从零实现 LLM Inference:070. Fused MLP + Fused Sampler + Fused KV Append(把 MLP epilogue / sampling / KV writeback 也做成默认开启)
069 里我们把 “attention 之外” 的第一块成熟融合(fused add+LayerNorm)补上了,同时把 cuda graph / chunked prefill / paged attention / prefix caching 这些业内默认优化都改成了默认开启。
但真要把 decode(T=1) 的尾巴扫干净,通常还剩两类特别“扎眼”的开销:
- Sampler:logits 后处理 + top-k/top-p + sample,如果还是一串 torch op/CPU glue,在高 QPS 时会被放大。
- KV writeback:paged decode 下每步都要把当前 token 的 K/V 写进 cache,如果还是“attention kernel + 每层一个 append kernel”,launch 数和带宽都不划算。
- MLP epilogue:
c_fc + bias后接GELU,再c_proj + bias,最后 residual add。如果拆成多个 elementwise kernel,会在大 batch 下被内存带宽“放大成噪音”。
这篇的目标很明确:把这三块也做成默认开启、可回归、可对比的成熟融合能力。
1) KV append 融合:把 “append” 合进 paged attention decode
旧路径:attention 先算,KV 后写(每层一个 append)
我们当前的 paged attention decode kernel(Triton)在计算 attention 时会用到当前 token 的 $K_{\text{new}},V_{\text{new}}$,但它只参与 attention 计算,并不负责写回 KV cache。
于是 decode 每步还需要:
- 模型 forward 返回每层的
(k_new, v_new)(shape[B, H, 1, D]) KVBlockManager.append_token_batch()再把它们写进k_cache/v_cache
这意味着 每 step 额外多了 n_layers 次 KV append(以及相应的 metadata 处理)。decode(T=1) 下,这种“launch + 带宽”开销非常容易变成 profiler 里的长尾。
新路径:reserve + writeback(kernel 内写回)
核心思路是把 “metadata 决策” 和 “数据写回” 分开:
- forward 之前 reserve:对每个 session、每一层,提前
reserve_append_tokens(n_append=1)- 需要新 block 就先分配
- 需要 COW(prefix cache/shared block)就先 clone
- metadata 的
length提前 +1
- forward 的 attention kernel 内 writeback:paged attention decode kernel 直接把当前 token 的
k_new/v_new写到 cache - forward 之后不再 append:跳过原来的
append_token_batch
写回地址的计算非常直接。设 block size 为 $B$,当前 token 的 position 为 $t$(这里 $t$ 就是 decode step 传进来的 context_len):
再用 paged KV 的 block_table(每个 sequence 的逻辑 block -> 物理 block id)得到:
最终写到:
\[k\_cache[\text{block\_id}, h, \text{offset}, d] \leftarrow K_{\text{new}}[b,h,d]\]对应落地改动:
rosellm/rosetrainer/paged_attention.py:Triton kernel 增加WRITE_KV分支,decode kernel 内写回rosellm/roseinfer/engine.py:decode 前reserve_append_tokens,构造PagedKVCache(write_kv=...),decode 后按开关决定是否还做 appendrosellm/rosetrainer/model.py:paged decode 调用补上write_kv=paged_kv_cache.write_kv
这块默认开启:--fused-kv-append(关闭:--no-fused-kv-append),用于做严谨 A/B。
2) Sampler 融合:把 top-k/top-p + sample 接到 flashinfer
采样里最常见的两个过滤:
- top-k:只保留 logits 最大的 $k$ 个 token
- top-p (nucleus):按概率从大到小累加,保留最小集合使得 $\sum p_i \ge p$
在工程上,Sampler 的性能坑通常来自两类:
- kernel 太碎(topk/softmax/cumsum/multinomial…一串 launch)
- CPU glue 太多(尤其是 admission/prefill 结束采样时,如果按 request 单独做)
这次我们做两点改动:
rosellm/roseinfer/engine.py:加入 flashinfer sampler(默认开启,--fused-sampler/--no-fused-sampler)- 直接走
flashinfer.sampling.top_k_top_p_sampling_from_logits()(避免 “softmax -> probs -> sample” 的 full-vocab 中间张量) - 使用持久化 CUDA generator(避免每次新建 generator 导致“伪随机不前进”)
- 直接走
ChunkedOnlineScheduler.step():prefill 完成后的“第 1 个 token”采样改成 batch 采样(而不是 per-request loop)
注:本次 benchmark 的采样参数是 top_k=50, top_p=0.9。从结果看,Sampler 的收益确实不如 KV writeback / MLP epilogue 那么“明显”,但至少它把采样路径的 kernel 形态收敛成了更接近业界默认的方式:decode 每步采样尽可能留在 GPU 上。
3) MLP epilogue 融合:bias+GELU + (bias+residual)
以 GPT-2 的 FFN 为例(HF 的 c_fc / c_proj),推理里最常见的形态是:
拆开看其实是两次 GEMM + 两段 elementwise:
bias + GELU(对 $xW_1$ 的输出做)bias + residual add(对 $hW_2$ 的输出做)
这两段 elementwise 很“短”,但在大 batch 下会频繁读写中间张量:如果每段都拆成多个 kernel(加 bias、激活、再 add),就会把本来应该被 GEMM 吃掉的时间拉出来。
这次我们做一个非常朴素、但工程上足够“成熟”的处理:
rosellm/rosetrainer/fused_mlp.py:新增两个 Triton kernelbias_gelu_new_():对[N, D]的激活矩阵做(x + bias) -> GELU_newin-placeadd_bias_residual_():对 residual 做residual += y + biasin-place
rosellm/rosetrainer/model.py:在 eval + CUDA +activation=gelu_new场景,FFN 走 fused fast path(默认开启)
这块默认开启:--fused-mlp(关闭:--no-fused-mlp),用于做严谨 A/B。
4) 开关体系:默认全开,只对比目标项
本篇新增三组开关,默认都为 true:
--fused-mlp/--no-fused-mlp--fused-sampler/--no-fused-sampler--fused-kv-append/--no-fused-kv-append
同时延续 069 的“业内默认开”体系(paged attention / cuda graph / chunked prefill / prefix cache / fused ops 都默认开),benchmark 时只切换这次新增的三项做 A/B。
Benchmark:online/offline(A/B:fused mlp / fused sampler / fused kv append)
Online(TraceA 回放)
python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--roseinfer-compare-fused-mlp \
--roseinfer-compare-fused-sampler \
--roseinfer-compare-fused-kv-append
Offline(吞吐)
python benchmarks/serving/offline_compare.py \
--model gpt2 --gpu 0 \
--max-batch-size 32 \
--roseinfer-compare-fused-mlp \
--roseinfer-compare-fused-sampler \
--roseinfer-compare-fused-kv-append
注:这台卡是 12GB 级别。offline 这里如果用 --max-batch-size 256,chunked prefill 的 [B, chunk, vocab] logits 会直接 OOM;所以我们把 scheduler 的 batch size 控到 32(吞吐对比依然成立)。
结果(HF GPT-2 / GPU0)
运行环境 / 版本 / 耗时(这次跑出来的真实数据)
- versions:
git_rev=8ca1ef9, rosellm=0.1.0, vllm=0.13.0, sglang=0.5.6.post2, torch=2.9.0, transformers=4.57.1, python=3.10.9 - online:
dtype=fp16,n=1000,scales=0.4,0.5,0.6,0.7,0.8,1.6, wall=8664.13s - offline:
dtype=fp16,num_prompts=256,input_len=512,output_len=128,max_batch_size=32, wall=90.24s
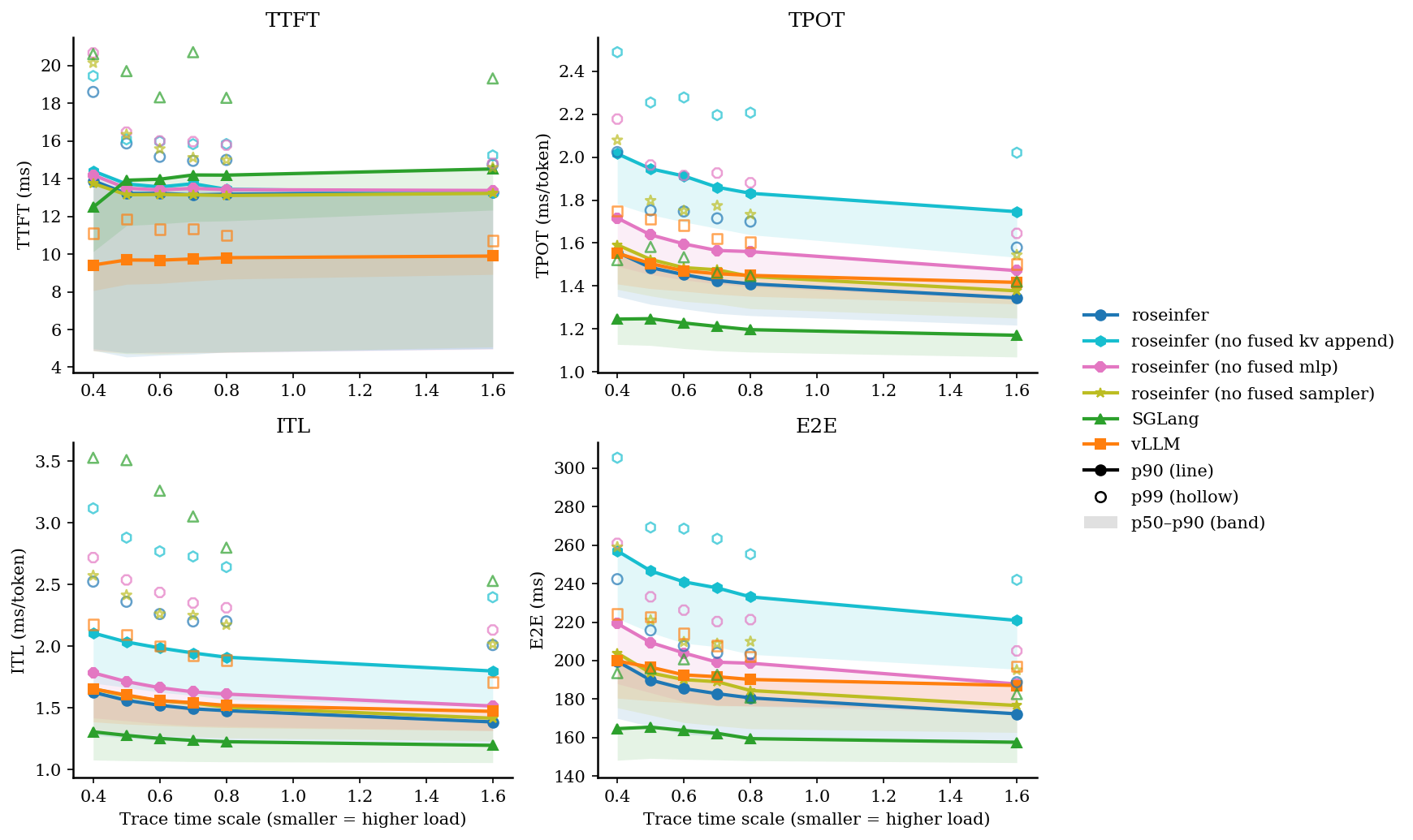
Online:p50/p90/p99(ms)
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer | 4.90/13.89/18.60 | 1.35/1.56/2.02 | 1.28/1.63/2.52 | 170.01/199.66/242.30 |
| 0.40 | roseinfer (no fused kv append) | 4.99/14.41/19.45 | 1.78/2.02/2.49 | 1.70/2.11/3.12 | 221.88/256.98/305.34 |
| 0.40 | roseinfer (no fused mlp) | 4.89/14.20/20.67 | 1.49/1.72/2.18 | 1.42/1.78/2.72 | 188.01/219.27/260.89 |
| 0.40 | roseinfer (no fused sampler) | 4.86/13.75/20.14 | 1.38/1.59/2.08 | 1.32/1.66/2.57 | 175.54/203.93/258.95 |
| 0.40 | SGLang | 10.13/12.49/20.61 | 1.13/1.25/1.52 | 1.08/1.31/3.53 | 148.27/164.69/193.53 |
| 0.40 | vLLM | 8.06/9.42/11.11 | 1.41/1.55/1.75 | 1.39/1.65/2.18 | 180.52/199.81/224.13 |
| 0.50 | roseinfer | 4.54/13.22/15.87 | 1.31/1.49/1.75 | 1.26/1.56/2.36 | 165.75/189.91/215.72 |
| 0.50 | roseinfer (no fused kv append) | 4.76/13.72/16.09 | 1.73/1.95/2.26 | 1.67/2.03/2.88 | 214.59/246.62/269.15 |
| 0.50 | roseinfer (no fused mlp) | 4.79/13.50/16.47 | 1.45/1.64/1.96 | 1.40/1.71/2.54 | 183.32/209.42/233.14 |
| 0.50 | roseinfer (no fused sampler) | 4.72/13.15/16.34 | 1.35/1.52/1.80 | 1.30/1.60/2.41 | 171.78/193.63/221.02 |
| 0.50 | SGLang | 11.51/13.92/19.71 | 1.12/1.25/1.58 | 1.07/1.28/3.51 | 149.24/165.46/195.93 |
| 0.50 | vLLM | 8.40/9.69/11.86 | 1.39/1.50/1.71 | 1.37/1.60/2.09 | 179.12/196.58/222.76 |
| 0.60 | roseinfer | 4.63/13.22/15.16 | 1.29/1.45/1.75 | 1.23/1.52/2.26 | 161.79/185.49/207.63 |
| 0.60 | roseinfer (no fused kv append) | 4.81/13.57/15.97 | 1.70/1.91/2.28 | 1.63/1.99/2.77 | 209.05/240.90/268.52 |
| 0.60 | roseinfer (no fused mlp) | 4.76/13.41/16.00 | 1.43/1.60/1.91 | 1.37/1.66/2.44 | 178.73/203.98/226.21 |
| 0.60 | roseinfer (no fused sampler) | 4.69/13.16/15.58 | 1.33/1.49/1.75 | 1.27/1.56/2.26 | 167.87/190.14/209.70 |
| 0.60 | SGLang | 11.61/13.97/18.32 | 1.11/1.23/1.53 | 1.07/1.25/3.26 | 148.75/163.73/200.69 |
| 0.60 | vLLM | 8.45/9.68/11.33 | 1.38/1.47/1.68 | 1.36/1.56/2.00 | 178.09/192.61/214.08 |
| 0.70 | roseinfer | 4.69/13.15/14.95 | 1.27/1.43/1.72 | 1.23/1.49/2.20 | 160.94/182.84/204.02 |
| 0.70 | roseinfer (no fused kv append) | 4.81/13.74/15.83 | 1.67/1.86/2.20 | 1.60/1.95/2.73 | 207.19/237.77/263.26 |
| 0.70 | roseinfer (no fused mlp) | 4.78/13.49/15.97 | 1.41/1.57/1.93 | 1.36/1.63/2.35 | 176.85/199.20/220.29 |
| 0.70 | roseinfer (no fused sampler) | 4.76/13.14/15.12 | 1.32/1.48/1.77 | 1.26/1.54/2.25 | 166.18/189.06/208.83 |
| 0.70 | SGLang | 11.73/14.20/20.71 | 1.10/1.21/1.46 | 1.06/1.24/3.05 | 148.46/162.28/192.65 |
| 0.70 | vLLM | 8.57/9.74/11.34 | 1.36/1.46/1.62 | 1.35/1.54/1.92 | 176.57/191.64/207.74 |
| 0.80 | roseinfer | 4.81/13.18/15.00 | 1.26/1.41/1.70 | 1.22/1.48/2.20 | 159.65/180.66/203.44 |
| 0.80 | roseinfer (no fused kv append) | 4.80/13.44/15.84 | 1.64/1.83/2.21 | 1.57/1.91/2.64 | 203.25/233.09/255.25 |
| 0.80 | roseinfer (no fused mlp) | 4.77/13.42/15.78 | 1.40/1.56/1.88 | 1.35/1.61/2.31 | 176.36/198.66/221.30 |
| 0.80 | roseinfer (no fused sampler) | 4.79/13.11/14.99 | 1.29/1.44/1.73 | 1.26/1.51/2.17 | 164.66/184.49/209.90 |
| 0.80 | SGLang | 11.76/14.19/18.29 | 1.09/1.20/1.45 | 1.06/1.23/2.80 | 148.05/159.49/180.79 |
| 0.80 | vLLM | 8.67/9.81/10.99 | 1.35/1.45/1.60 | 1.34/1.52/1.89 | 176.48/190.21/202.00 |
| 1.60 | roseinfer | 4.98/13.28/14.75 | 1.22/1.34/1.58 | 1.20/1.39/2.01 | 157.91/172.38/188.79 |
| 1.60 | roseinfer (no fused kv append) | 4.99/13.28/15.23 | 1.53/1.75/2.02 | 1.51/1.80/2.40 | 195.56/220.89/241.96 |
| 1.60 | roseinfer (no fused mlp) | 4.95/13.38/14.82 | 1.34/1.47/1.65 | 1.32/1.52/2.13 | 172.89/187.87/205.05 |
| 1.60 | roseinfer (no fused sampler) | 5.08/13.22/14.59 | 1.25/1.38/1.54 | 1.23/1.42/2.02 | 162.70/176.70/195.11 |
| 1.60 | SGLang | 12.34/14.52/19.32 | 1.07/1.17/1.42 | 1.06/1.20/2.53 | 147.05/157.62/182.65 |
| 1.60 | vLLM | 8.92/9.90/10.71 | 1.32/1.42/1.50 | 1.32/1.47/1.71 | 175.24/187.10/197.02 |
Online:2x2 指标总览图(p90 曲线 + p50~p90 band,空心点为 p99)
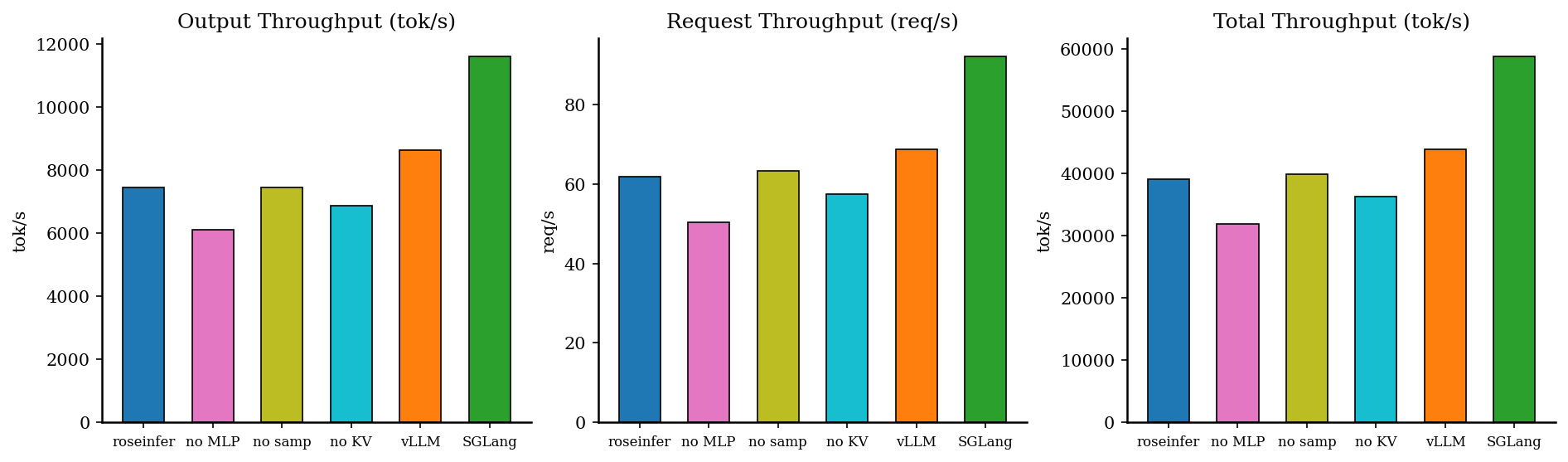
Offline:吞吐对比
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 61.71 | 7461.84 | 39059.34 | 4.148 |
| roseinfer (no fused kv append) | 57.46 | 6868.82 | 36286.89 | 4.455 |
| roseinfer (no fused mlp) | 50.35 | 6111.53 | 31891.16 | 5.084 |
| roseinfer (no fused sampler) | 63.24 | 7451.94 | 39829.74 | 4.048 |
| SGLang | 92.14 | 11628.04 | 58803.88 | 2.778 |
| vLLM | 68.70 | 8631.43 | 43804.40 | 3.726 |
小结 & 下一步
fused kv append在 decode(T=1) 的收益非常稳定:把每步的 “per-layer append kernel” 干掉后,TPOT/ITL/E2E都明显改善。fused mlp的收益在 online/offline 都更“硬”:no fused mlp会把TPOT/ITL/E2E拉高一档,说明这类 elementwise epilogue 在大 batch 下确实会变成带宽噪音。fused sampler在top_k=50, top_p=0.9下收益不算大,但现在采样路径已经收敛到 flashinfer 的 from_logits kernel;后续更值得继续做的是把更多 logit processor(温度/惩罚/约束)也“像业界一样”尽量留在 GPU 上。