从零实现 LLM Inference:068. Chunked Prefill(给 roseinfer 加增量 Prompt Ingestion)
这篇把 roseinfer 补上一个“缺了就很难跟业内对齐”的能力:chunked prefill(也常被叫作 chunked context / incremental prefill)。
一句话说清楚它解决什么问题:
- 长 prompt 的 prefill 是计算密集型热点,容易把 decode 的小步迭代(带宽瓶颈)“顶住”,导致在线指标里
ITL/TPOT变差,甚至出现 head-of-line blocking。 - chunked prefill 把 prompt 切成小块,每次只“吃”一部分 prompt token,并在 batch/iteration 层面与 decode 交错,从而让 decode 更平滑。
我们这次的实现目标是:
- 正确性不打折:chunked 与非 chunked 的 logits 语义一致(同一模型、同一输入,输出一致)。
- 工程上优雅可插拔:默认路径不变;chunked 通过开关启用,并能稳定回归对比。
- 跟 paged KV cache 设计对齐:复用
roseinfer现有 paged decode 的 KV 管理。
业界调研:vLLM / SGLang / TensorRT-LLM 怎么做 chunked prefill
1) vLLM:decode 优先 + token budget 下自动 chunk
vLLM V1 的描述非常清晰:chunked prefill 启用后,scheduler 会 先 batch 所有 decode,再在 max_num_batched_tokens 的剩余 token budget 里塞 prefill;如果某条 prefill 太长塞不进去,就自动切 chunk。
这带来两个直接收益:
- decode 被优先保障,
ITL更稳定; - 把 compute-bound(prefill)和 memory-bound(decode)交织起来,提高 GPU 利用率。
2) SGLang:chunk size 显式可控 + 可选 mixed chunk
SGLang 把 chunked prefill 作为显式参数暴露出来:
--chunked-prefill-size:每个 chunk 的最大 token 数(设为-1可以禁用)--enable-mixed-chunk:允许在一个 batch 里混 prefill chunk 与 decode(更接近“业内最强形态”)
并且很明确地提示:如果长 prompt prefill 过程中 OOM,首先尝试把 chunk size 调小。
3) TensorRT-LLM:IFB + paged KV + chunked context(推荐默认开)
TensorRT-LLM 把 continuous batching 叫 IFB(in-flight batching),并强调:
- 为了效率,输入必须是 packed(remove padding)
- chunked context 依赖 paged KV cache,且 chunk size(除最后一段外)要对齐 KV block size
他们在 scheduler 可视化文档里给出的结论也很强硬:chunked context 能显著改善“长 prompt 导致无法被调度”的 worst-case,建议默认开启。
注意:TensorRT-LLM 还单独提到 “chunked attention”(只在 chunk 内注意力)和 sliding window 等近似手段;这类会改变注意力 mask。我们这篇实现的是 chunked context/prefill:仍是全因果 mask,不改变语义。
Chunked Prefill 的正确性:为什么切 chunk 不会改变输出?
对标准因果 attention:
\[\mathrm{Attn}(Q,K,V) = \mathrm{softmax}\left(\frac{QK^\top}{\sqrt d}\right)V\]对一个 prompt token 序列 $x_0,\dots,x_{L-1}$,在任意一层里,位置 $t$ 的输出只依赖 前缀:
\[h_t = \mathrm{Attn}\left(q_t,\;K_{0:t},\;V_{0:t}\right)\]chunked prefill 做的只是把 $t=0\ldots L-1$ 的计算拆成多次执行:
- 先算 chunk1:$[0,c)$,把对应的 $K,V$ 写入 KV cache
- 再算 chunk2:$[c,2c)$,此时 KV cache 已包含 $[0,c)$,我们追加写入 $[c,2c)$,并用 causal mask 保证每个 token 只看 $K_{0:t}$
- 以此类推
只要每次计算 chunk 时满足:chunk 内 token 的 $K,V$ 已被写入到“对应位置”的 KV cache,并且 attention kernel 使用 causal mask,那么每个 $h_t$ 的依赖集合仍是 $K_{0:t},V_{0:t}$,语义就不会变。
我们的设计:paged KV + flashinfer paged prefill + 两队列 scheduler
这一版 chunked prefill 的关键点可以概括为三件事:
- KV 元数据先 reserve:chunk 进来前,先在
KVBlockManager里把 KV slot(paged blocks)分配好,并处理好 COW(copy-on-write)。 - KV 写入交给 kernel:prefill chunk 的每一层 attention 里,用
flashinfer.append_paged_kv_cache把新 token 的 $K,V$ 直接写进 paged KV cache,然后用BatchPrefillWithPagedKVCacheWrapper计算 attention 输出。 - scheduler 层面交错 decode/prefill:新增
ChunkedOnlineScheduler,每个step()里先跑一轮 decode micro-batch,再跑一轮 prefill micro-batch(每条请求只推进prefill_chunk_size个 token)。
核心开关
server 侧新增两个参数:
--chunked-prefill:开启 chunked prefill--prefill-chunk-size:每次最多 prefill 多少 token(默认 256)
并且强制要求:
- chunked prefill 必须配合
--paged-attn(paged KV cache) - CUDA AMP(fp16/bf16)+
flashinfer(我们当前使用 flashinfer 的 paged prefill kernel)
代码改造:关键改动点(按文件快速定位)
rosellm/rosetrainer/attention_backends.py:新增prefill_attention_flashinfer_paged(),用flashinfer.append_paged_kv_cache+BatchPrefillWithPagedKVCacheWrapper做 paged KV 的增量 prefill。rosellm/rosetrainer/model.py:MultiHeadSelfAttention.forward()在paged_kv_cache!=None && T>1时走flashinfer_paged;并修正GPTModel.forward()在use_cache=False分支也要把paged_kv_cache/layer_idx传下去(否则 chunked prefill 不会写 KV)。rosellm/roseinfer/engine.py:KVBlockManager.reserve_append_tokens()(只扩容/处理 COW,不写 KV);InferenceEngine.prefill_chunk_sessions()(一次推进一段 chunk);新增ChunkedOnlineScheduler(两队列:prefill/decode 交错调度)。rosellm/roseinfer/server.py:新增--chunked-prefill/--prefill-chunk-size,并在 server 侧切换使用ChunkedOnlineScheduler(强制要求--paged-attn)。benchmarks/serving/online_compare.py、benchmarks/serving/offline_compare.py:新增--roseinfer-chunked-prefill/--roseinfer-prefill-chunk-size,并在 compare 里增加roseinfer+chunked这个对比项。benchmarks/serving/plot_compare.py:增加roseinfer+chunked的 label/marker/color,保证出图可读。scripts/bench_roseinfer_self_compare.sh:支持ROSEINFER_CHUNKED_PREFILL=1开关,并给 offline 跑法加了更稳妥的默认规模(避免小显存 OOM)。
Benchmark:online/offline 自对比(flashinfer vs chunked prefill)
这篇直接复用 066/067 的 benchmark 框架,只对比 roseinfer 自己:
- baseline:
roseinfer (flashinfer)(整段 prompt 一次性 prefill) - 对比组:
roseinfer (chunked prefill)(增量 prefill + 交错调度)
Online
./.conda/bin/python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--backends roseinfer \
--roseinfer-prefill-attn-backends flashinfer \
--roseinfer-chunked-prefill --roseinfer-prefill-chunk-size 256 \
--roseinfer-paged-attn --roseinfer-cuda-graph \
--n 100 \
--scales 0.4,0.5,0.6,0.7,0.8,1.6 \
--max-output-len 64 \
--ignore-eos
Offline
./.conda/bin/python benchmarks/serving/offline_compare.py \
--model gpt2 --gpu 0 \
--backends roseinfer \
--roseinfer-prefill-attn-backends flashinfer \
--roseinfer-chunked-prefill --roseinfer-prefill-chunk-size 256 \
--roseinfer-paged-attn --roseinfer-cuda-graph \
--num-prompts 128 --input-len 256 --output-len 64 \
--max-batch-size 128 \
--ignore-eos
出图
./.conda/bin/python benchmarks/serving/plot_compare.py \
--online outputs/benchmarks/serving/online_20251225_194350/online_results.json \
--offline outputs/benchmarks/serving/offline_20251225_194303/offline_results.json \
--output-dir outputs/benchmarks/serving/figures/20251225_chunked_prefill
结果(HF GPT-2 / GPU0)
运行环境 / 版本 / 耗时
- versions:
git_rev=278bb83, rosellm=0.1.0, torch=2.6.0, transformers=4.46.3, python=3.11.11 - online:
dtype=fp16,ignore_eos=true,n=100,scales=0.4,0.5,0.6,0.7,0.8,1.6,max_output_len=64, wall=359.63s - offline:
dtype=fp16,ignore_eos=true,num_prompts=128,input_len=256,output_len=64, wall=13.54s
注:绝对数值会随机器/版本波动,重点是同一套脚本固定后,chunked on/off 可以稳定回归对比。
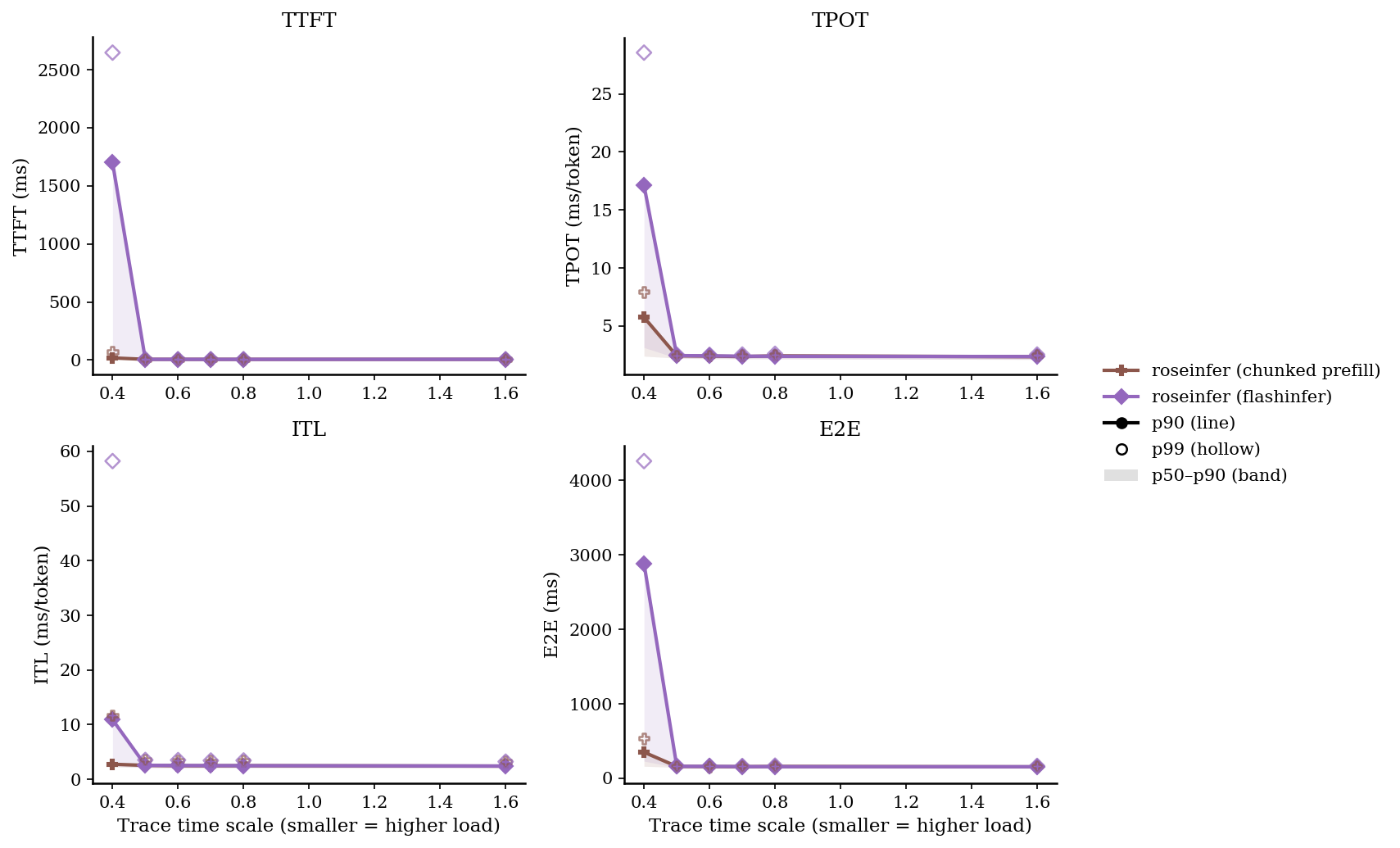
Online:p50/p90/p99(ms)
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer (chunked prefill) | 12.74/18.29/69.68 | 2.39/5.75/7.93 | 2.26/2.76/11.71 | 160.98/350.31/534.18 |
| 0.40 | roseinfer (flashinfer) | 24.22/1700.57/2647.35 | 3.14/17.12/28.56 | 2.47/10.91/58.23 | 229.47/2885.05/4260.07 |
| 0.50 | roseinfer (chunked prefill) | 4.98/6.05/6.99 | 2.22/2.42/2.46 | 2.15/2.55/3.60 | 145.45/158.93/161.32 |
| 0.50 | roseinfer (flashinfer) | 5.12/6.14/7.77 | 2.23/2.45/2.53 | 2.16/2.56/3.54 | 146.01/160.75/164.97 |
| 0.60 | roseinfer (chunked prefill) | 4.92/6.01/6.73 | 2.17/2.41/2.45 | 2.11/2.49/3.47 | 142.32/157.37/160.64 |
| 0.60 | roseinfer (flashinfer) | 5.01/6.09/6.79 | 2.20/2.43/2.51 | 2.14/2.53/3.52 | 144.07/159.46/164.49 |
| 0.70 | roseinfer (chunked prefill) | 5.03/6.02/6.91 | 2.17/2.36/2.47 | 2.11/2.48/3.38 | 142.08/155.50/161.93 |
| 0.70 | roseinfer (flashinfer) | 5.09/6.00/6.93 | 2.19/2.40/2.54 | 2.13/2.51/3.44 | 143.94/157.19/164.81 |
| 0.80 | roseinfer (chunked prefill) | 5.10/5.89/6.88 | 2.18/2.43/2.52 | 2.13/2.50/3.41 | 142.37/159.07/164.06 |
| 0.80 | roseinfer (flashinfer) | 5.08/5.99/7.33 | 2.16/2.38/2.60 | 2.11/2.50/3.45 | 142.07/155.81/169.47 |
| 1.60 | roseinfer (chunked prefill) | 5.26/5.98/6.58 | 2.11/2.35/2.49 | 2.09/2.42/3.25 | 139.00/153.49/161.49 |
| 1.60 | roseinfer (flashinfer) | 5.25/6.10/6.37 | 2.12/2.36/2.54 | 2.09/2.43/3.23 | 139.60/154.83/166.15 |
Online:2x2 指标总览图(p90 曲线 + p50~p90 band,空心点为 p99)
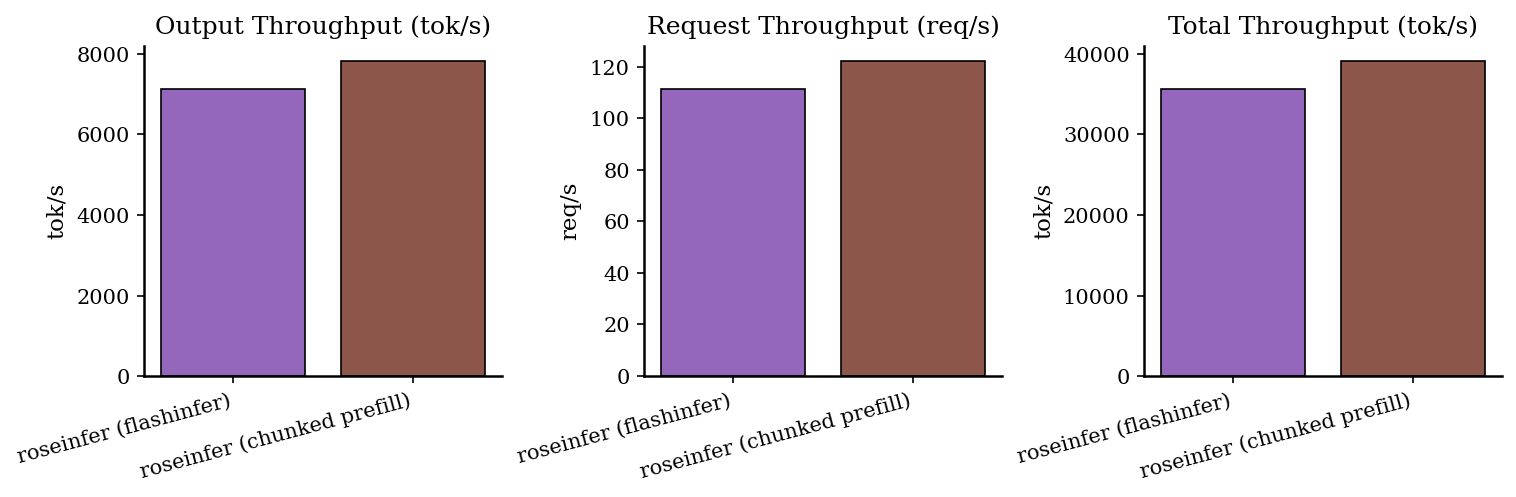
Offline:吞吐对比
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer (chunked prefill) | 122.14 | 7816.87 | 39084.36 | 1.048 |
| roseinfer (flashinfer) | 111.32 | 7124.62 | 35623.12 | 1.150 |
小结
roseinfer现在支持 chunked prefill:增量 prompt ingestion + paged KV cache + 交错调度,并且通过开关可回归对比。- 从 online 结果能看到:在更重的负载点(例如 scale=0.4)chunked 能显著改善 tail(
TTFT/TPOT/ITL/E2E),本质上是在系统层面缓解了 prefill 对 decode 的阻塞。 - 下一步如果要继续贴近 vLLM/TRT-LLM 的“最强形态”,可以把 scheduler 从 “decode batch + prefill chunk batch” 推进到 token budget 下的 mixed chunk packing(同一 iteration 内更细粒度地混合 prefill/decode)。