从零实现 LLM Inference:066. Online/Offline Serving Benchmark(roseinfer vs vLLM vs SGLang)
这篇主要做两件事:
- 给
roseinfer加一套 online serving latency 的压测:启动三套 OpenAI-compatible server(roseinfer/vLLM/SGLang),用 同一个 OpenAI client 回放同一份 trace,统计TTFT / TPOT / ITL / E2E,并直接画出对比图。 - 再补一个 offline throughput 的压测:不走 server,随机生成 token id 做吞吐对比,方便回归。
模型统一先用 HuggingFace gpt2(也可以换成 gpt2-medium/gpt2-large 等同族模型)。压测脚本留了 --model 口子,后续要扩到更多模型也方便。
Online 压测:指标与 trace 回放
1) 四个延迟指标怎么定义
对一次 streaming completion,记:
- request 发出时刻:$t_0$
- 第一个 token 到达时刻:$t_1$
- 第 $i$ 个 token 到达时刻:$t_i$
- 最后一个 token 到达时刻:$t_N$
那么:
- TTFT(Time To First Token):$\mathrm{TTFT} = t_1 - t_0$
- ITL(Inter-Token Latency):$\mathrm{ITL}i = t_i - t{i-1}$($i \ge 2$)
- TPOT(Time Per Output Token):$\mathrm{TPOT} = \frac{1}{N-1}\sum_{i=2}^{N}\mathrm{ITL}_i$
- E2E(End-to-End Latency):$\mathrm{E2E} = t_N - t_0$
统计上:
TTFT/E2E/TPOT:按 request 粒度 统计(p50/p90/p99)ITL:按 token 粒度 统计(把所有请求的 token 间隔摊平后算 p50/p90/p99)
2) TraceA:只给长度、不给文本怎么办?
参考 mini-sglang 的做法,用同一个 tokenizer 构造一个足够长的 “base prompt”(token 序列),然后对每条 trace 取前 input_len 个 token decode 成 prompt 文本即可:
- TraceA 提供:
timestamp / input_length / output_length - 我们生成:
prompt = decode(base_ids[:input_length])
这样三套 server 都拿到 一致的 prompt 文本,并且 token 长度也可控。
3) Trace timestamp scale:控制负载强弱
TraceA 自带一个 timestamp(单位秒)。我们按 mini-sglang 的思路做 scale:
\[t^{\text{send}}_i = t_{\text{start}} + s\cdot(\tau_i - \tau_{\min}) + \Delta\]- $s$ 越小,事件越“挤”,并发越高(更重的 online load)
- $\Delta$ 是起步偏移(默认 1s),用于让 server 先稳定起来
4) 长上下文对齐:必要时截断
TraceA 的长度上限远超 gpt2 的 1024 context。我们做了两层保护:
- 先按
max_ctx把input_len + output_len裁到能跑的范围 - 再额外减一个 safety margin(默认
--prompt-overhead-tokens 8,以及 1-token strict margin),避免不同 server 的 “<= / <” 边界差异导致偶发 400
Online 压测:实现与使用方式
1) 为什么用 /v1/completions 而不是 /v1/chat/completions
gpt2 没有 chat template,而部分 server(transformers 新版本默认)会拒绝 “没有显式 chat template 的 chat 请求”。为了把 benchmark 做到三家都能稳定跑,这里统一用 /v1/completions + stream=True。
对应地,roseinfer 的 server 新增了 /v1/completions 和 /v1/models 两个 endpoint,便于 OpenAI client 直连。
2) Server / Client 绑核(控制变量)
benchmarks/serving/online_compare.py 默认把 CPU 核心按一半切开:
- server:前半
- client:后半
并在 server 进程里设置:
OMP_NUM_THREADS = server_cpu_countMKL_NUM_THREADS = server_cpu_count
可以用 --server-cpus / --client-cpus 手动指定,例如:
python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--server-cpus "0-15" --client-cpus "16-31"
3) 一键跑 online
python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--n 200 \
--scales 0.4,0.5,0.6,0.7,0.8,1.6 \
--max-output-len 64 \
--ignore-eos
产物:
outputs/benchmarks/serving/online_<timestamp>/online_results.jsonoutputs/benchmarks/serving/online_<timestamp>/*.server.log
Offline 压测:实现与使用方式
offline 的目标很简单:不走 server,直接喂随机 token id,看吞吐。为了严格对齐测量边界(只看 engine/scheduler),这里统一采用 token-id 输入,并尽量避免 tokenize/detokenize 的额外开销:
roseinfer:用OnlineScheduler.add_requests()批量喂prompt_token_idsvLLM:用LLM.generate(prompt_token_ids=...),并设置detokenize=FalseSGLang:用Engine.generate(input_ids=...)+skip_tokenizer_init=True(避免 tokenizer/detokenizer 参与)
另外,offline 会用同一个 --seed 生成 prompt_token_ids,并按对应模型的 vocab_size 取值,保证三家输入一致;吞吐统计也按实际返回的 completion_tokens(而不是直接用 num_prompts * output_len)来计数。
一键跑:
python benchmarks/serving/offline_compare.py \
--model gpt2 --gpu 0 \
--num-prompts 128 --input-len 256 --output-len 64 \
--ignore-eos
产物:
outputs/benchmarks/serving/offline_<timestamp>/offline_results.json
自动画图(论文风格)
python benchmarks/serving/plot_compare.py \
--online outputs/benchmarks/serving/online_*/online_results.json \
--offline outputs/benchmarks/serving/offline_*/offline_results.json \
--output-dir outputs/benchmarks/serving/figures/run
会生成:
- 1 张 online latency 2x2 总览图(TTFT/TPOT/ITL/E2E),p90 曲线 + p50~p90 阴影带(空心点为 p99)
- 1 张 offline throughput 对比图
- 2 个 summary markdown(方便直接贴表格)
结果(HF GPT-2 / GPU0)
运行环境 / 版本 / 耗时(自动记录在 *_results.json)
- versions:
rosellm@415bffe,vllm=0.13.0,sglang=0.5.6.post2,torch=2.9.0,transformers=4.57.1,python=3.10.9 - online:
dtype=fp16,ignore_eos=true,n=200,scales=0.4,0.5,0.6,0.7,0.8,1.6,max_output_len=64, start=2025-12-25T13:44:06+08:00, end=2025-12-25T14:02:27+08:00, wall=1100.57s - offline:
dtype=fp16,ignore_eos=true,num_prompts=128,input_len=256,output_len=64, start=2025-12-25T14:14:52+08:00, end=2025-12-25T14:15:48+08:00, wall=55.56s
注:不同机器/版本会有波动,重点是 benchmark 框架固定后,后续做优化能稳定回归对比。
Online:p50/p90/p99(ms)
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer | 18.31/32.25/180.64 | 25.74/37.12/41.87 | 20.59/40.57/57.18 | 1561.39/2322.65/2644.23 |
| 0.40 | SGLang | 9.47/12.48/465.61 | 1.08/1.21/1.34 | 1.06/1.27/2.61 | 77.97/87.56/536.56 |
| 0.40 | vLLM | 8.13/9.46/11.96 | 1.34/1.44/1.62 | 1.32/1.52/1.97 | 92.31/99.51/104.85 |
| 0.50 | roseinfer | 8.88/15.84/451.09 | 12.56/18.23/21.77 | 12.42/18.53/34.99 | 799.11/1119.47/1404.33 |
| 0.50 | SGLang | 9.81/12.21/443.42 | 1.07/1.21/1.39 | 1.06/1.26/2.55 | 78.09/87.75/512.75 |
| 0.50 | vLLM | 8.44/9.92/432.63 | 1.32/1.44/1.52 | 1.31/1.51/1.91 | 92.17/99.97/523.46 |
| 0.60 | roseinfer | 8.14/14.36/444.51 | 10.51/15.01/18.55 | 10.23/15.84/23.46 | 661.92/964.38/1187.50 |
| 0.60 | SGLang | 9.73/11.95/437.32 | 1.07/1.19/1.46 | 1.06/1.25/2.34 | 77.97/87.17/503.81 |
| 0.60 | vLLM | 8.52/9.78/14.99 | 1.33/1.44/1.52 | 1.32/1.51/1.85 | 92.40/99.33/109.31 |
| 0.70 | roseinfer | 7.61/14.09/23.62 | 9.35/13.54/17.01 | 9.12/14.73/18.65 | 582.65/856.73/1079.59 |
| 0.70 | SGLang | 10.17/12.33/461.13 | 1.07/1.19/1.36 | 1.07/1.25/2.35 | 78.15/85.98/528.02 |
| 0.70 | vLLM | 8.60/9.74/416.17 | 1.31/1.44/1.61 | 1.31/1.50/1.84 | 91.85/100.14/501.97 |
| 0.80 | roseinfer | 6.94/12.80/443.34 | 8.68/12.85/15.47 | 8.54/13.70/17.92 | 546.56/823.10/1057.88 |
| 0.80 | SGLang | 10.25/12.12/447.69 | 1.08/1.19/1.36 | 1.08/1.25/2.13 | 78.60/87.35/515.71 |
| 0.80 | vLLM | 8.70/10.11/19.88 | 1.32/1.42/1.57 | 1.32/1.49/1.76 | 92.25/98.97/113.33 |
| 1.60 | roseinfer | 5.36/9.57/422.48 | 6.58/9.72/11.67 | 6.25/10.13/13.55 | 420.81/633.90/876.20 |
| 1.60 | SGLang | 10.58/15.71/22.27 | 1.11/1.21/1.36 | 1.10/1.26/2.06 | 80.62/87.80/105.28 |
| 1.60 | vLLM | 9.10/10.08/410.19 | 1.36/1.44/1.53 | 1.34/1.49/1.80 | 94.87/100.37/497.58 |
Online:2x2 指标总览图(p90 曲线 + p50~p90 band,空心点为 p99)
左上 TTFT,右上 TPOT,左下 ITL,右下 E2E:
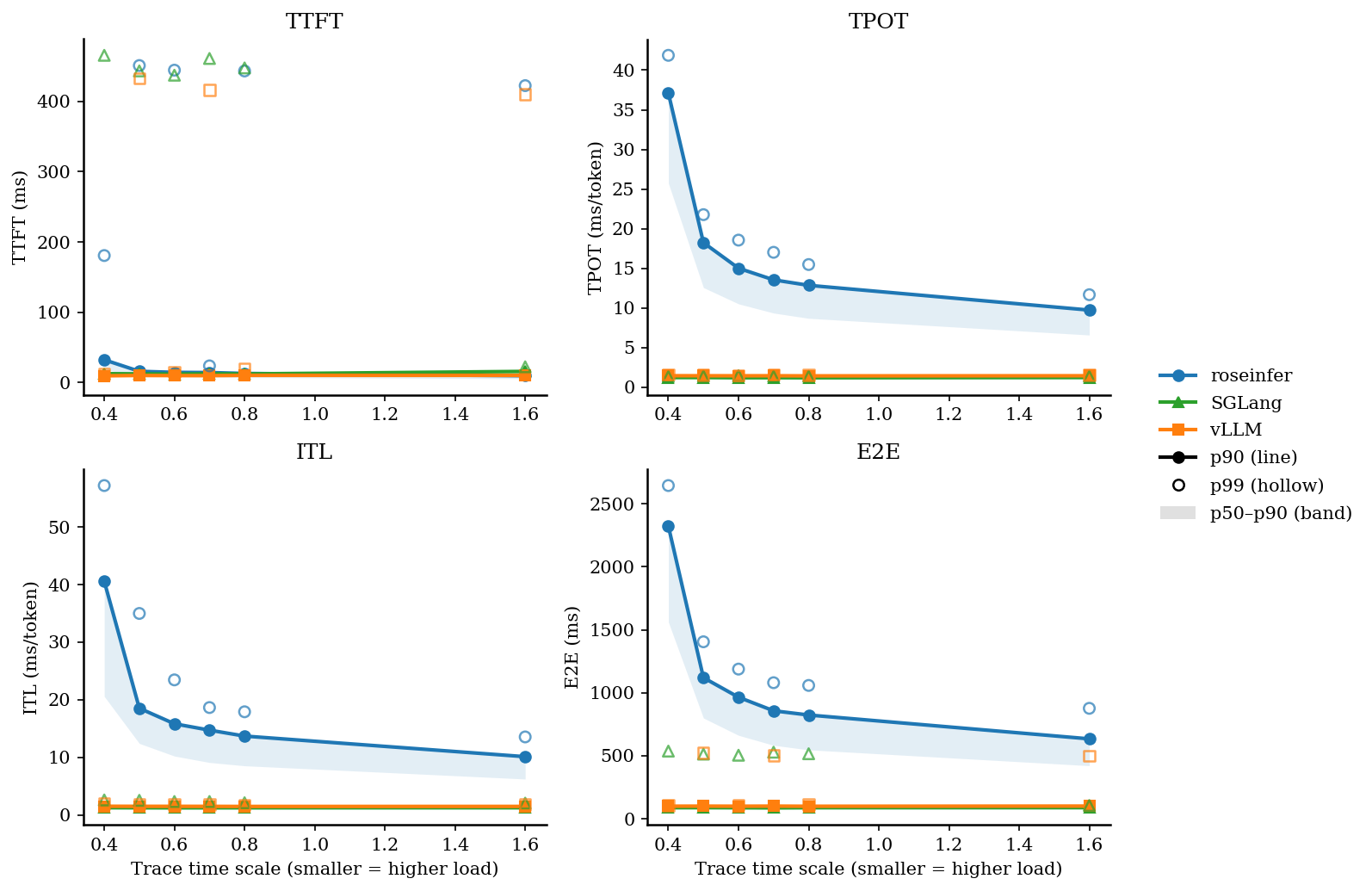
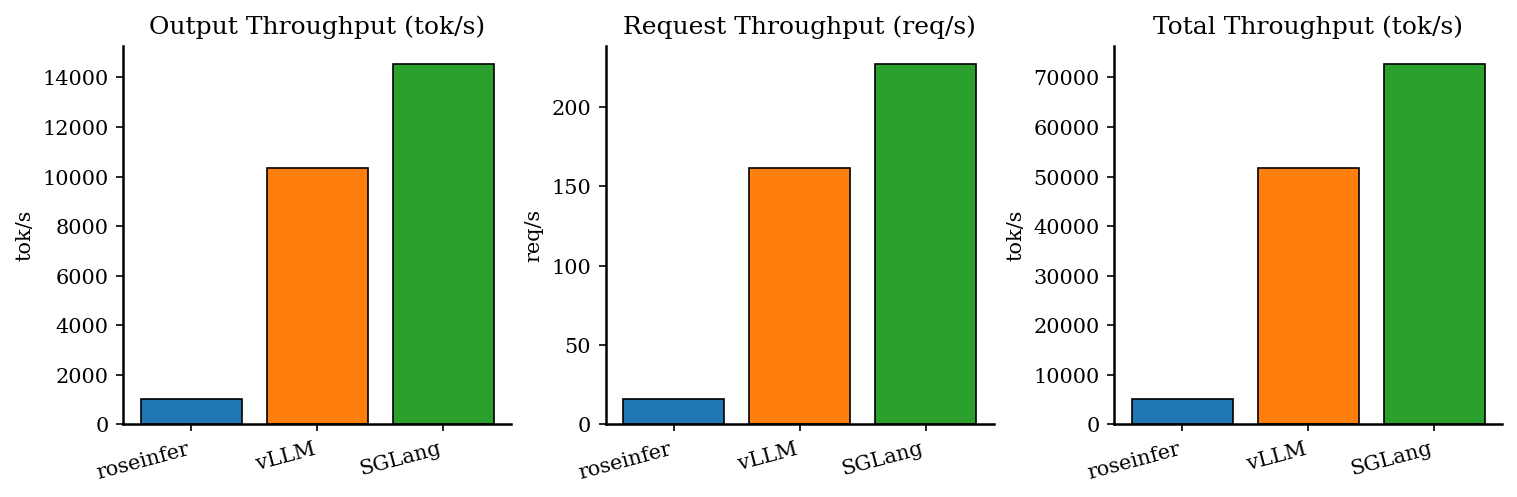
Offline:吞吐对比
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 15.72 | 1006.26 | 5031.28 | 8.141 |
| SGLang | 227.50 | 14560.12 | 72800.59 | 0.563 |
| vLLM | 161.76 | 10352.36 | 51761.80 | 0.791 |
小结
- 这版 benchmark 的价值不在于 “绝对数值”,而在于:控制变量 + 自动出图 + 可重复回归。
- 从图上能直观看到:在相同模型与采样参数下,
roseinfer的 online latency 会随着负载(scale↓)显著上升;而vLLM/SGLang的 token-level latency 更稳定。 - 有了这套 benchmark,后续做
KV cache / paged attention / kernel 融合 / 更 aggressive batching之类优化,就能用同一套脚本稳定验证收益。