从零实现 LLM Inference:071. Multiprocess Serving(engine process)让 roseinfer 的 Online 延迟稳定下来
这篇做一件“非常工程”的事:把 roseinfer 的 serving 从单进程改成多进程拆分,并且像业界那样留下:
- 为什么拆、怎么拆(调研 + 取舍)
- 怎么实现(踩坑 + 关键细节)
- 拆完到底值不值(online/offline 两套 benchmark + 图表)
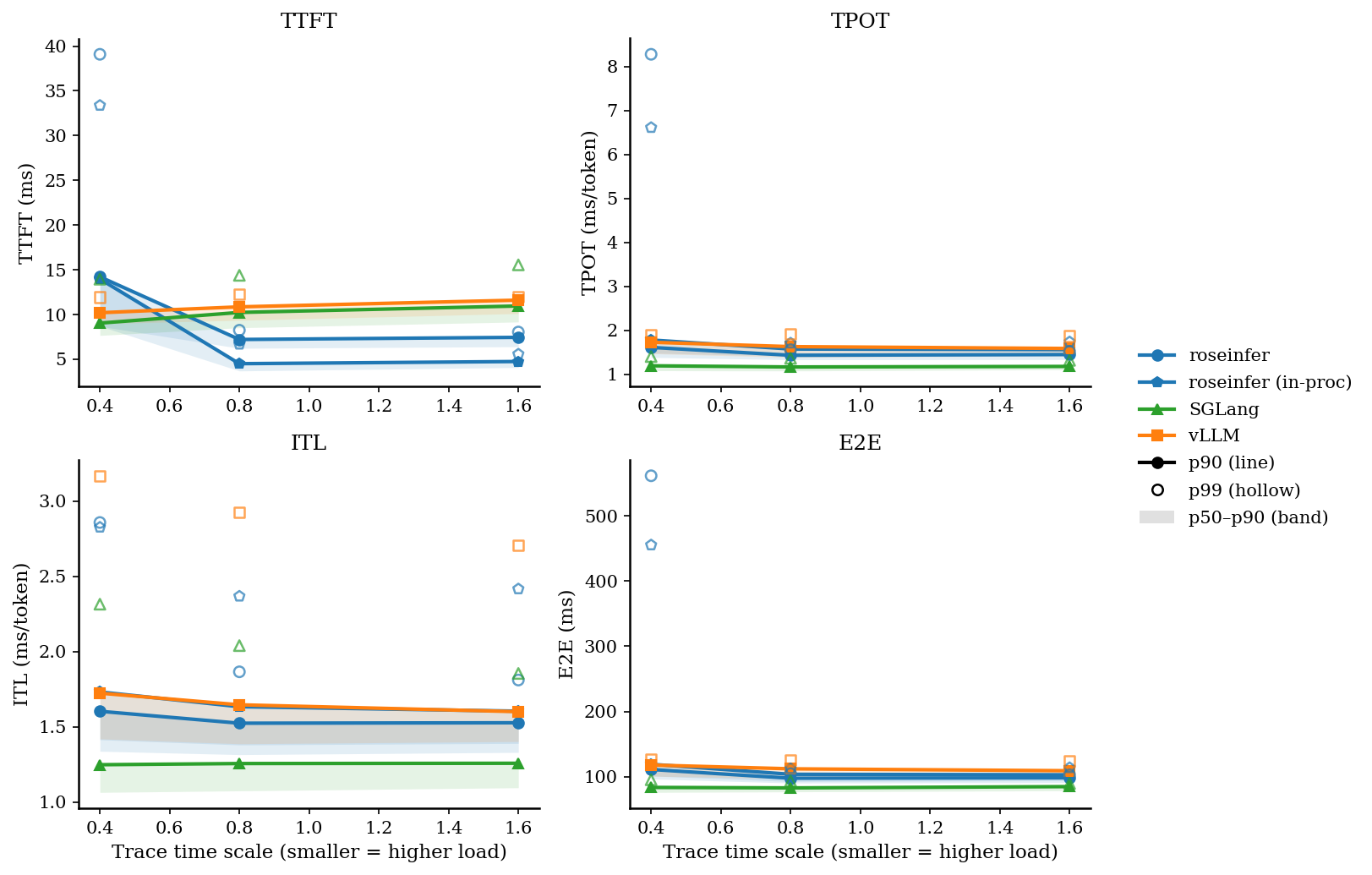
核心结论先放前面:在同一份 trace 的在线压测下,把 engine/scheduler 放到独立进程以后,TPOT/ITL/E2E 的 tail 会明显更稳(尤其是重负载时),而 TTFT 基本不变或略有上升(多了 IPC 固定成本)。
业界调研:vLLM / SGLang / TensorRT-LLM 都在拆什么?
1) vLLM:API Server 和 Engine 可以拆成“前后端”
vLLM 的 OpenAI server(vllm.entrypoints.openai.api_server)本质上也是 FastAPI + engine。关键点是它支持把 engine 变成 RPC(前端只做 HTTP/JSON/SSE,后端做调度与执行),也就是所谓的 “frontend multiprocessing / EngineClient” 思路:
- 目的:隔离 event loop / HTTP 框架的抖动,让 GPU worker 更“干净”
- 工程习惯:对 multiprocessing method(
spawn/forkserver)非常敏感,甚至会 preload 大模块,避免 fork 的坑
这对我们很重要:多进程并不是为了“多核并行算模型”(那是 TP/PP/EP 的事),而是为了把“杂活”从 engine 拿走。
2) SGLang:TokenizerManager + Scheduler + Detokenizer 三段式
SGLang 在 Engine 的 docstring 里把结构写得很直白:
- TokenizerManager(主进程):接 HTTP/SDK 请求、tokenize、把请求送进 scheduler
- Scheduler(子进程,甚至每个 TP rank 一个):调度 batch、forward、把 token id 输出给 detokenizer
- DetokenizerManager(子进程):把 token id 变成字符串/增量 chunk,再回给主进程
通信上用 ZMQ,跨进程传张量时还能选 cuda_ipc(同机多进程零拷贝)。
这种拆分把“CPU 压力”拆得极细:tokenize/detokenize/schedule 都能独立扩展与隔离。
3) TensorRT-LLM:C++ Executor + Scheduler Policy + Inflight Batching
TensorRT-LLM 更像“库 + 服务化组件”,它的重点是:
- C++ runtime 里把 executor 和 scheduler policy(max utilization / guaranteed no evict / static batch)做成可配置
- 还把 inflight batching / disaggregation(prefill/decode 拆开) 作为体系能力的一部分
我们暂时不追 C++ executor,但它给的启发是:“调度”是长期要进化的模块,必须先把边界拆出来。
roseinfer 现状:一个进程干所有事的问题在哪?
目前 rosellm/roseinfer/server.py 的结构(简化)是:
- FastAPI/uvicorn:HTTP + SSE streaming
SchedulerManager:一个 worker thread 循环做:- 接请求(还可能 tokenize)
scheduler.add_requests()做 prefillscheduler.step()做 decode- detokenize,把字符串片段塞回每个 request 的 queue
在吞吐不大时这也能跑,但一旦在线负载上来,单进程的典型问题就会出现:
- 抢 CPU / GIL 抖动:HTTP 解析 + JSON + SSE 拼装 + tokenize/detokenize 都会影响 scheduler loop
- 难绑核:server 需要的 CPU 核心数、engine 需要的 CPU 核心数并不一样,但单进程很难“分区”
- 隔离性差:任何一段 CPU work 的尖峰都会反映成
ITL的尾部抖动(token-level latency jitter)
所以我们的目标是:让 engine 进程只做“该它做的事”,剩下的留在 API 进程。
设计:极简但高收益的拆分 —— API 进程 + Engine 进程
对齐 vLLM/SGLang 的思路,但考虑 roseinfer 当前体量,我选了一个“最小改动、收益最大”的拆分:
(HTTP / SSE)
Client <-----------------> API Process
| tokenize / detokenize
| per-request stream buffer
v
IPC (multiprocessing.Queue)
^
| scheduler + model + KV
|
Engine Process
1) 关键边界
- Engine Process:拥有
InferenceEngine + OnlineScheduler/ChunkedOnlineScheduler + KV cache - API Process:只做 IO + (de)tokenize + 把 token id 变成 streaming text chunk
2) IPC 设计:按 step 批量发 token,避免 per-token IPC
在线 decode 的节奏是“一步出一批 token”(一个 step 给 active batch 每条序列各产一个 token)。
所以 IPC 事件按 step 聚合成:
tokens: {rid -> [token_ids...]}(同一步内,一个 rid 可能有 1~2 个 token:prefill 后的首 token + decode step token)finished_ids: [...]
这样消息频率是 “scheduler iteration 级别”,而不是 “token 级别”,能把 IPC 开销压到很低。
3) Cancel:客户端断连必须能释放 KV
如果 client 断连但 engine 还在生成,那就是白跑 + KV 泄漏风险。
所以在 stream_text() 的 finally 里会发 CancelRequestCmd 到 engine 进程。
4) Feature toggle(默认开)
- server:
--engine-process/--no-engine-process(默认--engine-process) - benchmark:
--roseinfer-compare-engine-process(一键 A/B)
实现:代码结构与关键改动
1) 新增:rosellm/roseinfer/mp.py
EngineProcessArgs:engine/scheduler 的启动参数(HF/ckpt、dtype、paged attn、fused ops 等)_engine_process_main():子进程主循环(接收 Add/Cancel,执行 add/step,发 TokensEvent)MPSchedulerManager:API 进程侧的 manager(维护 detokenizer + stream buffer,收 TokensEvent 并转成字符串 chunk)
2) 抽公共 detokenizer 工厂
rosellm/roseinfer/detokenizer.py 增加 build_detokenizer(),避免 engine 与 mp manager 各写一份 “gpt2 用 tiktoken byte decode,否则 fallback” 的逻辑。
3) server 改造:统一走 scheduler 路径
rosellm/roseinfer/server.py:
- 加
--engine-process/--no-engine-process - 启动时:
- engine-process:创建 tokenizer +
MPSchedulerManager - in-proc:创建
InferenceEngine+SchedulerManager
- engine-process:创建 tokenizer +
/generate、/v1/*的 non-stream 也统一用 scheduler 跑完再拼字符串(这样 API/engine 的行为一致)
4) benchmark & plot
benchmarks/serving/online_compare.py:- 新增
--roseinfer-compare-engine-process - vLLM 0.7.2 不支持
--stream-interval,这里兼容掉
- 新增
benchmarks/serving/offline_compare.py:- vLLM 0.7.2 里
top_k=0不合法(disable 用-1),做了兼容
- vLLM 0.7.2 里
benchmarks/serving/plot_compare.py:- 识别
roseinfer+inproc,图例能显示 “roseinfer (in-proc)”
- 识别
5) 测试
新增 tests/test_mp_scheduler_manager.py:CPU toy engine + MPSchedulerManager 跑通 streaming,保证 mp 基建不回归。
Benchmark:online + offline(含 A/B)
Online:指标回顾
对一次 streaming completion,记:
- request 发出时刻:$t_0$
- 第一个 token 到达时刻:$t_1$
- 第 $i$ 个 token 到达时刻:$t_i$
- 最后一个 token 到达时刻:$t_N$
那么:
- $\mathrm{TTFT} = t_1 - t_0$
- $\mathrm{ITL}i = t_i - t{i-1}\ (i \ge 2)$
- $\mathrm{TPOT} = \frac{1}{N-1}\sum_{i=2}^{N}\mathrm{ITL}_i$
- $\mathrm{E2E} = t_N - t_0$
Online:一键跑(roseinfer mp vs roseinfer in-proc vs vLLM vs SGLang)
python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--backends roseinfer,vllm,sglang \
--roseinfer-compare-engine-process \
--n 200 --scales 0.4,0.8,1.6 \
--max-output-len 64 \
--ignore-eos \
--timeout-ready-s 600
结果文件:outputs/benchmarks/serving/online_*/online_results.json
Online:p50/p90/p99(ms)
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer | 8.68/14.22/39.09 | 1.38/1.61/8.27 | 1.34/1.60/2.86 | 96.46/111.01/561.73 |
| 0.40 | roseinfer (in-proc) | 8.71/13.97/33.37 | 1.48/1.78/6.61 | 1.41/1.73/2.83 | 101.05/118.99/455.46 |
| 0.40 | SGLang | 7.66/9.04/13.95 | 1.08/1.19/1.40 | 1.06/1.25/2.31 | 75.84/83.45/95.21 |
| 0.40 | vLLM | 8.99/10.20/11.96 | 1.47/1.73/1.89 | 1.42/1.72/3.17 | 100.69/117.82/125.94 |
| 0.80 | roseinfer | 6.23/7.21/8.25 | 1.33/1.43/1.56 | 1.31/1.52/1.87 | 90.19/97.55/104.71 |
| 0.80 | roseinfer (in-proc) | 3.70/4.51/6.68 | 1.41/1.57/1.71 | 1.38/1.63/2.37 | 92.57/103.61/112.00 |
| 0.80 | SGLang | 8.53/10.24/14.38 | 1.08/1.17/1.36 | 1.07/1.26/2.04 | 76.67/82.71/93.40 |
| 0.80 | vLLM | 9.36/10.86/12.25 | 1.38/1.63/1.91 | 1.39/1.65/2.93 | 96.83/112.00/125.81 |
| 1.60 | roseinfer | 6.40/7.45/8.05 | 1.34/1.45/1.52 | 1.33/1.53/1.81 | 90.92/98.21/102.74 |
| 1.60 | roseinfer (in-proc) | 4.08/4.75/5.57 | 1.42/1.56/1.73 | 1.39/1.60/2.42 | 93.86/102.86/113.65 |
| 1.60 | SGLang | 9.17/10.96/15.55 | 1.10/1.18/1.32 | 1.09/1.26/1.85 | 78.35/84.70/89.55 |
| 1.60 | vLLM | 10.11/11.61/12.00 | 1.42/1.59/1.87 | 1.40/1.60/2.70 | 99.02/109.06/123.53 |
读法建议:别死盯 TTFT(mp 会多一点固定 IPC 成本),重点看 TPOT/ITL/E2E 的 tail,重负载下更直观。
Online:2x2 指标总览图
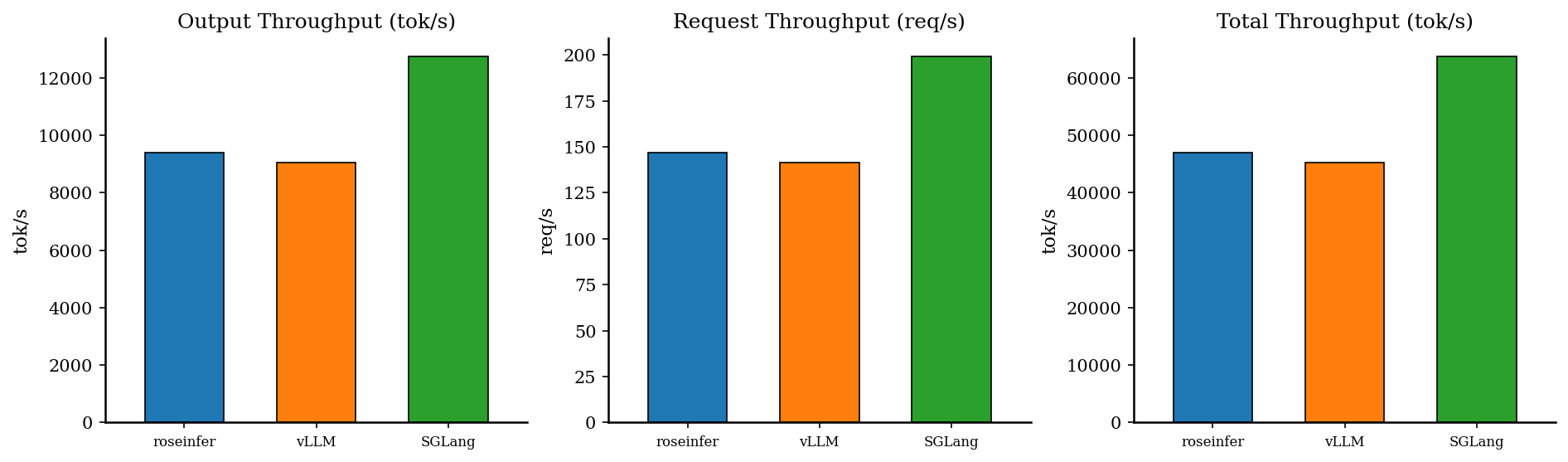
Offline:吞吐对比
python benchmarks/serving/offline_compare.py \
--model gpt2 --gpu 0 \
--backends roseinfer,vllm,sglang \
--num-prompts 128 --input-len 256 --output-len 64 \
--ignore-eos
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 146.73 | 9390.91 | 46954.54 | 0.872 |
| SGLang | 199.35 | 12758.25 | 63791.24 | 0.642 |
| vLLM | 141.21 | 9037.29 | 45186.46 | 0.906 |
踩坑记录(非常真实)
- CUDA + multiprocessing 必须小心 start method:engine 一定要在子进程里初始化,主进程只做 tokenizer/HTTP。
- 没有 Ready handshake 会踩“max_ctx 不一致”:prompt truncate 必须在 API 侧对齐 engine 的
max_position_embeddings,否则 detokenizer 的 prompt 状态会和 engine 的真实 prompt 不一致。 - client 断连必须 cancel:否则 KV cache 会一直占着;多进程以后不能再靠“queue 不存在”这种隐式信号了。
- vLLM 版本/CLI 经常变:
--stream-interval、top_k=0/-1这种细节会直接导致 benchmark 挂掉,必须做兼容分支。 - SGLang 的依赖矩阵也很“工程”:
torchao/transformers/flashinfer的版本一旦不对齐,就会在启动或 CUDA graph replay 时爆炸;这次我把 SGLang 的 attention backend 固定成triton(采样仍用flashinfer),先保证 benchmark 稳定可复现,再谈极限上限。
小结
- 业界共同做法:把 serving 拆成“IO/Tokenizer/Detokenizer”与“Scheduler/Model/KV”两类模块,优先保证后者的稳定与隔离。
- 这次 roseinfer 先落一个最小可行版本:API 进程 + Engine 进程,并把它做成默认开启的 feature toggle。
- 从同一套 trace 的 online benchmark 看,
TPOT/ITL/E2E的 tail 确实更稳;下一步如果要继续追 SGLang 的上限,就可以再把 tokenizer/detokenizer 拆成独立进程,甚至引入cuda_ipc做零拷贝传输。