从零实现 LLM Inference:067. 给 roseinfer 加 FlashAttention(Prefill 三选一:naive / flashinfer / flash-attn)
这篇的目标很明确:在 不破坏现有路径 的前提下,给 roseinfer 的 attention 加上两套 FlashAttention 实现,并且能用一套 benchmark 稳定回归对比:
naive:当前我们自己的实现(baseline)flash-attn:官方 FlashAttention(flash_attn)flashinfer:flashinfer的 FlashAttention(同样走 fused attention)
并且只做“自己和自己比”:
- online:同一份 trace 回放,画
TTFT/TPOT/ITL/E2E的 2x2 latency 图 - offline:固定 token-id 输入,画 3 根柱子的 throughput 图
FlashAttention 到底快在哪里?
标准 attention 的形式是:
\[\mathrm{Attn}(Q,K,V) = \mathrm{softmax}\left(\frac{QK^\top}{\sqrt d}\right)V\]Prefill 的场景下(一次性处理整段 prompt),$L$ 往往比较大,直接做的话需要显式 materialize 一个 $L\times L$ 的 score 矩阵(以及 softmax 中间量),不仅算力重,更关键是 HBM 读写压力很大。
FlashAttention 的核心思想可以概括为两点:
- 分块(block-wise)计算 $QK^\top$,避免把 $L\times L$ 的 score 全量写回显存。
- 用 online softmax 的方式,把 softmax 的归一化常数在 block 之间“滚动”累积起来。
一个常见的写法是维护每一行的 running max $m$、running sum $l$,以及输出累积 $o$。对某个新的 key-block 计算得到 score 子块 $s$ 后,有:
\[m' = \max\left(m, \max(s)\right)\] \[l' = l\cdot e^{m-m'} + \sum_j e^{s_j - m'}\] \[o' = o\cdot \frac{l\cdot e^{m-m'}}{l'} + \frac{\sum_j e^{s_j-m'}v_j}{l'}\]这样就能做到:只在片上(SRAM/寄存器)存少量 block 中间状态,而不是把整个 $L\times L$ 的 attention matrix 往返 HBM。
为什么我先只把 FlashAttention 用在 prefill?
很多同学第一反应是:decode 也能用 FlashAttention 吗?答案是“理论上能”,但工程上通常要分两类看:
- Prefill($T>1$):Q 长度大、K/V 长度大,attention 是明显的热点,FlashAttention 的收益通常最稳定、也最容易落地。
- Decode($T=1$):每步只有 1 个 query,算力不大,瓶颈更像是 “读 KV cache 的带宽 + cache 管理”。
更关键的是:我们当前 decode 用的是 paged KV cache(分页管理),这意味着 K/V 在物理上不是一整段连续内存。业内主流做法基本是:
- vLLM:paged attention(自研 kernel)
- SGLang:同样有 paged KV + 对应 kernel(很多场景也会用 flashinfer 的 paged decode kernel)
- flash-attn:提供
flash_attn_with_kvcache一类接口,但更偏向 连续 KV cache 的布局
如果要把 decode 也彻底切到 FlashAttention(尤其是保持 paged KV),通常需要更大规模的接口/内存布局改造;而这篇我们优先把收益大、改造小的 prefill 做通,并把开关留好,方便后续再逐步演进 decode。
代码改造:可插拔的 prefill attention backend
这里的设计目标是:保留原始实现路径,同时做到“开关化 + 可对比 + 可回归”。
1) Server/Engine 开关
roseinfer server 新增了两个参数(其中 prefill 是这篇的重点):
--prefill-attn-backend {naive,flashinfer,flashattn}--decode-attn-backend {naive,flashinfer,flashattn}(预留;paged decode 不走这个分支)
例如:
python -m rosellm.roseinfer.server \
--hf-model-id gpt2 --tokenizer-name gpt2 \
--device cuda \
--prefill-attn-backend flashattn \
--paged-attn --cuda-graph
2) 变长 batch:ragged/varlen 打包
online serving 的 batch 里每条 request 的 prompt 长度不同,如果直接 padding,会浪费算力,也会影响公平对比。
flash-attn 和 flashinfer 都支持 varlen/ragged 的接口:把 batch 的 token 维度 flatten 成一维,然后用 prefix-sum 描述每条序列的边界:
我们在 prefill 分支把 Q/K/V 打包成 varlen 格式,然后分别调用两套库的 fused attention kernel;如果依赖没装,则自动回退/跳过(benchmark 会把该 backend 标记为 unavailable)。
Benchmark:复用 066 的框架,但只做 self-compare
安装可选依赖(示例)
在本机的 /data/projects/rosellm/.conda 环境里跑通的版本是:
flash_attn==2.7.4.post1flashinfer==0.5.3(flashinfer-python+flashinfer-cubin)
对应安装命令(按需装,没装也能跑 naive 路径):
./.conda/bin/pip install -U flash-attn==2.7.4.post1
./.conda/bin/pip install -U flashinfer-python==0.5.3 flashinfer-cubin==0.5.3
一键跑 online + offline + 出图
bash scripts/bench_roseinfer_self_compare.sh \
--model gpt2 --gpu 0 \
--n 200 \
--scales 0.4,0.5,0.6,0.7,0.8,1.6 \
--max-output-len 64 \
--ignore-eos
产物(与 066 一致):
outputs/benchmarks/serving/online_*/online_results.jsonoutputs/benchmarks/serving/offline_*/offline_results.jsonoutputs/benchmarks/serving/figures/*/*.png(含 2x2 latency 图 + offline 吞吐图)
结果(HF GPT-2 / GPU0)
运行环境 / 版本 / 耗时
- versions:
rosellm@fd9a144,torch=2.6.0+cu124,transformers=4.46.3,python=3.11.11,flash_attn=2.7.4.post1,flashinfer=0.5.3 - online:
dtype=fp16,ignore_eos=true,n=200,scales=0.4,0.5,0.6,0.7,0.8,1.6, wall=1100.36s - offline:
dtype=fp16,ignore_eos=true,num_prompts=128,input_len=256,output_len=64, wall=21.60s
注:绝对数值会随机器/版本波动,重点是同一套脚本可稳定复现,方便后续做优化回归。
Online:p50/p90/p99(ms)
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
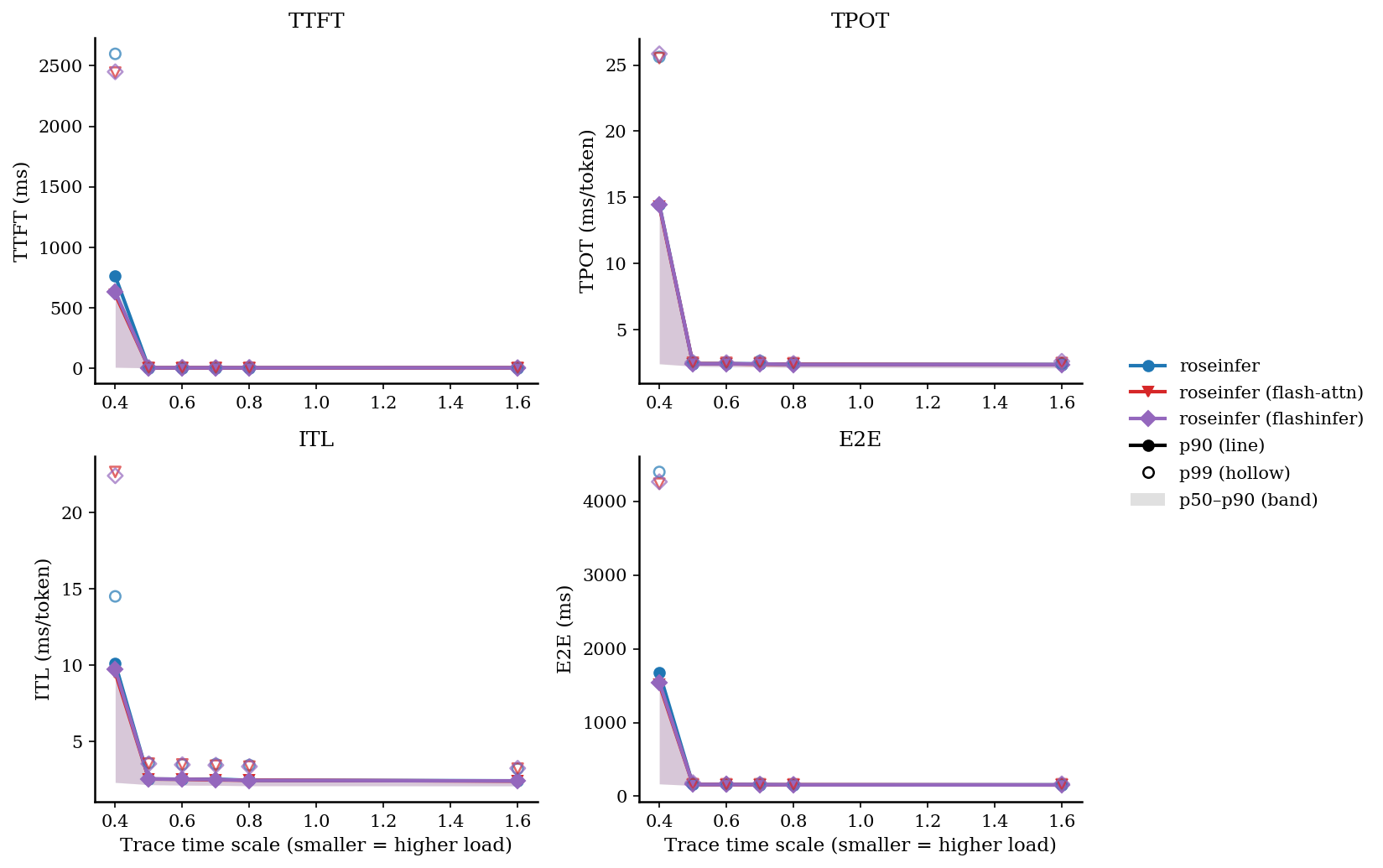
| 0.40 | roseinfer | 10.48/763.63/2597.87 | 2.41/14.48/25.61 | 2.31/10.11/14.51 | 167.28/1677.88/4398.18 |
| 0.40 | roseinfer (flash-attn) | 10.44/611.94/2443.25 | 2.42/14.34/25.52 | 2.33/9.52/22.66 | 168.04/1516.01/4239.02 |
| 0.40 | roseinfer (flashinfer) | 10.24/634.53/2449.74 | 2.46/14.43/25.84 | 2.33/9.74/22.42 | 169.65/1544.94/4264.94 |
| 0.50 | roseinfer | 4.97/6.11/9.21 | 2.25/2.44/2.57 | 2.18/2.55/3.60 | 146.83/159.69/167.84 |
| 0.50 | roseinfer (flash-attn) | 5.01/5.96/6.85 | 2.25/2.44/2.52 | 2.18/2.55/3.56 | 146.37/158.96/164.64 |
| 0.50 | roseinfer (flashinfer) | 5.06/6.03/7.41 | 2.24/2.43/2.54 | 2.16/2.56/3.55 | 146.17/159.90/184.34 |
| 0.60 | roseinfer | 5.06/6.01/7.11 | 2.21/2.44/2.54 | 2.14/2.54/3.50 | 144.62/159.80/166.07 |
| 0.60 | roseinfer (flash-attn) | 4.90/6.13/7.16 | 2.21/2.43/2.51 | 2.15/2.53/3.50 | 144.19/158.91/163.47 |
| 0.60 | roseinfer (flashinfer) | 5.09/6.04/9.51 | 2.20/2.43/2.51 | 2.15/2.53/3.48 | 143.84/159.20/163.98 |
| 0.70 | roseinfer | 5.19/6.18/8.13 | 2.20/2.42/2.64 | 2.13/2.54/3.52 | 143.50/158.71/174.16 |
| 0.70 | roseinfer (flash-attn) | 4.94/6.07/7.26 | 2.17/2.39/2.49 | 2.13/2.49/3.42 | 142.19/155.99/163.55 |
| 0.70 | roseinfer (flashinfer) | 5.10/6.14/7.06 | 2.20/2.42/2.54 | 2.15/2.51/3.45 | 143.79/158.56/165.51 |
| 0.80 | roseinfer | 5.09/5.95/7.31 | 2.16/2.39/2.49 | 2.11/2.47/3.46 | 140.77/156.11/162.49 |
| 0.80 | roseinfer (flash-attn) | 4.99/5.92/6.94 | 2.15/2.39/2.48 | 2.10/2.47/3.36 | 140.07/156.55/162.22 |
| 0.80 | roseinfer (flashinfer) | 5.19/6.09/9.41 | 2.15/2.37/2.46 | 2.10/2.46/3.37 | 140.76/155.25/160.44 |
| 1.60 | roseinfer | 5.30/6.04/6.66 | 2.12/2.37/2.46 | 2.09/2.43/3.22 | 139.09/155.77/162.25 |
| 1.60 | roseinfer (flash-attn) | 5.35/6.13/6.73 | 2.13/2.36/2.49 | 2.10/2.41/3.23 | 139.80/153.68/162.95 |
| 1.60 | roseinfer (flashinfer) | 5.24/6.00/6.95 | 2.13/2.36/2.62 | 2.10/2.42/3.25 | 139.54/153.49/168.71 |
Online:2x2 指标总览图(p90 曲线 + p50~p90 band,空心点为 p99)
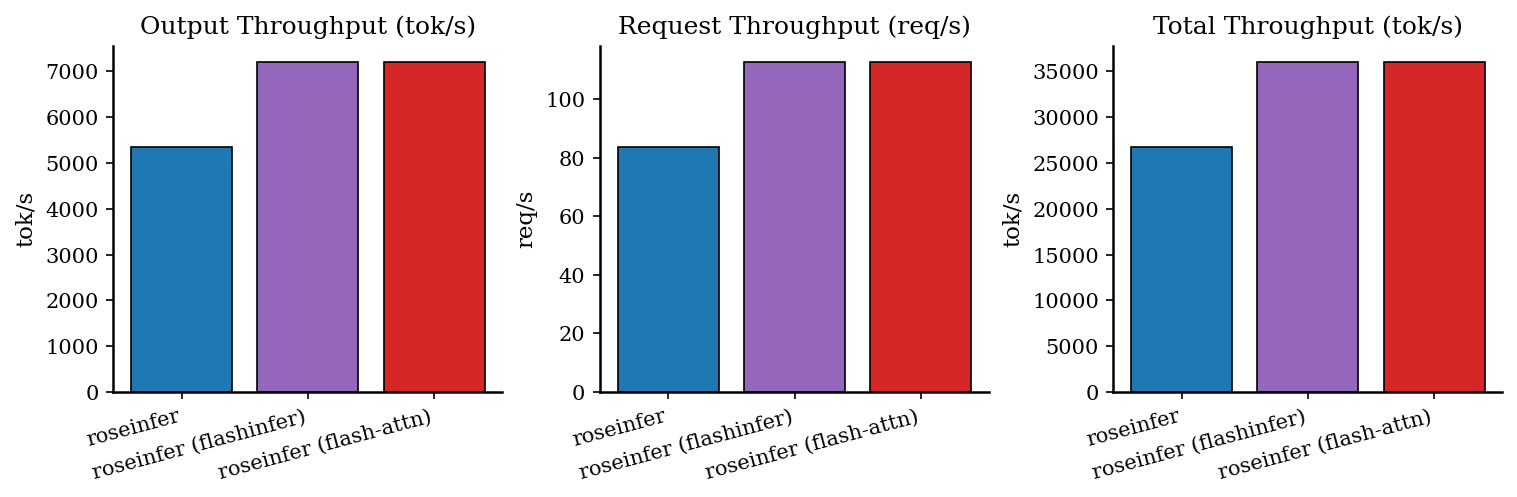
Offline:吞吐对比
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 83.44 | 5339.84 | 26699.21 | 1.534 |
| roseinfer (flash-attn) | 112.51 | 7200.58 | 36002.92 | 1.138 |
| roseinfer (flashinfer) | 112.59 | 7205.57 | 36027.85 | 1.137 |
小结
- Prefill 侧的吞吐收益非常明显:在这组设置下,
output tok/s从5339提升到~7200(约 $1.35\times$)。 - 在线 token-level latency 基本不变(TPOT/ITL):因为 decode 仍沿用 paged attention,FlashAttention 主要影响的是 TTFT/prefill 阶段。
- 下一步如果要继续吃收益,通常会落在:
paged KV的 decode kernel(flashinfer decode / 自研 paged attention)和更激进的 batching/scheduling;但那会涉及更大的接口与内存布局改造,这篇先把 prefill 的“可插拔 + 可回归”链路做完整。