从零实现 LLM Inference:077. roseinfer vs vLLM vs SGLang vs TensorRT-LLM(baseline)
这篇文章直接用仓库自带的 serving benchmark 跑一轮 baseline,对比 roseinfer / vLLM / SGLang / TensorRT-LLM:
- online latency:TTFT / TPOT / ITL / E2E 的 P50/P90/P99
- offline throughput:req/s、output tok/s、total tok/s
重点:roseinfer 这边保持所有选项的默认值(默认开着的优化就让它开着),用来观察默认配置下与业界框架的差距。
1. Benchmark 设置
1.1 硬件
- GPU0:NVIDIA GeForce RTX 4070(12282 MiB,driver 580.82.07)
1.2 环境与版本
由于 vllm==0.13.0 与 sglang==0.5.7 的 pip 依赖 pin 存在冲突(尤其是 torch / llguidance / outlines_core),所以四个 backend 通过 隔离的 Python env 来跑;路径都放在 repo 根目录下(并已 gitignore)。
| backend | Python env | Python | 关键包 |
|---|---|---|---|
| driver + roseinfer | ./.conda-bench/ |
3.10.9 | rosellm==0.1.0, torch==2.9.1 |
| vLLM | ./.conda-vllm/ |
3.10.19 | vllm==0.13.0, torch==2.9.0 |
| SGLang | ./.conda-sglang/ |
3.10.19 | sglang==0.5.7, torch==2.9.1 |
| TensorRT-LLM | ./.venv-trtllm/ |
3.12.3 | tensorrt_llm==1.1.0 |
跑出来的
online_results.json/offline_results.json里也会把*_python路径和版本写进meta.versions,方便核对“到底用的是哪个 env”。
1.3 统一参数
共同配置(按脚本默认值为主):
- model:
gpt2 - dtype:
fp16 - sampling:
temperature=0.7, top_p=0.9, top_k=50 - GPU:
0 - vLLM attention backend:
flashinfer(并设置--vllm-max-num-seqs=128,否则 vLLM 0.13.0 在 12GB GPU 上可能在 warmup 阶段 OOM) - SGLang attention backend:
triton(sampling backend 用flashinfer)
online(trace replay):
n=200(每个 scale 200 个请求)scales=[0.4, 0.8, 1.6](scale 越小负载越大)max_input_len=None(不限制)max_output_len=128
offline(固定 workload):
num_prompts=128input_len=256output_len=64max_batch_size=256
roseinfer:保持默认配置(不额外传 --roseinfer-* 开关)。
1.4 运行命令
online:
./.conda-bench/bin/python benchmarks/serving/online_compare.py \
--model gpt2 \
--output-dir outputs/benchmarks/serving/baseline_077_final/sglang_triton \
--backends roseinfer,vllm,sglang,trtllm \
--n 200 --scales 0.4,0.8,1.6 --timeout-ready-s 600 \
--vllm-python ./.conda-vllm/bin/python \
--vllm-attention-backend flashinfer --vllm-max-num-seqs 128 \
--sglang-python ./.conda-sglang/bin/python \
--sglang-attention-backend triton --sglang-sampling-backend flashinfer \
--trtllm-python ./.venv-trtllm/bin/python
offline:
./.conda-bench/bin/python benchmarks/serving/offline_compare.py \
--model gpt2 \
--output-dir outputs/benchmarks/serving/baseline_077_final/sglang_triton \
--backends roseinfer,vllm,sglang,trtllm \
--num-prompts 128 --input-len 256 --output-len 64 --max-batch-size 256 \
--vllm-python ./.conda-vllm/bin/python \
--vllm-attention-backend flashinfer --vllm-max-num-seqs 128 \
--sglang-python ./.conda-sglang/bin/python \
--sglang-attention-backend triton --sglang-sampling-backend flashinfer \
--trtllm-python ./.venv-trtllm/bin/python
画图(两张核心图:online/offline 各一张;--online/--offline 换成你自己的输出路径即可):
./.conda-bench/bin/python benchmarks/serving/plot_compare.py \
--online outputs/benchmarks/serving/baseline_077_final/sglang_triton/default/online_results.json \
--offline outputs/benchmarks/serving/baseline_077_final/sglang_triton/default/offline_results.json \
--output-dir outputs/benchmarks/serving/baseline_077_final/sglang_triton/default/figures
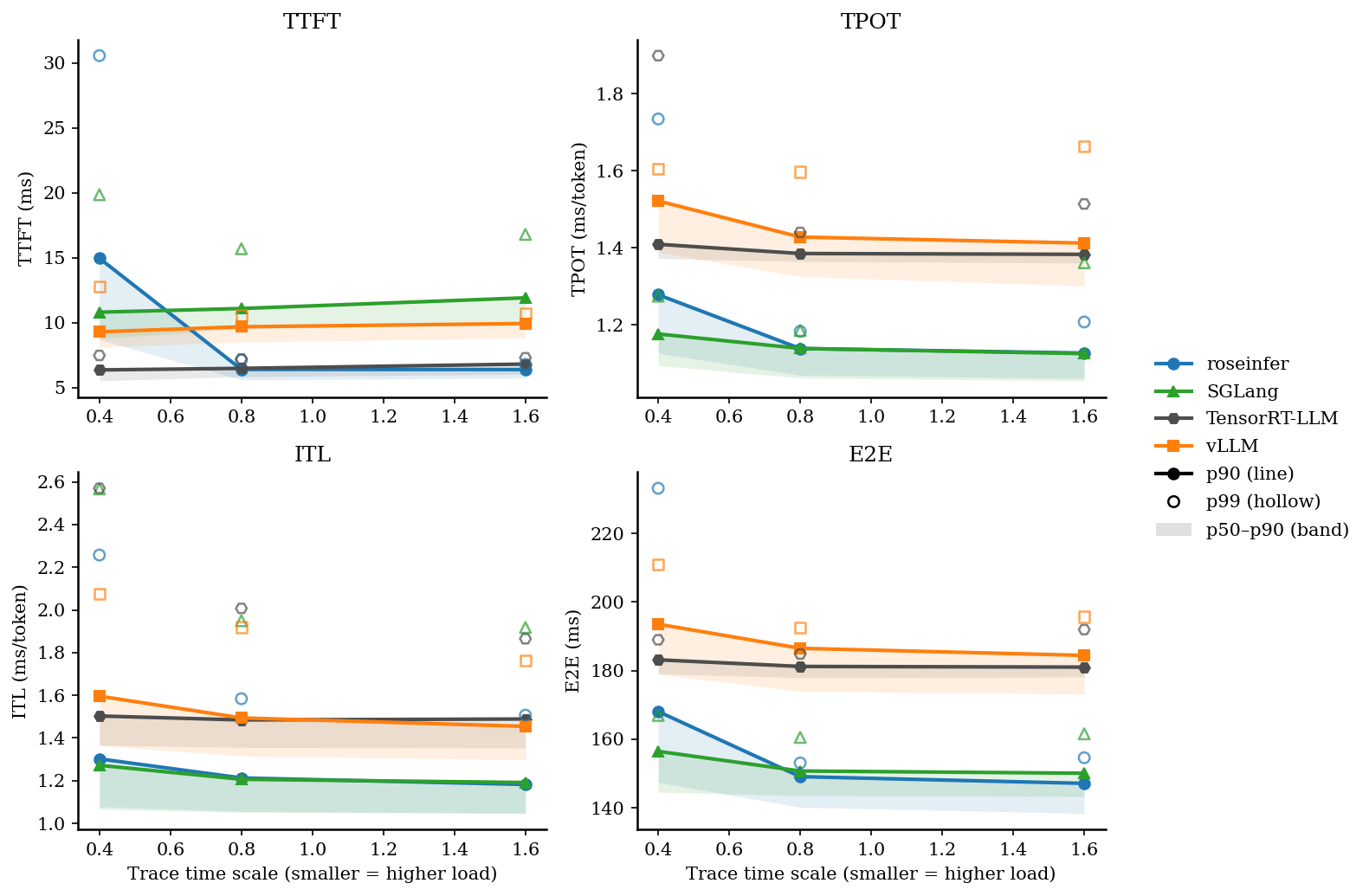
2. Online 结果
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer | 9.10/14.99/30.66 | 1.13/1.30/1.67 | 1.08/1.31/2.33 | 147.80/169.02/217.62 |
| 0.40 | SGLang | 8.81/10.76/20.37 | 1.09/1.18/1.28 | 1.06/1.26/2.48 | 144.71/155.61/167.55 |
| 0.40 | TensorRT-LLM | 6.01/7.16/8.04 | 1.37/1.41/1.87 | 1.37/1.51/2.62 | 179.77/183.32/189.11 |
| 0.40 | vLLM | 9.08/10.64/15.04 | 1.03/1.10/1.15 | 1.02/1.19/1.76 | 136.76/148.02/153.48 |
| 0.80 | roseinfer | 5.58/6.36/7.60 | 1.07/1.14/1.16 | 1.06/1.21/1.58 | 140.08/148.89/153.50 |
| 0.80 | SGLang | 9.60/11.29/17.22 | 1.06/1.13/1.18 | 1.05/1.20/2.08 | 143.47/151.83/159.04 |
| 0.80 | TensorRT-LLM | 6.17/7.20/8.24 | 1.36/1.38/1.50 | 1.36/1.49/2.00 | 178.66/181.82/189.60 |
| 0.80 | vLLM | 9.39/10.70/11.79 | 0.99/1.07/1.11 | 0.99/1.15/1.47 | 133.98/143.83/147.86 |
| 1.60 | roseinfer | 5.85/6.50/7.13 | 1.07/1.13/1.20 | 1.05/1.19/1.51 | 138.80/147.41/155.84 |
| 1.60 | SGLang | 10.07/11.76/16.47 | 1.05/1.13/1.24 | 1.05/1.19/1.84 | 143.62/150.19/162.64 |
| 1.60 | TensorRT-LLM | 6.47/7.48/8.01 | 1.36/1.39/1.52 | 1.35/1.50/1.88 | 178.38/181.57/200.40 |
| 1.60 | vLLM | 9.90/11.16/11.74 | 0.98/1.06/1.14 | 0.98/1.12/1.32 | 133.85/142.63/151.43 |
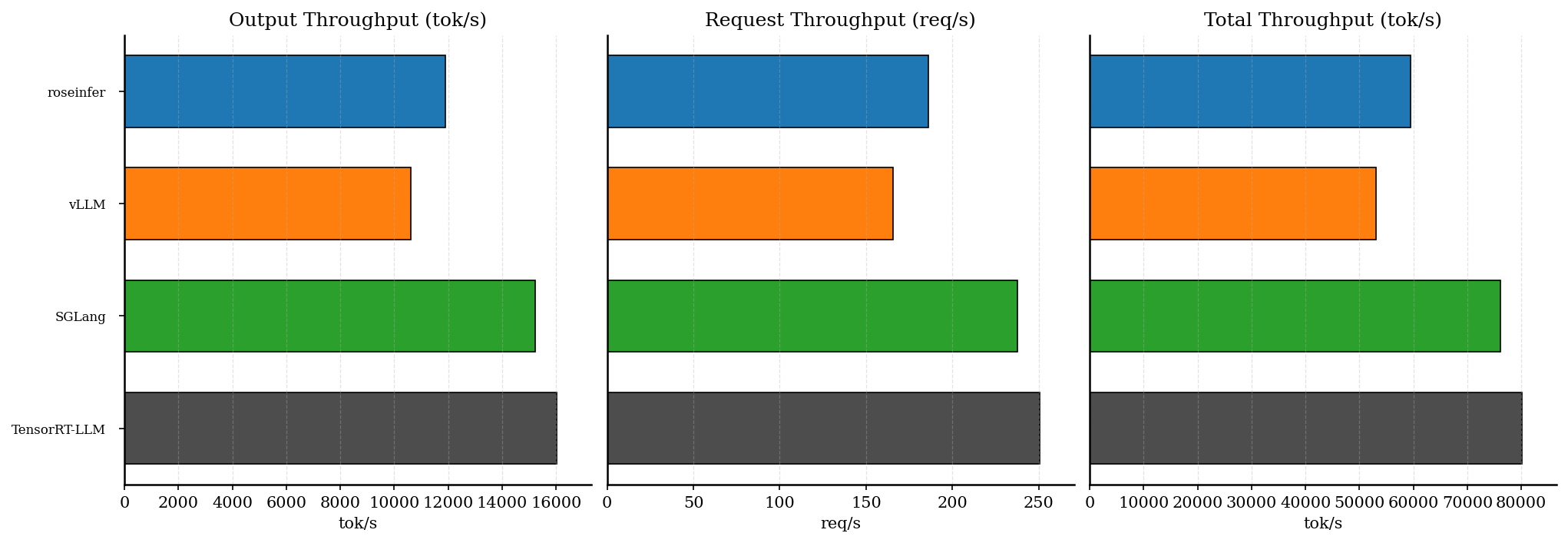
3. Offline 结果
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 185.06 | 11843.99 | 59219.95 | 0.692 |
| SGLang | 241.38 | 15448.16 | 77240.81 | 0.530 |
| TensorRT-LLM | 249.31 | 15955.85 | 79779.23 | 0.513 |
| vLLM | 193.69 | 12396.47 | 61982.35 | 0.661 |
3.1 为什么 vLLM offline 吞吐偏低?
这组 benchmark 用的是 gpt2(模型很小),同时启用了 top_k/top_p sampling。对这种“小模型 + sampling”的 workload 来说,sampling / 调度的开销很容易变成吞吐瓶颈(相对大模型而言更明显)。
vLLM 这边有一个很典型的 trade-off:
- 默认路径更偏向 online latency:top-k/top-p 的采样实现尽量避免引入额外的 CPU-GPU synchronization。
- 但这也意味着在某些 workload 下(尤其是小模型),offline throughput 会被 sampling 侧开销拖住。
vLLM 提供了 FlashInfer sampler 的 opt-in(VLLM_USE_FLASHINFER_SAMPLER=1),它能显著提升 offline throughput,但会明显拉高 online 的 E2E(主要是每 token 的额外同步/开销会被放大)。
因此本文的 baseline 仍然使用 vLLM 默认 sampler(更贴近 online serving 的常见取舍);如果你只关心 offline “吞吐上限”,可以单独给 vLLM 跑一份 VLLM_USE_FLASHINFER_SAMPLER=1 的结果作为参考。
3.2 Attention backend 的影响
这篇 baseline 以“各家更优/更常见”的组合为准:
- vLLM:
attention_backend=flashinfer - SGLang:
attention_backend=triton(采样仍用sampling_backend=flashinfer)
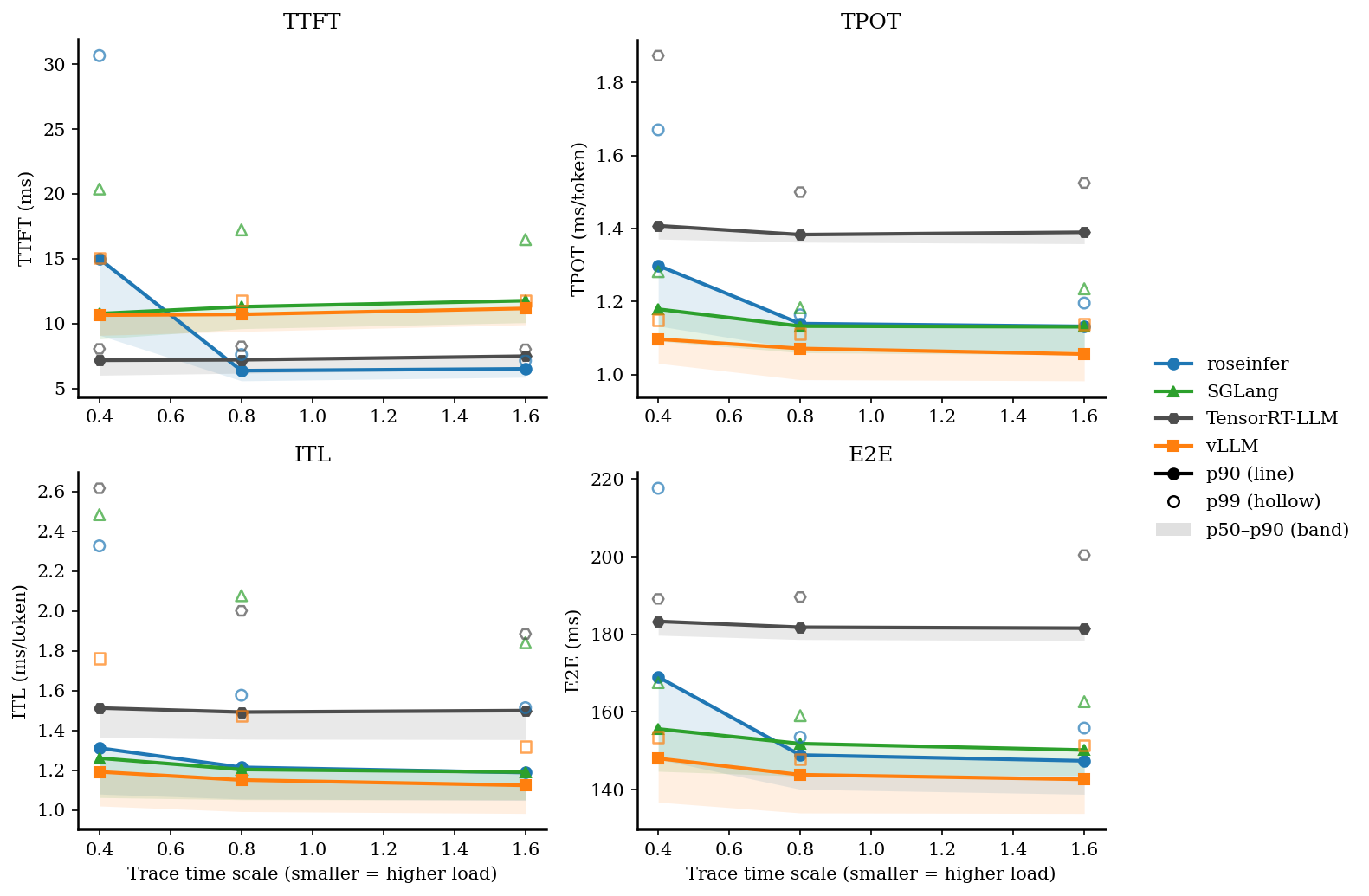
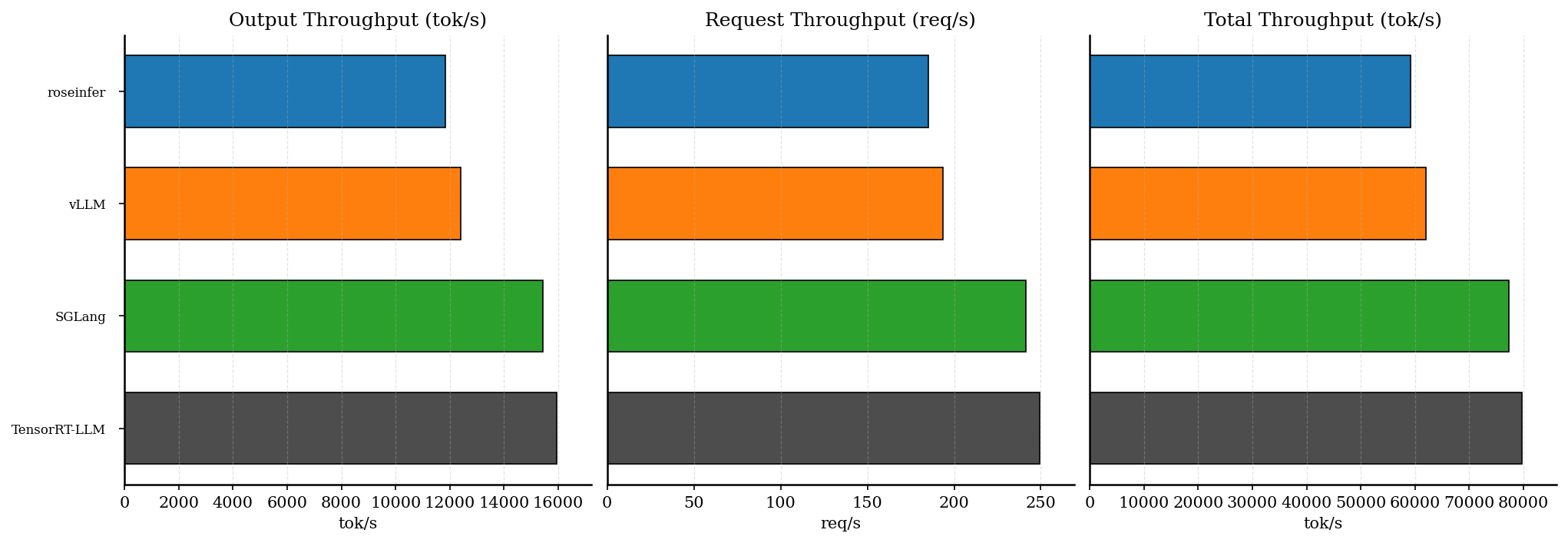
对照实验(见后面的 “SGLang attention=flashinfer”):在这个 gpt2 workload 下,SGLang 的 flashinfer attention 并不占优,offline throughput 会从 15448 tok/s 降到 13926 tok/s(约 -11%);online 的 TTFT/E2E 也只有小幅波动,整体 triton 略好。
一个经验解释:gpt2 是 MHA(非 GQA),FlashInfer 的某些高性能路径更偏向 GQA / 更大 group size 的场景;在这个 workload 上,SGLang 的 Triton attention 反而更合适。
4. 对照:SGLang attention=flashinfer
下面是把 vLLM / SGLang 的 attention backend 都强制到 flashinfer 的对照结果,保留用于参考:
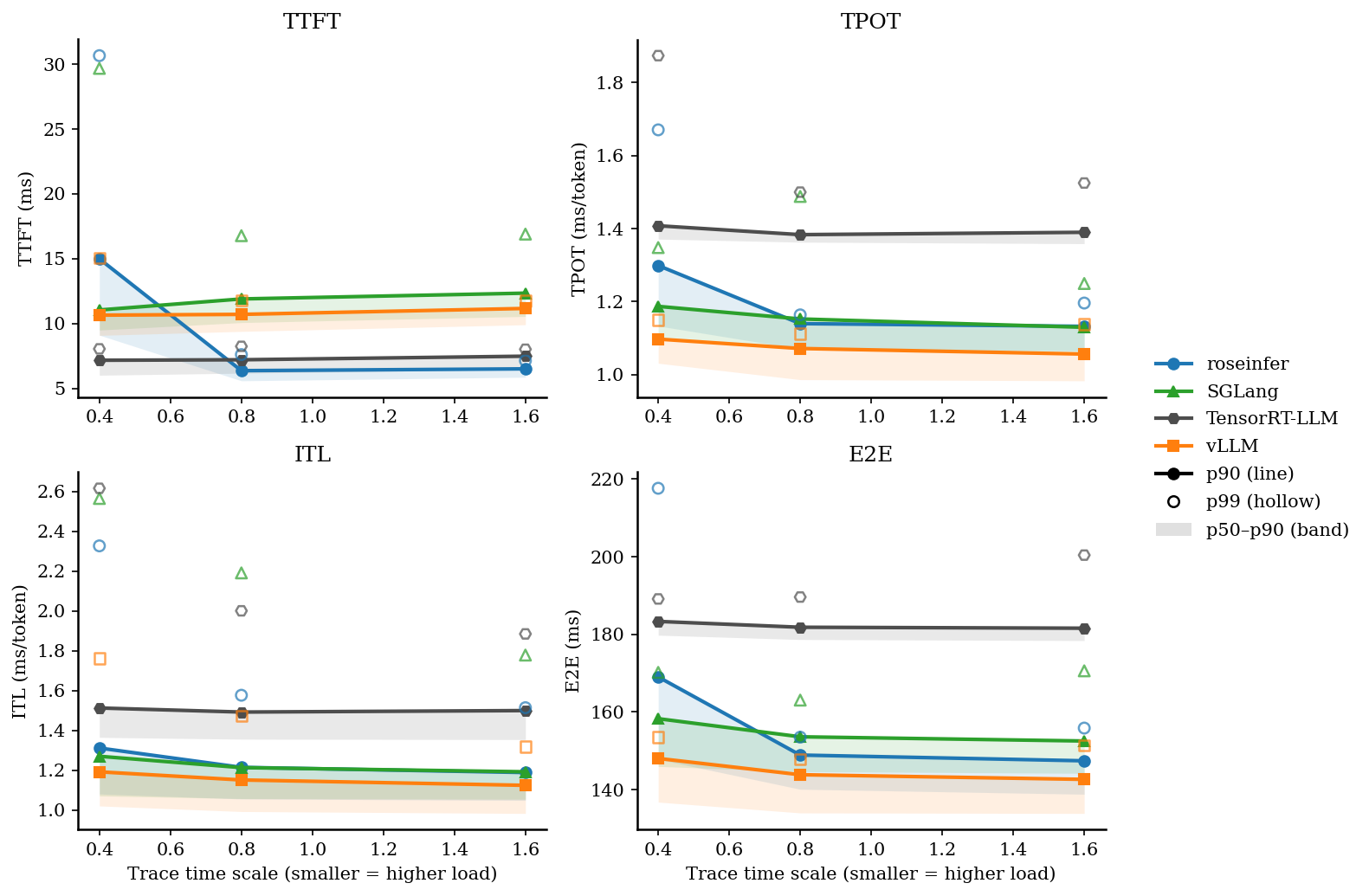
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer | 9.10/14.99/30.66 | 1.13/1.30/1.67 | 1.08/1.31/2.33 | 147.80/169.02/217.62 |
| 0.40 | SGLang | 9.49/11.04/29.68 | 1.10/1.19/1.35 | 1.07/1.27/2.56 | 145.96/158.26/170.19 |
| 0.40 | TensorRT-LLM | 6.01/7.16/8.04 | 1.37/1.41/1.87 | 1.37/1.51/2.62 | 179.77/183.32/189.11 |
| 0.40 | vLLM | 9.08/10.64/15.04 | 1.03/1.10/1.15 | 1.02/1.19/1.76 | 136.76/148.02/153.48 |
| 0.80 | roseinfer | 5.58/6.36/7.60 | 1.07/1.14/1.16 | 1.06/1.21/1.58 | 140.08/148.89/153.50 |
| 0.80 | SGLang | 10.07/11.89/16.77 | 1.07/1.15/1.49 | 1.06/1.21/2.19 | 144.63/153.60/163.05 |
| 0.80 | TensorRT-LLM | 6.17/7.20/8.24 | 1.36/1.38/1.50 | 1.36/1.49/2.00 | 178.66/181.82/189.60 |
| 0.80 | vLLM | 9.39/10.70/11.79 | 0.99/1.07/1.11 | 0.99/1.15/1.47 | 133.98/143.83/147.86 |
| 1.60 | roseinfer | 5.85/6.50/7.13 | 1.07/1.13/1.20 | 1.05/1.19/1.51 | 138.80/147.41/155.84 |
| 1.60 | SGLang | 10.54/12.34/16.90 | 1.06/1.13/1.25 | 1.05/1.19/1.78 | 144.19/152.51/170.59 |
| 1.60 | TensorRT-LLM | 6.47/7.48/8.01 | 1.36/1.39/1.52 | 1.35/1.50/1.88 | 178.38/181.57/200.40 |
| 1.60 | vLLM | 9.90/11.16/11.74 | 0.98/1.06/1.14 | 0.98/1.12/1.32 | 133.85/142.63/151.43 |
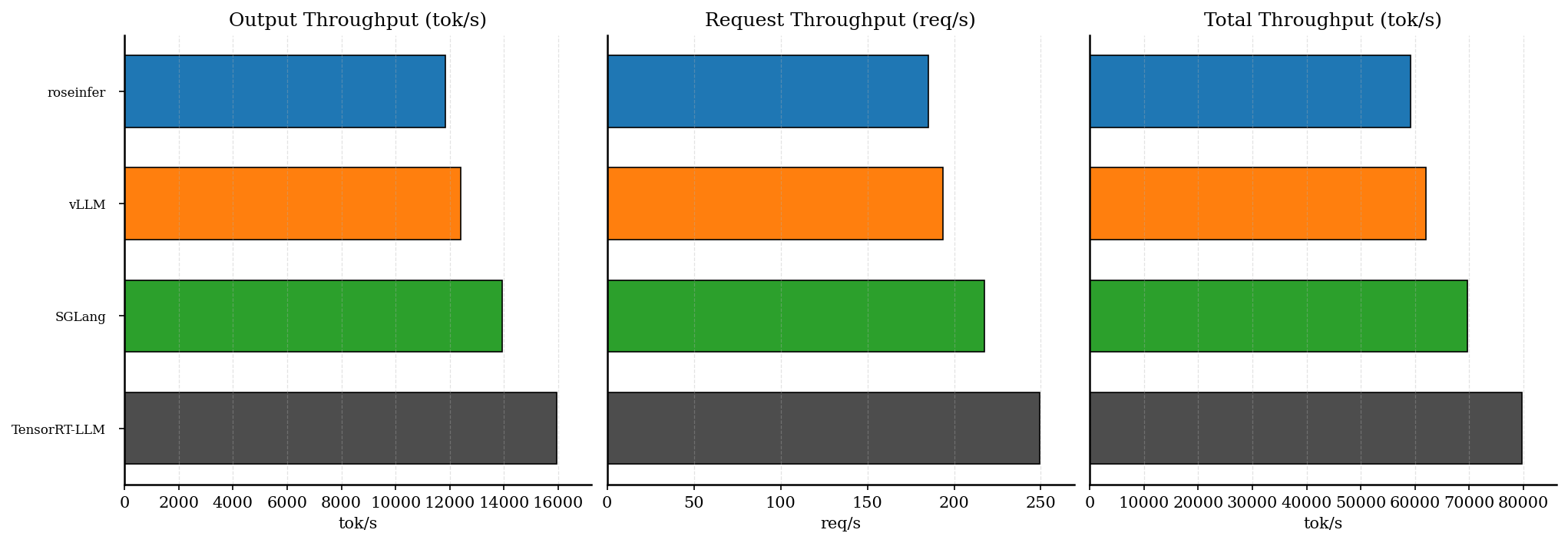
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 185.06 | 11843.99 | 59219.95 | 0.692 |
| SGLang | 217.60 | 13926.19 | 69630.93 | 0.588 |
| TensorRT-LLM | 249.31 | 15955.85 | 79779.23 | 0.513 |
| vLLM | 193.69 | 12396.47 | 61982.35 | 0.661 |
5. 旧结果(未强制 FlashInfer attention)
下面是之前的 baseline(vLLM attention backend=auto,实际选择了 FlashAttention;SGLang attention backend=triton),保留用于对比:
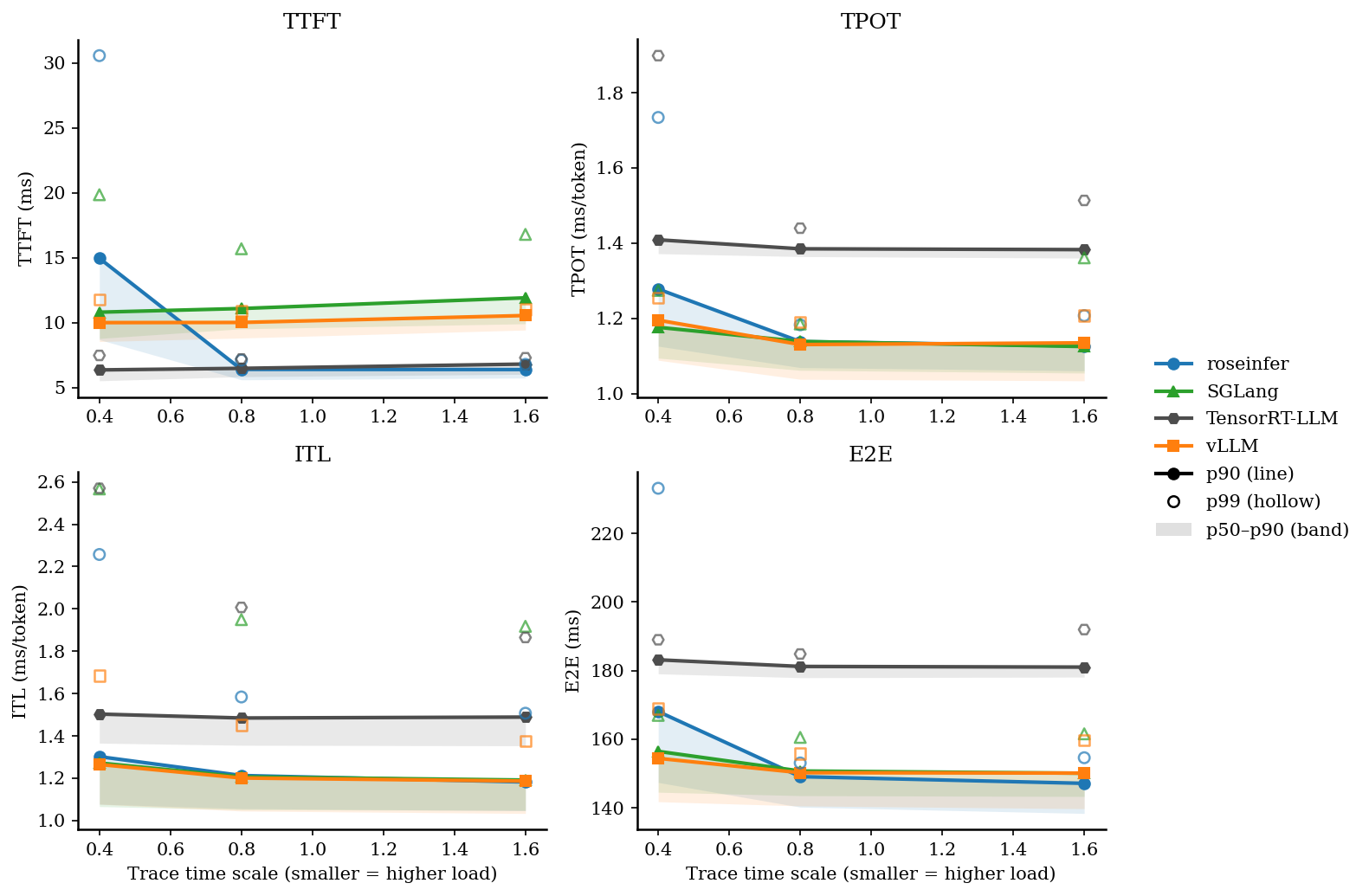
| scale | backend | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer | 8.70/14.96/30.56 | 1.13/1.28/1.73 | 1.08/1.30/2.26 | 147.41/168.09/233.17 |
| 0.40 | SGLang | 8.79/10.81/19.85 | 1.09/1.18/1.27 | 1.07/1.27/2.57 | 144.56/156.48/166.97 |
| 0.40 | TensorRT-LLM | 5.53/6.37/7.49 | 1.37/1.41/1.90 | 1.37/1.50/2.57 | 179.08/183.17/189.01 |
| 0.40 | vLLM | 8.55/10.01/11.78 | 1.09/1.20/1.26 | 1.08/1.27/1.68 | 141.80/154.44/168.93 |
| 0.80 | roseinfer | 5.61/6.41/7.13 | 1.07/1.14/1.18 | 1.06/1.21/1.58 | 140.22/149.11/153.10 |
| 0.80 | SGLang | 9.53/11.10/15.69 | 1.06/1.14/1.19 | 1.05/1.21/1.95 | 143.57/150.76/160.55 |
| 0.80 | TensorRT-LLM | 5.85/6.49/7.22 | 1.36/1.39/1.44 | 1.36/1.48/2.01 | 177.96/181.23/184.86 |
| 0.80 | vLLM | 8.83/10.02/10.91 | 1.04/1.13/1.19 | 1.05/1.20/1.45 | 140.57/150.26/155.83 |
| 1.60 | roseinfer | 5.75/6.40/6.80 | 1.06/1.13/1.21 | 1.05/1.18/1.51 | 138.38/147.16/154.62 |
| 1.60 | SGLang | 9.92/11.92/16.80 | 1.06/1.13/1.36 | 1.05/1.19/1.92 | 143.33/150.10/161.59 |
| 1.60 | TensorRT-LLM | 6.04/6.82/7.31 | 1.36/1.38/1.51 | 1.35/1.49/1.86 | 178.13/181.04/191.98 |
| 1.60 | vLLM | 9.44/10.56/11.03 | 1.03/1.14/1.21 | 1.03/1.19/1.38 | 139.77/150.15/159.79 |
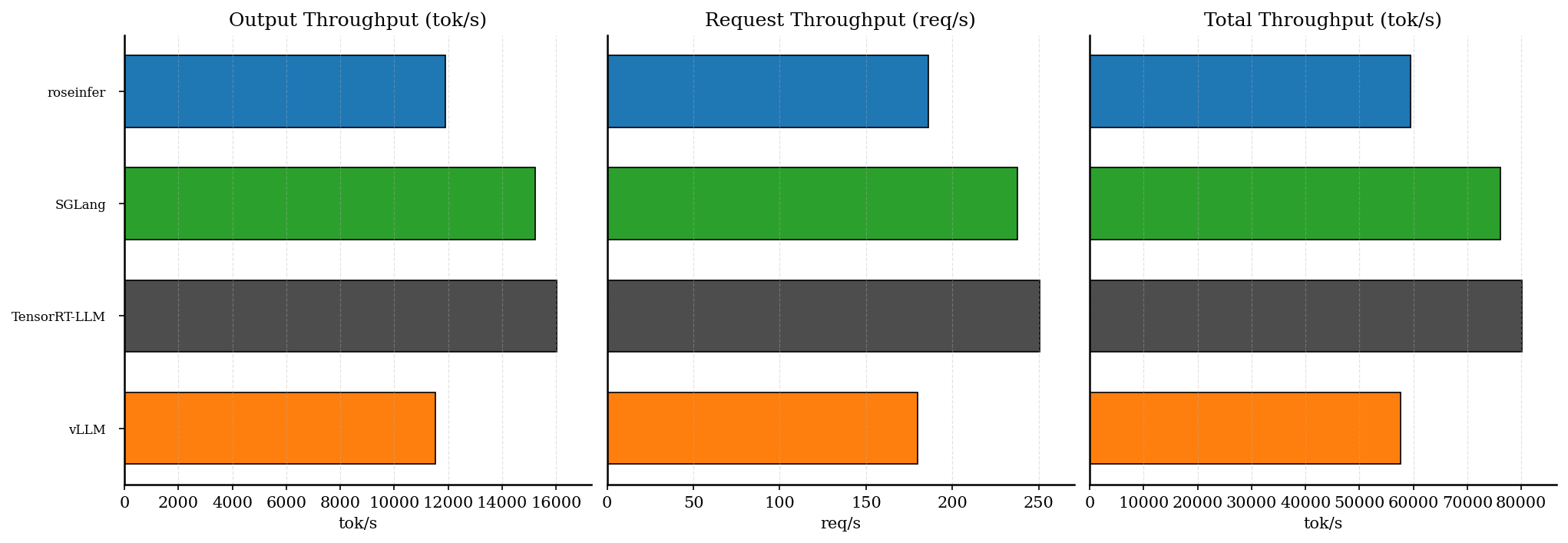
| backend | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer | 185.92 | 11898.63 | 59493.14 | 0.688 |
| SGLang | 237.89 | 15225.16 | 76125.79 | 0.538 |
| TensorRT-LLM | 250.54 | 16034.54 | 80172.72 | 0.511 |
| vLLM | 179.91 | 11514.03 | 57570.13 | 0.712 |
6. roseinfer:关闭 overlap schedule(nooverlap)
为了评估 roseinfer 默认开启的 CPU/GPU overlap(overlap_schedule)的影响,我保持其它参数不变,只额外加上 --roseinfer-no-overlap-schedule 跑了一组 roseinfer 的 online/offline,并采集了 torch profiler 与 nsys profile。
6.1 运行命令
online/offline benchmark:
./.conda-bench/bin/python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--output-dir outputs/benchmarks/serving/baseline_077_final/roseinfer_nooverlap \
--backends roseinfer \
--n 200 --scales 0.4,0.8,1.6 --timeout-ready-s 600 \
--roseinfer-no-overlap-schedule
./.conda-bench/bin/python benchmarks/serving/offline_compare.py \
--model gpt2 --gpu 0 \
--output-dir outputs/benchmarks/serving/baseline_077_final/roseinfer_nooverlap \
--backends roseinfer \
--num-prompts 128 --input-len 256 --output-len 64 --max-batch-size 256 \
--roseinfer-no-overlap-schedule
profile(online/offline 各跑一份;online 用 scale=0 让 trace 更“密集”,并设置 --cuda-flush-interval=1ms 以稳定拿到 CUDA kernels):
./.conda-bench/bin/python benchmarks/serving/online_compare.py \
--model gpt2 --gpu 0 \
--output-dir outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap \
--backends roseinfer \
--roseinfer-no-overlap-schedule \
--profile both --profile-only \
--profile-n 16 --profile-scale 0 \
--profile-torch-with-stack --profile-torch-record-shapes \
--profile-nsys-cuda-flush-interval-ms 1
./.conda-bench/bin/python benchmarks/serving/offline_compare.py \
--model gpt2 --gpu 0 \
--output-dir outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap \
--backends roseinfer \
--roseinfer-no-overlap-schedule \
--profile both --profile-only \
--profile-num-prompts 8 --profile-input-len 256 --profile-output-len 64 \
--profile-nsys-cuda-flush-interval-ms 1
(可选)nsys 生成/更新 .sqlite 并看 kernel summary:
nsys stats --report cuda_gpu_kern_sum \
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/online_20260119_104950/profiles/nsys/roseinfer+nooverlap/roseinfer+nooverlap.nsys-rep
6.2 Online 对照结果
| scale | config | TTFT p50/p90/p99 (ms) | TPOT p50/p90/p99 (ms) | ITL p50/p90/p99 (ms) | E2E p50/p90/p99 (ms) |
|---|---|---|---|---|---|
| 0.40 | roseinfer(default) | 9.10/14.99/30.66 | 1.13/1.30/1.67 | 1.08/1.31/2.33 | 147.80/169.02/217.62 |
| 0.40 | roseinfer+nooverlap | 8.34/13.50/29.57 | 1.21/1.38/1.77 | 1.16/1.41/2.20 | 157.75/179.60/228.82 |
| 0.80 | roseinfer(default) | 5.58/6.36/7.60 | 1.07/1.14/1.16 | 1.06/1.21/1.58 | 140.08/148.89/153.50 |
| 0.80 | roseinfer+nooverlap | 5.90/6.72/7.57 | 1.13/1.21/1.24 | 1.13/1.31/1.58 | 149.09/158.81/163.18 |
| 1.60 | roseinfer(default) | 5.85/6.50/7.13 | 1.07/1.13/1.20 | 1.05/1.19/1.51 | 138.80/147.41/155.84 |
| 1.60 | roseinfer+nooverlap | 6.11/7.04/7.33 | 1.13/1.21/1.27 | 1.12/1.28/1.52 | 146.89/157.27/167.10 |
6.3 Offline 对照结果
| config | req/s | output tok/s | total tok/s | total latency (s) |
|---|---|---|---|---|
| roseinfer(default) | 185.06 | 11843.99 | 59219.95 | 0.692 |
| roseinfer+nooverlap | 173.28 | 11090.10 | 55450.51 | 0.739 |
6.4 简要结论
- 关闭 overlap schedule 后,TPOT/ITL 与 E2E 在三个 scale 上都有明显上升;offline 吞吐约下降 6%。
- TTFT 在
scale=0.4上略有改善,但在scale=0.8/1.6上变差;整体仍体现出 overlap 对“稳定吞吐/端到端”的帮助。
7. 原始数据
当前结果(vLLM attention backend=flashinfer;SGLang attention backend=triton):
- online:
outputs/benchmarks/serving/baseline_077_final/sglang_triton/default/online_results.json - offline:
outputs/benchmarks/serving/baseline_077_final/sglang_triton/default/offline_results.json - figures(脚本产物):
outputs/benchmarks/serving/baseline_077_final/sglang_triton/default/figures/
对照结果(SGLang attention backend=flashinfer):
- online:
outputs/benchmarks/serving/baseline_077_final/attn_flashinfer/default/online_results.json - offline:
outputs/benchmarks/serving/baseline_077_final/attn_flashinfer/default/offline_results.json - figures(脚本产物):
outputs/benchmarks/serving/baseline_077_final/attn_flashinfer/default/figures/
旧结果(未强制 FlashInfer attention,保留用于对比):
- online:
outputs/benchmarks/serving/baseline_077_final/vllm_async/default/online_results.json - offline:
outputs/benchmarks/serving/baseline_077_final/vllm_async/default/offline_results.json - figures(脚本产物):
outputs/benchmarks/serving/baseline_077_final/vllm_async/default/figures/
旧结果(vLLM async scheduling 关闭,保留用于对比):
- online:
outputs/benchmarks/serving/baseline_077_final/default/online_results.json - offline:
outputs/benchmarks/serving/baseline_077_final/default/offline_results.json - figures(脚本产物):
outputs/benchmarks/serving/baseline_077_final/default/figures/
roseinfer 对照(关闭 overlap schedule / CPU-GPU overlap):
- online:
outputs/benchmarks/serving/baseline_077_final/roseinfer_nooverlap/default/online_results.json - offline:
outputs/benchmarks/serving/baseline_077_final/roseinfer_nooverlap/default/offline_results.json - online profile manifest:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/online_20260119_104950/profile_manifest.json - online torch trace:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/online_20260119_104950/profiles/torch/roseinfer+nooverlap/trace.json - online nsys rep:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/online_20260119_104950/profiles/nsys/roseinfer+nooverlap/roseinfer+nooverlap.nsys-rep - online nsys sqlite:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/online_20260119_104950/profiles/nsys/roseinfer+nooverlap/roseinfer+nooverlap.sqlite - offline profile manifest:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/offline_20260119_105039/profile_manifest.json - offline torch trace:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/offline_20260119_105039/profiles/torch/roseinfer+nooverlap/trace.trace.json - offline nsys rep:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/offline_20260119_105039/profiles/nsys/roseinfer+nooverlap/roseinfer+nooverlap.nsys-rep - offline nsys sqlite:
outputs/benchmarks/serving/baseline_077_final/profile_roseinfer_nooverlap/offline_20260119_105039/profiles/nsys/roseinfer+nooverlap/roseinfer+nooverlap.sqlite