种 gateway-first 的执行边界。
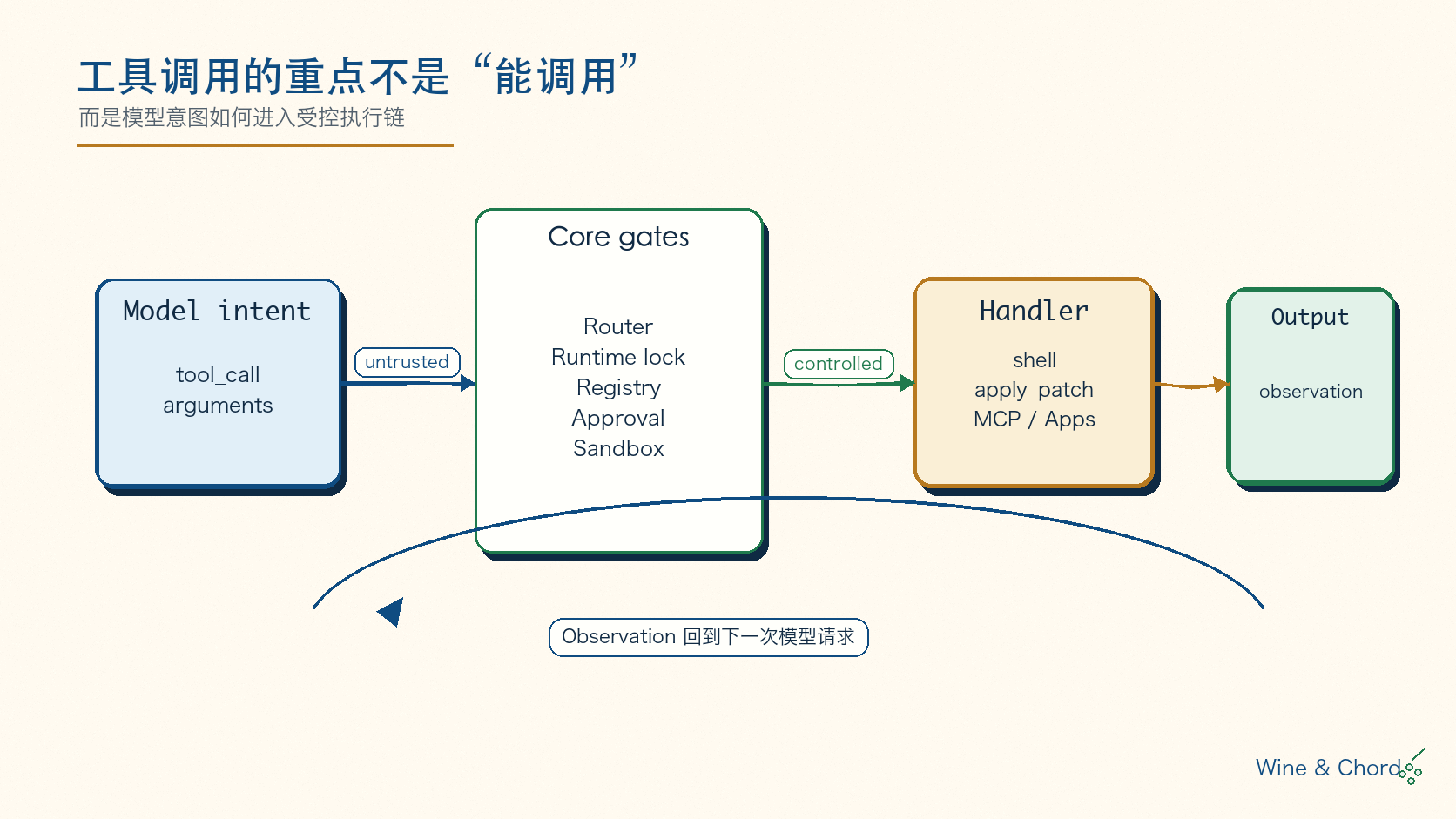
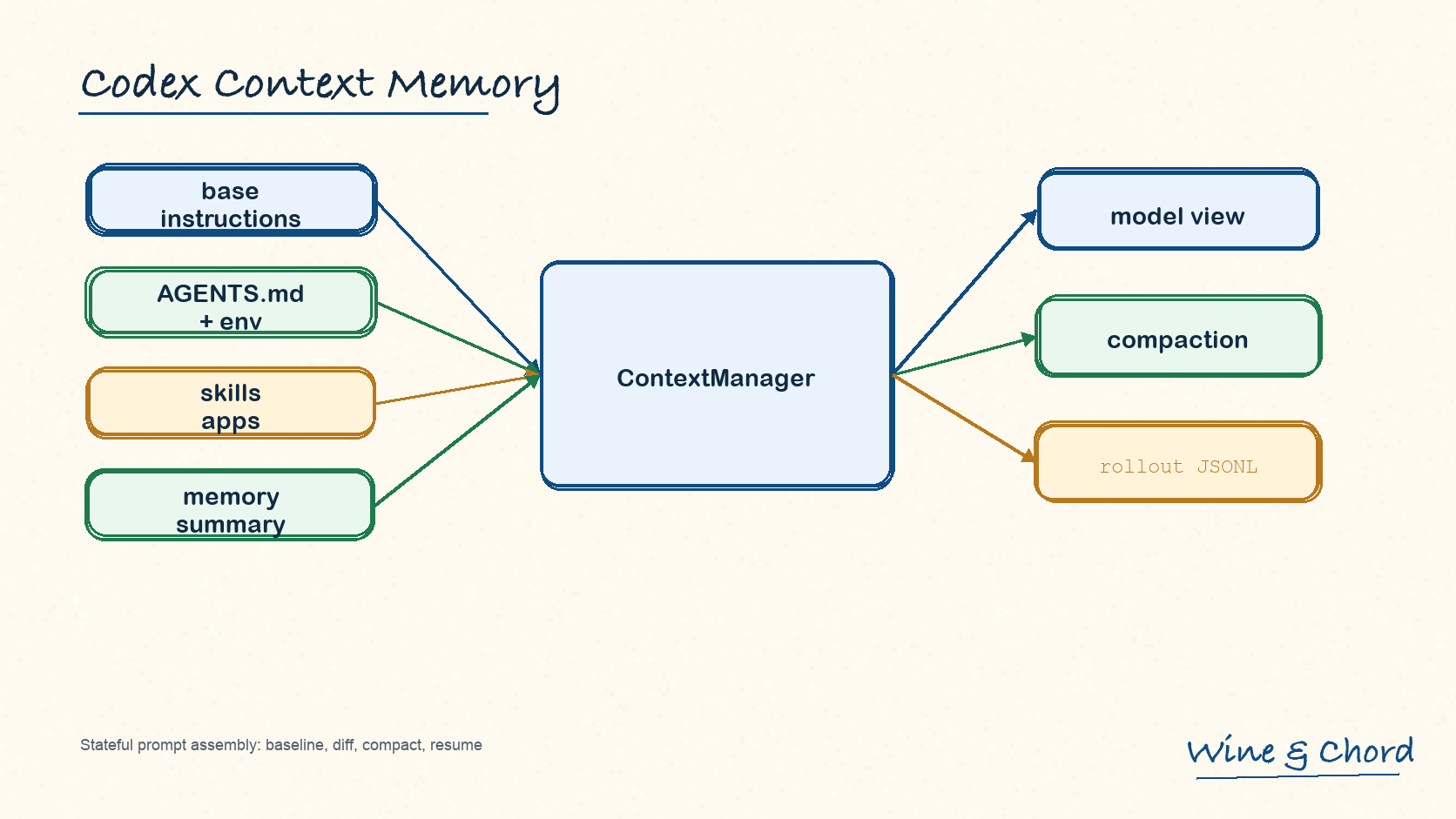
图 1. 模型只发出工具调用意图;是否能执行、如何执行、以什么权限执行,由 core 工具运行时分层决定。
阅读契约
读这篇时不要把“工具调用”理解成“模型调用一个函数”。更稳的读法是连续问四件事:
- 模型本轮看见的
ToolSpec是怎么来的? - API 返回的
ResponseItem如何被还原成内部ToolCall? - 并行、mutating、hooks、approval 和 sandbox 分别在哪一层收束?
- handler output 如何成为下一次模型请求里的 observation?
只要这四个问题分开,Codex 的工具系统就不再是一团“大 switch”,而是一条从 model-visible schema 到受控执行结果的约束流水线。
一、先区分 spec、call、handler
1.1 模型看到的是 ToolSpec
先看总图。它不是一个“大 switch”,而是一条从 model-visible spec 到 handler output 的约束流水线。
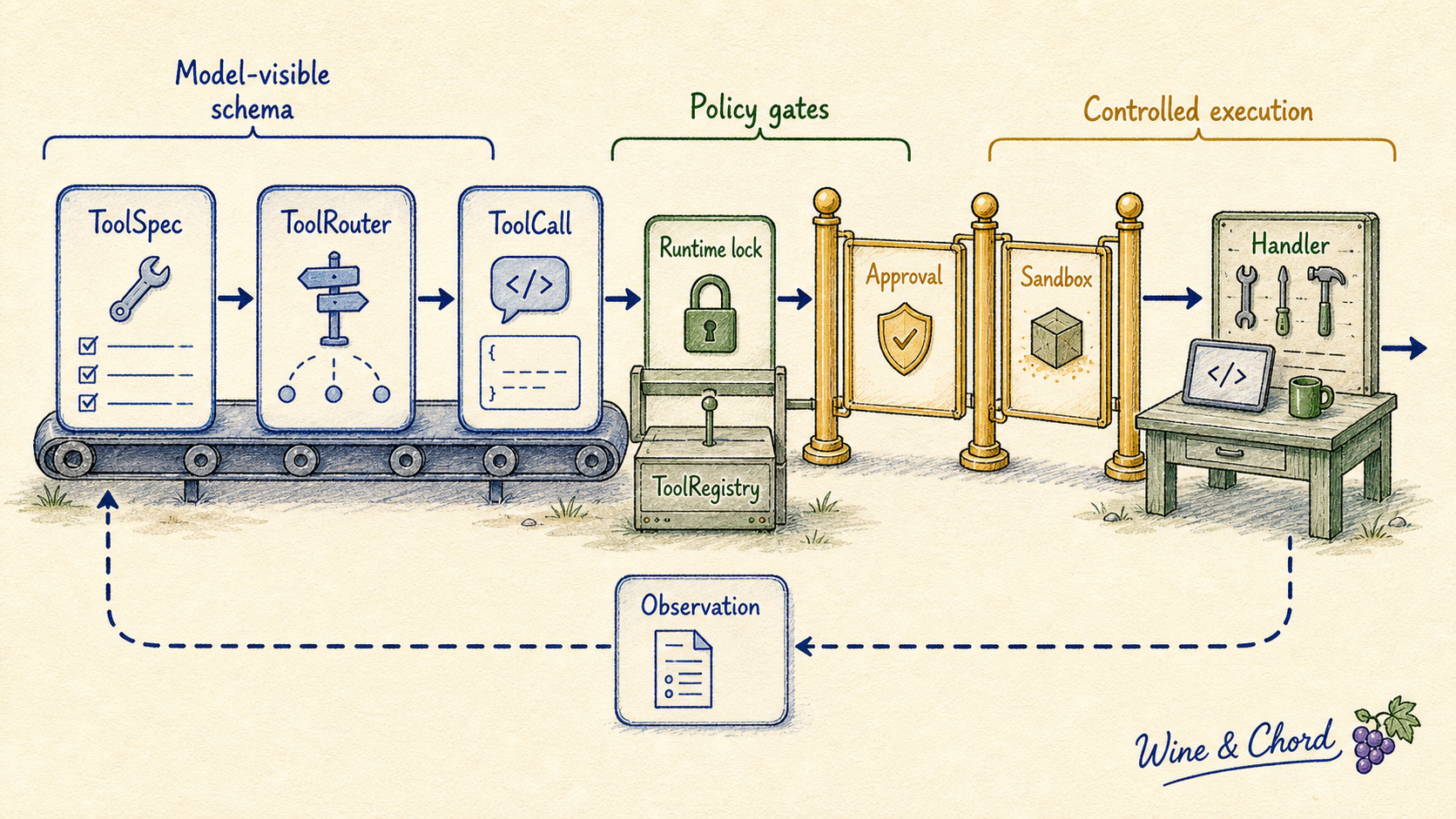
图 2. 模型只看到工具 schema;core 侧才知道 handler、审批、沙箱、并发和 hooks。读源码时可以先沿着 ToolRouter::build_tool_call 到 ToolRegistry::dispatch_any 这条线走。
工具在 build_prompt 时注入模型请求。上一篇提到,Prompt.tools 来自 router.model_visible_specs(),不是直接来自某个 handler。OpenAI 的 tools 文档讲的是 API 层的工具能力;Codex 源码里更重要的是:API 层的工具 schema 必须和本地执行语义分开。
工具集合的构造在 build_specs_with_discoverable_tools。这里会把几类工具来源统一规划:
- 内置工具,例如
apply_patch、view_image、unified_exec - MCP / Apps 工具
- deferred MCP tools
- dynamic / discoverable tools
- 多 Agent 工具
tool_search/tool_suggest
规划结果分成两类:model-visible ToolSpec 和 core-side ToolHandler。这个分离是整套工具系统的第一条边界。模型需要知道的是“我可以调用什么,参数 schema 是什么”;core 需要知道的是“谁来处理、是否支持并行、是否可能修改环境、是否要过审批和 sandbox、失败如何反馈给模型”。
ToolRouter 保存 registry、所有 spec、模型可见 spec、允许并行的 MCP server 集合,见 ToolRouter。from_config 里还会过滤 deferred dynamic tools,避免还没加载的工具直接暴露给模型。
这解释了 Codex 为什么能支持 lazy tool discovery:工具世界可以很大,但模型每轮看到的工具集合应该尽量小、尽量确定。
1.2 Router 把 API 输出还原成内部 ToolCall
模型流里出现 OutputItemDone 时,Codex 调 handle_output_item_done。这里先调用 ToolRouter::build_tool_call,把不同形态的 ResponseItem 还原为内部 ToolCall:
FunctionCall:普通 function tool;如果命中 MCP tool info,则转成ToolPayload::McpToolSearchCall:客户端执行的tool_searchCustomToolCall:Responses API custom toolLocalShellCall:转换成local_shell
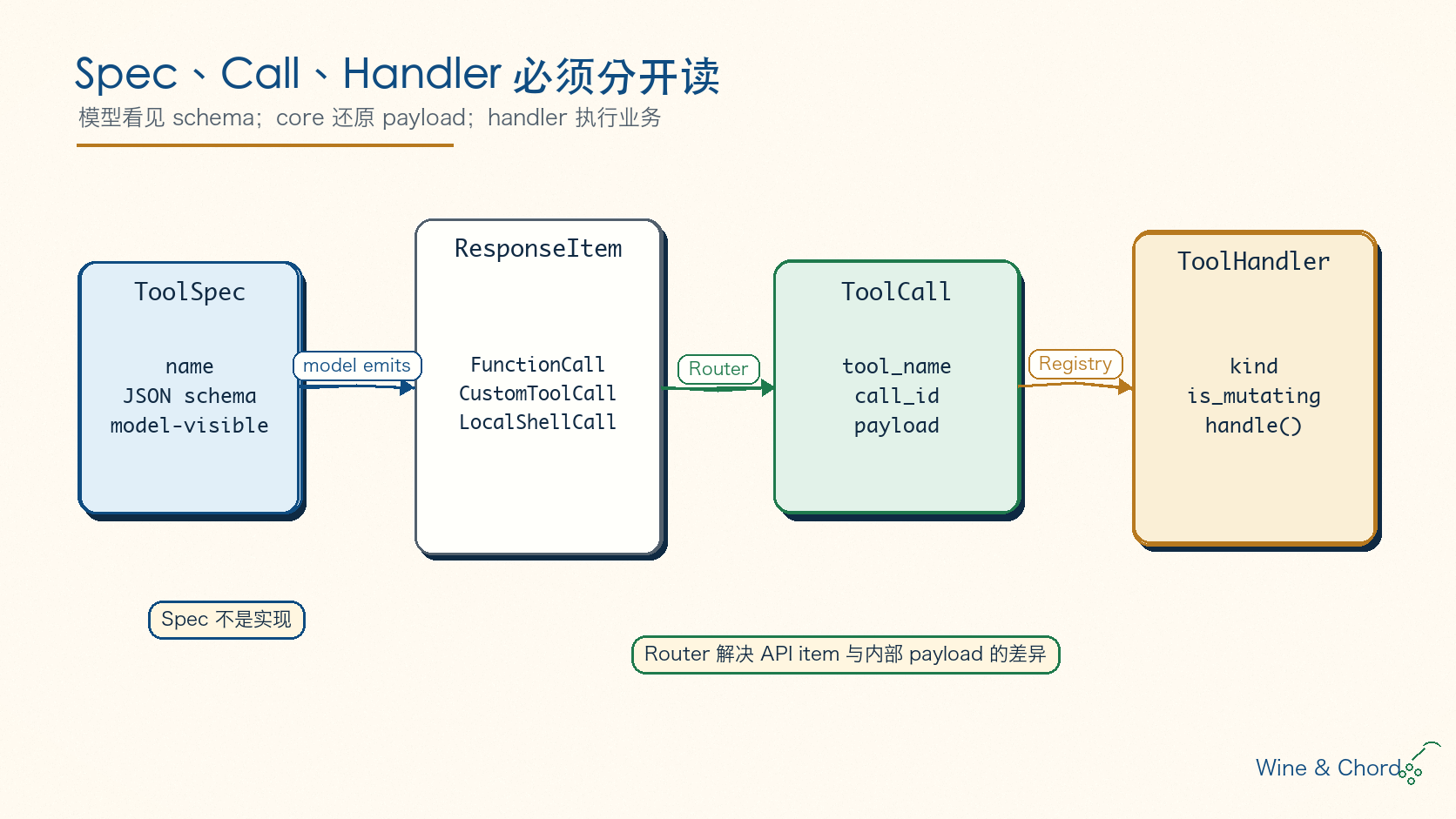
图 3. ToolSpec 是模型可见 schema,ResponseItem 是 provider API 输出,ToolCall 是 core 统一执行形态,ToolHandler 才是真正的业务实现。
对应逻辑在 ToolRouter::build_tool_call。这个转换层的价值是稳定后续执行链。模型 API 可以用多种方式表达工具调用,但 registry、runtime、approval 和 handler 不应该到处判断 ResponseItem 类型。后面统一处理 ToolCall { tool_name, call_id, payload } 就够了。
MCP payload 也说明了为什么 router 不能省。MCP Tools 规范把 tool 描述为有 name、description、inputSchema 等元数据的 server capability;但 Codex 暴露给模型的 MCP tool name 可能经过清洗、去重或 hash,以适配 API 命名限制。执行时却必须知道原始 server/tool。Codex 在 router 阶段把它还原为 server + raw tool name + raw arguments,后面的 MCP handler 才能准确调用对应 server。
1.3 Handler 声明语义,不重写全局策略
真正执行工具的是 ToolHandler。但 handler 不应该自己重写一遍全局策略。ToolHandler trait 的扩展点包括 kind、matches_kind、is_mutating、pre_tool_use_payload、post_tool_use_payload、create_diff_consumer、handle,见 ToolHandler。
这组方法说明 handler 的职责边界:它声明自己处理什么 payload,声明自己是否 mutating,提供 hook payload 和 diff consumer,最终执行具体工具逻辑。审批、并发、telemetry、trace、hooks 的编排不散落在每个 handler 里,而是由外层 runtime/registry/orchestrator 统一处理。
二、执行链上的每一道 gate
2.1 并行不是“模型说并行就并行”
进入 handler 之前,工具调用先过 runtime。下图把关键 gate 放在一条线上:
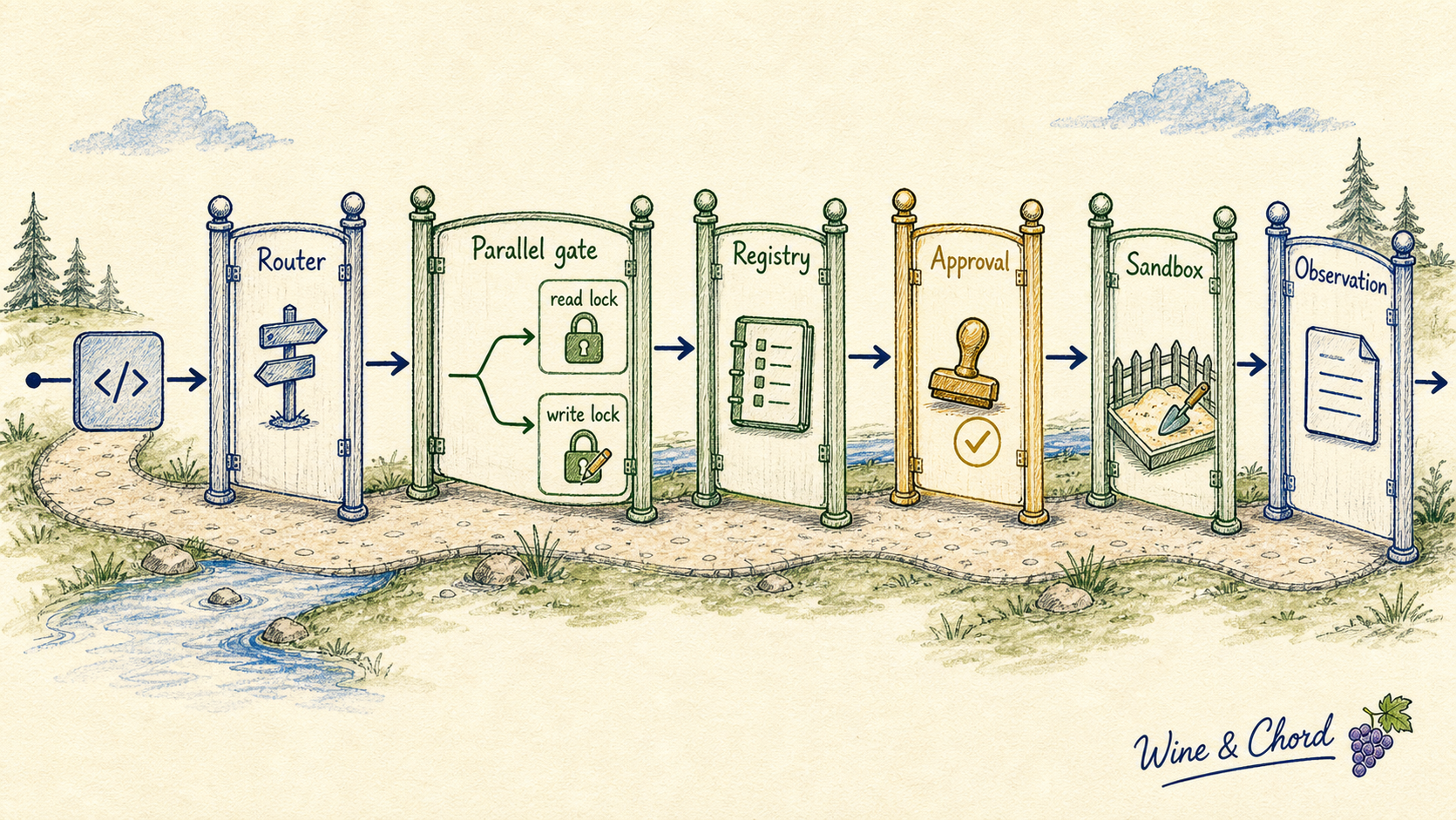
图 4. 模型给的是“我要调用某个工具”的意图;系统要在每一道门上重新确认“这个意图能不能以这种方式执行”。
ToolCallRuntime 是工具执行的外层 runtime。它有一个 parallel_execution: RwLock<()>,见 ToolCallRuntime。执行时先问 router:这个工具是否支持并行。支持并行的工具拿读锁,不支持并行的工具拿写锁,见 handle_tool_call_with_source。
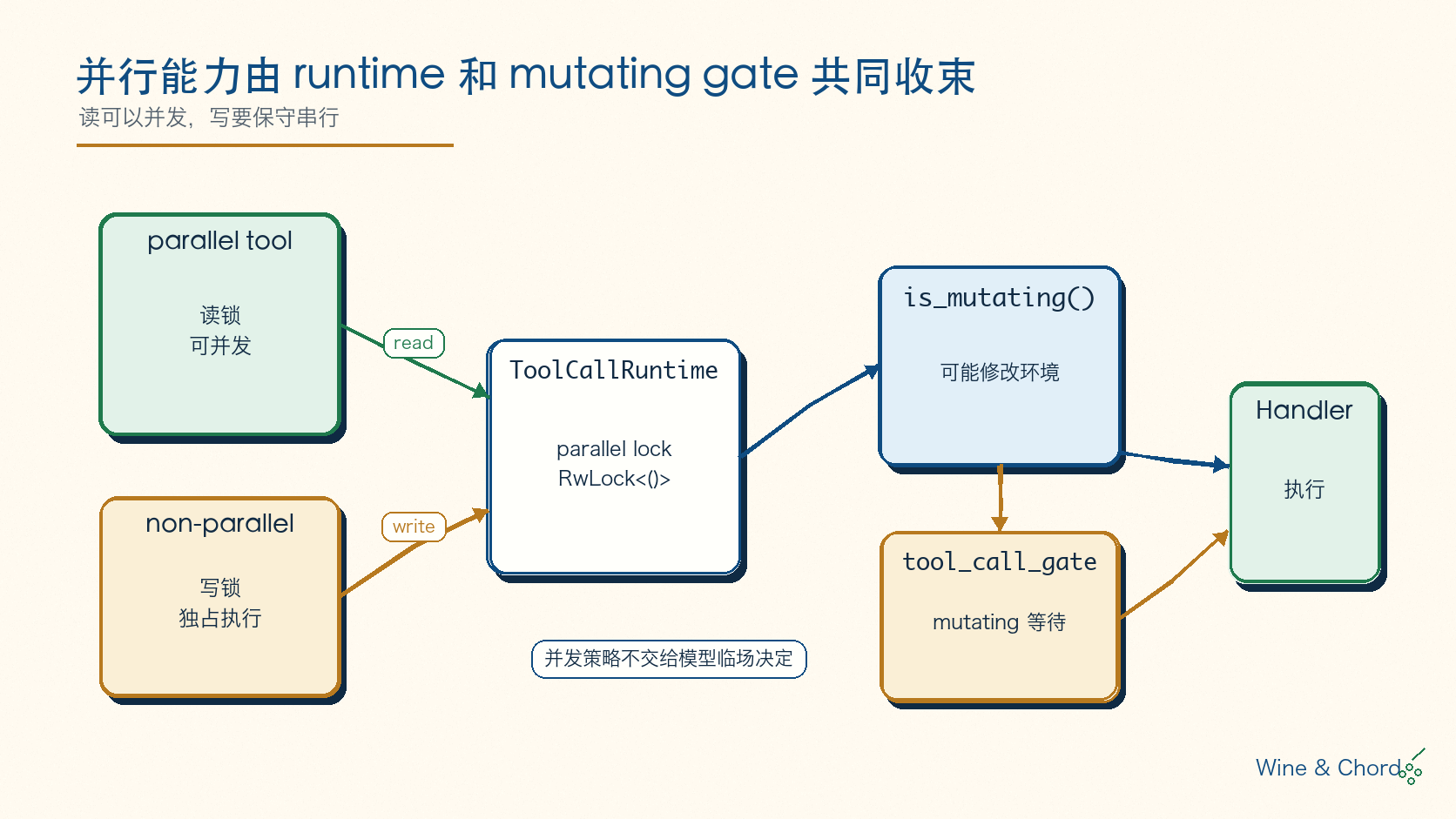
图 5. 读可以并发,写要保守串行;工具并行能力由 runtime 和 handler 语义共同决定。
这个设计不复杂,但工程上非常实用:只读查询、部分 MCP 工具可以并行;shell、patch、会改文件的工具通常应该串行;如果模型一次返回多个工具调用,runtime 不需要为每个工具写一套并发策略。
这里追求的不是极致吞吐,而是可解释的状态边界:读可以并发,写要保守串行。coding agent 面对的是一个真实工作区,错误并行不只是返回顺序不同,而是可能把文件、进程、审批请求和 trace 全部搅在一起。
2.2 Registry 统一处理 hooks、mutating gate 和输出回填
ToolRegistry::dispatch_any 是工具分发中心。源码可以从 dispatch_any 读起。它做的事情很多,但顺序很清楚:
- 找 handler。
- 检查 payload kind 是否匹配。
- 运行 pre-tool-use hooks。
- 调用
handler.is_mutating()判断是否可能修改环境。 - mutating 工具等待
tool_call_gate。 - 调用 handler。
- 运行 post-tool-use hooks。
- 记录 goal runtime、telemetry、trace。
- 把 handler output 转成模型能吃的
ResponseInputItem。
压成伪代码:
handler = registry.lookup(tool_name)
ensure payload kind matches handler kind
pre_result = run_pre_tool_use_hooks(handler, payload)
if pre_result blocks:
return blocked output
if handler.is_mutating():
wait for tool_call_gate
output = handler.handle(payload, runtime_context)
post_result = run_post_tool_use_hooks(handler, output)
record telemetry / trace
return output as ResponseInputItem
这里最值得注意的是 hooks 的身份。hooks 不是模型工具,而是工具执行链旁边的策略扩展点。pre hook 可以阻止执行;post hook 可以追加上下文、停止流程、替换反馈给模型的结果。这样 hooks 能影响 agent 行为,但不需要暴露成模型可调用工具。
这也是安全边界的一部分:模型工具调用是 untrusted input;用户配置的 hook command 是 trusted policy surface。两者必须分开看。
2.3 工具输出会回到下一次模型请求
工具执行完成后,结果不是只给 UI 看。handler output 会被规范化成 ResponseInputItem,追加进模型可见 history,再进入下一轮 build_prompt。这就是 ReAct 论文里 action/observation 交替的工程落地版本,但 Codex 需要把每个 observation 都放进协议、trace、审批和上下文预算里。
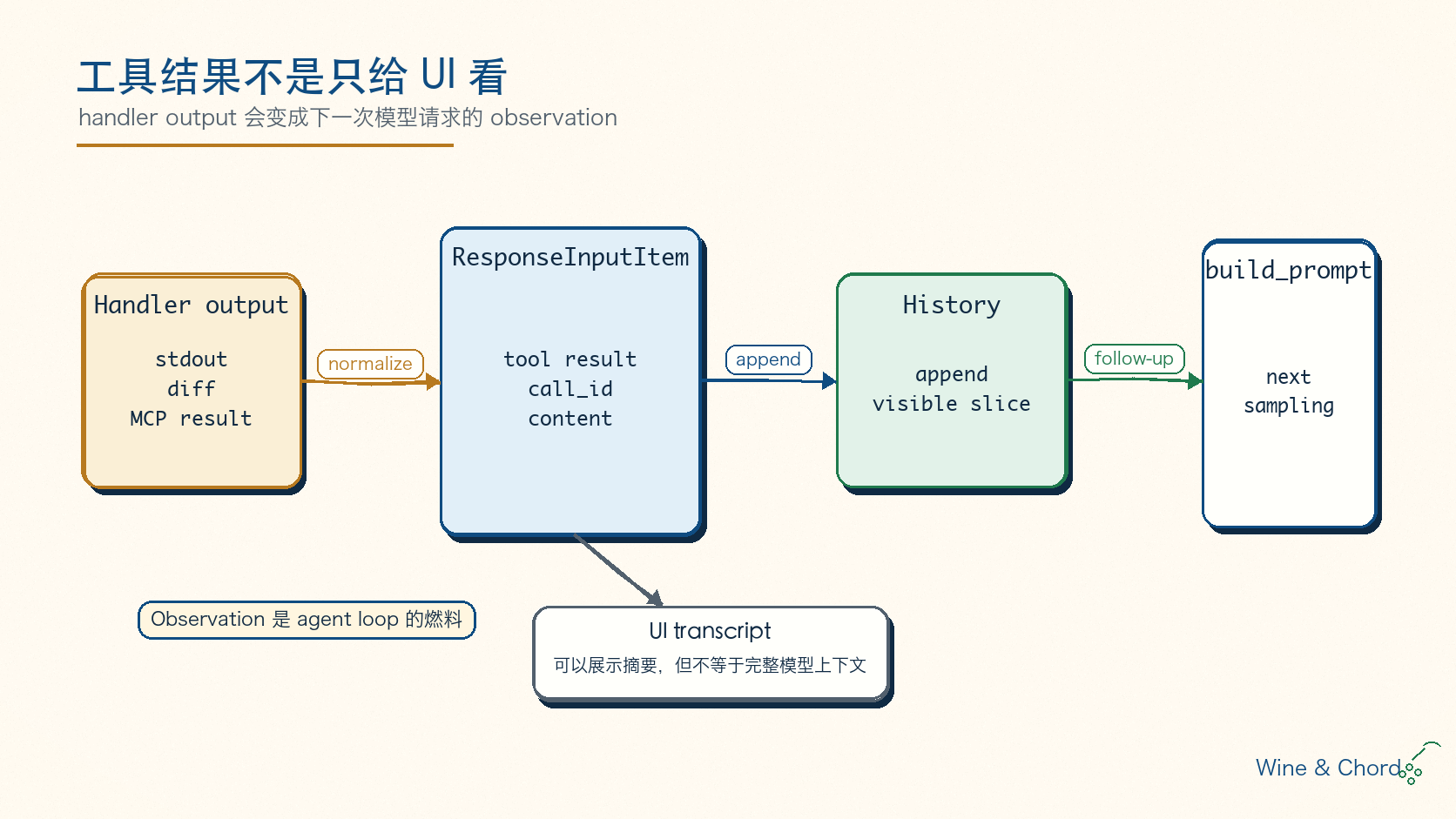
图 6. UI transcript 可以展示摘要,但模型下一次请求看到的是 core 维护的 history/projection。两者不能简单等同。
这也是为什么上一篇强调“turn 不等于一次模型请求”。工具输出如果需要 follow-up,就会推动 run_turn 再采样一次;如果没有工具调用、没有继续条件,turn 才收束。
三、approval 和 sandbox 集中在 orchestrator
如果每个工具都自己写“判断审批、尝试 sandbox、失败后提示用户、用户允许再重试”,最后一定会漂移。Codex 把这套逻辑集中到 ToolOrchestrator 和 sandboxing.rs。
sandboxing.rs 里有一个核心枚举:ExecApprovalRequirement。它把执行前状态分成三类:
Skip:不需要审批,可能还带bypass_sandbox。NeedsApproval:需要用户或 guardian 审批。Forbidden:直接禁止。
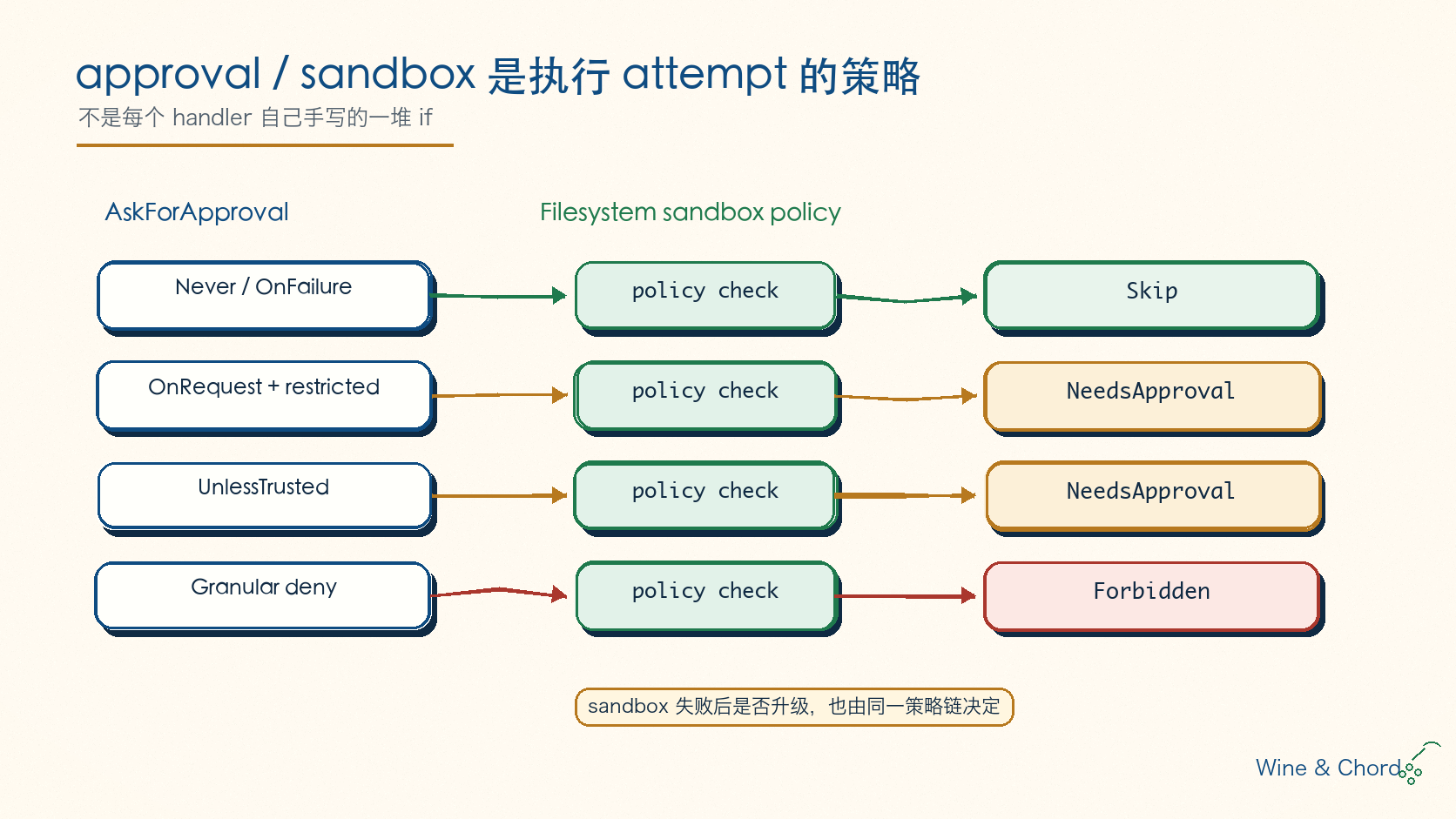
图 7. approval/sandbox 是执行 attempt 的策略,不是每个 handler 里各写一套 if/else。
默认判断在 default_exec_approval_requirement。它结合 AskForApproval 和 filesystem sandbox policy 得出是否需要审批。例如 Never、OnFailure 默认不问;OnRequest 在 restricted filesystem 下需要问;UnlessTrusted 总是问;granular policy 还可能禁止某些 prompt。
这层设计有两个好处。第一,审批逻辑是工具无关的,shell / unified exec / apply_patch 都能复用。第二,sandbox 不是一个布尔值,而是一次执行尝试的策略:初始 attempt 是否 sandbox、失败后是否允许升级、额外权限是否被批准。
OpenClaw 的取舍更偏 gateway-first。它的文档把 Gateway 放在 host 侧,工具执行可以下沉到 sandbox backend;backend 抽象再提供 exec spec、shell command 和 filesystem bridge 等能力,见 sandboxing.md 和 backend.ts。Codex 更像“core 工具运行时统一计算 approval/sandbox”,OpenClaw 更像“Gateway 控制面统一接入不同执行后端”。
两者的共同点是:shell 不是普通函数,必须被放进权限、隔离和审计边界里。
四、三个 handler 案例
4.1 Shell / Unified Exec:终端执行不是 Command::new 的包装
Codex 里有多条 shell 相关路径。传统 shell handler 会先把参数转成 ExecParams,再进入执行策略。ExecParams 里关键字段包括 command、cwd、env、network policy、sandbox permissions、Windows sandbox level,对应转换在 ShellHandler::to_exec_params。
UnifiedExecHandler 面向更完整的终端交互场景:exec_command 可以启动命令会话,write_stdin 可以向已有 session 写入输入,见 ExecCommandArgs。
这些字段可以分成几组:命令形态、执行位置、输出预算、权限请求和用户说明。UnifiedExecHandler::handle 执行前还会解析 cwd、可能触发 implicit skill invocation、分配 process id、派生实际 shell command、计算输出截断预算、应用 turn permissions、校验额外权限请求、拦截 apply_patch,再交给 UnifiedExecProcessManager,见 UnifiedExecHandler::handle。
coding agent 的 shell 是模型影响真实工作区的主要入口,所以它必须同时考虑可恢复交互、TTY、输出截断、审批、sandbox、权限升级、事件流和用户可见性。
4.2 apply_patch 是一等工具,不是 shell 字符串
很多 agent 会把文件编辑做成“让模型生成 shell 命令”。Codex 没这么做。
apply_patch 有独立 handler,主入口在 handlers/apply_patch.rs。同时 shell / unified exec 中如果检测到 apply_patch 命令,还会走 intercept_apply_patch。
这个拦截很关键。否则模型可以把 patch 塞进 shell,绕过 patch 工具的语义、文件级审批、diff tracking 和安全评估。
apply_patch 一等化带来的收益是:patch 可以被解析成结构化文件修改,审批可以按文件级别处理,TUI / app-server 可以展示 diff,rollout / trace 可以准确记录“修改了什么”,shell 也不用承担所有文件编辑语义。
换句话说,Codex 不只关心“最终文件变了”,还关心“这个变更通过什么语义边界产生”。
4.3 MCP / Apps:外部工具也要进入同一条链
MCP 工具同样走 router/handler/runtime 边界。Router 会把 model-visible MCP tool name 还原成 server/tool/raw_arguments。MCP handler 本身不实现业务,而是把调用交给 MCP connection manager。MCP 调用生命周期在 mcp_tool_call.rs:开始事件、approval、执行、结束事件都在这里。
MCP Tools 规范特别强调 tool 是 server 暴露的能力,客户端仍应在敏感操作上提供清晰 UI 和用户确认。这和 Codex 的工具链正好对应:MCP server 给 capability,Codex core 决定本轮怎么暴露、怎么审批、怎么执行、怎么把结果回填给模型。
Apps 是特殊 MCP server,也就是 codex_apps。app connector 的可用性、是否 enabled、tool approval policy、tool search lazy loading,都不是模型自己决定的,而是由 config、connector state 和 app-server protocol 共同决定。
这和传统“给模型一个 tools 数组”不同。Codex 需要处理的不是几十个静态函数,而是动态出现的插件、MCP server、connector、deferred tools。tool_search / tool_suggest 的存在,就是为了在工具空间很大时,仍然让模型只在需要时展开能力。
五、源码阅读规则
| 问题 | 正确读法 | 反例 |
|---|---|---|
| 模型“会用工具”意味着什么? | 它只看见 ToolSpec,不知道真实 handler。 |
把 spec 当成执行实现。 |
| 工具名为什么要经过 router? | API item 要还原成内部 ToolCall 和准确 payload。 |
在每个 handler 里解析 ResponseItem。 |
| 为什么需要 runtime lock? | 工具并行必须由工具属性和状态风险决定。 | 模型一次返回多个调用就全部并发。 |
| hooks 属于谁? | hooks 是 trusted policy surface,不是模型工具。 | 把 hook 当成模型可自由调用的能力。 |
| approval/sandbox 放在哪里? | 放在统一 orchestrator/policy,供多个工具复用。 | 每个 handler 自己判断权限。 |
apply_patch 为什么特殊? |
文件修改需要结构化语义、diff 和审批。 | 让模型通过 shell 自由写 patch。 |
| 工具输出到哪里去? | 转成 ResponseInputItem,进入下一次模型请求。 |
只当作 UI transcript 里的展示文本。 |
这张表也是后续读 Codex 工具代码的最小 checklist:先找 spec,再找 router,再看 runtime/registry gate,再看 approval/sandbox,最后才看具体 handler。
小结
Codex 的工具系统不是“模型调用函数”的薄包装。它把工具意图拆成几层:ToolSpec 是模型可见 schema,ToolRouter 把模型输出还原成内部 ToolCall,ToolCallRuntime 处理取消和并行,ToolRegistry 统一 handler 分发和 hooks,ToolOrchestrator / sandboxing 集中审批和 sandbox attempt,最后才是 shell、unified exec、apply_patch、MCP、dynamic tools 各自执行。
这套结构的代价是调用链长、类型多;收益是安全策略、观测、并发和扩展不会散落到每个工具里。对 coding agent 来说,这个取舍很现实:工具能力越强,越需要把“能力”和“约束能力的边界”一起设计。