Codex 源码剖析:003. 上下文、记忆与压缩
前两篇看了 turn loop 和工具系统。这一篇看 Codex 更容易被低估的一层:上下文工程。
很多 agent 失败不是因为不会调用工具,而是因为上下文没有边界。用户规则、项目文档、模型基线、权限策略、工具输出、长期记忆、压缩摘要和恢复日志一旦被混成“一段 prompt”,长会话里最先坏掉的就不是模型能力,而是状态语义。
本文基于 openai/codex 固定源码快照 ac4332c05b11e00ae775a24cb762edc05c5b5932,复核日期为 2026-06-11。平台契约以 OpenAI Responses API 和 Responses migration guide 为准,源码行号都指向该快照。
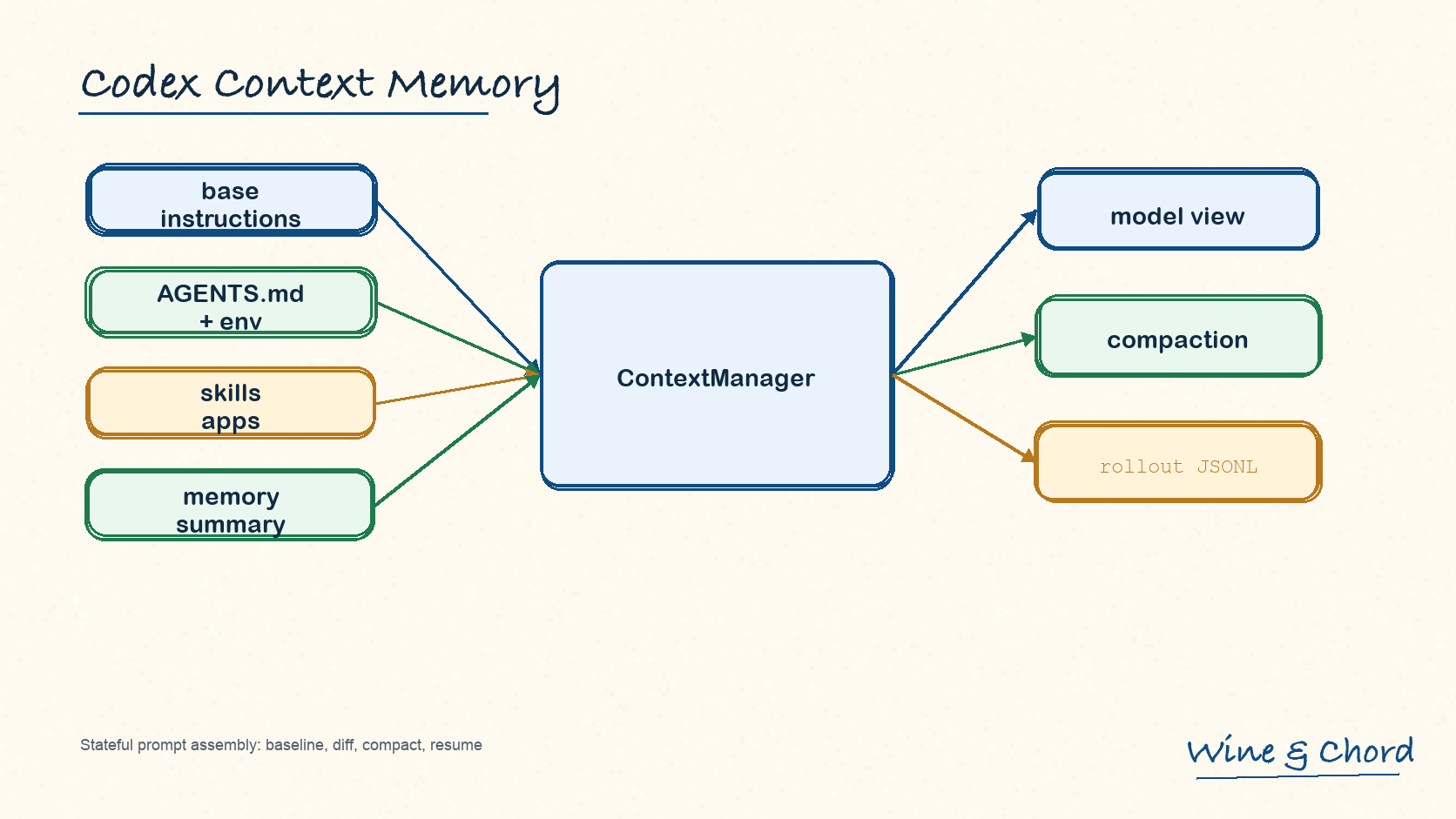
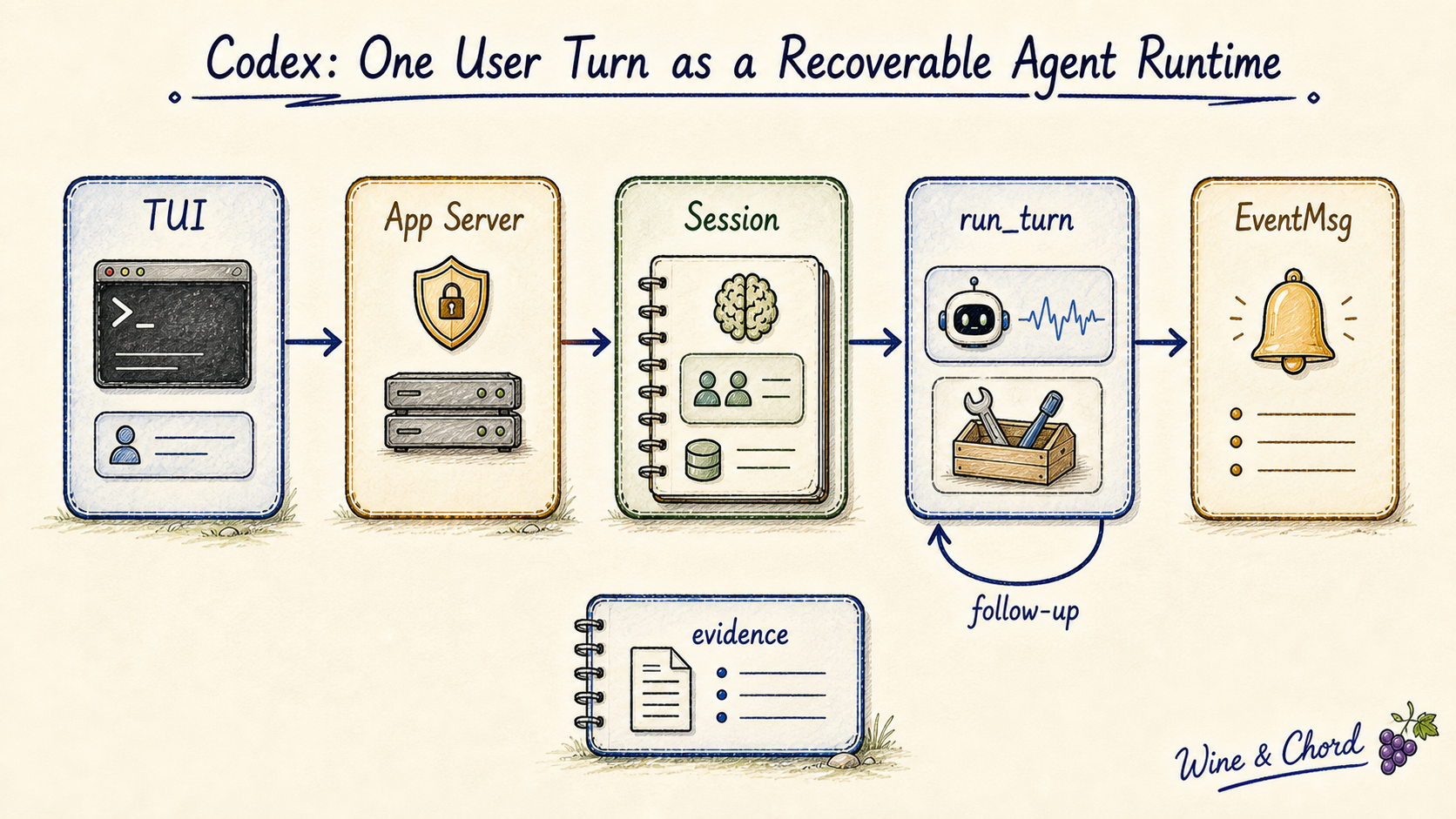
图 1. Codex 的 prompt 不是一段字符串,而是可追踪、可压缩、可恢复的状态系统。
阅读契约
这篇只回答一个问题:Codex 如何让模型每一轮看到足够上下文,同时又不把所有规则、能力、记忆和历史无条件塞进同一段 prompt?读完以后,应该能分清 provider contract、session baseline、model-visible context、history compression 和 durable recovery 五个视图。
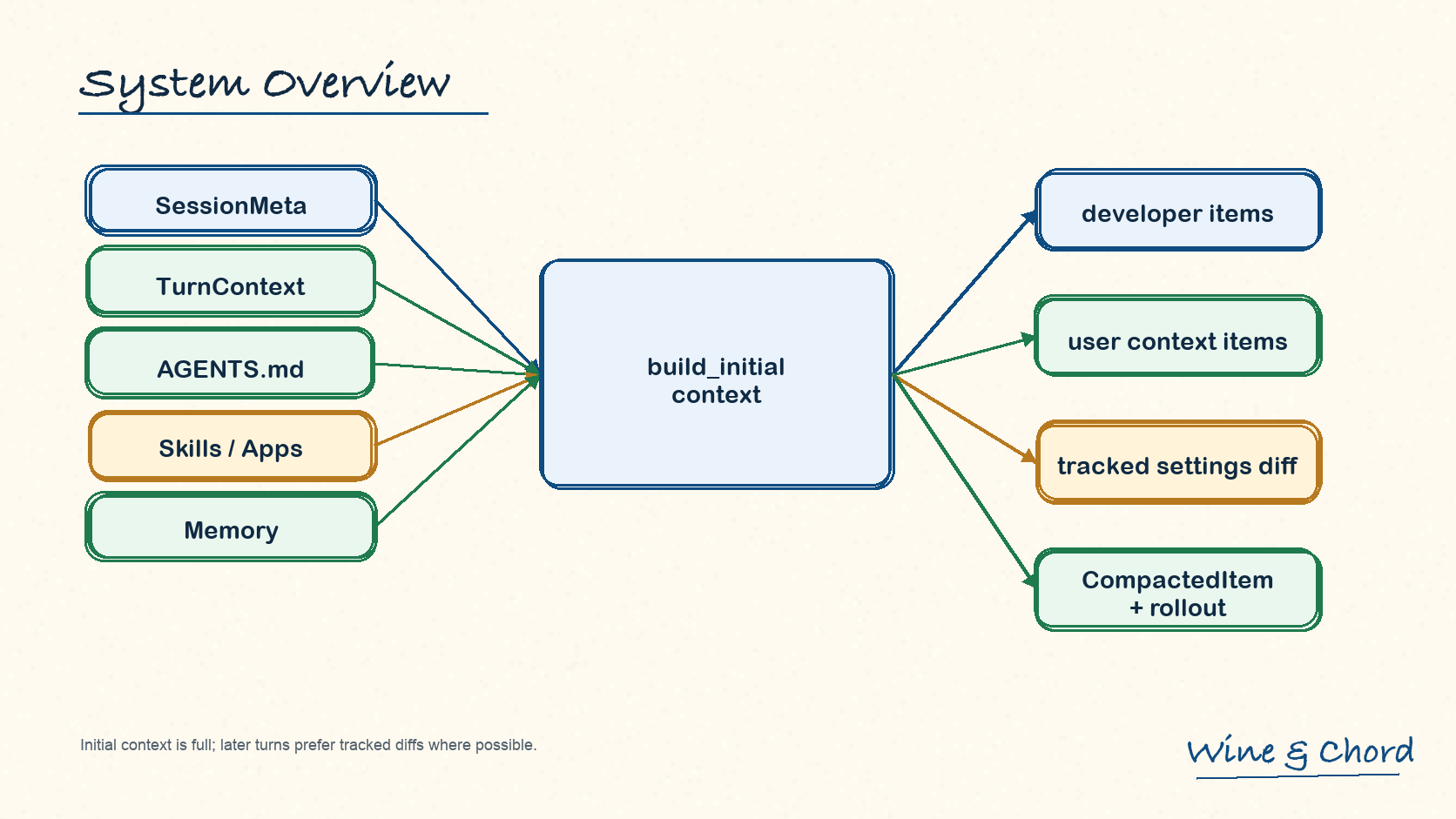
图 2. 上下文工程的核心不是“拼得更长”,而是把来源、角色、可变性和恢复路径分开。
一、Responses API 先划出两条通道
1.1 instructions 是稳定基线,input 是会话材料
Responses API 的公开表面把稳定指令和 conversation input 分开。Codex 继承这条边界:稳定基线走 base_instructions,动态上下文以 ResponseItem::Message 进入 conversation input。
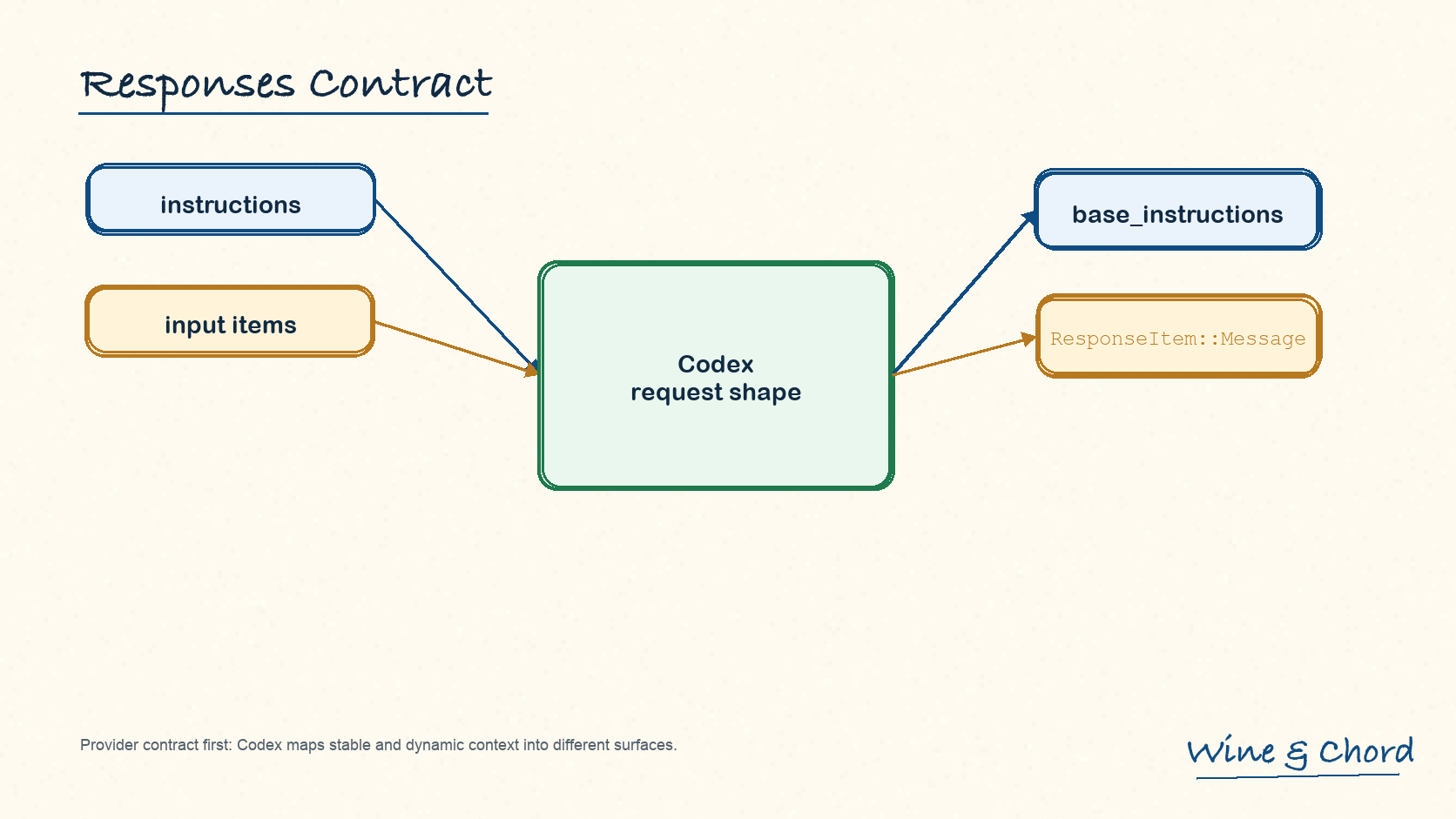
图 3. Provider contract 先规定两个表面;Codex 再决定哪些状态应该放进哪个表面。
稳定基线
base_instructions 不是每轮临时拼出来的文本。它属于 session configuration,是模型请求的稳定基线。
动态上下文
AGENTS.md、environment context、permissions update、model switch、memory read prompt、skills/apps/plugins 摘要会随着 turn context 变化。它们必须保留来源和 role,而不是混入同一块 system prompt。
1.2 分离带来三个后果
可以 diff
cwd、approval policy、realtime、model 变化时,Codex 可以基于 reference baseline 发 settings diff,而不是每轮重注入一大段上下文。
可以 compact
compaction 替换 history 时,Codex 需要知道哪些 initial context 要在特定阶段补回模型视图。
可以 resume
resume 不只是读回聊天记录,还要重建 history、previous turn settings、reference context baseline 和 surviving tail。
二、base_instructions 是 session 级基线
2.1 优先级在 Codex::spawn 里写死
Codex::spawn 选择 base_instructions 的顺序是:config override、rollout 里的 SessionMeta.base_instructions、当前模型默认 instructions。
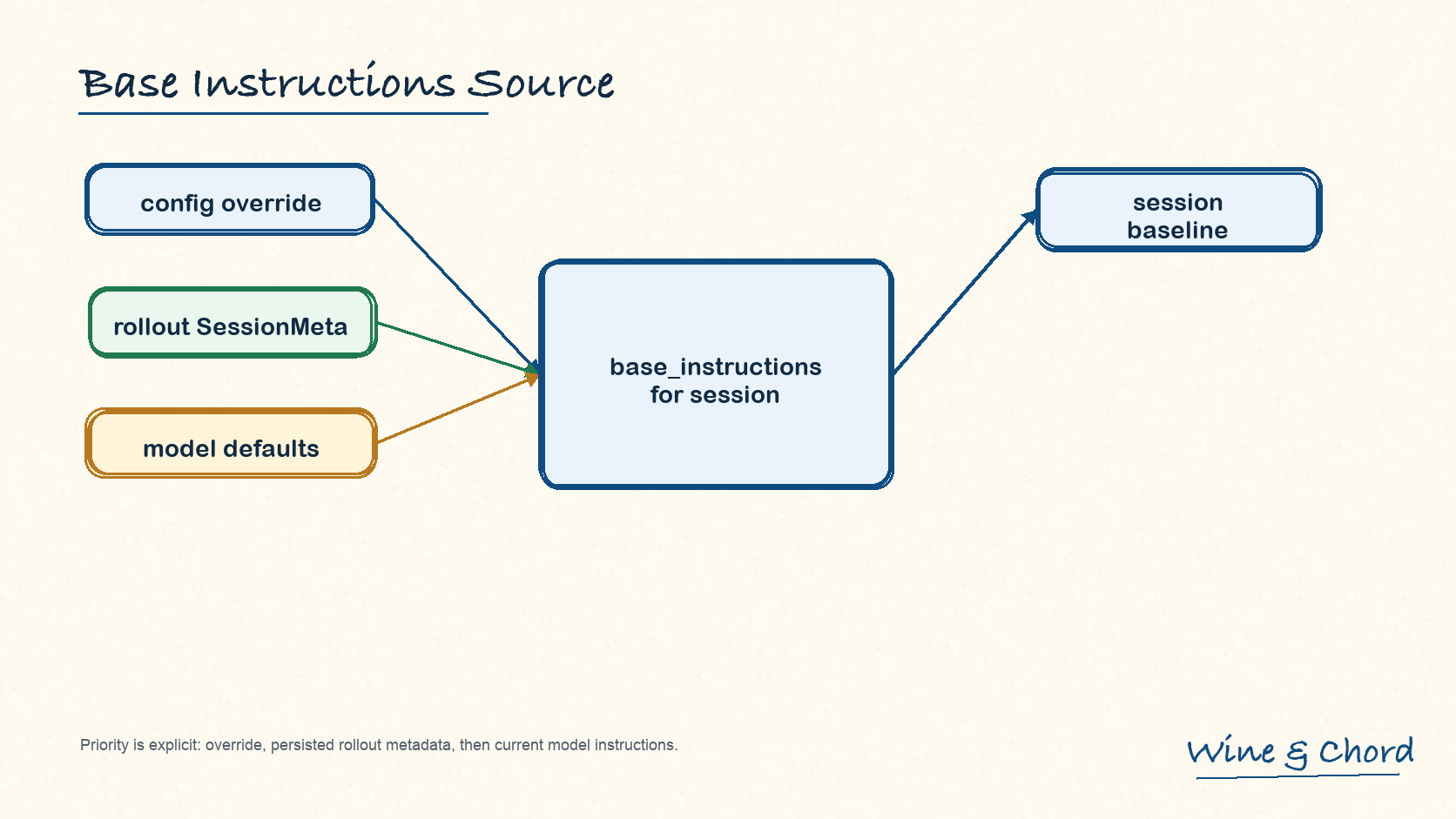
图 4. base_instructions 的优先级决定 resume/fork 时用哪个稳定基线,而不是让当前默认值覆盖过去会话。
config override
显式配置优先,适合受控环境或测试路径。
rollout metadata
恢复旧会话时,如果 rollout 保存了 SessionMeta.base_instructions,Codex 会优先使用过去记录的基线。
model defaults
只有前两者都没有时,才回退到当前模型信息渲染出的默认 instructions。
2.2 SessionMeta 与 TurnContextItem 分担恢复职责
RolloutItem 把 SessionMeta、ResponseItem、CompactedItem、TurnContext 和 EventMsg 放进同一个 tagged enum。
SessionMeta 解释起点
SessionMeta 保存 session-level 事实,例如 cwd、source、base instructions、dynamic tools、memory mode。
TurnContextItem 解释每个 turn
record_context_updates_and_set_reference_context_item 会在 regular user turn 后持久化 TurnContextItem。即使这轮没有 model-visible diff,resume 也能恢复最新 durable baseline。
三、首个真实 turn 才完整注入动态上下文
3.1 build_initial_context 产出两类 message
build_initial_context 先收集 developer sections 和 contextual user sections,再分别构造成 ResponseItem::Message。
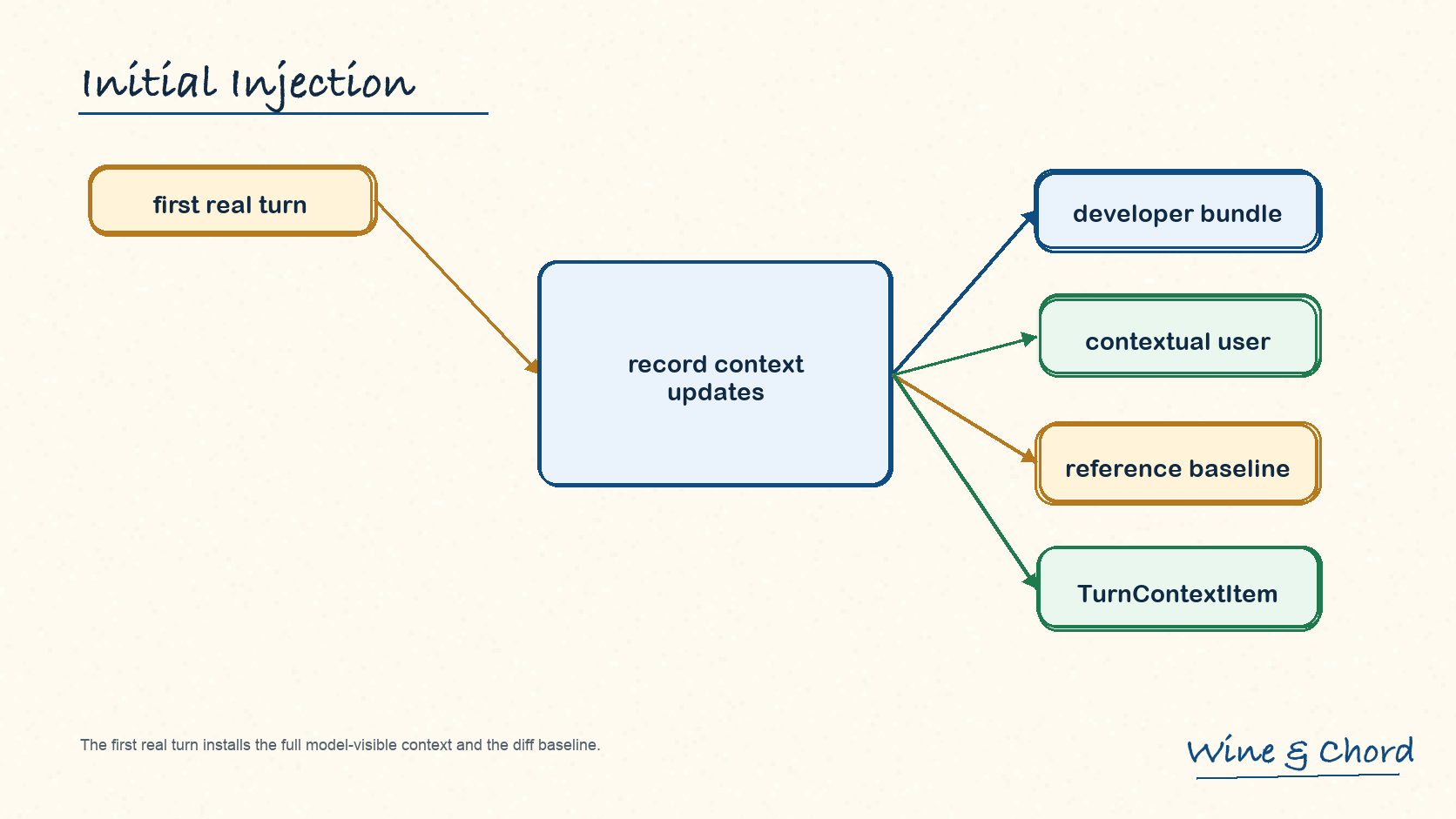
图 5. 首个真实 turn 同时建立模型可见上下文和后续 diff 的 reference baseline。
developer sections
developer 侧可能包括 permissions、developer instructions、memory read prompt、collaboration mode、realtime、personality、apps、skills、plugins 和 commit trailer instructions。
contextual user sections
user 侧主要包括 AGENTS.md user instructions 和 environment context。UserInstructions 的 role 是 "user",marker 是 # AGENTS.md instructions for ...,见 context/user_instructions.rs。
baseline
首个真实 turn 建立 reference baseline;后续 turn 才能按 tracked settings diff 发送变化。
3.2 全量注入与 diff 的分支
record_context_updates_and_set_reference_context_item 的核心分支可以压成:
if reference_context_item is None:
build_initial_context(turn_context)
else:
build_settings_update_items(reference_context_item, turn_context)
没有 baseline
Codex 必须完整注入动态上下文。
有 baseline
Codex 尝试只发 settings diff,减少 token overhead。
baseline 仍会持久化
函数最后持久化 RolloutItem::TurnContext,把 runtime view 和 durable recovery 连接起来。
四、AGENTS.md 是用户上下文,不是安全边界
4.1 搜索与拼接规则
agents_md.rs 文件头说明:Codex 从 cwd 向上找到 project root,再从 project root 到 cwd 依序收集 AGENTS.md,不越过 root。默认文件名和 local override 分别是 AGENTS.md / AGENTS.override.md;全局文件由 load_global_instructions 读取。
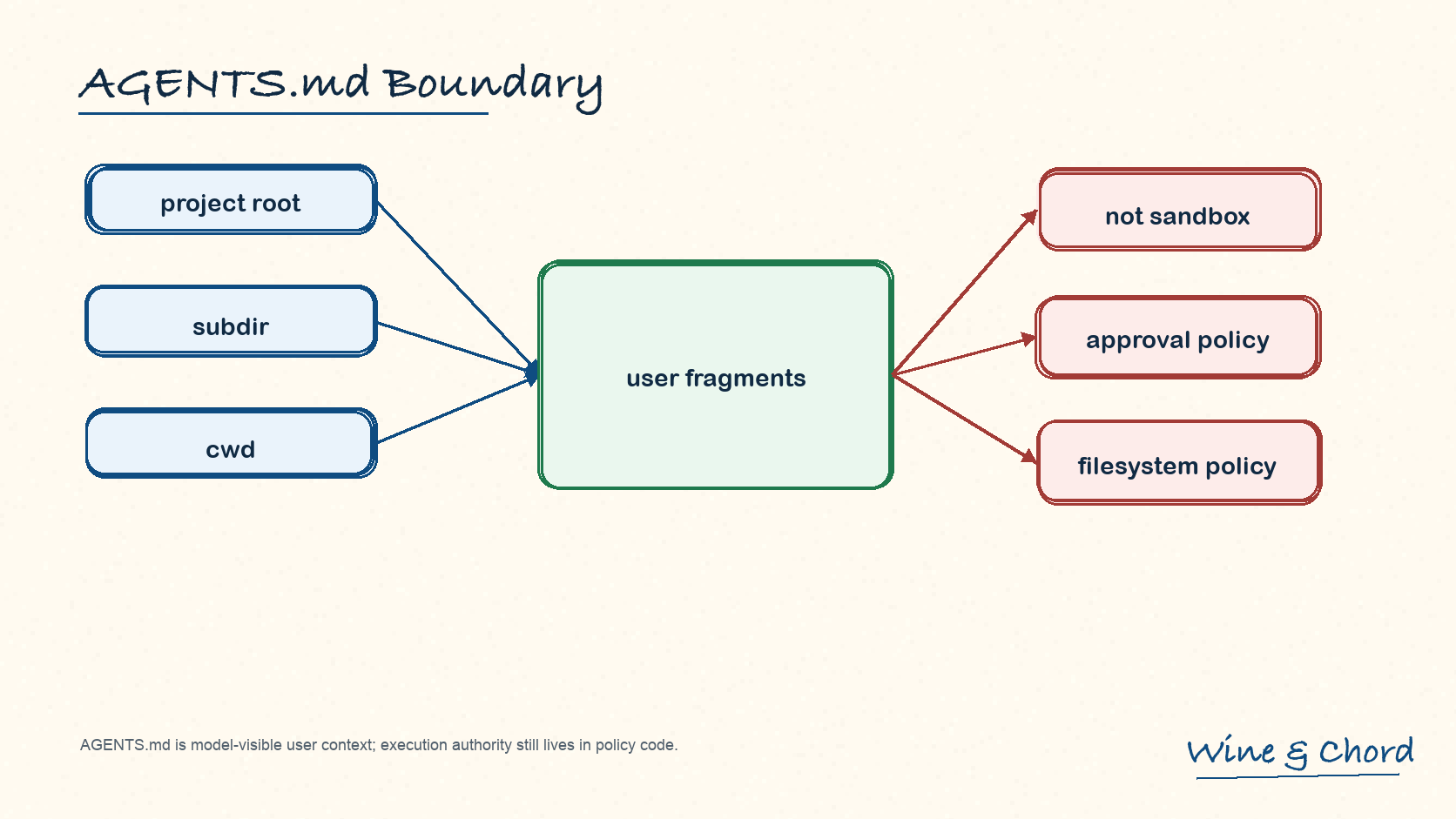
图 6. AGENTS.md 是模型可见的用户上下文;执行权限仍然由 approval、sandbox 和 filesystem policy 决定。
从根到叶
越靠近 cwd 的规则越晚出现,但源码没有把它升级成不可覆盖的安全层。
config 与项目文档分隔
AgentsMdManager::user_instructions 在 config instructions 和项目文档之间插入 --- project-doc ---,保留来源感。
4.2 为什么不是 sandbox
行为指导
AGENTS.md 指导模型如何工作。
执行约束
approval、sandbox、filesystem policy 和工具实现才约束实际 action。
恢复语义
AGENTS.md 属于 turn context 相关的 user fragment,不是 SessionMeta.base_instructions。
五、Skills、Plugins、Apps 先摘要,按需展开
5.1 能力列表不一次性吃完整窗口
skills 的可用列表由 AvailableSkillsInstructions 渲染;plugins 和 apps 分别由 available_plugins_instructions.rs 与 apps_instructions.rs 渲染。
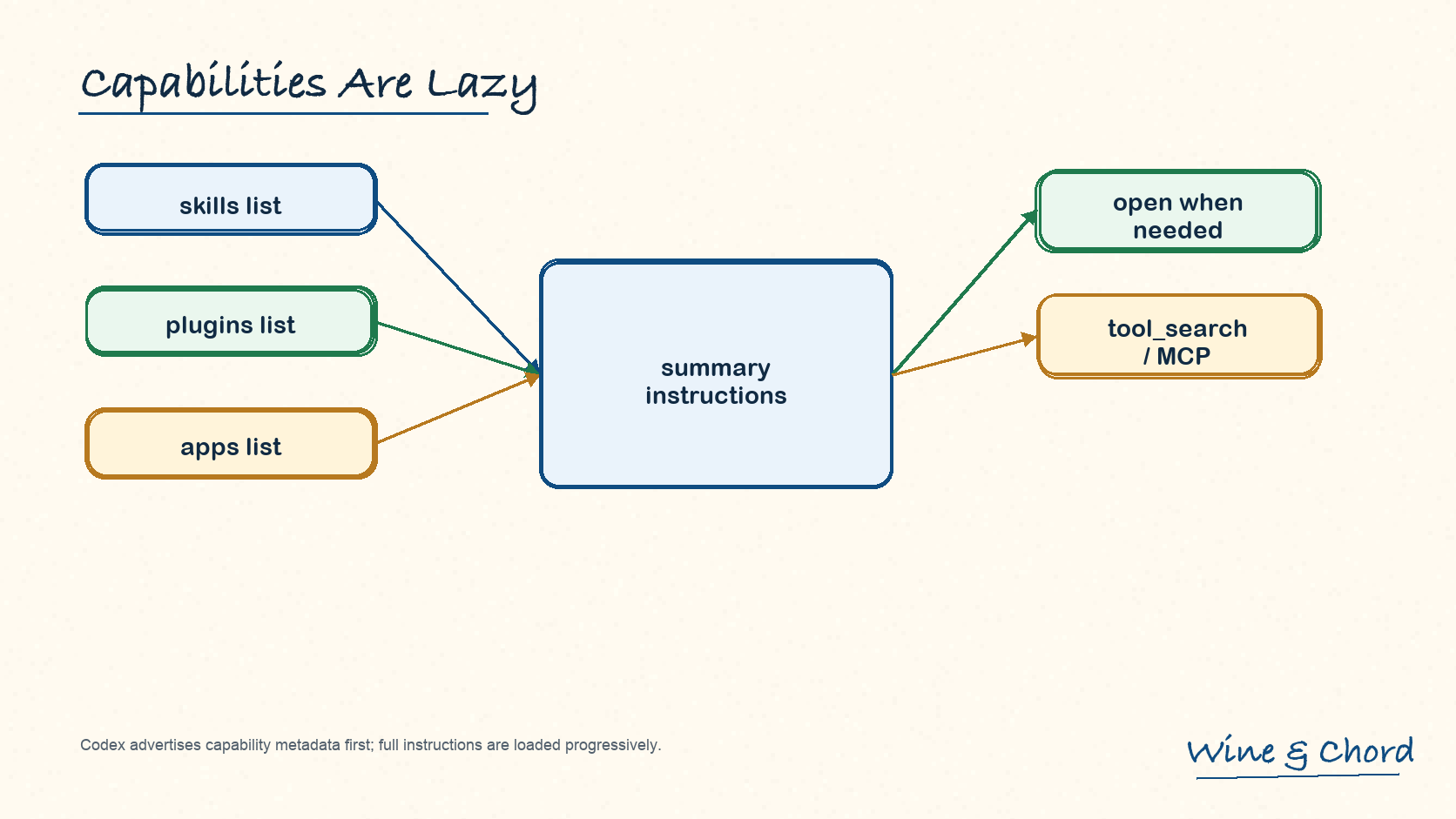
图 7. Codex 先暴露 capability metadata;具体 skill body、connector 或工具细节按需再加载。
摘要节省预算
可用列表告诉模型“有哪些能力”和“什么时候该加载”,而不是把每个 SKILL.md 全塞进 prompt。
来源仍然不同
skills、plugins、apps 都可能提供工具,但来源和激活规则不同,所以不能混进 AGENTS.md user fragment。
5.2 动态工具也需要恢复形状
Codex::spawn 在 dynamic tools 为空时,会对 resumed/forked thread 优先从 state DB 或 rollout-file 读 thread-start tools。
工具集合不是当前进程快照
resume 后工具集合不能随当前进程静默漂移。
能力摘要不是执行证据
真正的工具结果仍通过 ResponseItem、event 和 rollout 持久化。
六、tracked settings diff 的范围
6.1 ContextManager 持有 reference baseline
ContextManager 保存 items、history_version、token_info 和 reference_context_item。build_settings_update_items 比较 environment、permissions、collaboration mode、realtime、personality、model 等字段。
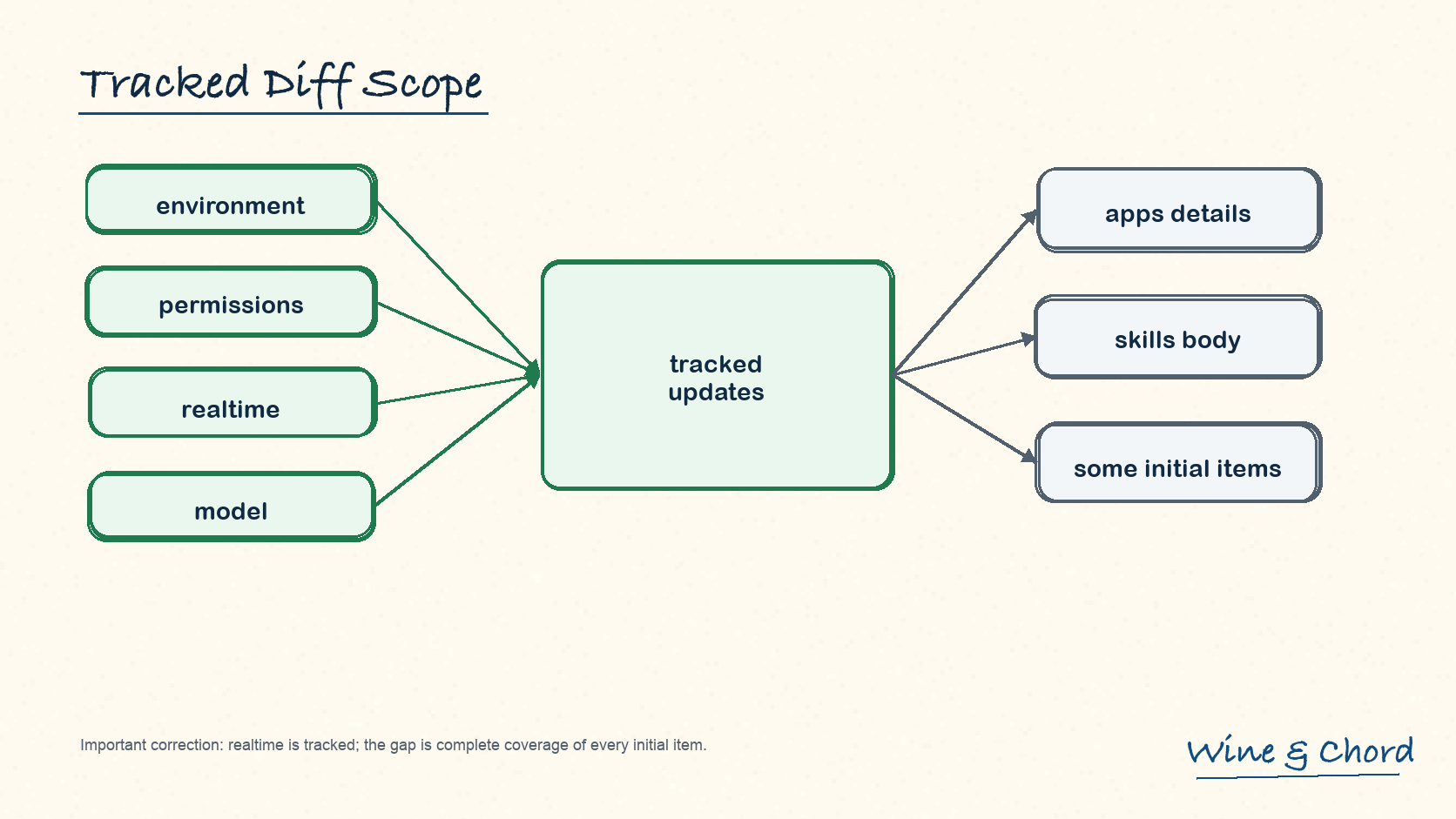
图 8. realtime 属于 tracked updates;真正缺口是 initial context 中仍有部分 model-visible item 尚未完整 diff。
tracked 包括 realtime
源码调用 build_realtime_update_item,所以把 realtime 归到 untracked 是错的。
gap 不是丢失
源码注释说明 settings diff 尚未覆盖 build_initial_context 的每一种 model-visible item。这是 coverage gap,不是说上下文一定丢。
6.2 模型看到的是投影
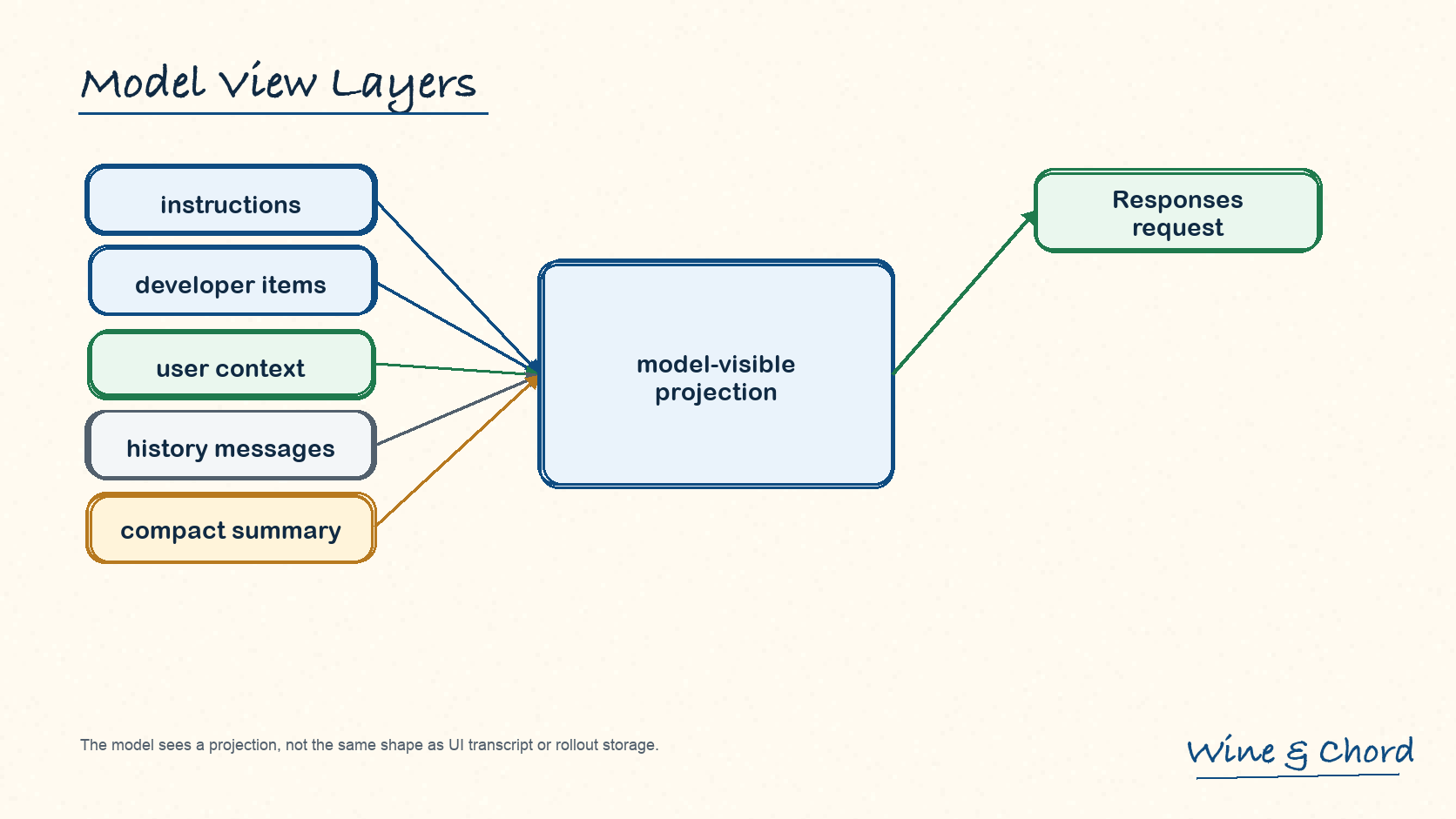
图 9. 模型看到的是投影后的请求形状,不等于 UI transcript 或 rollout storage 的原始形状。
history 不是唯一真相
resume 还要读 rollout、replacement history 和 TurnContext metadata。
diff 是优化
tracked diff 减少重复注入,但不定义整个上下文系统的身份。
七、memory:读路径进 prompt,写路径异步整理
7.1 read path 是 developer prompt fragment
build_memory_tool_developer_instructions 读取 memory_summary.md,按 token limit 截断,渲染成 developer instructions;文件为空时返回 None。
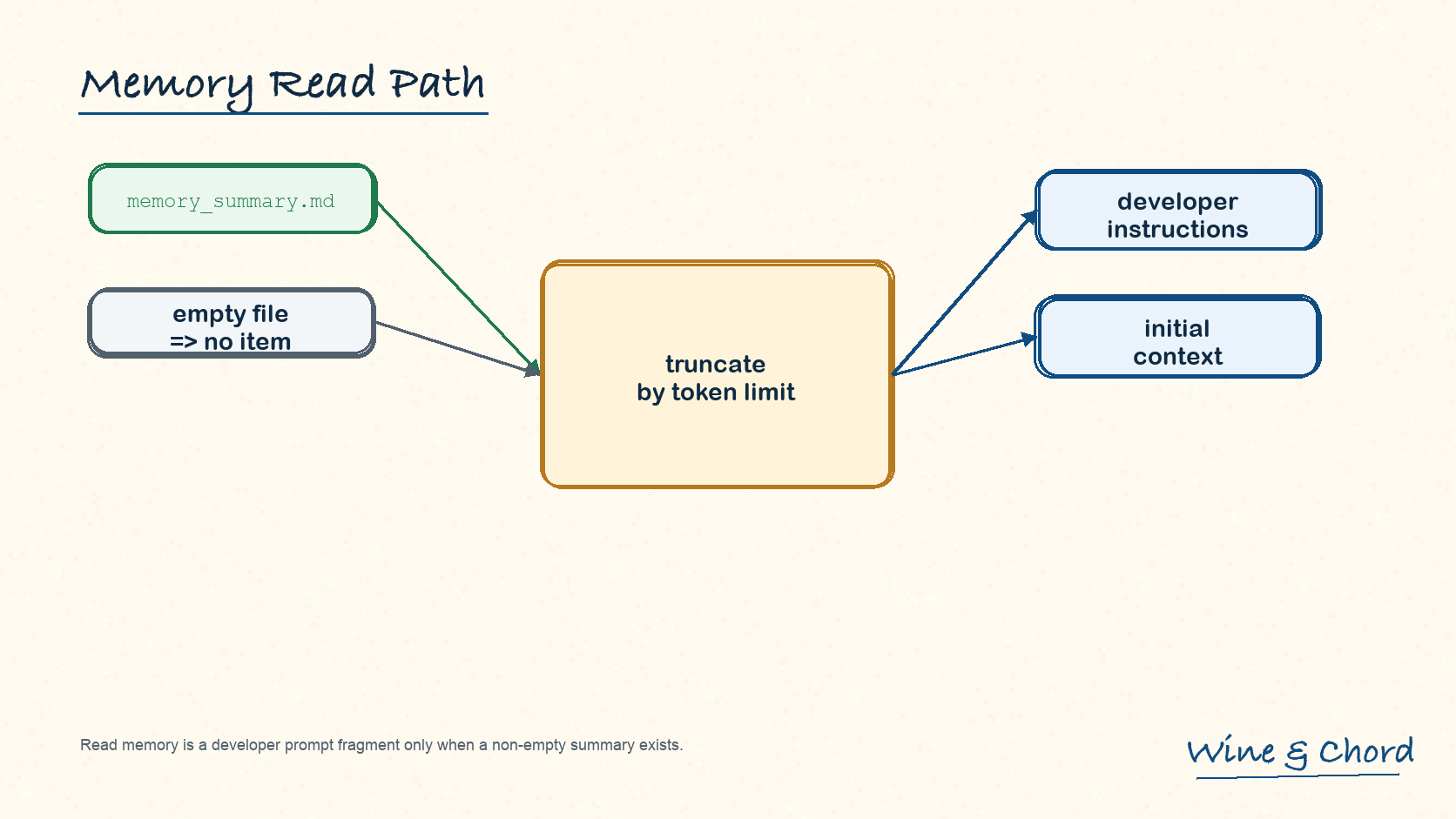
图 10. memory read 有文件来源、截断策略和 developer-role 入口。
summary 存在才出现
memory 开启不等于每轮都有额外上下文。
与 Claude Code 不同
Claude Code 的 Memory 文档 描述的是可编辑的层级记忆文件;Codex 这里更像启动时读取 summary,再通过后台 pipeline 整理长期偏好。
7.2 write path 是受限异步 pipeline
start_memories_startup_task 会跳过 ephemeral session、关闭 MemoryTool 的配置和 non-root agent session;通过 rate limit 后运行 phase 1 与 phase 2。
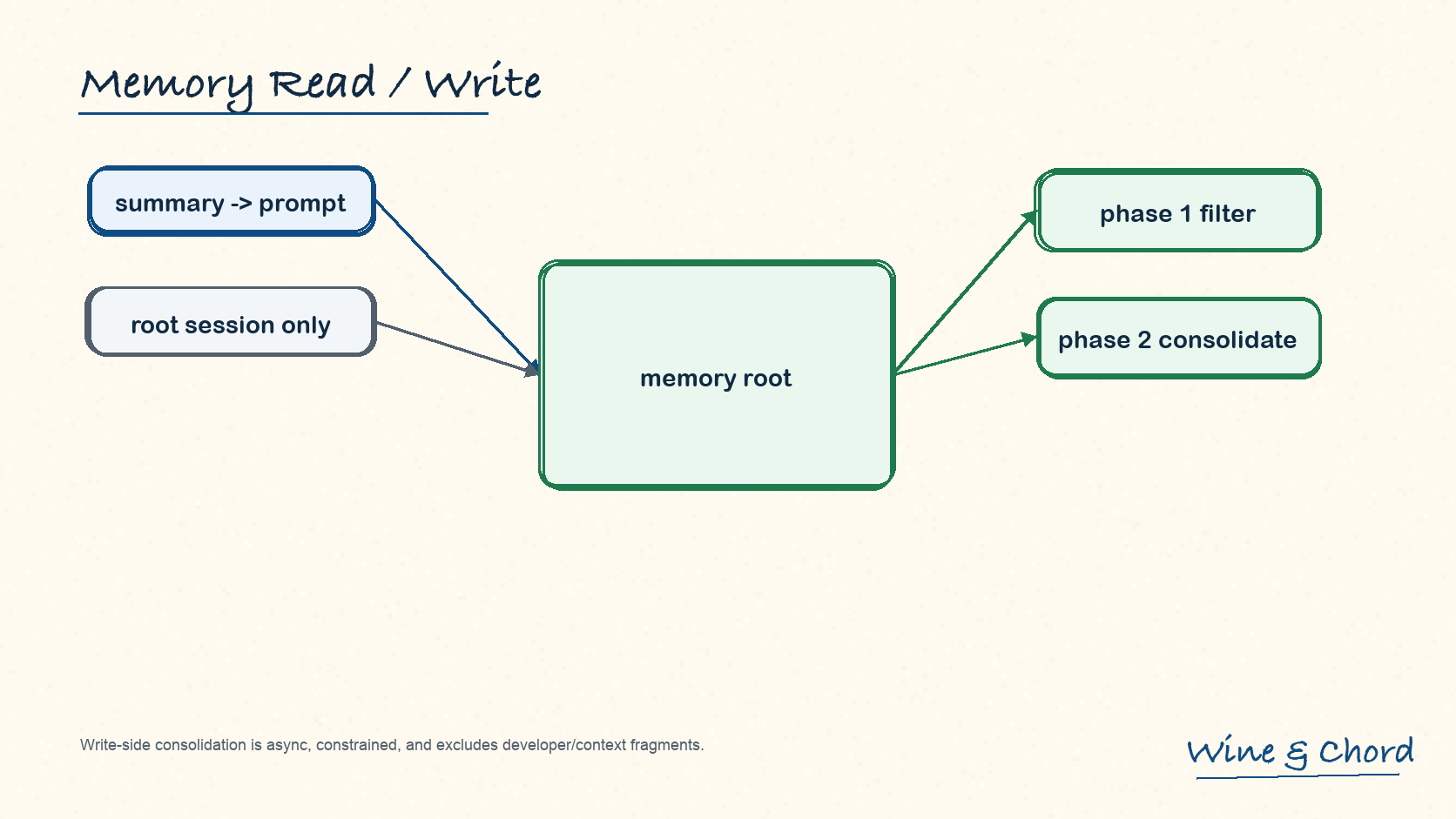
图 11. 读路径进当前 prompt,写路径异步过滤并整理长期材料。
phase 1 过滤
phase1.rs 会过滤 rollout response items、丢弃 developer messages、排除部分 contextual user fragment,并做 secret redaction。
phase 2 收缩能力
phase2.rs 把 consolidation agent 限制在 memory root,禁用 apps/plugins/memory/collab 等能力,并使用无网络 sandbox。
八、compaction 是 history replacement
8.1 pre-turn 与 mid-turn 不同
InitialContextInjection 有 DoNotInject 和 BeforeLastUserMessage 两种策略。pre-turn/manual compaction 清掉 baseline;mid-turn compaction 要在最后一个真实 user message 前补回 initial context。
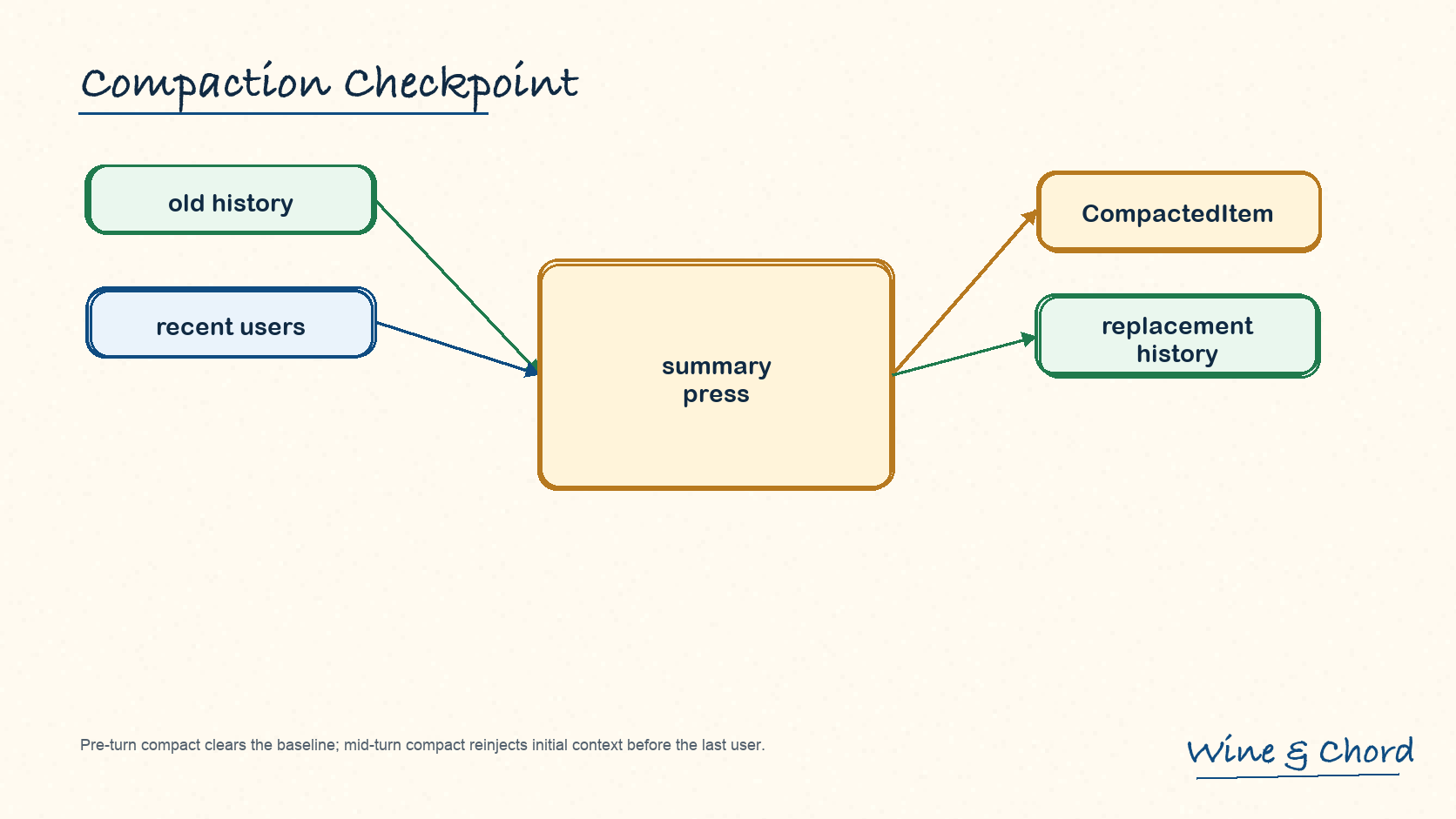
图 12. compaction 的产物不是普通 summary,而是带 replacement history 语义的 checkpoint。
pre-turn compact
run_pre_sampling_compact 在超过 auto compact limit 时使用 DoNotInject。
model downshift
maybe_run_previous_model_inline_compact 在切到更小 context window 时可能触发 pre-turn compact。
mid-turn compact
post-sampling 阶段若 token limit reached 且需要 follow-up,会用 BeforeLastUserMessage。
8.2 CompactedItem 是恢复锚点
CompactedItem 包含 message 和可选 replacement_history;compact.rs 会构造 replacement history 并调用 replace_compacted_history。
summary 不是全部上下文
summary 压缩旧 history;权限、cwd、model、memory、skills/apps 仍走自己的注入或 diff 路径。
replacement history 决定 resume 起点
没有 replacement history,恢复逻辑无法区分已替换的旧历史和仍需保留的新尾部。
九、rollout 恢复与 rollout trace 要分开
9.1 rollout JSONL 是生产恢复路径
RolloutItem 是持久化结构;恢复逻辑在 rollout_reconstruction.rs。
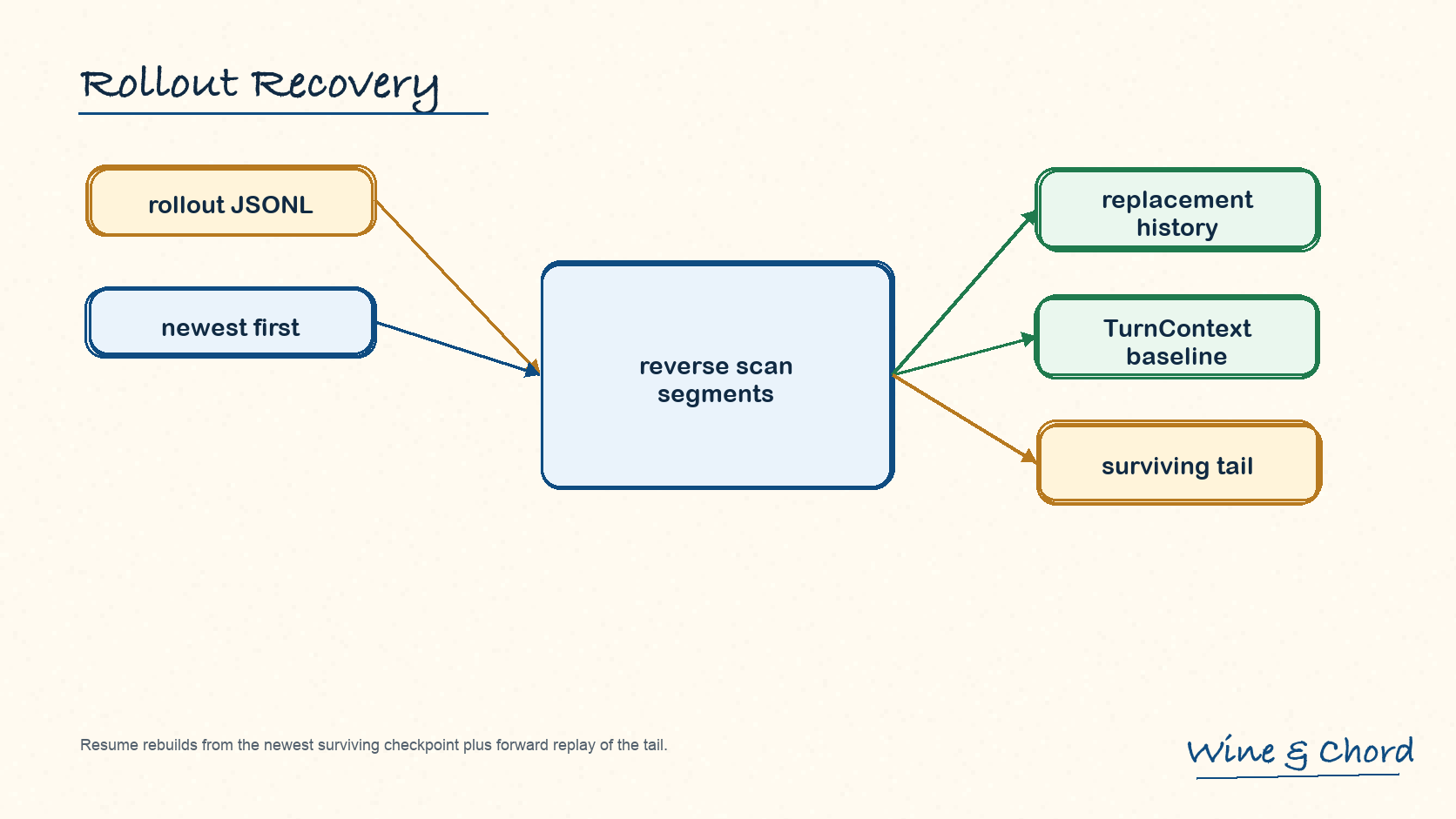
图 13. Resume 从最新可存活 checkpoint 逆向扫描,再正向回放 surviving tail。
逆向扫描
reconstruct_history_from_rollout 从新到旧扫描,直到找到 replacement history、previous turn settings 和 reference context item。
segment finalization
TurnStarted、TurnComplete、TurnAborted、UserMessage、TurnContext 会被归并成可判断的 turn segment。
tail replay
拿到 checkpoint 后,还要向前 materialize newer suffix,保持 history semantics。
9.2 rollout trace 是诊断图谱
rollout-trace/README.md 明确说 tracing 不是 telemetry,只在 CODEX_ROLLOUT_TRACE_ROOT 设置时写本地 bundle,且 bundle 可能包含 prompts、responses、tool inputs/outputs、terminal output 和路径。
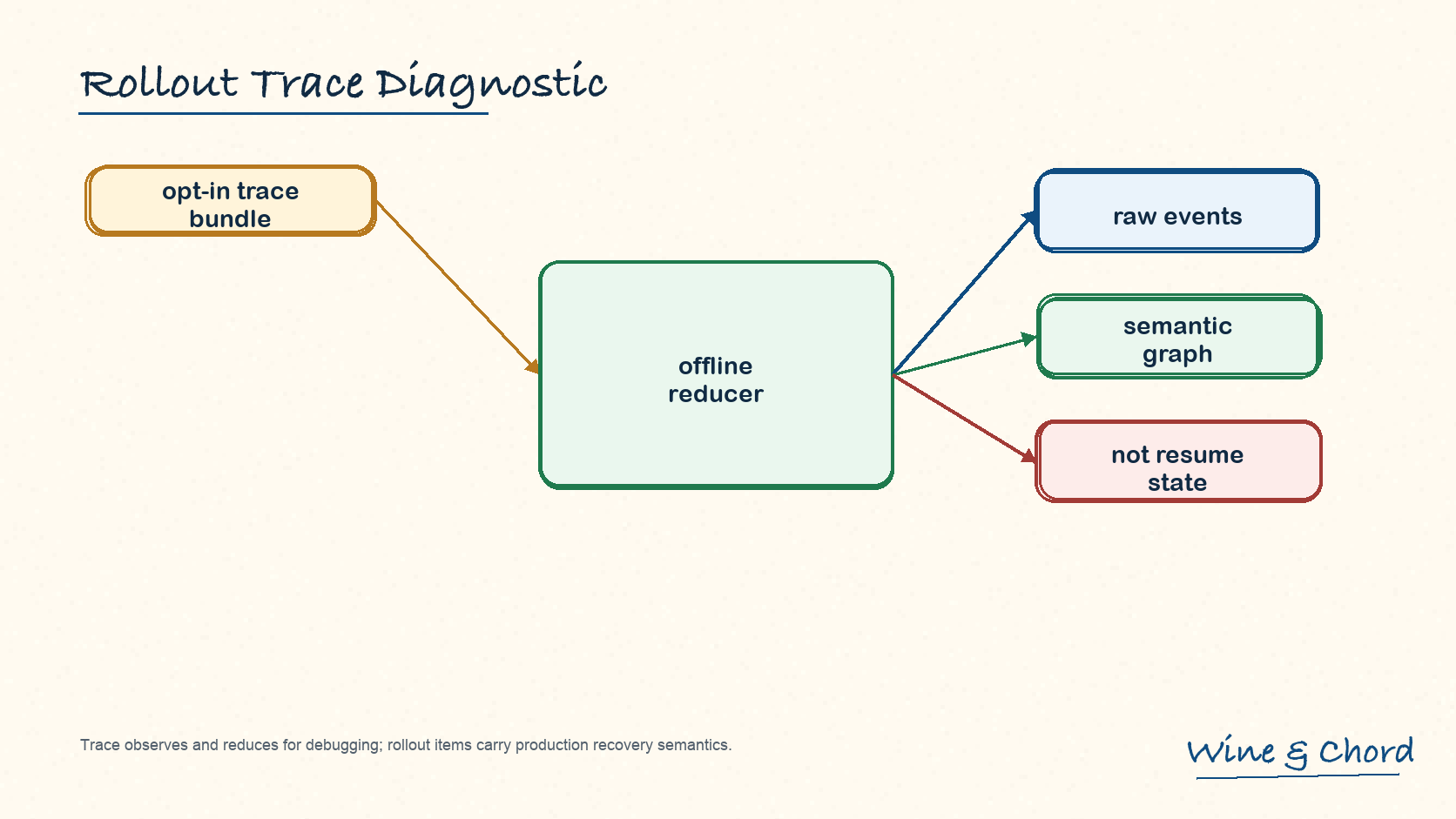
图 14. trace 用来 observe first, interpret later;生产恢复语义仍在 rollout items 里。
trace 保存证据
它解释某个 tool call、runtime output 或 agent notification 是怎么来的。
trace 不决定 resume
resume 走 rollout reconstruction,不走 trace graph。
十、把系统压成可迁移规则
| 层级 | Codex 里的证据 | 读源码时要问的问题 | 常见误判 |
|---|---|---|---|
| Provider contract | Responses API 的 `instructions` / `input` | 稳定基线和 conversation items 是否分开? | 把 API 字段当成服务内部实现。 |
| Initial context | `build_initial_context`、developer/user fragments | 每个 fragment 的 role、来源和 feature gate 是什么? | 把所有动态上下文都叫 system prompt。 |
| Tracked diff | `reference_context_item`、`build_settings_update_items` | 哪些字段被 diff,哪些仍需 full injection 或 replay? | 认为 diff 已覆盖所有 initial items。 |
| Memory | `memory_summary.md`、phase 1/phase 2 pipeline | 这是读路径、写路径,还是整理 worker 的限制? | 认为 memory 是无过滤的全量长期记录。 |
| Compaction | `InitialContextInjection`、`CompactedItem.replacement_history` | 这次 compact 是否补回 initial context?baseline 被清掉了吗? | 把 compact summary 当成全部上下文。 |
| Rollout recovery | `RolloutItem`、`reconstruct_history_from_rollout` | 最新 surviving checkpoint 和 tail replay 怎么组合? | 把 rollout trace 当成 resume 权威状态。 |
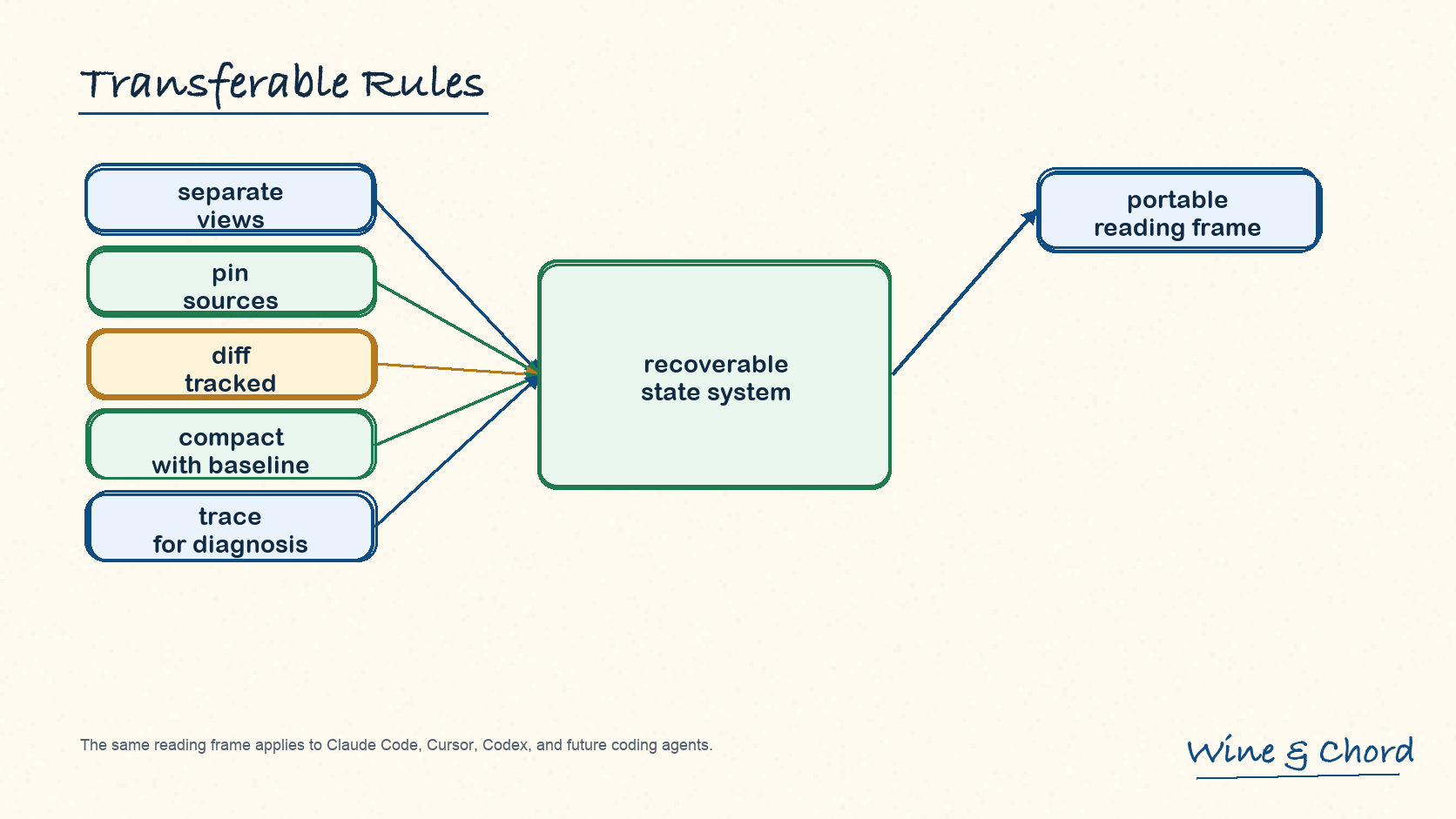
图 15. 一个成熟 coding agent 的 prompt 不只是输入文本,而是可追踪、可压缩、可恢复的状态系统。
10.1 三条最短规则
先分视图
UI transcript、model view、rollout storage、trace graph 不一定同形。
再看 baseline
base_instructions、reference_context_item、TurnContextItem 分别解决不同恢复问题。
最后看替换语义
compaction 和 resume 的关键不是摘要文本,而是 replacement history 与 surviving tail 如何接上。
参考
- Codex source snapshot:
openai/codex@ac4332c05b11e00ae775a24cb762edc05c5b5932 - OpenAI Responses API: overview, migration guide,
responses.create - OpenAI: Unrolling the Codex agent loop
- Claude Code: Memory