本页所有表格都围绕起点移动;后缀文本只是帮助你验证排序。
Suffix Array Only
后缀数组入门
这一页只讲后缀数组本身:把所有后缀排成字典序,理解 rank 为什么能代表一段前缀,理解倍增为什么每轮只看两个已经知道顺序的块。
本页只回答一个问题:后缀数组为什么能用“排序后的起点列表”代表所有后缀的字典序。读完后,你应该能解释 suffix、rank、pair key 和 doubling 之间的关系。
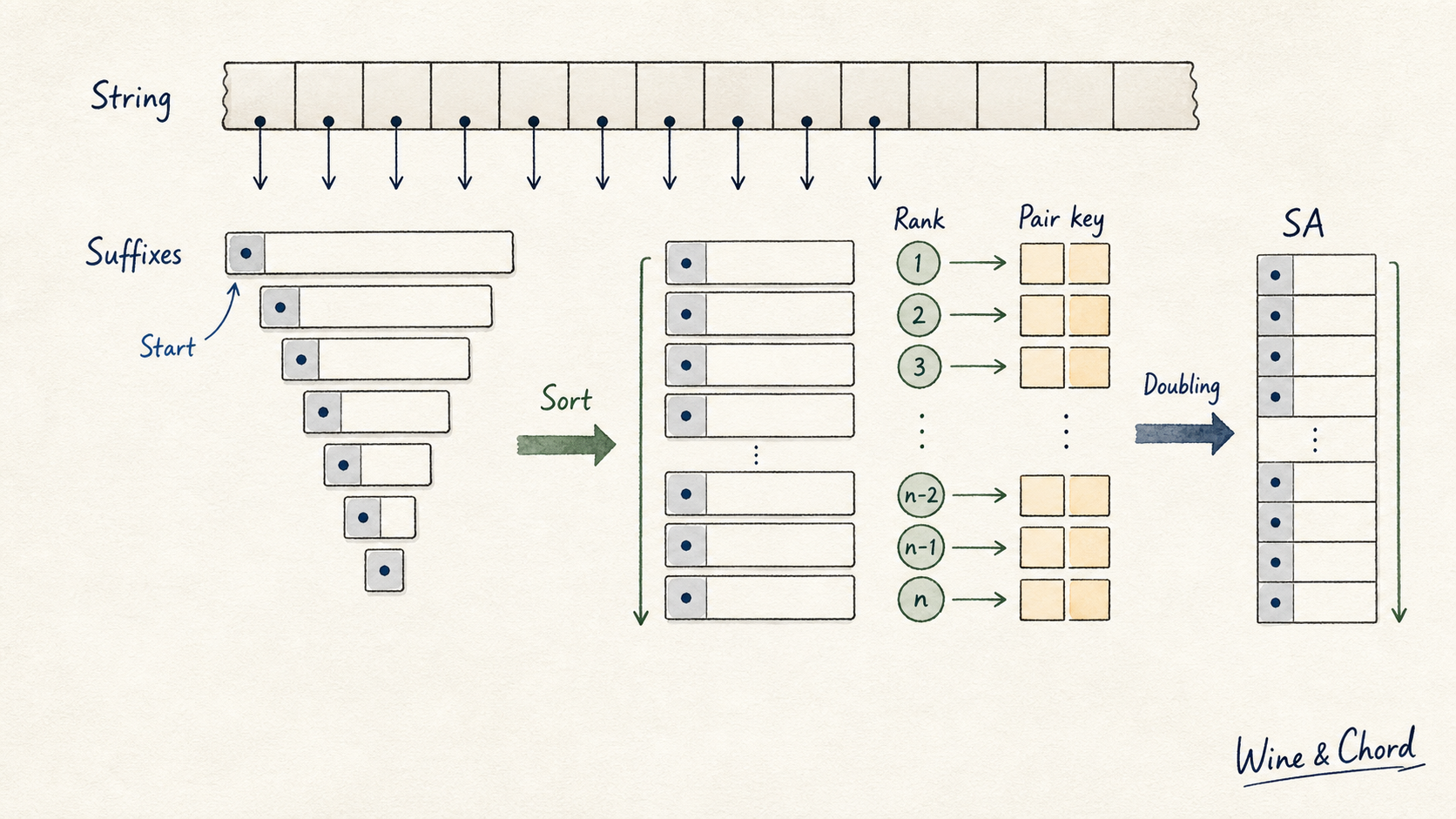
倍增不是重新比较整段字符串,而是复用上一轮 rank 形成二元组。
读完应能说清 sa 存的是排序后的起点,不是复制后的后缀字符串。
为什么
原字符串
后缀观察台
当前构造轮
| # | 起点 | 后缀 | 比较键 | 新 rank |
|---|
知识互链
LCP 是什么 后缀数组只负责排序;相邻后缀到底像到哪里,由 LCP 单独讲。 应用:最短唯一子数组 这道题会把后缀数组和 LCP 拼起来,但不污染本页的基础概念。C++
核心代码
这段代码展示倍增构造的骨架。重点不是背模板,而是理解 rank 如何把一段前缀压成可比较的名字。
vector<int> buildSuffixArray(string s) { s += '$'; int n = s.size(); vector<int> sa(n), cls(n); vector<pair<char, int>> first(n); for (int i = 0; i < n; i++) first[i] = {s[i], i}; sort(first.begin(), first.end()); for (int i = 0; i < n; i++) sa[i] = first[i].second; cls[sa[0]] = 0; for (int i = 1; i < n; i++) { cls[sa[i]] = cls[sa[i - 1]]; if (first[i].first != first[i - 1].first) cls[sa[i]]++; } for (int len = 1; len < n; len <<= 1) { sort(sa.begin(), sa.end(), [&](int a, int b) { if (cls[a] != cls[b]) return cls[a] < cls[b]; return cls[(a + len) % n] < cls[(b + len) % n]; }); vector<int> next(n); next[sa[0]] = 0; for (int i = 1; i < n; i++) { pair<int, int> prev = { cls[sa[i - 1]], cls[(sa[i - 1] + len) % n], }; pair<int, int> now = { cls[sa[i]], cls[(sa[i] + len) % n], }; next[sa[i]] = next[sa[i - 1]] + (prev != now); } cls = next; } sa.erase(sa.begin()); return sa;}