从零实现 LLM Inference:075. Online P99 长尾时延:从 700ms 尾巴到 vLLM 级别
这篇只盯一件事:online serving 的 P99 长尾。
在 074 里,multiprocess 拆分、绑核、IPC、profile harness 我都补齐了;但把线上 trace 一压,P99 还是会出现很不讲道理的尾巴——平均看着挺顺,少数请求突然被“卡”一大截。
这种问题最烦的点是:你很难靠直觉猜对。必须把问题拆成可量化的东西,然后一层层排。
Benchmark 形态
我这里沿用项目里现成的 online benchmark:
- trace stage:按真实线上 trace 的时间戳回放请求(缩放因子
scale越小,负载越大) - profile stage:单独跑一个很小的样本专门采 profile,避免 profile 影响 benchmark 数据
指标还是四个:
- TTFT:time-to-first-token
- ITL:inter-token latency
- TPOT:time per output token
- E2E:端到端
简单记法(以输出 token 数为 $N$):
\[\mathrm{TPOT} = \frac{t_{end}-t_{first}}{N-1},\quad \mathrm{E2E} = t_{end}-t_{start}\]P99 的“长尾”一般会在 ITL 上体现得最明显:某些 token 间隔突然变大,把整条请求拉长。
先把现象钉死
我把这次 075 的 online 对比合并成一张图(roseinfer 的几组开关来自本地最新 main,vLLM/SGLang/TensorRT-LLM 用之前跑过的现成数据,不重复测)。
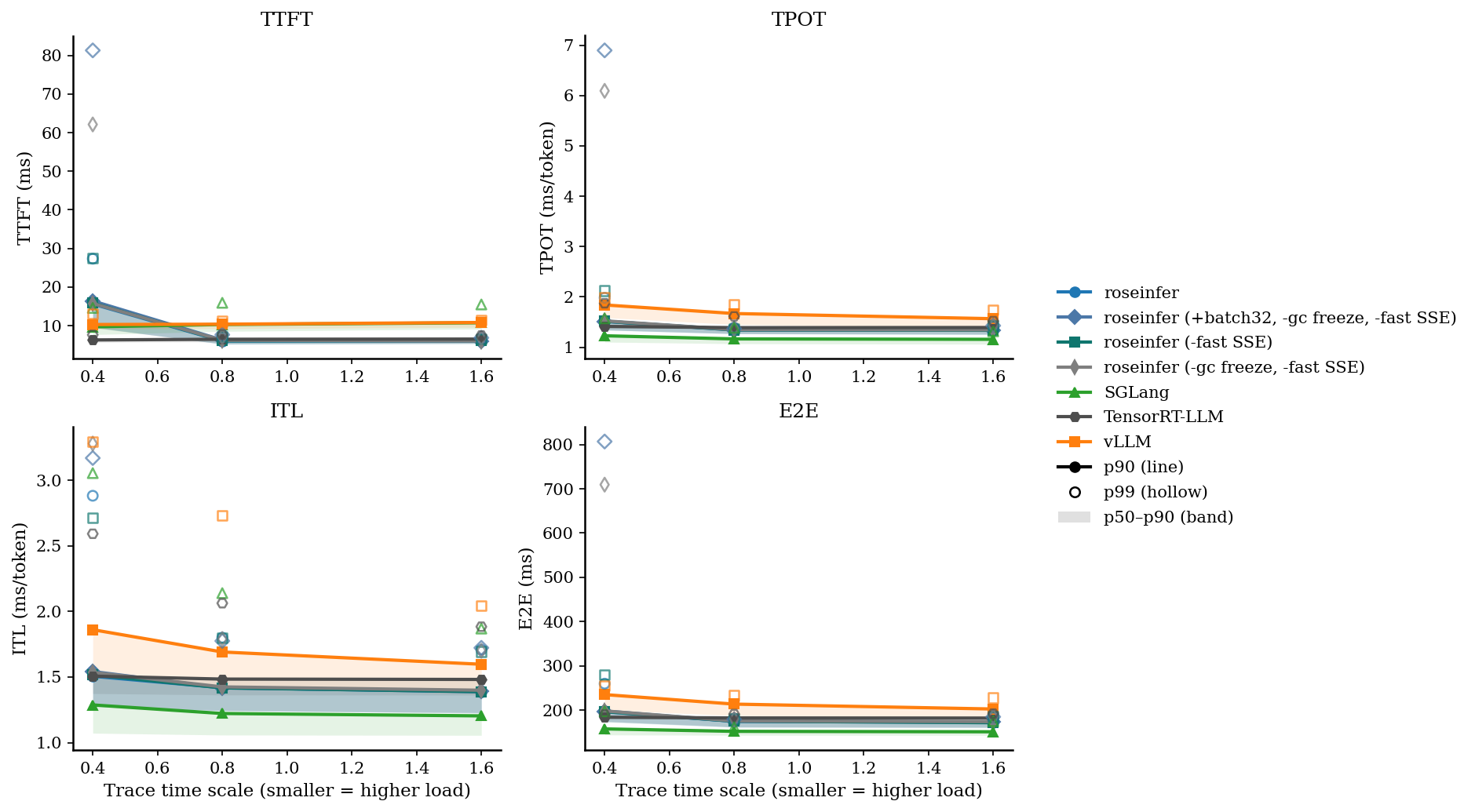
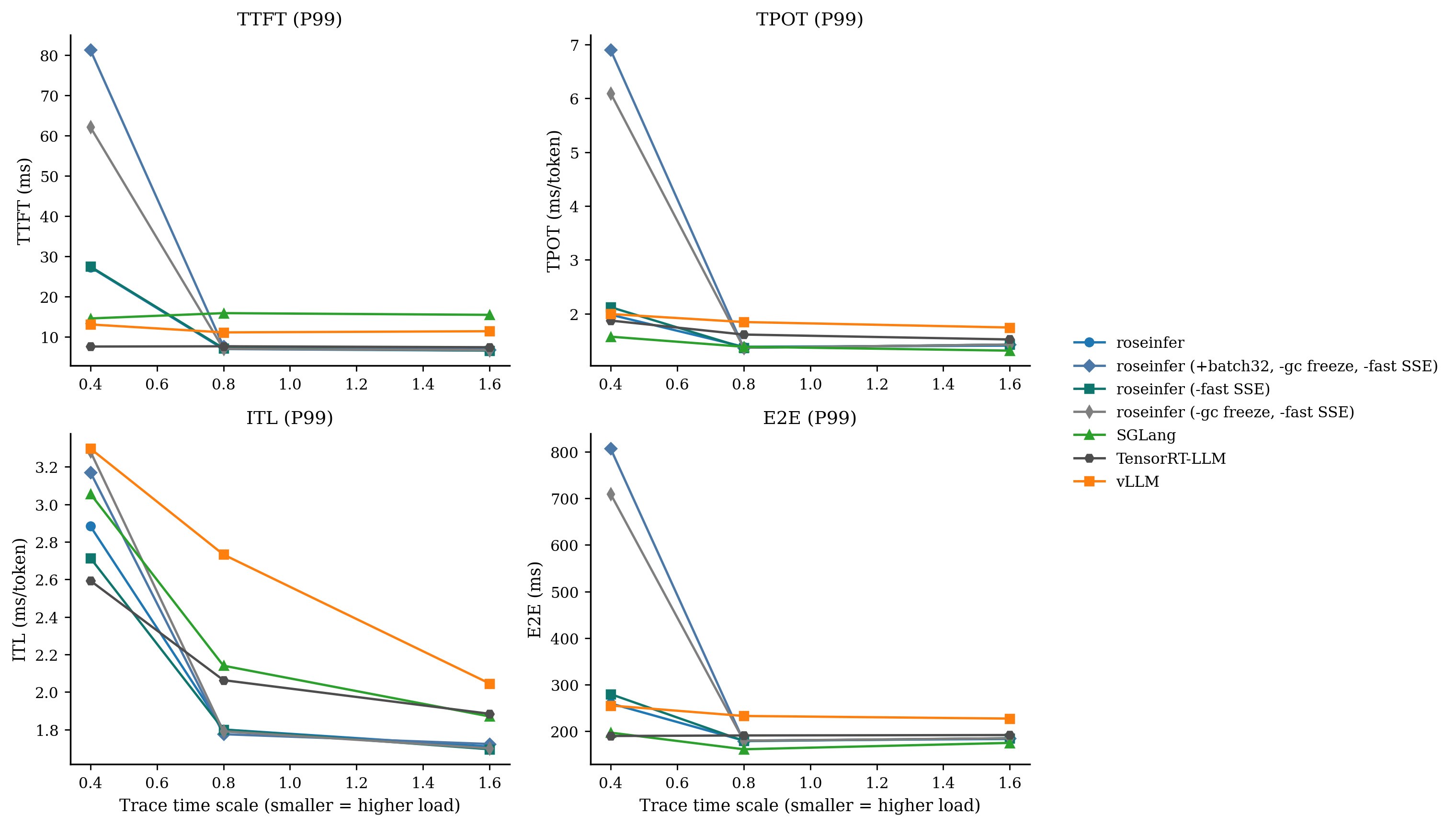
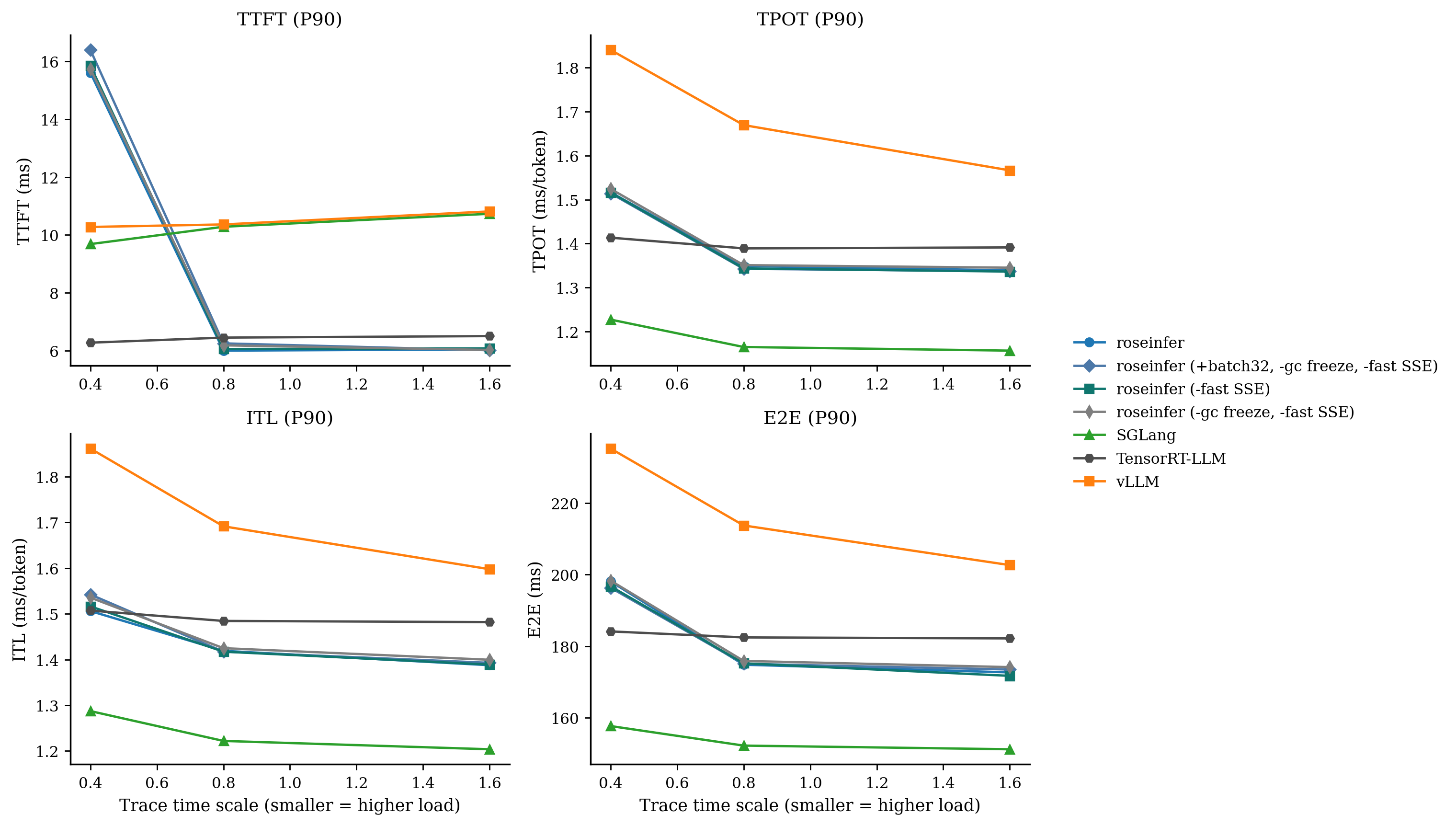
只看 P99 / P90 会更直观:
然后把 scale=0.4(最重负载)那一格的原始数字直接贴出来,避免“看图说话”:
| backend | TTFT p90 (ms) | TTFT p99 | TPOT p90 (ms/tok) | TPOT p99 | E2E p90 (ms) | E2E p99 |
|---|---|---|---|---|---|---|
| roseinfer | 15.60 | 27.33 | 1.516 | 1.982 | 198.08 | 259.92 |
| roseinfer (-fast SSE) | 15.85 | 27.48 | 1.516 | 2.123 | 196.69 | 279.92 |
| roseinfer (-gc freeze, -fast SSE) | 15.74 | 62.12 | 1.524 | 6.093 | 198.28 | 709.39 |
| roseinfer (+batch32, -gc freeze, -fast SSE) | 16.39 | 81.31 | 1.514 | 6.897 | 196.30 | 806.82 |
| vllm | 10.28 | 13.09 | 1.840 | 1.995 | 235.18 | 255.43 |
| sglang | 9.69 | 14.58 | 1.227 | 1.574 | 157.67 | 197.26 |
| trtllm | 6.28 | 7.60 | 1.413 | 1.874 | 184.11 | 190.06 |
这个表格里最刺眼的不是 P90,而是 -gc freeze 之后 P99 直接炸穿:E2E P99 ~700ms,和 P90 ~200ms 差了 3.5 倍。
这就很像典型的“系统抖一下”:平时正常,偶尔停顿。
第一个直觉:是不是 batch 太小导致队列抖动
我第一反应其实很工程:max_batch_size=8 会不会在 trace 高峰时被打爆,导致部分 request 轮询排队,从而拉长 E2E?
于是做了一个最直接的试验:+batch32(加 --max-batch-size=32)。
结果很快把我打醒:scale=0.4 的 E2E P99 反而更差(709ms -> 807ms),TTFT P99 也更差。
结论:这不是“batch 太小”这种简单锅,至少不是主因。
业界的暗示:vLLM / SGLang 都会 freeze GC
我开始去翻业界实现的“服务侧工程细节”,很快就撞到一个很一致的点:它们都主动处理 GC。
vLLM 有专门的 freeze_gc_heap(),直接三次 gc.collect 然后 gc.freeze,注释写得很直白:减少 serving 时 GC overhead 和 jitter(源码:vllm/utils/gc_utils.py)。
SGLang 也提供了 freeze_gc(),同样是为了 latency jitter(源码:python/sglang/srt/utils/common.py)。
这两个信号叠在一起,就很像在说:
如果你在 Python 里做高频 serving,又盯 P99,GC 这关你迟早得过。
GC freeze:把 GC jitter 从线上热路径拿掉
这块我做得很直接:照着业界把 gc.freeze() 接上去,然后用 ablation 证明它确实是“救命稻草”。
- server 增加
--gc-freeze - 对比开关用
--no-gc-freeze - multiprocess 时 API process 和 engine process 都会在 startup/warmup 后执行一次
gc.collect(0/1/2) + gc.freeze()
实现位置:
rosellm/roseinfer/server.py:解析--gc-freeze,在uvicorn.run()之前 freezerosellm/roseinfer/mp.py:engine process warmup 后 freezerosellm/roseinfer/gc_observer.py:顺手补了 GC pause 可观测(下面讲)
结果很干脆:如果把 gc freeze 关掉(并且 fast SSE 也关掉),scale=0.4 的 E2E P99 会从 ~260ms 直接回到 ~700ms。
这基本就是把“病态长尾”一刀切掉:不是平均变快,而是那种偶发的“停顿”消失了。
现在这个优化在 roseinfer 里我直接 默认打开 了,因为它对 P99 是实打实的正收益;要对比就用 --no-gc-freeze。
我最喜欢的一个细节是 ITL 的 max:
-gc freeze, -fast SSE:ITL max ~180ms- 默认配置:ITL max ~30ms
这就很像:之前偶发“停顿”没了。
fast SSE:把 streaming JSON 热路径再瘦一刀
GC freeze 之后,尾巴已经压到 vLLM 量级附近,但我还想再挤一点:P99 ~280ms 距离 vLLM ~255ms 还有个小台阶。
我这里选了一个很明确的 hot path:OpenAI SSE streaming 的 JSON 组装。
之前的实现是每个 stream event 都走一遍 Pydantic model_dump_json(),这条路径会制造很多短命对象。于是我加了 --fast-sse:
- 默认打开(对比用
--no-fast-sse) - 开启时对
/v1/completions的 streaming 走一条更直接的 bytes 拼接路径 - 优先用
orjson.dumps()做字符串转义,避免手写 escape
实现位置:
rosellm/roseinfer/server.py:--fast-sse,create_app(..., fast_sse=...)benchmarks/serving/online_compare.py:--roseinfer-no-fast-sse转成 server 的--no-fast-sse
从表里看得很清楚:只关 fast SSE,scale=0.4 的 E2E P99 会从 ~260ms 回弹到 ~280ms。
这里我比较满意的一点是:P90 几乎没变,说明这是偏“尾巴优化”,不是靠牺牲平均来换尾巴。
业界的 “fast SSE” 长啥样
我这里说的 “fast SSE”,其实就是一句话:别在 token 流的热路径上创建一堆 Python 对象、再让 Pydantic/json 去收拾残局。
这玩意不是什么玄学优化,vLLM/SGLang/TensorRT-LLM 里也都能找到类似取舍,只是落点不太一样。
vLLM:OpenAI streaming 直接 model_dump_json()
vLLM 的 OpenAI completion streaming 路径很直白:每个 chunk 都是一个 Pydantic model,然后 chunk.model_dump_json(...) 再拼成 "data: ...\n\n":
CompletionStreamResponse(...).model_dump_json(...)→yield f"data: {response_json}\n\n"- 源码:https://github.com/vllm-project/vllm/blob/7b5575fa7dcf76ac86ab8d18501b9cc04f74f6bb/vllm/entrypoints/openai/serving_completion.py
Responses API 那边也类似(把 event.type + event.model_dump_json() 包成 SSE):
- 源码:https://github.com/vllm-project/vllm/blob/7b5575fa7dcf76ac86ab8d18501b9cc04f74f6bb/vllm/entrypoints/openai/api_server.py
所以严格讲,vLLM 并没有专门做一个 “fast JSON builder”。它更像是:先把 GC jitter 这种会炸尾的东西处理掉,然后让 streaming 序列化保持足够简单/可维护。
SGLang:有两套路径,一套 orjson,一套 model_dump_json()
SGLang 的 “internal /generate” endpoint(不是 OpenAI 兼容)就非常像我这次的 fast SSE:直接 orjson.dumps(),而且直接 yield bytes:
yield b"data: " + orjson.dumps(out, ...) + b"\n\n"- 源码:https://github.com/sgl-project/sglang/blob/ea177372bd8cb12fca335291e81ef049b8655472/python/sglang/srt/entrypoints/http_server.py
但 OpenAI 兼容的 completion/chat streaming,依然是 chunk.model_dump_json():
- 源码:https://github.com/sgl-project/sglang/blob/ea177372bd8cb12fca335291e81ef049b8655472/python/sglang/srt/entrypoints/openai/serving_completions.py
- 源码:https://github.com/sgl-project/sglang/blob/ea177372bd8cb12fca335291e81ef049b8655472/python/sglang/srt/entrypoints/openai/serving_chat.py
我的理解是:SGLang 更像把 “最快的那条链路” 留给自家 /generate,OpenAI 兼容层优先保证协议一致性和代码清晰。
TensorRT-LLM:把 SSE chunk 生成挪到 postprocess 层,但还是 Pydantic
TensorRT-LLM 的 OpenAI server 里,streaming 时 yield 的字符串基本来自 postprocess handler(比如 chat_stream_post_processor),里面同样会 chunk.model_dump_json(...),再拼 "data: ...\n\n":
- 源码:https://github.com/NVIDIA/TensorRT-LLM/blob/7c82605327ba0f2a04aa6c30f2568c97ab1e0c86/tensorrt_llm/serve/postprocess_handlers.py
- OpenAI server 入口:https://github.com/NVIDIA/TensorRT-LLM/blob/7c82605327ba0f2a04aa6c30f2568c97ab1e0c86/tensorrt_llm/serve/openai_server.py
它看起来并没有刻意去做 “orjson / 手写 JSON builder”,更多是把事情分层:让主执行路径专心跑引擎,把格式化/协议封装放到 postprocess 层去做。
回到 roseinfer:为什么我这里 “fast SSE” 会有感知
这次的 benchmark 是 OpenAI /v1/completions streaming,并且在 scale=0.4 的重负载下我们确实观察到:
- GC freeze 解决的是 “偶发停顿” 这种系统级 jitter;
- fast SSE 解决的是 “每个 token 都要做一次不必要的 Python 分配/序列化”。
它不是万能药(也不是替代引擎优化),但在我们这个栈上,它确实是一个性价比很高的 tail 优化点。
把 GC 变成“能看见的东西”
我对 GC 最不满意的一点是:你不做可观测,它永远像玄学。
所以这次我顺手补了一个很轻量的 GC pause observer:gc.callbacks 里打点,在 log 里直接看到 “哪个 generation、停了多久、一次收了多少对象”。
开关也很简单:
--gc-warn-ms <ms>:只打印超过阈值的 GC pause(默认 0,不打印)--gc-log-all:打印每一次 GC(很吵,只建议短时间开)
如果你同时开了 ROSEINFER_NVTX=1,它还会把 GC pause 打成 NVTX range,和 nsys/torch trace 对齐会更直观。
Offline 吞吐:顺手贴一张,确认没“偷性能”
这次 075 的两个核心点(GC freeze / fast SSE)本质都在 online serving 边界层,按理说不该影响 offline throughput;但我还是把 074 那套 offline 结果也贴过来,避免大家脑补成 “为了 P99 牺牲了吞吐”。
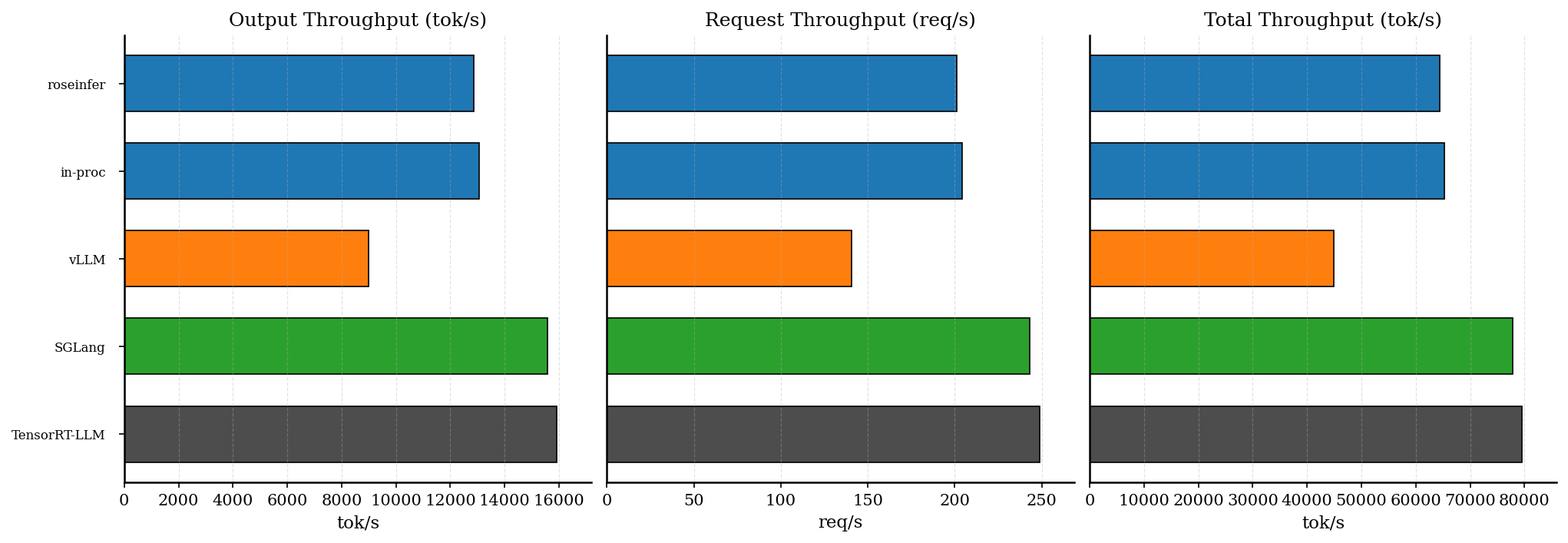
同样把原始数字贴在这里(num_prompts=128, input_len=256, output_len=64, fp16):
| backend | req/s | output tok/s | total tok/s |
|---|---|---|---|
| roseinfer | 201.14 | 12872.99 | 64364.95 |
| roseinfer (in-proc) | 204.01 | 13056.84 | 65284.22 |
| vLLM | 140.44 | 8988.14 | 44940.70 |
| SGLang | 243.20 | 15564.48 | 77822.40 |
| TensorRT-LLM | 248.69 | 15916.24 | 79581.21 |
这里的结论其实也符合直觉:P99 抖动被压住,并不等价于“吞吐变快”。SGLang/TRT-LLM 的 throughput 领先更多来自引擎/算子层面(尤其是 prefill/decode 的 kernel/调度),这也是我前面说的:下一步要继续追它们,得回到更硬的东西。
Profile 文件位置和读法
我这次所有新实验的 profile 都是通过 online_compare 的 profile stage 自动落盘的,位置固定:
roseinfer (-fast SSE)(当时的目录名叫roseinfer+gcfreeze)- torch:
outputs/benchmarks/serving/online_20251230_011122/profiles/torch/roseinfer+gcfreeze/trace.json - nsys:
outputs/benchmarks/serving/online_20251230_011122/profiles/nsys/roseinfer+gcfreeze/nsys.nsys-rep
- torch:
roseinfer(当时的目录名叫roseinfer+gcfreeze+fastsse)- torch:
outputs/benchmarks/serving/online_20251230_014149/profiles/torch/roseinfer+gcfreeze+fastsse/trace.json - nsys:
outputs/benchmarks/serving/online_20251230_014149/profiles/nsys/roseinfer+gcfreeze+fastsse/nsys.nsys-rep
- torch:
vLLM/SGLang/TensorRT-LLM 的历史 profile 在:
outputs/benchmarks/serving/online_20251228_231859/profile_manifest.json
怎么打开:
- torch trace:用 Perfetto 打开
trace.json(Chrome 也行,但 Perfetto 更稳) - nsys:
nsys-ui直接打开.nsys-rep;或者用nsys stats先看个汇总
看什么:
1) 有没有明显的 host-side 大空洞(GPU 空转但请求还没结束),这是尾巴最常见的“罪证” 2) CUDA kernel 的节奏是否均匀,长尾通常对应某些 iter 突然被拖长 3) CPU thread 的占用是否突刺,尤其是 Python runtime / allocator / GC 相关的抖动
小结
这次 P99 长尾的结论比我预期更“朴素”:
+batch32这种“看起来像系统问题”的调参,并不能解决核心矛盾,甚至会负优化- 真正的大头是 GC jitter:freeze 之后尾巴直接断崖式下去
- 在尾巴收敛之后,再去抠 streaming 热路径(fast SSE)可以继续压一点 P99,把结果推到 vLLM 区间
- 这俩现在在 roseinfer 里默认开了;要做 A/B 对比,用
--no-gc-freeze/--no-fast-sse
下一步如果要继续追 SGLang/TRT-LLM 的水平,我的判断就不是“再抠一点系统工程”了,而是要回到更硬的东西:token 侧的 TPOT(尤其是 P90)差距还在,得从 kernel/调度再往里挖。